ElasticSearch极简入门总结
一,目录
安装es
项目添加maven依赖
es客户端组件注入到spring容器中
es与mysql表结构对比
索引的删除创建
文档的crud
es能快速搜索的核心-倒排索引
基于倒排索引的精确搜索、全文搜索(重点)
es集群
二,二,安装ES环境(安装完成后,开启ES,默认端口9200能访问到,说明成功了)
安装文章
三,Java项目中添加ES的maven依赖
1.<dependency>
2. <groupId>org.elasticsearch.client</groupId>
3. <artifactId>elasticsearch-rest-high-level-client</artifactId>
4. <version>7.10.2</version>
</dependency>
四,四,将ES客户端组件注入到spring容器中(客户端组件RestHighLevelClient,其封装了操作es的crud方法,底层原理就是模拟各种es需要的请求)
1.package com.shuang.config;
2.
3.import org.apache.http.HttpHost;
4.import org.elasticsearch.client.RestClient;
5.import org.elasticsearch.client.RestHighLevelClient;
6.import org.springframework.context.annotation.Bean;
7.import org.springframework.context.annotation.Configuration;
8.
9.@Configuration //xml文件-bean
10.public class ElasticSearchClientConfig {
11.
12. @Bean
13. public RestHighLevelClient restHighLevelClient(){
14. RestHighLevelClient client = new RestHighLevelClient(
15. RestClient.builder(
16. //多个集群,就new多个
17. new HttpHost("localhost", 9200, "http")));
18. return client;
19. }
20.}
五,到这里,springboot整合ES就好了。相较于springboot操作mysql需要jdbc支持,ES直接一步封装到位,后期可以直接使用。
六,在进行crud前,我们先对比一下es与mysql。看完后,我们正式开始crue

七,索引的操作(对应的mysql就是数据库的创建、删除)在kibana中可以傻瓜式的创建索引与删除索引
1)java代码创建索引
package com.shuang;
@SpringBootTest
class DemoApplicationTests {
@Autowired
private RestHighLevelClient restHighLevelClient;
@Test
void contextLoads() throws IOException {
//1,创建索引表
CreateIndexRequest request=new CreateIndexRequest("shuangbao");
//2,客户端执行请求 IndicesClient,请求后获得响应
CreateIndexResponse createIndexResponse=
restHighLevelClient.indices().create(request, RequestOptions.DEFAULT);
System.out.println(createIndexResponse);
}
}
2)删除索引
@Test
void testDeleteIndex() throws IOException {
DeleteIndexRequest request=new DeleteIndexRequest();
AcknowledgedResponse delete =restHighLevelClient.indices().delete(request,RequestOptions.DEFAULT);
System.out.println(delete);
}
八,操作文档(es7中”类型”我们一般都是设置为默认的_doc,es8中将移除”类型”,相当于mysql的表没有了),文档相当于mysql中的一条记录。es中插入一条json数据,如果没有指明文档id,就会随机生成一个
先新建索引,默认类型为_doc,建立文档结构json格式的属性有string类型的name,integer类型的age。
1.PUT /shuang_index1
2. {
3. "settings": {
4. "index": {
5. "number_of_replicas": "1",
6. "number_of_shards": "5" }
7. },
8. "mappings": {
9. "test_type": {
10. "properties": {
11. "name": {
12. "type": "string",
13. },
14. "age": {
15. "type": "integer"
16. }
17. }
18. }
19. }
20. }
插入一条文档id为1的数据
PUT shuang_index2/_doc/1
{
"name":"shuang1",
"age":"1"
}
1)获取文档的信息,这里我们获取文档id为1的信息
//获取文档的信息
@Test
void testIsGetDocument() throws IOException {
GetRequest getRequest=new GetRequest("shuang_index1","1");
//不获取返回的_source的上下文
GetResponse getResponse=restHighLevelClient.get(getRequest,RequestOptions.DEFAULT);
System.out.println(getResponse.getSourceAsString());//打印文档的数据_source
System.out.println(getResponse); //打印文档id为1的完整返回信息
}
{"age":1,"name":"shuang1"}
"_index":"shuang_index1","_type":"_doc","_id":"1","_version":1,"_seq_no":4,"_primary_term":1,"found":true,"_source":{"age":1,"name":"shuang1"}}
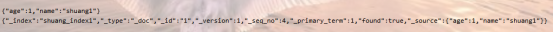
2)插入数据(数据来源可以是其他地方)
1.@Test
2.void testBulkRequest() throws IOException {
3. BulkRequest bulkRequest=new BulkRequest();
4. bulkRequest.timeout("10s");
5.
