Flink的状态编程和容错机制(四)
一、状态编程
Flink 内置的很多算子,数据源 source,数据存储 sink 都是有状态的,流中的数据都是 buffer records,会保存一定的元素或者元数据。例如 : ProcessWindowFunction会缓存输入流的数据,ProcessFunction 会保存设置的定时器信息等等。
1,算子状态(operator state)
算子状态的作用范围限定为算子任务。这意味着由同一并行任务所处理的所有数据都可以访问到相同的状态,状态对于同一任务而言是共享的。Flink为算子状态提供三种基本数据结构:
列表状态(List state):将状态表示为一组数据的列表。
联合列表状态(Union list state):也将状态表示为数据的列表。它与常规列表状态的区别在于,在发生故障时,或者从保存点(savepoint)启动应用程序时如何恢复。
广播状态(Broadcast state):如果一个算子有多项任务,而它的每项任务状态又都相同,那么这种特殊情况最适合应用广播状态。
2,键控状态(keyed state)
键控状态是根据输入数据流中定义的键(key)来维护和访问的。具有相同 key 的所有数据都会访问相同的状态。Flink 的 Keyed State 支持以下数据类型:
ValueState[T]保存单个的值,值的类型为 T。
get 操作: ValueState.value()
set 操作: ValueState.update(value: T)
ListState[T]保存一个列表,列表里的元素的数据类型为 T。基本操作如下:
ListState.add(value: T)
ListState.addAll(values: java.util.List[T])
ListState.get()返回 Iterable[T]
ListState.update(values: java.util.List[T])
MapState[K, V]保存 Key-Value 对。
MapState.get(key: K)
MapState.put(key: K, value: V)
MapState.contains(key: K)
MapState.remove(key: K)
ReducingState[T]
AggregatingState[I, O]
State.clear()是清空操作。
案例:判断两个相邻的评分之间差值,如果大于10就输出当前key对应的这两次评分。
自定义继承RichFlatMapFunction
val resultDStream:DataStream[(String,Double,Double)] = stream.keyBy(_.id)
.flatMap(new MyKeyedState(10.0)) //keyby之后再进行自定义的聚合
//输入为id,输入为(id,lastRate,currentRate)
class MyKeyedState(diff:Double) extends RichFlatMapFunction[Item,(String,Double,Double)]{
//记录上次的评分
var lastRateState:ValueState[Double] = _
override def open(parameters: Configuration): Unit = {
//初始化上次的评分
lastRateState = getRuntimeContext.getState[Double](new ValueStateDescriptor[Double]("rate",Types.of[Double]))
}
override def flatMap(value: Item, out: Collector[(String, Double, Double)]): Unit = {
val currentRate = value.rate
val lastRate = lastRateState.value()
if (lastRate != && (lastRate - currentRate).abs > diff) { //不是第一次进入并且差值大于10
out.collect((value.id,lastRate,currentRate))
}
lastRateState.update(currentRate)
}
}
使用flatMapWithState
val resultDStream:DataStream[(String,Double,Double)] = stream.keyBy(_.id)
.flatMapWithState[(String,Double,Double),Double]{
case (item:Item,None)=> //如果state为None表示是第一次,此时给定初始值即可
(List.empty,Some(item.rate))
case (item:Item,last:Some[Double])=> //如果有值的情况下就是判定和输出
val lastRate = last.getOrElse()
val currentRate = item.rate
if (lastRate != && (lastRate - currentRate).abs > 10.0) { //不是第一次进入并且差值大于10
(List((item.id,lastRate,currentRate)),Some(currentRate))
}else{
(List.empty,Some(currentRate))
}
}
二、状态一致性
1,一致性级别
在流处理中,一致性可以分为3个级别:
at-most-once: 这其实是没有正确性保障的委婉说法 ——故障发生之后,计数结果可能丢失。 同样的还有 udp。
at-least-once: 这表示计数结果可能大于正确值,但绝不会小于正确值。 也就是说,计数程序在发生故障后可能多算,但是绝不会少算。
exactly-once: 这指的是系统保证在发生故障后得到的计数结果与正确值一致。
Flink 的一个重大价值在于,它既保证了 exactly-once,也具有低延迟和高吞吐的处理能力。
2,端到端(end-to-end)状态一致性
端到端的一致性保证,意味着结果的正确性贯穿了整个流处理应用的始终;每一个组件都保证了它自己的一致性,整个端到端的一致性级别取决于所有组件中一致性最弱的组件。具体可以划分如下:
内部保证 — — 依赖 checkpoint
source端 — — 需要外部源可重设数据的读取位置
sink端 — — 需要保证从故障恢复时,数据不会重复写入外部系统
而对于sink端,又有两种具体的实现方式:幂等( Idempotent)写入和事务性( Transactional)写入。
幂等:所谓幂等操作,是说一个操作,可以重复执行很多次,但只导致一次结果更改,也就是说,后面再重复执行就不起作用了
事务性:需要构建事务来写入外部系统,构建的事务对应着checkpoint,等到 checkpoint 真正完成的时候,才把所有对应的结果写入sink 系统中。
对于事务性写入,具体又有两种实现方式:预写日志(WAL)和两阶段提交(2PC)。DataStream API 提供了 GenericWriteAheadSink 模板类和TwoPhaseCommitSinkFunction 接口。

