hadoop(三)HDFS 文件系统
Hadoop 附带了一个名为 HDFS(Hadoop 分布式文件系统)的分布式文件系统,专门 存储超大数据文件,为整个 Hadoop 生态圈提供了基础的存储服务。
本章内容:
1) HDFS 文件系统的特点,以及不适用的场景
2) HDFS 文件系统重点知识点:体系架构和数据读写流程
3) 关于操作 HDFS 文件系统的一些基本用户命令 1.
1.HDFS 特点:
HDFS 专为解决大数据存储问题而产生的,其具备了以下特点:
1) HDFS 文件系统可存储超大文件 每个磁盘都有默认的数据块大小,这是磁盘在对数据进行读和写时要求的最小单位, 文件系统是要构建于磁盘上的,文件系统的也有块的逻辑概念,通常是磁盘块的整数倍, 通常文件系统为几千个字节,而磁盘块一般为 512 个字节。 HDFS 是一种文件系统,自身也有块(block)的概念,其文件块要比普通单一磁 盘上文件系统大的多,默认是 64MB。 HDFS 上的块之所以设计的如此之大,其目的是为了最小化寻址开销。 HDFS 文件的大小可以大于网络中任意一个磁盘的容量,文件的所有块并不需要存 储在一个磁盘上,因此可以利用集群上任意一个磁盘进行存储,由于具备这种分布式存 储的逻辑,所以可以存储超大的文件,通常 G、T、P 级别。
2) 一次写入,多次读取 一个文件经过创建、写入和关闭之后就不需要改变,这个假设简化了数据一致性的 问题,同时提高数据访问的吞吐量。
3) 运行在普通廉价的机器上 Hadoop 的设计对硬件要求低,无需昂贵的高可用性机器上,因为在 HDFS 设计 中充分考虑到了数据的可靠性、安全性和高可用性。
2. 不适用于 HDFS 的场景:
1) 低延迟 HDFS
不适用于实时查询这种对延迟要求高的场景,例如:股票实盘。往往应对低 延迟数据访问场景需要通过数据库访问索引的方案来解决,Hadoop 生态圈中的 Hbase 具有这种随机读、低延迟等特点。
2) 大量小文件
对于 Hadoop 系统,小文件通常定义为远小于 HDFS 的 block size(默认 64MB) 的文件,由于每个文件都会产生各自的 MetaData 元数据,Hadoop 通过 Namenode 来存储这些信息,若小文件过多,容易导致 Namenode 存储出现瓶颈。
3) 多用户更新
为了保证并发性,HDFS 需要一次写入多次读取,目前不支持多用户写入,若要修 改,也是通过追加的方式添加到文件的末尾处,出现太多文件需要更新的情况,Hadoop 是不支持的。 针对有多人写入数据的场景,可以考虑采用 Hbase 的方案。
4) 结构化数据
HDFS 适合存储半结构化和非结构化数据,若有严格的结构化数据存储场景,也可 以考虑采用 Hbase 的方案。
5) 数据量并不大
通常 Hadoop 适用于 TB、PB 数据,若待处理的数据只有几十 GB 的话,不建议 使用 Hadoop,因为没有任何好处。
3. HDFS 体系架构
HDFS 是一个主/从(Master/Slave)体系架构,由于分布式存储的性质,集群拥有两 类节点 NameNode 和 DataNode。
NameNode(名字节点):系统中通常只有一个,中心服务器的角色,管理存储和检索 多个 DataNode 的实际数据所需的所有元数据。
DataNode(数据节点):系统中通常有多个,是文件系统中真正存储数据的地方,在 NameNode 统一调度下进行数据块的创建、删除和复制

图中的 Client 是 HDFS 的客户端,是应用程序可通过该模块与 NameNode 和 DataNode 进行交互,进行文件的读写操作。
4. HDFS 数据块复制
为了系统容错,文件系统会对所有数据块进行副本复制多份,Hadoop 是默认 3 副本 管理。
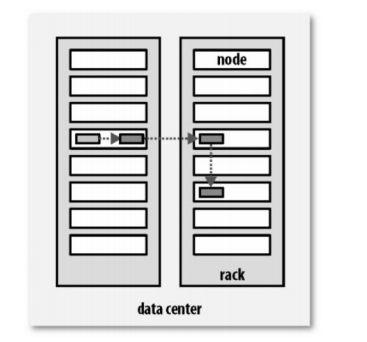
