Serializer序列器
定义Serializer
1. 定义方法
Django REST framework中的Serializer使用类来定义,须继承自rest_framework.serializers.Serializer。
例如,我们已有了一个数据库模型类BookInfo
class BookInfo(models.Model):
btitle = models.CharField(max_length=20, verbose_name='名称')
bpub_date = models.DateField(verbose_name='发布日期', null=True)
bread = models.IntegerField(default=0, verbose_name='阅读量')
bcomment = models.IntegerField(default=0, verbose_name='评论量')
image = models.ImageField(upload_to='booktest', verbose_name='图片', null=True)
我们想为这个模型类提供一个序列化器,可以定义如下:
class BookInfoSerializer(serializers.Serializer):
"""图书数据序列化器"""
id = serializers.IntegerField(label='ID', read_only=True)
btitle = serializers.CharField(label='名称', max_length=20)
bpub_date = serializers.DateField(label='发布日期', required=False)
bread = serializers.IntegerField(label='阅读量', required=False)
bcomment = serializers.IntegerField(label='评论量', required=False)
image = serializers.ImageField(label='图片', required=False)
注意:serializer不是只能为数据库模型类定义,也可以为非数据库模型类的数据定义。serializer是独立于数据库之外的存在。
2. 字段与选项
常用字段类型:

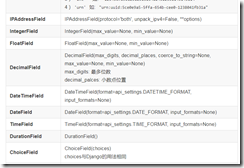


read_only:True表示不允许用户自己上传,只能用于api的输出。如果某个字段设置了read_only=True,那么就不需要进行数据验证,只会在返回时,将这个字段序列化后返回
write_only:与read_only对应;就是用户post过来的数据,后台服务器处理后不会再经过序列化后返回给客户端;最常见的就是我们在使用手机注册的验证码和填写的密码。
3. 创建Serializer对象
Serializer的构造方法为:
Serializer(instance=None, data=empty, **kwarg)
说明:
1)用于序列化时,将模型类对象传入instance参数
2)用于反序列化时,将要被反序列化的数据传入data参数
3)除了instance和data参数外,在构造Serializer对象时,还可通过context参数额外添加数据,如
serializer = AccountSerializer(account, context={'request': request})
通过context参数附加的数据,可以通过Serializer对象的context属性获取。
Serializer使用
我们定义一个测试视图来使用序列化器,如下:
views
def test(request):
return HttpResponse('ok')
urls
urlpatterns = [
url(r'^test/$', views.test)
]
1. 基本使用
def test(request):
book = BookInfo.objects.get(id=5) # 先查询出一个图书对象
serializer = BookInfoSerializer(book) # 构建序列化
print(serializer.data) # 获取序列化数据 {'image': None, 'btitle': '西游记', 'id': 5, 'bread': 10, 'bcomment': 10, 'bpub_date': '1988-01-01'} return HttpResponse('ok')
如果要被序列化的是包含多条数据的查询集QuerySet,可以通过添加many=True参数补充说明
def test(request):
book = BookInfo.objects.all() # 先查询出一个图书对象
serializer = BookInfoSerializer(book, many=True) # 构建序列化
print(serializer.data) # 获取序列化数据 {'image': None, 'btitle': '西游记', 'id': 5, 'bread': 10, 'bcomment': 10, 'bpub_date': '1988-01-01'} return HttpResponse('ok')
2. 关联对象嵌套序列化
如果需要序列化的数据中包含有其他关联对象,则对关联对象数据的序列化需要指明。
例如,在定义英雄数据的序列化器时,外键hbook(即所属的图书)字段如何序列化?
