一、使用 BeautifulSoup抓取网页信息信息
一、解析网页信息
from bs4 import BeautifulSoup
with open('C:/Users/michael/Desktop/Plan-for-combating-master/week1/1_2/1_2code_of_video/web/new_index.html','r') as web_data:
Soup = BeautifulSoup(web_data,'lxml')
print(Soup)

二、获取要爬取元素的位置
浏览器右键-》审查元素-》copy-》seletor
"""
body > div.main-content > ul > li:nth-child(1) > div.article-info > h3 > a
body > div.main-content > ul > li:nth-child(1) > div.article-info > p.meta-info > span:nth-child(2)
body > div.main-content > ul > li:nth-child(1) > div.article-info > p.description
body > div.main-content > ul > li:nth-child(1) > div.rate > span
body > div.main-content > ul > li:nth-child(1) > img
"""
images = Soup.select('body > div.main-content > ul > li:nth-child(1) > img')
print(images)

修改成:
images = Soup.select('body > div.main-content > ul > li:nth-of-type(1) > img')
print(images)

这时候能获取到一个
images = Soup.select('body > div.main-content > ul > li > img')
print(images)

获取到了所有图片
titles = Soup.select('body > div.main-content > ul > li > div.article-info > h3 > a')
descs = Soup.select('body > div.main-content > ul > li > div.article-info > p.description')
rates = Soup.select(' body > div.main-content > ul > li > div.rate > span')
cates = Soup.select(' body > div.main-content > ul > li > div.article-info > p.meta-info > span')
print(images,titles,descs,rates,cates,sep='\n-----------\n')

获取到了其他信息
三、获取标签中的文本信息(get_text())及属性(get())
for title in titles:
print(title.get_text())
封装成字典:
for title,image,desc,rate,cate in zip(titles,images,descs,rates,cates):
data = {
'title':title.get_text(),
'rate':rate.get_text(),
'desc':desc.get_text(),
'cate':cate.get_text(),
'image':image.get('src')
}
print(data)

因为cates有多个属性,需要上升到父节点
cates = Soup.select(' body > div.main-content > ul > li > div.article-info > p.meta-info')
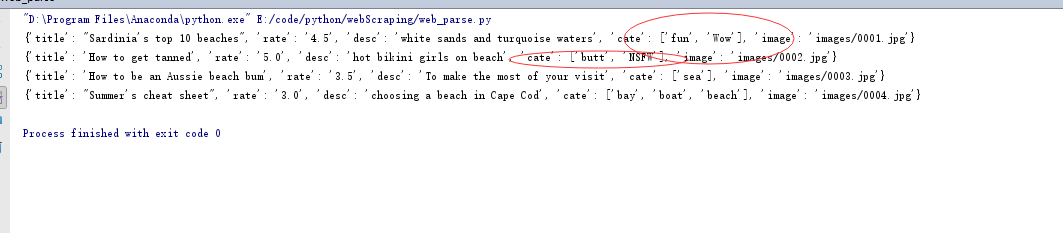
for title,image,desc,rate,cate in zip(titles,images,descs,rates,cates):
data = {
'title':title.get_text(),
'rate':rate.get_text(),
'desc':desc.get_text(),
'cate':list(cate.stripped_strings),
'image':image.get('src')
}
print(data)
#找到评分大于3的文章
for i in info:
if float(i['rate'])>3:
print(i['title'],i['cate'])