三、检查点(checkpoint)
1,检查点算法(图解)
简介:其实有两个source:source1和source2,这两个source均接收到(1,2,3,4,5,6,7,8,9...)等数据
第一步,其实接收到checkpoint编号为2的数据,如下图:

第二步,source停止接收checkpoint编号为2之后的数据,产生对应的barrier屏障。直到状态后端(state backends)存入对应的检查点之后,返回给source任务,待JobManager通知确认检查点完成。如图:

第三步,barrier对齐:等待所有source分区中标记相同检查点编号的数据到达处理完成之后再进行当前barrier(例如当前蓝色4数据是source1中cpt2之后的数据,故而先不做计算,会存入缓存直到当前黄色标记的cpt2之前的数据全部处理完毕)。如图:

当收到所有输入分区的 barrier 时,任务就将其状态保存到状态后端的检查点中,然后将 barrier 继续向下游转发。如图:
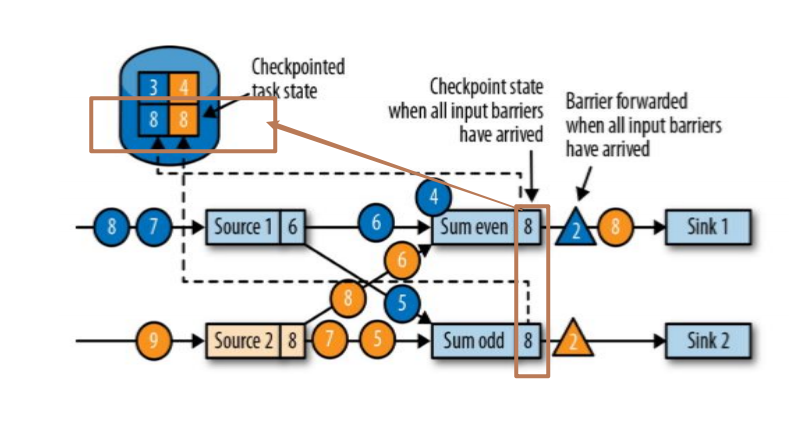
第四步:Sink 任务向 JobManager 确认状态保存到 checkpoint 完毕,当所有任务都确认已成功将状态保存到检查点时,检查点就真正完成了。如图:

