Redis学习笔记(八)——持久化
一、介绍
Redis的所有的数据都存在内存中,然后不定期的通过异步方式保存到磁盘上(这称为"半持久化模式");也可以把每一次数据变化都写入到一个append only file(aof)里面(这称为"全持久化模式")。
由于Redis的数据都是存放在内存中,如果没有配置持久化,Redis重启后数据就全丢失了,于是许亚萍开启Redis的持久化功能,将数据保存到磁盘上,当Redis重启后,可以从磁盘中恢复数据。Redis提供两种方式进行持久化,一种是RDB持久化(原理是将Redis在内存中的数据记录定时dump到磁盘上的RDB持久化;另一个中是AOF(append only file)持久化(原理是将Redis的操作日志以追加的方式写入文件)。
- 两者的区别:
1、RDB持久化是指在指定的时间间隔内将内存中的数据快照写入磁盘,实际操作过程是fork一个子进程,先将数据集写入临时文件,写入成功后,在替换之前的文件,用二进制压缩存储。

2、AOF持久化日志的形式记录服务器所处理的每一个写、删除操作,查询操作不回记录,以文本的方式记录,可以打开文件看到详细的操作记录。

- 两者的优缺点:
RDB方式:
优点:
1、一旦采用该方式,那么你的整个Redis数据库将只包含一个文件,这对于文件备份而言是非常完美的。比如,你可能打算每个小时归档一次最近24小时的数据,同时还要每天归档一次最近30天的数据。通过这样的备份策略,一旦系统出现灾难性故障,我们可以非常简单的进行恢复。
2、对于灾难恢复而言,RDB是非常不错的选择。因为我们可以非常轻松的将一个单独的文件压缩后再转移到其他存储介质上。
3、性能最大优化;对于Redis的服务进程而言,在开始持久化时,它唯一需要做的只是fork出子进程,之后再由子进程完成这些持久化工作,这样就可以极大的避免服务进程执行IO操作了。
4、相比于AOF机制,如果数据集很大,RDB的启动效率会更高。
缺点:
1、如果你想保证数据的高可用性,即最大限度的避免数据丢失,那么RDB将不是一个很好的选择。因为系统一旦再定时持久化之前出现宕机现象,此前没有来得及写入磁盘的数据都将丢失。
2、由于RDB是通过fork子进程来协助完成数据持久化工作的,因此,如果数据集较大时,可能会导致整个服务器停止服务几百毫秒,甚至几秒钟。
AOF方式:
优点:
1、该机制可以带来更高的数据安全性,即数据持久性。Redis中提供了三种同步策略,即每秒同步、每修改同步和不同步。事实上,每秒同步也是异步完成的,其效率也非常高,所差的是一旦系统出现宕机现象,那么这一秒钟之内修改的数据将会丢失。而每修改同步,我们可以将其视为同步持久化,即每次发生的数据变化都立即记录到磁盘中,可以预见,这种方式在效率上是最低的。至于无同步,就是数据不会进行持久化。
2、由于该机制对日志文件的写入操作采用的是append模式,因此到写入过程中即使出现宕机现象,也不会破坏日志文件已经存在的内容。然而如果我们本次操作只是写入了一半数据就出现了系统崩溃问题,不用担心,在Redis下一次启动之前,我们可以通过redis-check-aof工具来帮助我们解决数数据一致性的问题。
3、如果日志过大,Redis可以自动启用rewirte机制。即Redis以append模式不断的将修改数据写入到老的磁盘文件中,同时Redis还会创建一个新的文件用于记录此期间有哪些修改命令被执行。因此在进行rewirte切换时可以更好的保证数据安全性。
4、AOF包含一个格式清晰、易于理解的日志文件用于记录所有的修改操作。事实上,我们也可以通过该文件完成数据的重建。
缺点:
1、对于相同数量的数据集而言,AOF文件通常要大于RDB文件。RDB在恢复大数据集时的速度比AOF恢复速度要快。
2、根据同步策略的不同,AOF在运行效率上往往会慢于RDB。总之,每秒同步策略的效率是比较高的,同步禁用策略的效率和RDB一样高效。
两者的选择标准,就是看系统是愿意牺牲一些性能,换取更高的缓存一致性(AOF),还是愿意写操作频率的时候,不启用备份来换取更高的性能,待手动save的时候,再做备份(RDB)。
二、实现
1、RDB方式
1.1、配置redis.conf
在redis目录下,打开redis.conf配置文件,命令:vi redis.conf