6. ArrayList<User> userList=new ArrayList<>();
7. userList.add(new User("jiang1",1));
8. userList.add(new User("jiang2",2));
9. userList.add(new User("jiang3",3));
10. userList.add(new User("jiang4",4));
11. userList.add(new User("jiang5",5));
12. userList.add(new User("jiang6",6));
13. userList.add(new User("jiang7",7));
14. userList.add(new User("jiang8",8));
15.
16. //批处理请求
17. for(int i=0;i<userList.size();i++){
18. //批量更新和删除,就在这里修改对应的请求就可以了
19. bulkRequest.add(
20. new IndexRequest("shuang_index1")
21. .id(""+(i+1))
22. .source(JSON.toJSONString(userList.get(i)),XContentType.JSON));
23.
24. }
25. BulkResponse bulkResponse=restHighLevelClient.bulk(bulkRequest,RequestOptions.DEFAULT);
26.
27. System.out.println(bulkResponse.hasFailures());//是否失败,返回false代表成功
28.}
3)删除文档信息
1.@Test
2.void testDeleteRequest() throws IOException {
3. DeleteRequest request=new DeleteRequest("shuang_index1","1");
4. request.timeout("1s");
5.
6. DeleteResponse deleteResponse=restHighLevelClient.delete(request,RequestOptions.DEFAULT);
7. System.out.println(deleteResponse.status());
8.
9.}
4)更新文档信息
1.@Test
2. void testUpdateRequest() throws IOException {
3. UpdateRequest updateRequest=new UpdateRequest("shuang_index1","1");
4. updateRequest.timeout("1s");
5.
6. User user=new User("爽爽爽",18);
7. updateRequest.doc(JSON.toJSONString(user),XContentType.JSON);
8.
9. UpdateResponse updateResponse=restHighLevelClient.update(updateRequest,RequestOptions.DEFAULT);
10.
11. System.out.println(updateResponse.status());
12. }
九,倒排索引
前面介绍了文档的查找,是普通的查找get方式的,需要指定_index、_type、_id。也就是根据id从正排索引中获取内容,确定唯一文档。
但搜索search方式需要一种更复杂的模型,因为不知道查询会命中哪些文档。采用倒排索引可以满足复杂的搜索过程。

搜索也分精确值搜索和全文搜索,对数据建立索引和执行搜索的原理如下图所示:
十,查询和全文查询
Term(精确,不会被分词器解析,keyword类型的字段也不会被分词器解析)和match(全文,会被分词器解析)是两个常用的基于倒排索引的搜索类型。他们对应的java类主要有 TermQueryBuilder和MatchQueryBuilder。
精确搜索(在shuang_index1索引中,name字段为shuang1的文档)
1.@Test
2. void testSearch() throws IOException {
3. SearchRequest searchRequest=new SearchRequest("shuang_index1");
4. //构建搜索条件
5. SearchSourceBuilder sourceBuilder=new SearchSourceBuilder();
6.
7. TermQueryBuilder termQueryBuilder=QueryBuilders.termQuery("name","shuang1");
8.
9. sourceBuilder.query(termQueryBuilder);
10. sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
11.
12. searchRequest.source(sourceBuilder);
13.
14. SearchResponse searchResponse=restHighLevelClient.search(searchRequest,RequestOptions.DEFAULT);
15. System.out.println(JSON.toJSONString(searchResponse.getHits()));
16.
