Databricks 第7篇:管理Secret
有时,访问数据要求您通过JDBC对外部数据源进行身份验证,可以使用Azure Databricks Secret来存储凭据,并在notebook和job中引用它们,而不是直接在notebook中输入凭据。
要配置一个Secret,需要分三步:
- 创建secret scope,scope name是大小写敏感的。
- 把secret添加到secret scope中,secret name是大小写敏感的。
- 把权限授予secret scope。
一,Secret Scope简介
Secret Scope是Secret的集合,每一个Secret是由name唯一确定的。每一个Databricks 的workspace最多创建100个Secret Scope。Azure 支持两种类型的Secret Scope:Azure Key Vault-backed 和 Databricks-backed。
1,基于Azure Key Vault的Secret Scope
要引用存储在Azure Key Vault中的Secret,可以创建基于Azure Key Vault的Secret Scope,基于Azure Key Valut的Secret Scope对于Key Valut来说是只读的。 本文重点介绍基于Azure Key Valut的Secret Scope。
2,基于Databricks的Secret Scope
基于Databricks的Secret Scope存储在由Azure Databricks拥有和管理的加密数据库中,Secret Scope的name在工作空间中必须唯一,必须包含字母数字字符,破折号,下划线和句点,并且不得超过128个字符。名称被认为是不敏感的,并且工作空间中的所有用户都可以读取。
二,创建基于Azure Key Vault的Secret Scope
使用 Azure Portal UI创建Azure Key Vault-backed 的 secret scope。首先,在创建该类型的Secret Scope之前,确保对Azure Key Valut实例具有Contributor权限。
打开网页“https://<databricks-instance>#secrets/createScope”,这个URL是大小写敏感的,注意URL中的“createScope”,其中的“Scope”首字母必须是大写的。
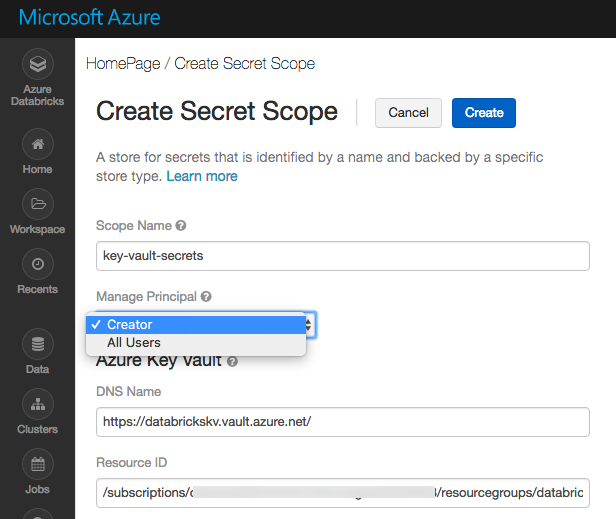
主要的配置选项:
- Scope Name:指定Secret Scope的name,该名称是大小写敏感的。
- Manage Principal:用于定义该Secret Scope的Manage Principal(拥有管理权限的安全主体),选项All Users表示所有的用户都有MANAGE权限,选项Creator表示只有Secret Scope的创建者拥有MANAGE权限。MANAGE权限拥有对Secret Scope的读写权限,推荐选项是Creator,把MANAGE权限只授权给Creator。但是,用户的账户必须具有Azure Databricks Premium Plan ,才可以选择Creator。
- DNS Name:是Valut URI,从Key Valut的Properties面板中可以查看到。
- Resource ID:从Azure Key Valut的属性面板中可以查看到Resource ID。
三,个人访问Token
如果要访问Databricks REST API,可以使用Databricks personal access tokens来进行权限验证。
点击Databricks 工作区右上角的user profile icon

点击“User Settings”,进入到“User Settings”页面,在该页面中点击“Generage New Token”生成新的Token。

注意:要把Token保存起来,再次进入该页面,Token不再可见。
四:配置Databricks CLI
使用Databricks CLI 命令来验证Secret Scope是否创建成功。
Step1:安装Databricks CLI
- pip install databricks-cli
Step2:配置验证信息
输入Databricks Host,并输入生成的个人访问Token
- databricks configure --token
Step3:查看Secret Scope列表
- databricks secrets list-scopes
参考稳定:
Authentication using Azure Databricks personal access tokens
Databricks 第7篇:管理Secret的更多相关文章
- Databricks 第8篇:把Azure Data Lake Storage Gen2 (ADLS Gen 2)挂载到DBFS
DBFS使用dbutils实现存储服务的装载(mount.挂载),用户可以把Azure Data Lake Storage Gen2和Azure Blob Storage 账户装载到DBFS中.mou ...
