MapReduce 的 shuffle 过程中经历了几次 sort ?
shuffle 是从map产生输出到reduce的消化输入的整个过程。
排序贯穿于Map任务和Reduce任务,是MapReduce非常重要的一环,排序操作属于MapReduce计算框架的默认行为,不管流程是否需要,都会进行排序。
在MapReduce计算框架中,主要用到了两种排序方法:快速排序和归并排序
1)快速排序:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据比另外一部分的所有数据都小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此使整个数据成为有序序列。
2)归并排序:归并排序在分布式计算里面用的非常多,归并排序本身就是一个采用分治法的典型应用。归并排序是将两个(或两个以上)有序表合并成一个新的有序表,即把待排序序列分为若干个有序的子序列,再把有序的子序列合并为整体有序序列。
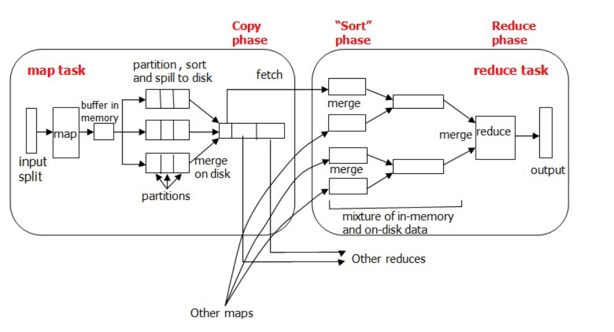
在map任务和reduce任务的过程中,一共发生3次排序操作。
当map函数产生输出时,会首先写入内存的环形缓冲区,当达到设定的阈值,在刷写磁盘之前,后台线程会将缓冲区的数据划分成相应的分区。在每个分区中,后台线程按键进行内排序,如下图所示:
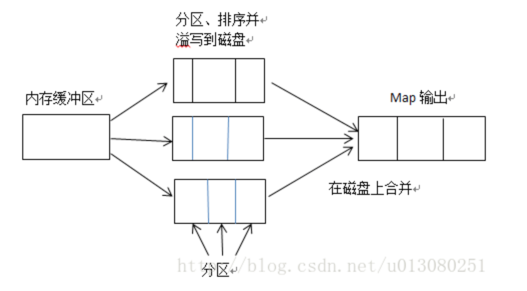
在Map任务完成之前,磁盘上存在多个已经分好区,并排好序的、大小和缓冲区一样的溢写文件,这时溢写文件将被合并成一个已分区且已排序的输出文件。由于溢写文件已经经过第一次排序,所以合并文件时只需要再做一次排序就可使输出文件整体有序。
在shuffle阶段,需要将多个Map任务的输出文件合并,由于经过第二次排序,所以合并文件时只需要再做一次排序就可使输出文件整体有序,如下图所示。
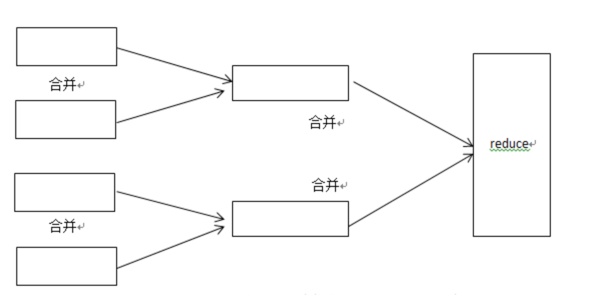
在这3次排序中第一次是在内存缓冲区做的排序,使用的算法是快速排序,第二次排序和第三次排序都是在文件合并阶段发生的,使用的是归并排序。
MapReduce 的 shuffle 过程中经历了几次 sort ?的更多相关文章
- MapReduce的Shuffle过程介绍
MapReduce的Shuffle过程介绍 Shuffle的本义是洗牌.混洗,把一组有一定规则的数据尽量转换成一组无规则的数据,越随机越好.MapReduce中的Shuffle更像是洗牌的逆过程,把一 ...
- MapReduce:Shuffle过程详解
1.Map任务处理 1.1 读取HDFS中的文件.每一行解析成一个<k,v>.每一个键值对调用一次map函数. <0,hello you> & ...