Flink 检查点算法的正式名称是异步分界线快照(asynchronous barrier snapshotting)。该算法大致基于Chandy-Lamport 分布式快照算法。
检查点是 Flink 最有价值的创新之一,因为它使 Flink 可以保证 exactly-once,并且不需要牺牲性能。
2,Flink+Kafka实现exactly-once
端到端的状态一致性的实现,需要每一个组件都实现,对于 Flink + Kafka 的数据管道系统(Kafka 进、Kafka 出)而言,各组件怎样保证 exactly-once 语义呢?
内部 — — 利用 checkpoint 机制,把状态存盘,发生故障的时候可以恢复,保证内部的状态一致性。
source — — kafka consumer 作为 source,可以将偏移量保存下来,如果后续任务出现了故障,恢复的时候可以由连接器重置偏移量,重新消费数据,保证一致性
sink — — kafka producer 作为 sink,采用两阶段提交 sink,需要实现一个 TwoPhaseCommitSinkFunction
执行过程实际上是一个两段式提交,每个算子执行完成,会进行“预提交”,直到执行完sink 操作,会发起“确认提交”,如果执行失败,预提交会放弃掉。
具体的两阶段提交步骤总结如下:
第一条数据来了之后,开启一个 kafka 的事务(transaction),正常写入 kafka 分区日志但标记为未提交,这就是“预提交”
jobmanager 触发 checkpoint 操作,barrier 从 source 开始向下传递,遇到 barrier 的算子将状态存入状态后端,并通知 jobmanager
sink 连接器收到 barrier,保存当前状态,存入 checkpoint,通知jobmanager,并开启下一阶段的事务,用于提交下个检查点的数据
jobmanager 收到所有任务的通知,发出确认信息,表示 checkpoint 完成
sink 任务收到 jobmanager 的确认信息,正式提交这段时间的数据
外部 kafka 关闭事务,提交的数据可以正常消费了。
3,状态后端(state backend)
env.setStateBackend(new MemoryStateBackend())
env.setStateBackend(new FsStateBackend("checkpointDataUri"))
env.setStateBackend(new RocksDBStateBackend("checkpointDataUri"))
a)MemoryStateBackend
内存级的状态后端,会将键控状态作为内存中的对象进行管理,将它们存储在 TaskManager 的 JVM 堆上;而将checkpoint 存储在 JobManager 的内存中。
b)FsStateBackend
将checkpoint 存到远程的持久化文件系统(FileSystem)上。 而对于本地状态,跟 MemoryStateBackend 一样,也会存在 TaskManager 的 JVM 堆上。
c)RocksDBStateBackend
将所有状态序列化后,存入本地的 RocksDB 中存储。
使用RocksDB需要添加依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb_2.</artifactId>
<version>1.7.</version>
</dependency>
Flink的状态编程和容错机制(四)的更多相关文章
- 总结Flink状态管理和容错机制
本文来自8月11日在北京举行的 Flink Meetup会议,分享来自于施晓罡,目前在阿里大数据团队部从事Blink方面的研发,现在主要负责Blink状态管理和容错相关技术的研发. 本文主要内容如 ...
- Flink状态管理和容错机制介绍
本文主要内容如下: 有状态的流数据处理: Flink中的状态接口: 状态管理和容错机制实现: 阿里相关工作介绍: 一.有状态的流数据处理# 1.1.什么是有状态的计算# 计算任务的结果不仅仅依赖于输入 ...
- Flink原理(五)——容错机制
本文是博主阅读Flink官方文档以及<Flink基础教程>后结合自己理解所写,若有表达有误的地方欢迎大伙留言指出. 1. 前言 流式计算分为有状态和无状态两种情况,所谓状态就是计算过程中 ...
- Flink的状态管理与恢复机制
参考地址:https://www.cnblogs.com/airnew/p/9544683.html 问题一.什么是状态? 问题二.Flink状态类型有哪几种? 问题三.状态有什么作用? 问题四.如何 ...
- 「Flink」Flink的状态管理与容错
在Flink中的每个函数和运算符都是有状态的.在处理过程中可以用状态来存储数据,这样可以利用状态来构建复杂操作.为了让状态容错,Flink需要设置checkpoint状态.Flink程序是通过chec ...
- Flink 容错机制与状态
简介 Apache Flink提供了一种容错机制,可以持续恢复数据流应用程序的状态. 该机制确保即使出现故障,经过恢复,程序的状态也会回到以前的状态. Flink 主持 at least once 语 ...
- Apache Flink - 数据流容错机制
Apache Flink提供了一种容错机制,可以持续恢复数据流应用程序的状态.该机制确保即使出现故障,程序的状态最终也会反映来自数据流的每条记录(只有一次). 从容错和消息处理的语义上(at leas ...
- Flink 从0到1学习—— 分享四本 Flink 国外的书和二十多篇 Paper 论文
前言 之前也分享了不少自己的文章,但是对于 Flink 来说,还是有不少新入门的朋友,这里给大家分享点 Flink 相关的资料(国外数据 pdf 和流处理相关的 Paper),期望可以帮你更好的理解 ...
- Flink学习(三)状态机制于容错机制,State与CheckPoint
摘自Apache官网 一.State的基本概念 什么叫State?搜了一把叫做状态机制.可以用作以下用途.为了保证 at least once, exactly once,Flink引入了State和 ...
随机推荐
- 循序渐进VUE+Element 前端应用开发(17)--- 菜单资源管理
在权限管理系统中,菜单也属于权限控制的一个资源,应该直接应用于角色,和权限功能点一样,属于角色控制的一环.不同角色用户,登录系统后,出现的系统菜单是不同的.在VUE+Element 前端中,我们菜单结 ...
- Python Ethical Hacking - MAC Address & How to Change(1)
MAC ADDRESS Media Access Control Permanent Physical Unique Assigned by manufacturer WHY CHANGE THE M ...
- 洛谷P1063.能量项链
题目描述 在Mars星球上,每个Mars人都随身佩带着一串能量项链.在项链上有N颗能量珠.能量珠是一颗有头标记与尾标记的珠子,这些标记对应着某个正整数.并且,对于相邻的两颗珠子,前一颗珠子的尾标记一定 ...
- vue & 百度地图:使用百度地图
index.html <!DOCTYPE html> <html> <head> <meta charset="utf-8"> &l ...
- Newbe.Claptrap 框架入门,第二步 —— 简单业务,清空购物车
接上一篇 Newbe.Claptrap 框架入门,第一步 —— 创建项目,实现简易购物车 ,我们继续要了解一下如何使用 Newbe.Claptrap 框架开发业务.通过本篇阅读,您便可以开始尝试使用 ...
- MySQL数据库---表的操作
存储引擎 表就是文件,表的存储引擎就是文件的存储格式,即数据的组织存储方式. 字段类型 1.整数类型 整数类型:TINYINT SMALLINT MEDIUMINT INT BIGINT 作用:存储年 ...
- vue如何使用excel导出后台数据
let params = { // 请求参数 要下载Excel的id 'id':this.excelId }; //导入的接口名 api_excel_exportExcel().then(res =& ...
- django-celery 版本 常用命令
http://celery.github.io/django-celery/introduction.html #先启动服务器 python manage.py runserver #再启动worke ...
- HBase面试考点
HBase 架构图 组成部分及作用 Zookeeper在HBase中作用 Master的高可用 RegionServer的监控 元数据的入口 HMaster 不仅有维护集群元数据信息的功能,还能 通过 ...
- lua判断字符串包含另一个字符串
lua判断字符串包含另一个字符串 --string.find("元字符串","模式字符串") 如下: print(string.find("CCBWe ...