复本管理策略是运行客户端的节点上放一个复本(若客户端运行在集群之外,会随机选 择一个节点),第二个复本会放在与第一个不同且随机另外选择的机架中节点上,第三个复 本与第二个复本放在相同机架,切随机选择另一个节点。所存在其他复本,则放在集群中随 机选择的节点上,不过系统会尽量避免在相同机架上放太多复本。
所有有关块复制的决策统一由 NameNode 负责,NameNode 会周期性地接受集群中 数据节点 DataNode 的心跳和块报告。一个心跳的到达表示这个数据节点是正常的。一个 块报告包括该数据节点上所有块的列表
5. HDFS 读取和写入流程
1) 读文件的过程:
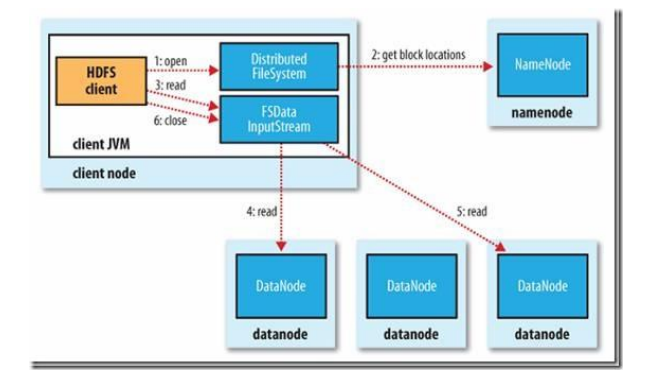
首先 Client 通过 File System 的 Open 函数打开文件,Distributed File System 用 RPC 调用 NameNode 节点,得到文件的数据块信息。对于每一个数据块,NameNode 节点返 回保存数据块的数据节点的地址。Distributed File System 返回 FSDataInputStream 给 客户端,用来读取数据。客户端调用 stream 的 read()函数开始读取数据。DFSInputStream 连接保存此文件第一个数据块的最近的数据节点。DataNode 从数据节点读到客户端 (client),当此数据块读取完毕时,DFSInputStream 关闭和此数据节点的连接,然后连接 此文件下一个数据块的最近的数据节点。当客户端读取完毕数据的时候,调用 FSDataInputStream 的 close 函数。
在读取数据的过程中,如果客户端在与数据节点通信出现错误,则尝试连接包含此数据 块的下一个数据节点。失败的数据节点将被记录,以后不再连接。
2) 写文件的过程:
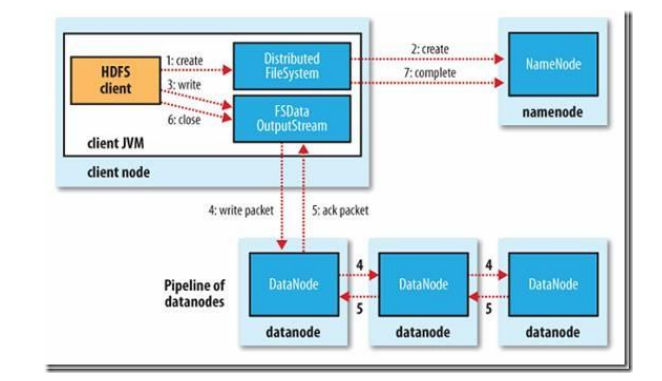
客户端调用 create()来创建文件,Distributed File System 用 RPC 调用 NameNode 节点,在文件系统的命名空间中创建一个新的文件。NameNode 节点首先确定文件原来不 存在,并且客户端有创建文件的权限,然后创建新文件。
Distributed File System 返回 DFSOutputStream,客户端用于写数据。客户端开始 写入数据,DFSOutputStream 将数据分成块,写入 Data Queue。Data Queue 由 Data Streamer 读取,并通知 NameNode 节点分配数据节点,用来存储数据块(每块默认复制 3 块)。分配的数据节点放在一个 Pipeline 里。Data Streamer 将数据块写入 Pipeline 中的第 一个数据节点。第一个数据节点将数据块发送给第二个数据节点。第二个数据节点将数据发 送给第三个数据节点。
DFSOutputStream 为发出去的数据块保存了 Ack Queue,等待 Pipeline 中的数据节 点告知数据已经写入成功。
6. 操作 HDFS 的基本命令
上面已经对hadoop 命令做了别名hdfs
1) 打印文件列表(ls)
标准写法:
hdfs fs -ls hdfs:/ #hdfs: 明确说明是 HDFS 系统路径
简写:
hdfs fs -ls / #默认是 HDFS 系统下的根目录
打印指定子目录:
hdfs fs -ls /package/test/ #HDFS 系统下某个目录
2) 上传文件、目录(put、copyFromLocal)
put 用法:
上传新文件:
hdfs fs -put file:/root/test.txt hdfs:/ #上传本地 test.txt 文件到 HDFS 根目录,HDFS
根目录须无同名文件,否则“File exists”
