开源数据库中间件-MyCat
开源数据库中间件-MyCat产生的背景
如今随着互联网的发展,数据的量级也是成指数的增长,从GB到TB到PB。对数据的各种操作也是愈加的困难,传统的关系型数据库已经无法满足快速查询与插入数据的需求。这个时候NoSQL的出现暂时解决了这一危机。它通过降低数据的安全性,减少对事务的支持,减少对复杂查询的支持,来获取性能上的提升。
但是,在有些场合NoSQL一些折衷是无法满足使用场景的,就比如有些使用场景是绝对要有事务与安全指标的。这个时候NoSQL肯定是无法满足的,所以还是需要使用关系型数据库。如何使用关系型数据库解决海量存储的问题呢?此时就需要做数据库集群,为了提高查询性能将一个数据库的数据分散到不同的数据库中存储。
什么是MyCat?
Mycat 背后是阿里曾经开源的知名产品——Cobar。Cobar 的核心功能和优势是 MySQL 数据库分片,此产品曾经广为流传,据说最早的发起者对 Mysql 很精通,后来从阿里跳槽了,阿里随后开源的 Cobar,并维持到 2013 年年初,然后,就没有然后了。
Cobar 的思路和实现路径的确不错。基于 Java 开发的,实现了 MySQL 公开的二进制传输协议,巧妙地将自己伪装成一个 MySQL Server,目前市面上绝大多数 MySQL 客户端工具和应用都能兼容。比自己实现一个新的数据库协议要明智的多,因为生态环境在哪里摆着。
Mycat 是基于 cobar 演变而来,对 cobar 的代码进行了彻底的重构,使用 NIO 重构了网络模块,并且优化了 Buffer 内核,增强了聚合,Join 等基本特性,同时兼容绝大多数数据库成为通用的数据库中间件。
简单的说,MyCAT就是:一个新颖的数据库中间件产品,支持mysql集群,或者mariadb cluster,提供高可用性数据分片集群。你可以像使用mysql一样使用mycat。对于开发人员来说根本感觉不到mycat的存在。

MyCat支持的数据库:

使用mycat之前肯定要使用mysql(具体哪个数据库无所谓,只要是mycat支持的就行)简单的说一下Linux下mysql的安装:
安装要求:
JDK:要求jdk必须是1.7及以上版本
MySQL:推荐mysql是5.5以上版本
安装与启动步骤如下:
(1)将MySQL的服务端和客户端安装包(RPM)上传到服务器

(2)查询之前是否安装过MySQL
rpm -qa|grep -i mysql
(3)卸载旧版本MySQL
rpm -e --nodeps 软件名称
(4)安装服务端
rpm -ivh MySQL-server-5.5.-.linux2..i386.rpm
(5)安装客户端
rpm -ivh MySQL-client-5.5.-.linux2..i386.rpm
(6)启动MySQL服务
service mysql start
(7)登录MySQL (记得设置mysql登录密码,此处不作详细介绍!)
mysql -u root -proot
(8)设置远程登录权限
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%'IDENTIFIED BY 'root' WITH GRANT OPTION;
在本地SQLyog 连接远程MySQL进行测试
接下来的工作就是我们的重头戏mycat了,首先当然还是从mycat的安装说起了。
mycat的官方网站:http://www.mycat.org.cn/
下载地址①:https://github.com/MyCATApache/Mycat-download
下载地址②:http://dl.mycat.io/
下载好了之后开始正式安装:
第一步:将Mycat-server-1.4-release-20151019230038-linux.tar.gz上传至服务器
第二步:将压缩包解压缩。建议将mycat放到/usr/local/mycat目录下。
tar -xzvf Mycat-server-1.4-release--linux.tar.gz
mv mycat /usr/local
第三步:进入mycat目录的bin目录,启动mycat
./mycat start
停止mycat:
./mycat stop
mycat 支持的命令{ console | start | stop | restart | status | dump }
Mycat的默认端口号为:8066
此时我们已经成功的安装好了mycat了,这之前先不用着急怎么去用mycat,我们需要知道怎么用mycat分片解决海量数据存储方案的。
首先来说说什么是分片?
简单来说,就是指通过某种特定的条件,将我们存放在同一个数据库中的数据分散存放到多个数据库(主机)上面,以达到分散单台设备负载的效果。数据的切分(Sharding)根据其切分规则的类型,可以分为两种切分模式。
(1)一种是按照不同的表(或者Schema)来切分到不同的数据库(主机)之上,这种切分可以称之为数据的垂直(纵向)切分
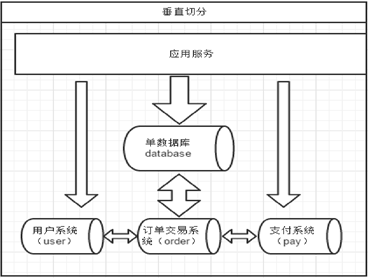
(2)另外一种则是根据表中的数据的逻辑关系,将同一个表中的数据按照某种条件拆分到多台数据库(主机)上面,这种切分称之为数据的水平(横向)切分。