17. for(SearchHit documentFields :searchResponse.getHits().getHits()){
18. System.out.println(documentFields.getSourceAsMap());
19. }
20. }
第二个输出是对搜索返回信息进行了提取关键字段。
全文搜索
1)在kibana上新建shuang_index2索引(相当于在navicat上去新建mysql数据库)
一般我们不指定类型(系统会默认为_doc,es7不推荐使用了,es8将会移除类型,相当于mysql没有了表这个结构)。
设置里面的文档字段为name和age,它们类型为string与interger。
1.PUT /shuang_index2
2. {
3. "settings": {
4. "index": {
5. "number_of_replicas": "1", //设置副本数为1
6. "number_of_shards": "5" } //设置分片数为5
7. },
8. "mappings": {
9. "test_type": {
10. "properties": {
11. "name": {
12. "type": "string",
13. },
14. "age": {
15. "type": "integer"
16. }
17. }
18. }
19. }
20. }
2)插入数据(一般我们是从数据仓库批量导入,java代码见上面文档的插入)
Kibana控制台也可以自己手动插入
1.PUT shuang_index2/_doc/5
2.{
3. "name":"shuang e",
4. "age":"5"
5.}
这里shuang_index2为索引、_doc为类型、5代表文档id(大数据环境下,我们一般不指定文档id,系统会随机生成一个文档id,唯一标识该文档)。它们分别对应mysql的数据库、表、行。name和age代表mysql字段中的列属性。文档结构必须为json格式。
3)搭建好索引结构后,我们去用java代码实现一下
(内置分词器先把shuang bao分词为shuang 与 bao ,再去shuang_index2索引中去寻找,文档1、2、3、4、5分别有name=shuang a、b、c、d、e。他们事先也被分词器拆解了,只要有一个与上面对应,就搜索成功,并且会携带一个相似程度score返回)
1.@Test
2.void testSearch() throws IOException {
3. SearchRequest searchRequest=new SearchRequest("shuang_index2");
4. //构建搜索条件
5. SearchSourceBuilder sourceBuilder=new SearchSourceBuilder();
6.
7. MatchQueryBuilder matchQueryBuilder=QueryBuilders.matchQuery("name","shuang bao");
8. sourceBuilder.query(matchQueryBuilder);
9. sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
10.
11. searchRequest.source(sourceBuilder);
12.
13. SearchResponse searchResponse=restHighLevelClient.search(searchRequest,RequestOptions.DEFAULT);
14. System.out.println(searchResponse);
15.
16. for(SearchHit documentFields :searchResponse.getHits().getHits()){
17. System.out.println(documentFields.getSourceAsMap());
18. }
19.}
返回结果:
{"took":770,"timed_out":false,"_shards":{"total":1,"successful":1,"skipped":0,"failed":0},"hits":{"total":{"value":5,"relation":"eq"},"max_score":0.08701137,"hits":[{"_index":"shuang_index2","_type":"_doc","_id":"1","_score":0.08701137,"_source":{"name":"shuang a","age":"1"}},{"_index":"shuang_index2","_type":"_doc","_id":"2","_score":0.08701137,"_source":{"name":"shuang b","age":"2"}},{"_index":"shuang_index2","_type":"_doc","_id":"3","_score":0.08701137,"_source":{"name":"shuang c","age":"3"}},{"_index":"shuang_index2","_type":"_doc","_id":"4","_score":0.08701137,"_source":{"name":"shuang d","age":"4"}},{"_index":"shuang_index2","_type":"_doc","_id":"5","_score":0.08701137,"_source":{"name":"shuang e","age":"5"}}]}}
{name=shuang a, age=1}
{name=shuang b, age=2}
{name=shuang c, age=3}
{name=shuang d, age=4}
{name=shuang e, age=5}
十一,es集群

如图3个es服务构成的集群,索引test分成了5片,一个副本(粗框的),而book一个分片一个副本。保证了如果有一个服务坏了,其他服务也能执行所有工作。
一个搜索请求必须询问请求的索引中所有分片的某个副本来进行匹配。假设一个索引有5个主分片,每个主分片有1个副分片,共10个分片,一次搜索请求会由5个分片来共同完成,它们可能是主分片,也可能是副分片。也就是说,一次搜索请求只会命中所有分片副本中的一个。
ElasticSearch极简入门总结就结束了感谢您的阅读
ElasticSearch极简入门总结的更多相关文章
- Git 极简入门教程学习笔记
Git 极简入门教程 http://rogerdudler.github.io/git-guide/index.zh.html 测试用 https://github.com/xxx/BrnShop. ...
- .Net Core in Docker极简入门(下篇)
Tips:本篇已加入系列文章阅读目录,可点击查看更多相关文章. 目录 前言 开始 Docker-Compose 代码修改 yml file up & down 镜像仓库 最后 前言 上一篇[. ...