我们先定义HeroInfoSerialzier除外键字段外的其他部分
对于关联字段,可以采用以下几种方式:
1. PrimaryKeyRelatedField
此字段将被序列化为关联对象的主键。
hbook = serializers.PrimaryKeyRelatedField(label='图书', read_only=True)
或
hbook = serializers.PrimaryKeyRelatedField(label='图书', queryset=BookInfo.objects.all())
指明字段时需要包含read_only=True或者queryset参数:
- 包含read_only=True参数时,该字段将不能用作反序列化使用
- 包含queryset参数时,将被用作反序列化时参数校验使用
使用效果:
def test(request):
hero = HeroInfo.objects.get(id=10) # 查询一个英雄对象
serializer = HeroInfoSerializer(hero) # 构建序列化
print(serializer.data) # 返回序列化内容 {'id': 10, 'hcomment': '独孤九剑', 'hname': '令狐冲', 'hbook': 3, 'hgender': 1}
return HttpResponse('ok')
报错:说明id不存在

2. StringRelatedField
此字段将被序列化为关联对象的字符串表示方式(即__str__方法的返回值)
hbook = serializers.StringRelatedField(label='图书')
def test(request):
hero = HeroInfo.objects.get(id=11) # 查询一个英雄对象
serializer = HeroInfoSerializer(hero) # 构建序列化
print(serializer.data) # 返回序列化内容 {'hgender': 0, 'hbook': '笑傲江湖', 'id': 11, 'hname': '任盈盈', 'hcomment': '弹琴'}
return HttpResponse('ok')
3. 使用关联对象的序列化器
hbook = BookInfoSerializer()
def test(request):
hero = HeroInfo.objects.get(id=11) # 查询一个英雄对象
serializer = HeroInfoSerializer(hero) # 构建序列化
print(serializer.data) # 返回序列化内容 {'hgender': 0, 'hbook': OrderedDict([('id', 3), ('btitle', '笑傲江湖'), ('bpub_date', '1995-12-24'), ('bread', 20), ('bcomment', 80), ('image', None)]), 'hcomment': '弹琴', 'id': 11, 'hname': '任盈盈'}
return HttpResponse('ok')
4. HyperlinkedRelatedField
此字段将被序列化为获取关联对象数据的接口链接
hbook = serializers.HyperlinkedRelatedField(label='图书', read_only=True, view_name='books-detail')
必须指明view_name参数,以便DRF根据视图名称寻找路由,进而拼接成完整URL。
{'id': 6, 'hname': '乔峰', 'hgender': 1, 'hcomment': '降龙十八掌', 'hbook': 'http://127.0.0.1:8000/books/2/'}
5. SlugRelatedField
此字段将被序列化为关联对象的指定字段数据
slug_field指明使用关联对象的哪个字段
hbook = serializers.SlugRelatedField(label='图书', read_only=True, slug_field='bpub_date')
def test(request):
hero = HeroInfo.objects.get(id=11) # 查询一个英雄对象
serializer = HeroInfoSerializer(hero) # 构建序列化
print(serializer.data) # 返回序列化内容 {'id': 11, 'hgender': 0, 'hcomment': '弹琴', 'hname': '任盈盈', 'hbook': datetime.date(1995, 12, 24)} return HttpResponse('ok')
6. 重写to_representation方法
序列化器的每个字段实际都是由该字段类型的to_representation方法决定格式的,可以通过重写该方法来决定格式。
注意,to_representations方法不仅局限在控制关联对象格式上,适用于各个序列化器字段类型。
自定义一个新的关联字段:
class BookRelateField(serializers.RelatedField):
"""自定义用于处理图书的字段"""
def to_representation(self, value):
return 'Book: %d %s' % (value.id, value.btitle)
hbook = BookRelateField(read_only=True)
def test(request):
hero = HeroInfo.objects.get(id=11) # 查询一个英雄对象
serializer = HeroInfoSerializer(hero) # 构建序列化
print(serializer.data) # 返回序列化内容 {'hbook': 'Book: 3 笑傲江湖', 'id': 11, 'hcomment': '弹琴', 'hname': '任盈盈', 'hgender': 0}
return HttpResponse('ok')
many参数
如果关联的对象数据不是只有一个,而是包含多个数据,如想序列化图书BookInfo数据,每个BookInfo对象关联的英雄HeroInfo对象可能有多个,此时关联字段类型的指明仍可使用上述几种方式,只是在声明关联字段时,多补充一个many=True参数即可。
此处仅拿PrimaryKeyRelatedField类型来举例,其他相同。
在BookInfoSerializer中添加关联字段:
class BookInfoSerializer(serializers.Serializer):
"""图书数据序列化器"""
id = serializers.IntegerField(label='ID', read_only=True)
btitle = serializers.CharField(label='名称', max_length=20)
bpub_date = serializers.DateField(label='发布日期', required=False)
bread = serializers.IntegerField(label='阅读量', required=False)
bcomment = serializers.IntegerField(label='评论量', required=False)
image = serializers.ImageField(label='图片', required=False)
heroinfo_set = serializers.PrimaryKeyRelatedField(read_only=True, many=True) # 新增
使用效果:
def test(request):
book = BookInfo.objects.get(id=3) # 查询一个英雄对象
serializer = BookInfoSerializer(book) # 构建序列化
print(serializer.data) # 返回序列化内容 {'image': None, 'id': 3, 'bpub_date': '1995-12-24', 'bcomment': 80, 'bread': 20, 'heroinfo_set': [10, 11, 12, 13], 'btitle': '笑傲江湖'} return HttpResponse('ok')
Serializer序列器的更多相关文章
- Android初级教程:使用xml序列器
之前备份短信的时候生成xml都是手动拼写的,有一个问题:当短信里面存在</body>这样的标签的时候,最后结果就不是完整的xml文件,显然出错.但是,今天使用序列化器的方式,就能有效的解决 ...