hdfs fs -put test.txt /test2.txt #上传并重命名文件。
hdfs fs -put test1.txt test2.txt hdfs:/ #一次上传多个文件到 HDFS 路径。
上传文件夹:
hdfs fs -put mypkg /newpkg #上传并重命名了文件夹。
覆盖上传:
hdfs fs -put -f /root/test.txt / #如果 HDFS 目录中有同名文件会被覆盖
copyFromLocal 用法:
上传文件并重命名:
hdfs fs -copyFromLocal file:/test.txt hdfs:/test2.txt
覆盖上传:
hdfs fs -copyFromLocal -f test.txt /test.txt
3) 下载文件、目录(get、copyToLocal)
get 用法:
拷贝文件到本地目录:
hdfs fs -get hdfs:/test.txt file:/root/
拷贝文件并重命名,可以简写:
hdfs fs -get /test.txt /root/test.txt
copyToLocal 用法
拷贝文件到本地目录:
hdfs fs -copyToLocal hdfs:/test.txt file:/root/
拷贝文件并重命名,可以简写:
hdfs fs -copyToLocal /test.txt /root/test.txt
4) 拷贝文件、目录(cp)
从本地到 HDFS,同 put
hdfs fs -cp file:/test.txt hdfs:/test2.txt
从 HDFS 到 HDFS
hdfs fs -cp hdfs:/test.txt hdfs:/test2.txt
hdfs fs -cp /test.txt /test2.txt
5) 移动文件(mv)
hdfs fs -mv hdfs:/test.txt hdfs:/dir/test.txt
hdfs fs -mv /test.txt /dir/test.txt
6) 删除文件、目录(rm)
删除指定文件
hdfs fs -rm /a.txt
删除全部 txt 文件
hdfs fs -rm /*.txt
递归删除全部文件和目录
hdfs fs -rm -R /dir/
7) 读取文件(cat、tail)
hdfs fs -cat /test.txt #以字节码的形式读取
hdfs fs -tail /test.txt
8) 创建空文件(touchz)
hdfs fs - touchz /newfile.txt
9) 创建文件夹(mkdir)
hdfs fs -mkdir /newdir /newdir2 #可以同时创建多个
hdfs fs -mkdir -p /newpkg/newpkg2/newpkg3 #同时创建父级目录
10) 获取逻辑空间文件、目录大小(du)
hdfs fs - du / #显示 HDFS 根目录中各文件和文件夹大小
hdfs fs -du -h / #以最大单位显示 HDFS 根目录中各文件和文件夹大小
hdfs fs -du -s / #仅显示 HDFS 根目录大小。即各文件和文件夹大小之和
hadoop(三)HDFS 文件系统的更多相关文章
- 搭建maven开发环境测试Hadoop组件HDFS文件系统的一些命令
1.PC已经安装Eclipse Software,测试平台windows10及Centos6.8虚拟机 2.新建maven project 3.打开pom.xml,maven工程项目的pom文件加载以 ...
- hadoop(三):hdfs 机架感知
client 向 Active NN 发送写请求时,NN为这些数据分配DN地址,HDFS文件块副本的放置对于系统整体的可靠性和性能有关键性影响.一个简单但非优化的副本放置策略是,把副本分别放在不同机架 ...