- WPF 精修篇 管理资源字典
原文:WPF 精修篇 管理资源字典 样式太多 每个界面可能需要全局的样式 有没有肯能 WPF 中的样式 像Asp.net中 的CSS一样管理那 有的 有资源字典 BurshDictionary &l ...
- Databricks 第10篇:Job
Job是立即运行或按计划运行notebook或JAR的一种方法,运行notebook的另一种方法是在Notebook UI中以交互方式运行. 一,使用UI来创建Job 点击"Jobs&quo ...
- Databricks 第5篇:Databricks文件系统(DBFS)
Databricks 文件系统 (DBFS,Databricks File System) 是一个装载到 Azure Databricks 工作区的分布式文件系统,可以在 Azure Databric ...
- Databricks 第6篇:Spark SQL 维护数据库和表
Spark SQL 表的命名方式是db_name.table_name,只有数据库名称和数据表名称.如果没有指定db_name而直接引用table_name,实际上是引用default 数据库下的表. ...
- Databricks 第9篇:Spark SQL 基础(数据类型、NULL语义)
Spark SQL 支持多种数据类型,并兼容Python.Scala等语言的数据类型. 一,Spark SQL支持的数据类型 整数系列: BYTE, TINYINT:表示1B的有符号整数 SHORT, ...
- Databricks 第11篇:Spark SQL 查询(行转列、列转行、Lateral View、排序)
本文分享在Azure Databricks中如何实现行转列和列转行. 一,行转列 在分组中,把每个分组中的某一列的数据连接在一起: collect_list:把一个分组中的列合成为数组,数据不去重,格 ...
- MySQL-第十二篇管理结果集
1.ResultSet 2.可更新的结果集,使用ResultSet的updateRow()方法.
- Databricks 第四篇:分组统计和窗口
对数据分析时,通常需要对数据进行分组,并对每个分组进行聚合运算.在一定意义上,窗口也是一种分组统计的方法. 分组数据 DataFrame.groupBy()返回的是GroupedData类,可以对分组 ...
随机推荐
- Unity2D 人物移动切换人物图片
勾选Constraints_freeze Rotation_z轴锁定,防止碰撞偏移. public float moveSpeed = 3f;//定义移动速度 priv ...
- 牛客挑战赛46 C
题目链接: 排列 考虑\(dp\),我们思考如何设计状态 将第i个数插入i-1个数中,我们考虑会新增多少个超级逆序对 假设将\(i\)插入后\(i\)的位置为\(l\),\(i-1\)的原来的位置为\ ...
- 关于Java中的String类知识点小总结
Java中的String类知识点 前言 在 Java 中字符串属于对象,Java 提供了 String 类来创建和操作字符串. 如何创建字符串 最简单的方式 String str = "he ...
- python 无损压缩照片,支持批量压缩,支持保留照片信息
由于云盘空间有限,照片尺寸也是很大,所以写个Python程序压缩一下照片,腾出一些云盘空间 1.批量压缩照片 新建 photo_compress.py 代码如下 1 # -*- coding: utf ...
- 2020 .NET 开发者峰会顺利在苏州落幕,相关数据很喜人以及线上直播回看汇总
在2019年上海中国.NET开发者大会的基础上,2020年12月19-20日 继续以"开源.共享.创新" 为主题的第二届中国 .NET 开发者峰会(.NET Conf China ...
- 如何查看打印机的IP地址和MAC地址
1. 打开控制面板,选择设备和打印机: 2. 选中打印机,右键单机,选择打印机 "属性": 3. 选择web服务,可以直接查看打印机的IP地址或MAC地址,如下图所示: 4. ...
- Redis 设计与实现:Redis 对象
本文的分析都是基于 Redis 6.0 版本源码 redis 6.0 源码:https://github.com/redis/redis/tree/6.0 在 Redis 中,有五大数据类型,都统一封 ...
- CSS系列 (03):CSS三大特性
层叠性 层叠性指的是样式的优先级,当产生冲突时以优先级高的为准,优先级相同时取后面定义的属性样式. 继承性 继承性指的是子孙元素可以继承父元素的属性. 记录一下开发中常用的继承属性: 字体系列 fon ...
- 解决UE4缓存使C盘膨胀的问题
使用UE4的时候会发现C盘越来越小了,那是因为UE4引擎的缓存文件默认保存在C盘的缘故. 概述 一.出现的问题:UE4的缓存文件会导致C盘膨胀. 二.解决的方式:请严格按照下列步骤来执行.1. 更改U ...
- 超长JVM总结,面试必备
什么是JVM JVM 是可运行 Java 代码的假想计算机 ,包括一套字节码指令集.一组寄存器.一个栈.一个垃圾回收,堆 和 一个存储方法域.JVM 是运行在操作系统之上的,它与硬件没有直接的交互. ...