- DRF框架之Serializer序列化器的序列化操作
在DRF框架中,有两种序列化器,一种是Serializer,另一种是ModelSerializer. 今天,我们就先来学习一下Serializer序列化器. 使用Serializer序列化器的开发步骤 ...
- DRF框架之Serializer序列化器的反序列化操作
昨天,我们完成了Serializer序列化器的反序列化操作,那么今天我们就来学习Serializer序列化器的最后一点知识,反序列化操作. 首先,我们定要明确什么是反序列化操作? 反序列化操作:JOS ...
- DRF 序列化器-Serializer (2)
作用 1. 序列化,序列化器会把模型对象转换成字典,经过response以后变成json字符串 2. 完成数据校验功能 3. 反序列化,把客户端发送过来的数据,经过request以后变成字典,序列化器 ...
- 16-DRF工程搭建与序列化器
1.DRF工程搭建 环境安装与配置 DRF是以Django扩展应用的方式提供的,所以我们可以直接利用Django环境,而无需创建(先创建Django环境). 1.安装DRF pip3 install ...
- Django:前后端分离 djangorestframework开发API接口 serializer序列化认证组件
参考:https://blog.csdn.net/zhangmengran/article/details/84887206 目的: 使用serializer序列化器将QuerySet数据序列化为js ...
- Django 学习之Django Rest Framework_序列化器_Serializer
作用: 1.序列化,序列化器会把模型对象转换成字典,经过response以后变成json字符串. 2.反序列化,把客户端发送过来的数据,经过request以后变成字典,序列化器可以把字典转成模型. 3 ...
- drf Serializer使用
drf序列化 在前后端不分离的项目中,可以使用Django自带的forms组件进行数据验证,也可以使用Django自带的序列化组件对模型表数据进行序列化. 那么在前后端分离的项目中,drf也提供了数据 ...
- DjangoRestFramework学习二之序列化组件、视图组件 serializer modelserializer
DjangoRestFramework学习二之序列化组件.视图组件 本节目录 一 序列化组件 二 视图组件 三 xxx 四 xxx 五 xxx 六 xxx 七 xxx 八 xxx 一 序列化组 ...
随机推荐
- C#常用控件的属性以及方法(转载)
-----以前看别人的,保存了下来,但是忘了源处,望见谅. C#常用控件属性及方法介绍 目录 1.窗体(Form) 2.Label (标签)控件 3.TextBox(文本框)控件 4.RichText ...
- Primefaces dataTable设置某个cell的样式问题
设置primefaces dataTable的源网段列的Cell可以编辑,当回车键保存时,判断是否输入的网段合法,如果不合法就显示警告信息,并将这个不合法的数据用红色表示.问题是,怎么给这一个cell ...
- mybatis使用说明
起步:1.创建一个maven项目工程.2.打开pom.xml配置文件,3.设置源代码编码方式为UTF-8.4.设置编译源代码的JDK版本.最好大于1.6版本.5. 重点--添加Mybatis的相关依赖 ...
- 最简实例演示asp.net5中用户认证和授权(3)
上接: 最简实例演示asp.net5中用户认证和授权(2) 在实现了角色的各种管理接口后,下一步就是实现对用户的管理,对用户管理的接口相对多一些,必须要实现的有如下三个: 1 public inter ...
- MS Chart 条状图【转】
private void Form1_Load(object sender, EventArgs e) { string sql1 = "select 类别,coun ...
- mysql通用分页存储过程遇到的问题
DELIMITER $$ USE `tsb_asksys`$$ DROP PROCEDURE IF EXISTS `P_viewPage`$$ CREATE DEFINER=`root`@`local ...
- C# 常见的字符串操作
例1: 遍历字符串中的每一个字符: string src = "aa-b - c-a - d-e- d-e- a- a-b-cc"; foreach(char c in src) ...
- 【迷你微信】基于MINA、Hibernate、Spring、Protobuf的即时聊天系统:6.技术简介之Protobuf
欢迎阅读我的开源项目<迷你微信>服务器与<迷你微信>客户端 protocolbuffer(以下简称Protobuf)是google 的一种数据交换的格式,它独立于语言,独立于平 ...
- LeetCode Merge Two Sorted Lists 归并排序
题意: 将两个有序的链表归并为一个有序的链表. 思路: 设合并后的链表为head,现每次要往head中加入一个元素,该元素要么属于L1,要么属于L2,可想而知,此元素只能是L1或者L2的首个元素, ...
- SharePoint Survey – Custom Action
<?xml version="1.0" encoding="utf-8" ?> <Elements xmlns="http://sc ...