- Hadoop MapReduce的Shuffle过程
一.概述 理解Hadoop的Shuffle过程是一个大数据工程师必须的,笔者自己将学习笔记记录下来,以便以后方便复习查看. 二. MapReduce确保每个reducer的输入都是按键排序的.系统执行 ...
- mapReduce的shuffle过程
http://www.jianshu.com/p/c97ff0ab5f49 总结shuffle 过程: map端的shuffle: (1)map端产生数据,放入内存buffer中: (2)buffer ...
- shuffle过程中的信息传递
依据Spark1.4版 Spark中的shuffle大概是这么个过程:map端把map输出写成本地文件,reduce端去读取这些文件,然后执行reduce操作. 那么,问题来了: reducer是怎么 ...
- MapReduce的shuffle过程详解
[学习笔记] 结果分析:shuffle的英文是洗牌,混洗的意思,洗牌就是越乱越好的意思.当在集群的情况下是这样的,假如有三个map节点和三个reduce节点,一号reduce节点的数据会来自于三个ma ...
- Hadoop Mapreduce的shuffle过程详解
1.map task读取数据时默认调用TextInputFormat的成员RecoreReader,RecoreReader调用自己的read()方法,进行逐行读取,返回一个key.value; 2. ...
- Shuffle过程
Shuffle过程 在MapReduce框架中,shuffle是连接Map和Reduce之间的桥梁,Map的输出要用到Reduce中必须经过shuffle这个环节,shuffle的性能高低直接影响了整 ...
- 2.27 MapReduce Shuffle过程如何在Job中进行设置
一.shuffle过程 总的来说: *分区 partitioner *排序 sort *copy (用户无法干涉) 拷贝 *分组 group 可设置 *压缩 compress *combiner ma ...
随机推荐
- vue多个路由复用同一个组件的跳转问题(this.router.push)
因为router-view传参问题无法解决,比较麻烦. 所以我采取的是@click+this.router.push来跳转 但是现在的问题是跳转后,url改变了,但是页面的数据没有重新渲染,要刷新才可 ...
- PHP asort() 函数
------------恢复内容开始------------ 实例 对关联数组按照键值进行升序排序: <?php$age=array("Peter"=>"35 ...
- Proteus 8使用 1新建一个Proteus工程
新建一个Proteus工程 下一步 创建部分结束,可以看到两部分-->原理图与源代码. 首先按下F7或从“构建”菜单中选择“构建工程” 之后切换到原理图窗口 按下F12或点击窗口最左下角的“运行 ...
- 023_go语言中的通道
代码演示 package main import "fmt" func main() { messages := make(chan string) go func() { mes ...
- 【工具】之001-CentOS7 最小化安装配置
写在前面 我很懒,,,不想敲一个命令一个命令敲... "偷懒是有前提的,不是之前,就是之后." 简述 CentOS 7 最小化安装版本:CentOS-7-x86_64-Minima ...
- centos之hadoop的安装
Evernote Export 第一步 环境部署 参考 http://dblab.xmu.edu.cn/blog/install-hadoop-in-centos/ 1.创建hadoop用户 $su ...
- SSM框架入门——整合SSM并实现对数据的增删改查功能(Eclipse平台)
一.搭建框架环境 整个项目结构如下: 搭建SSM步骤如下: (1)准备好三大框架的jar包,如图所示 (2)在Eclipse中创建一个web project ,并把这些jar包粘贴到lib文件夹中. ...
- C#LeetCode刷题之#100-相同的树(Same Tree)
问题 该文章的最新版本已迁移至个人博客[比特飞],单击链接 https://www.byteflying.com/archives/4066 访问. 给定两个二叉树,编写一个函数来检验它们是否相同. ...
- C#LeetCode刷题之#717-1比特与2比特字符( 1-bit and 2-bit Characters)
问题 该文章的最新版本已迁移至个人博客[比特飞],单击链接 https://www.byteflying.com/archives/3740 访问. 有两种特殊字符.第一种字符可以用一比特0来表示.第 ...
- C#LeetCode刷题之#628-三个数的最大乘积( Maximum Product of Three Numbers)
问题 该文章的最新版本已迁移至个人博客[比特飞],单击链接 https://www.byteflying.com/archives/3726 访问. 给定一个整型数组,在数组中找出由三个数组成的最大乘 ...