找到红圈的配置部分
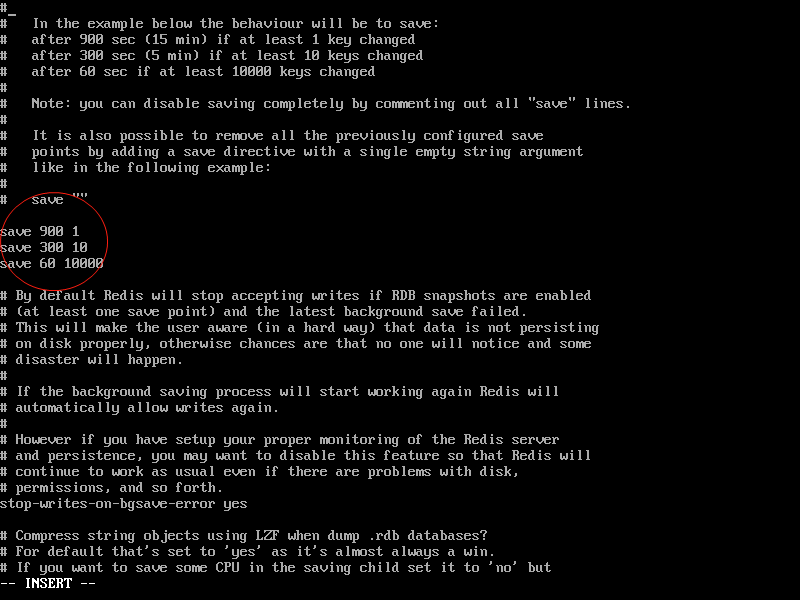
这里的save 900 1 表示:每900秒内至少有一个key发生变化,就持久化;
save 300 10 表示:每300秒内至少有10个key发生变化,就持久化;
save 60 100 表示:每60秒内至少有100个key发生变化,就持久化;
再往下拉:

这里有个dbfilename配置是保存持久化的文件名,默认是dump.rdb
再往下拉:

dir ./ 表示文件存储路径是当前路径(你也可以选择修改);
我们退出,查看redis目录
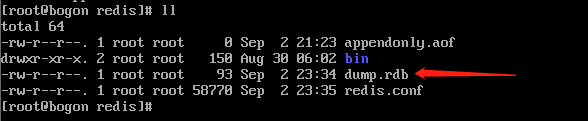
当前路径里确实有dump.rdb这个文件。
1.2、RDB备份和恢复数据
假如我们遇到断电、宕机等现象,我们需要恢复数据,下面来模拟下:
我们先重置下数据,把redis服务先关掉

删除dump.rdb文件

启动redis,进入客户端

这时启动,是没有数据的
我们新增几个key,然后shutdown save 保存退出


假如这个时候,我们重启redis,这时候启动过程会进行rdb check验证,
然后加载redis目录下的rdb文件,加载数据;我们验证下:
数据加载出来了
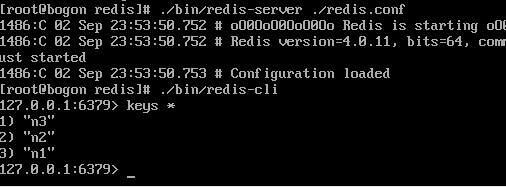
这时我们把redis下的rdb文件剪切到其他地方去,然后再重启试下
剪切文件
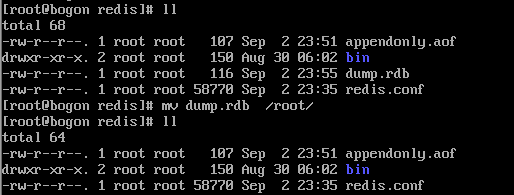
把rdb文件剪切后,发现数据不存在了