四、完整代码
from bs4 import BeautifulSoup
info =[]
with open('C:/Users/michael/Desktop/Plan-for-combating-master/week1/1_2/1_2code_of_video/web/new_index.html','r') as web_data:
Soup = BeautifulSoup(web_data,'lxml')
# print(Soup)
"""
body > div.main-content > ul > li:nth-child(1) > div.article-info > h3 > a
body > div.main-content > ul > li:nth-child(1) > div.article-info > p.meta-info > span:nth-child(2)
body > div.main-content > ul > li:nth-child(1) > div.article-info > p.description
body > div.main-content > ul > li:nth-child(1) > div.rate > span
body > div.main-content > ul > li:nth-child(1) > img
"""
images = Soup.select('body > div.main-content > ul > li > img') titles = Soup.select('body > div.main-content > ul > li > div.article-info > h3 > a')
descs = Soup.select('body > div.main-content > ul > li > div.article-info > p.description')
rates = Soup.select(' body > div.main-content > ul > li > div.rate > span')
cates = Soup.select(' body > div.main-content > ul > li > div.article-info > p.meta-info')
# print(images,titles,descs,rates,cates,sep='\n-----------\n') for title,image,desc,rate,cate in zip(titles,images,descs,rates,cates):
data = {
'title':title.get_text(),
'rate':rate.get_text(),
'desc':desc.get_text(),
'cate':list(cate.stripped_strings),
'image':image.get('src')
}
#添加到列表中
info.append(data)
#找到评分大于3的文章
for i in info:
if float(i['rate'])>3:
print(i['title'],i['cate'])
一、使用 BeautifulSoup抓取网页信息信息的更多相关文章
- Python 抓取网页并提取信息(程序详解)
最近因项目需要用到python处理网页,因此学习相关知识.下面程序使用python抓取网页并提取信息,具体内容如下: #---------------------------------------- ...
- HttpClient+Jsoup 抓取网页信息(网易贵金属为例)
废话不多说直接讲讲今天要做的事. 利用HttpClient和Jsoup技术抓取网页信息.HttpClient是支持HTTP协议的客户端编程工具包,并且它支持HTTP协议. jsoup 是一款基于 Ja ...
- python爬虫抓取哈尔滨天气信息(静态爬虫)
python 爬虫 爬取哈尔滨天气信息 - http://www.weather.com.cn/weather/101050101.shtml 环境: windows7 python3.4(pip i ...
- python写的爬虫工具,抓取行政村的信息并写入到hbase里
python的版本是2.7.10,使用了两个第三方模块bs4和happybase,可以通过pip直接安装. 1.logger利用python自带的logging模块配置了一个简单的日志输出 2.get ...
- Java广度优先爬虫示例(抓取复旦新闻信息)
一.使用的技术 这个爬虫是近半个月前学习爬虫技术的一个小例子,比较简单,怕时间久了会忘,这里简单总结一下.主要用到的外部Jar包有HttpClient4.3.4,HtmlParser2.1,使用的开发 ...
- Python爬虫实战---抓取图书馆借阅信息
Python爬虫实战---抓取图书馆借阅信息 原创作品,引用请表明出处:Python爬虫实战---抓取图书馆借阅信息 前段时间在图书馆借了很多书,借得多了就容易忘记每本书的应还日期,老是担心自己会违约 ...
- 教您使用java爬虫gecco抓取JD全部商品信息
gecco爬虫 如果对gecco还没有了解可以参看一下gecco的github首页.gecco爬虫十分的简单易用,JD全部商品信息的抓取9个类就能搞定. JD网站的分析 要抓取JD网站的全部商品信息, ...
- 使用python抓取美团商家信息
抓取美团商家信息 import requests from bs4 import BeautifulSoup import json url = 'http://bj.meituan.com/' ur ...
- 使用selenium webdriver+beautifulsoup+跳转frame,实现模拟点击网页下一页按钮,抓取网页数据
记录一次快速实现的python爬虫,想要抓取中财网数据引擎的新三板板块下面所有股票的公司档案,网址为http://data.cfi.cn/data_ndkA0A1934A1935A1986A1995. ...
随机推荐
- beifen---http://vdisk.weibo.com/s/uhCtnyUhD0Ooc
- WannaCry勒索病毒处理指南
北京时间2017年5月12日晚,勒索软件"WannaCry"感染事件在全球范围内爆发,被攻击者电脑中的文件被加密,被要求支付赎金以解密文件: 1.开机前断网 如果电脑插了网线,则先 ...
- C语言,简单计算器【上】
由于工作需要最近在研究PHP扩展,无可避免的涉及到了C语言.从出了学校以后C语言在实际工作中还没有用到过,所以必须要先进行一点复习工作.个人认为对于熟悉一样东西说最好的方法是上手实践.于是便想起了当时 ...
- ios6.0,程序为横屏,出现闪退
本文转载至 http://blog.csdn.net/huanghuanghbc/article/details/10150355 ios6.0,程序为横屏,出现闪退 *** Terminatin ...
- kbmmw 5 的日志备份功能简介
kbmmw 自从4.8.2 版本里增加了日志管理以后,随着版本升级,增加了很多功能,使用方法也有所改变. 功能也越来越强大. 今天说一下 kbmmw5 里面的日志备份,顺便演示一下新的使用方法. 我们 ...
- EasyDarwin开源流媒体云平台之语音对讲功能设计与实现
本文由EasyDarwin开源团队成员Alex贡献:http://blog.csdn.net/cai6811376/article/details/52006958 EasyDarwin云平台一直在稳 ...
- MongoDB——mongo-connector同步到ES
1.搭建完毕MongoDb复制集环境 2.开始安装 mongo-connector pip install mongo-connector:基于pip命令,不管是linux .window 系统默认有 ...
- jQuery 给div绑定单击事件
说明:这篇随笔介绍的是怎么给div添加单击(click)事件.不再废话 直接看代码 <%@ Page Language="C#" AutoEventWireup=" ...
- AndroidContactsTest.java
以下代码使用ContactManager.apk进行测试 package com.saucelabs.appium; import io.appium.java_client.AppiumDriver ...
- Docker容器的网络连接:
yw1989@ubuntu:~$ ifconfig docker0 Link encap:Ethernet HWaddr 02:42:97:61:42:9f inet addr:172.17.0.1 ...