- Hadoop点滴-HDFS文件系统
1.HDFS中,目录作为元数据,保存在namenode中,而非datanode中 2.HDFS的文件权限模型与POSIX的权限模式非常相似,使用 r w x 3.HDFS的文件执行权限(X)可以 ...
- Hadoop之HDFS文件系统
概念 HDFS,它是一个文件系统,用于存储文件,通过目录树来定位文件:其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色. HDFS的设计适合一次写入,多次读出的场景,且不 ...
- hadoop中HDFS文件系统 nameNode出现的问题 nameNode无法打开
1,修改core-site.xml文件,先改成localhost,将所有进程关闭stop-all.sh(或者是先关闭所有进程,然后再修改文件),然后重启,在修改core-site.xml文件成ip地址 ...
- Hadoop之HDFS文件系统(二)
HDFS客户端 通过IO流操作HDFS HDFS文件上传 @Test public void putFileToHDFS() throws Exception{ // 1 创建配置信息对象 Confi ...
- hadoop系列二:HDFS文件系统的命令及JAVA客户端API
转载请在页首明显处注明作者与出处 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据的一些内容,如hadoop,spark,storm,机器学习等. 当前使用的hadoop版本为2.6 ...
- Hadoop基础-HDFS分布式文件系统的存储
Hadoop基础-HDFS分布式文件系统的存储 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.HDFS数据块 1>.磁盘中的数据块 每个磁盘都有默认的数据块大小,这个磁盘 ...
- 大数据学习笔记之Hadoop(二):HDFS文件系统
文章目录 一 HDFS概念 1.1 概念 1.2 组成 1.3 HDFS 文件块大小 二 HFDS命令行操作 三 HDFS客户端操作 3.1 eclipse环境准备 3.1.1 jar包准备 3.2 ...
随机推荐
- Ubuntu12.04下YouCompleteMe安装教程(部分)
1.通过源码编译安装VIM 开发中使用的是Ubuntu 12.04 LTS,通过sudo apt-get install vim安装的版本较低,不支持YCM,所以,用源码编译并安装最新的Vim. 卸载 ...
- 线程之sleep(),wait(),yield(),join()等等的方法的区别
操作线程的常用方法大体上有sleep(),join(),yield()(让位),wait(),notify(),notifyAll(),关键字synchronized等等. 由于这些方法功能有些 ...
- HDU 6092 01背包变形
Rikka with Subset Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others ...
- 【File】文件操作(初识文件操作一)
一,初识文件流 看到标题就知道接下来的所有操作对象都是面对文件进行的.那么问题来了.在java中目录是不是也属于文件呢?答案是yes.既然目录也属于文件,那么对于目录跟文件的区分就显现出来了.在接下来 ...
- Python中str、list、numpy分片操作
在Python里,像字符串(str).列表(list).元组(tupple)和这类序列类型都支持切片操作 对对象切片,s是一个字符串,可以通过类似数组索引的方式获取字符串中的字符,同时也可以用s[a: ...
- centos使用--zsh
目录 1 切换到zsh 1.1 查看系统当前的shell 1.2 查看bin下是否有zsh包 1.3 安装zsh包 1.4 切换shell至zsh 2 安装oh-my-zsh 2.1 oh-my-zs ...
- C#开发微信公众平台教程
http://www.cnblogs.com/xishuai/p/3625859.html http://www.cnblogs.com/wuhuacong/p/3614175.html http:/ ...
- 【Scramble String】cpp
题目: Given a string s1, we may represent it as a binary tree by partitioning it to two non-empty subs ...
- MFC深入浅出读书笔记第一部分
最近看侯捷的MFC深入浅出,简单总结一下. 第一章首先就是先了解一下windows程序设计的基础知识,包括win32程序开发基础,什么*.lib,*.h,*.cpp的,程序入口点WinMain函数,窗 ...
- Python+Selenium练习篇之7-利用name定位元素
本文介绍如何通过节点中name的值来定位这个web元素.还是来看百度首页搜索输入框,通过name的值来定位. 相关脚本代码: # coding=utf-8 from selenium import w ...