如果要恢复数据的话,我们需要把刚才剪切掉的rdb文件拷贝回redis目录下即可
复制rdb文件

启动服务,这时候数据就有了,这就是恢复过程
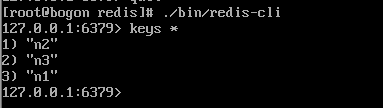
2、AOF方式
2.1、配置redis.conf
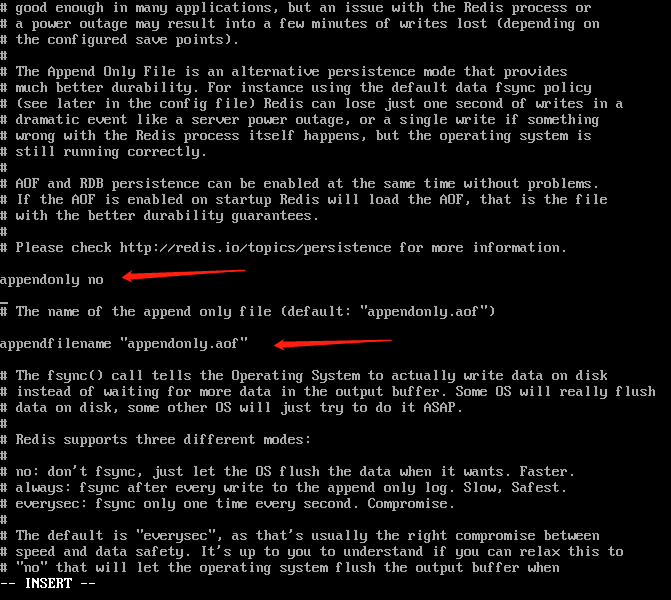
appendonly no:默认关闭AOF方式,我们修改成yes,就开启
appendfilename "appendonly.aof":是默认的AOF文件名
再往下拉:

这里是三种同步策略:
always:是只要发生修改,立即同步(推荐使用,安全性最高)
everysec:是每秒同步一次
no:是不同步
我们修改成always
然后保存退出。
启动Redis,随便加几个key

退出来后,redis目录下就多了一个appendonly.aof文件。
2.2、数据备份和恢复
我们先把原有数据的appendonly.aof文件剪切到别的目录,启动reids,又生成一个新的aof文件,但是查看数据的时候是空的
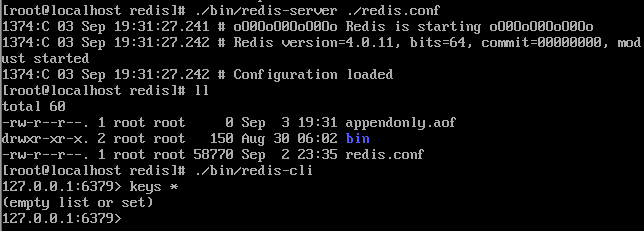
退出,把原AOF文件拷贝回来