- Spring Security极简入门三部曲(上篇)
目录 Spring Security极简入门三部曲(上篇) 写在前面 为什么要用Spring Security 数据库设计 demo时刻 核心代码讲解 小结 Spring Security极简入门三部 ...
- Spring Security极简入门三部曲(中篇)
目录 Spring Security极简入门三部曲(中篇) 验证流程 Authentication接口 过滤器链 AuthenticationProvider接口: demo时刻 代码讲解 小结 Sp ...
- Express + Mongoose 极简入门
今天尝试使用express + mongoose,构建了一个简单的Hello world,实现以下功能: 定义mongodb使用的Schema,一个User 访问/输出Hello world 访问/i ...
- Spring Boot 如何极简入门?
Spring Boot已成为当今最流行的微服务开发框架,本文是如何使用Spring Boot快速开始Web微服务开发的指南,我们将创建一个可运行的包含内嵌Web容器(默认使用的是Tomcat)的可运行 ...
- Nginx 极简入门教程!
上篇文章和大家聊了 Spring Session 实现 Session 共享的问题,有的小伙伴看了后表示对 Nginx 还是很懵,因此有了这篇文章,算是一个 Nginx 扫盲入门吧! 基本介绍 Ngi ...
- 【Java杂货铺】用Security做权限极简入门
原来大多数单体项目都是用的shiro,随着分布式的逐渐普及以及与Spring的天生自然的结合.Spring Security安全框架越受大家的青睐.本文会教你用SpringSecurity设计单项目的 ...
- Svelte 极简入门
弹指之间即可完成. 注意:原文发表于 2017-8-7,随着框架不断演进,部分内容可能已不适用. Svelte 是一种新型框架. 以往我们要引入一个框架或者类库,可以通过在页面上放置 ...
随机推荐
- 一位弱校选手的oi经历
锦瑟无端五十弦,一弦一柱思华年. 这只是一位不知道什么时候就要退役的oier在一节晚自习的时候写的无聊东西 曾经也想好好写一写自己的oi历程,也许会有人看,不过因为自己懒加上文笔差也一直没写,直到昨天 ...
- .NET Core 3.0或3.1 类库项目中引用 Microsoft.AspNetCore.App
本文为原创文章.首发:http://www.zyiz.net/ 在 ASP.NET Core 3.0+ web 项目中已经不需要在 .csproj 中添加对 Microsoft.AspNetCore. ...
- Access 数据库容量问题
1.单个表的最大容量 2G. 2.单个表的最大条数 3.自动编号的最大数 4.数据库的最大容量 5.text备注形式的字段的最大数据量 6.ole对象字段的最大数据量,图片的最大大小 7.文本字段的 ...
- easyui中清空table列表中数据
方法一 var item = $('#filegrid').datagrid('getRows');//获取类表中全部数据if (item) { for (var i = item.length - ...
- springboot项目配置数据库
在pom.xml文件中配置 <!-- mybatis整合springboot起步依赖--> <dependency> <groupId>org.mybatis.sp ...
- react项目中登陆注册验证码的倒计时,页面刷新不会重置
目前很多的网站和app在做登陆注册时都会用到手机验证码,为了防止验证码轰炸,也就是随意的点击验证码,一般我们需要对获取验证码进行一些限制,最常用到的是在规定时间内不得重复发送. 实现倒计时很简单,可以 ...
- java的注释方法
1.单行注释 //注释的内容 2.多行注释 /....../ 3./**......*/,这种方式和第二种方式相似.这种格式是为了便于javadoc程序自动生成文档.
- “You may need an appropriate loader to handle this file type”
这里不能为空!!!!!!!!!!!!!!!!!!!!
- vscode 安装与配置
vscode 安装与配置 安装 安装 vscode 从官网 [https://code.visualstudio.com/Download] 下载速度奇慢,可以找到下载的网址,如下图所示,将其中红色框 ...
- idea中maven的安装与配置
说明:类似maven安装和配置的帖子在网上有很多,本人也有做过参照,但是有些帖子的步骤跳跃性比较大,故此,本人整理了一下,给大家做个参考. 一.下载安装 一般都是在官网进行下载 https://mav ...