启动redis,这时数据已经恢复过来了

三、常用配置(上面也有讲过)
1、RDB持久化配置
Redis会将数据集的快照dump到dump.rdb文件中。此外我们也可以通过配置文件修改Redis服务器dump快照的频率,打开redis.conf文件之后,搜索save,可以看到下面的配置信息:
save 900 1 #在900秒(15分钟)之后,如果至少有1个key发生变化,则dump内存快照。
save 300 10 #在300秒(5分钟)之后,如果至少有10个key发生变化,则dump内存快照。
save 60 10000 #在60秒(1分钟)之后,如果至少有10000个key发生变化,则dump内存快照。
2、AOF持久化配置
在Redis的配置文件(redis.conf)中存在三种同步方式,它们分别是:
appendfsync always #每次有数据修改发生时都会写入AOF文件。
appendfsync everysec #每秒钟同步一次,该策略为AOF的缺省策略。
appendfsync no #从不同步。高效但是数据不会被持久化。
Redis学习笔记(八)——持久化的更多相关文章
- Redis学习笔记八:集群模式
作者:Grey 原文地址:Redis学习笔记八:集群模式 前面提到的Redis学习笔记七:主从复制和哨兵只能解决Redis的单点压力大和单点故障问题,接下来要讲的Redis Cluster模式,主要是 ...
- Redis学习笔记9--Redis持久化
redis是一个支持持久化的内存数据库,也就是说redis需要经常将内存中的数据同步到磁盘来保证持久化.redis支持四种持久化方式,一是 Snapshotting(快照)也是默认方式:二是Appen ...
- Redis学习笔记(一)-持久化
一.RDB持久方式 RDB持久化是把当前进程的数据已快照的形式保存到硬盘的过程. 触发方式: 1.手动触发命令:save和bgsave save:阻塞式,内存较大的实例在执行过程中会造成长时间的阻塞, ...
- Redis学习笔记八:独立功能之二进制位数组
Redis 提供了 setbit.getbit.bitcount.bitop 四个命令用于处理二进制位数组. setbit 命令用于为位数组指定偏移量上的二进制位设置值,偏移量从 0 开始计数. ge ...
- Redis学习笔记六:持久化实验(AOF,RDB)
作者:Grey 原文地址:Redis学习笔记六:持久化实验(AOF,RDB) Redis几种持久化方案介绍和对比 AOF方式:https://blog.csdn.net/ctwctw/article/ ...
- Redis学习笔记(二) Redis 数据类型
Redis 支持五种数据类型:string(字符串).list(列表).hash(哈希).set(集合)和 zset(有序集合),接下来我们讲解分别讲解一下这五种类型的的使用. String(字符串) ...
- redis 学习笔记(6)-cluster集群搭建
上次写redis的学习笔记还是2014年,一转眼已经快2年过去了,在段时间里,redis最大的变化之一就是cluster功能的正式发布,以前要搞redis集群,得借助一致性hash来自己搞shardi ...
- Redis学习笔记4-Redis配置详解
在Redis中直接启动redis-server服务时, 采用的是默认的配置文件.采用redis-server xxx.conf 这样的方式可以按照指定的配置文件来运行Redis服务.按照本Redi ...
- Redis学习笔记之ABC
Redis学习笔记之ABC Redis命令速查 官方帮助文档 中文版本1 中文版本2(反应速度比较慢) 基本操作 字符串操作 set key value get key 哈希 HMSET user:1 ...
- Redis学习笔记(1)——Redis简介
一.Redis是什么? Remote Dictionary Server(Redis) 是一个开源的使用ANSI C语言编写.遵守BSD协议.支持网络.可基于内存亦可持久化的日志型.Key-Value ...
随机推荐
- 滴滴开源AgileTC:敏捷测试用例管理平台
桔妹导读:AgileTC是一套敏捷的测试用例管理平台,支持测试用例管理.执行计划管理.进度计算.多人实时协同等能力,方便测试人员对用例进行管理和沉淀.产品以脑图方式编辑可快速上手,用例关联需求形成流 ...
- 手把手教你ASP.NET Core:使用Entity Framework Core进行增删改查
新建表Todo,如图 添加模型类 在"解决方案资源管理器"中,右键单击项目. 选择"添加" > "新建文件夹". 将文件夹命名为 Mo ...
- .Net Core 2.2 存取Cookie
第一步(注释代码):注释Startup.cs中 ConfigureServices 函数中的 options.CheckConsentNeeded = context => true; 第二步 ...
- 对offsetof、 container_of宏和结构体的理解
offsetof 宏 #include<stdio.h> #define offsetoff(type, member) ((int)&((type*)0)->me ...
- Vue路由Hash模式分析
Vue路由Hash模式分析 Vue-router是Vue的核心组件,主要是作为Vue的路由管理器,Vue-router默认hash模式,即使用URL的Hash来模拟一个完整的URL,当URL改变时页面 ...
- Linux设置主机名称与host映射
uname -n :查看host对应的域名 2.在 /etc/hostname 删除原来的重新配置需要的域名 3.在 /etc/hosts 中添加域名和映射ip 4.重启系统 5.其他主机 ...
- python-格式化(%,format,f-string)输出+输入
1-格式化输出: % 1.print('我的姓名是%s,身高%s cm'%(name,height)) 2.%s -str() ; %d–十进制3.传入值的时候一定是个元组,不是列表4.当指定长度时: ...
- API可视化管理平台YApi
Yapi是什么 YApi 是高效.易用.功能强大的 api 管理平台,旨在为开发.产品.测试人员提供更优雅的接口管理服务.可以帮助开发者轻松创建.发布.维护 API,YApi 还为用户提供了优秀的交互 ...
- C# excel文件导入导出
欢迎关注微信公众号 C#编程大全 这里有更多入门级实例帮你快速成长 在C#交流群里,看到很多小伙伴在excel数据导入导出到C#界面上存在疑惑,所以今天专门做了这个主题,希望大家有所收获! 环境:wi ...
- nginx的脚本引擎(二)rewrite
其实rewrite指令和上一篇说的if/set/return/break之类的没多大差别,但是rewrite用起来相对复杂,我就把他单独放到了这里.想要弄懂nginx的脚本引擎需要先明白处理reque ...