MyCat分片策略:
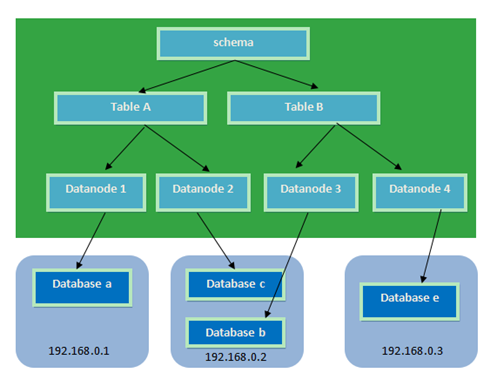
分片相关的概念:
逻辑库(schema) :前面讲了数据库中间件,通常对实际应用来说,并不需要知道中间件的存在,业务开发人员只需要知道数据库的概念,所以数据库中间件可以被看做是一个或多个数据库集群构成的逻辑库。
逻辑表(table):既然有逻辑库,那么就会有逻辑表,分布式数据库中,对应用来说,读写数据的表就是逻辑表。逻辑表,可以是数据切分后,分布在一个或多个分片库中,也可以不做数据切分,不分片,只有一个表构成。
分片表:是指那些原有的很大数据的表,需要切分到多个数据库的表,这样,每个分片都有一部分数据,所有分片构成了完整的数据。 总而言之就是需要进行分片的表。
非分片表:一个数据库中并不是所有的表都很大,某些表是可以不用进行切分的,非分片是相对分片表来说的,就是那些不需要进行数据切分的表。
分片节点(dataNode):数据切分后,一个大表被分到不同的分片数据库上面,每个表分片所在的数据库就是分片节点(dataNode)。
节点主机(dataHost) :数据切分后,每个分片节点(dataNode)不一定都会独占一台机器,同一机器上面可以有多个分片数据库,这样一个或多个分片节点(dataNode)所在的机器就是节点主机(dataHost),为了规避单节点主机并发数限制,尽量将读写压力高的分片节点(dataNode)均衡的放在不同的节点主机(dataHost)。
分片规则(rule) :前面讲了数据切分,一个大表被分成若干个分片表,就需要一定的规则,这样按照某种业务规则把数据分到某个分片的规则就是分片规则,数据切分选择合适的分片规则非常重要,将极大的避免后续数据处理的难度。
关于MyCat分片配置
(1)配置schema.xml
schema.xml作为MyCat中重要的配置文件之一,管理着MyCat的逻辑库、逻辑表以及对应的分片规则、DataNode以及DataSource。弄懂这些配置,是正确使用MyCat的前提。这里就一层层对该文件进行解析。
schema 标签用于定义MyCat实例中的逻辑库
Table 标签定义了MyCat中的逻辑表 rule用于指定分片规则,auto-sharding-long的分片规则是按ID值的范围进行分片 1-5000000 为第1片 5000001-10000000 为第2片....
dataNode 标签定义了MyCat中的数据节点,也就是我们通常说所的数据分片。
dataHost标签在mycat逻辑库中也是作为最底层的标签存在,直接定义了具体的数据库实例、读写分离配置和心跳语句。
在服务器上创建3个数据库,分别是db1 db2 db3
修改schema.xml如下:
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://org.opencloudb/">
<schema name="PINYOUGOUDB" checkSQLschema="false" sqlMaxLimit="">
<table name="tb_test" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" />
</schema>
<dataNode name="dn1" dataHost="localhost1" database="db1" />
<dataNode name="dn2" dataHost="localhost1" database="db2" />
<dataNode name="dn3" dataHost="localhost1" database="db3" />
<dataHost name="localhost1" maxCon="" minCon="" balance=""
writeType="" dbType="mysql" dbDriver="native" switchType="" slaveThreshold="">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.25.142:3306" user="root"
password="root">
</writeHost>
</dataHost>
</mycat:schema>
(2)配置 server.xml
server.xml几乎保存了所有mycat需要的系统配置信息。最常用的是在此配置用户名、密码及权限。在system中添加UTF-8字符集设置,否则存储中文会出现问号
<property name="charset">utf8</property>
修改user的设置 , 我们这里为 PINYOUGOUDB设置了两个用户
<user name="test">
<property name="password">test</property>
<property name="schemas">PINYOUGOUDB</property>
</user>
<user name="root">
<property name="password"></property>
<property name="schemas">PINYOUGOUDB</property>
</user>
MyCat分片测试:
进入mycat ,执行下列语句创建一个表:
CREATE TABLE tb_test (
id BIGINT() NOT NULL,
title VARCHAR() NOT NULL ,
PRIMARY KEY (id)
) ENGINE=INNODB DEFAULT CHARSET=utf8
创建后你会发现,MyCat会自动将你的表转换为大写,这一点与Oracle有些类似。
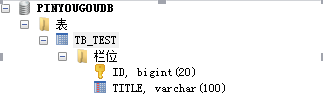
我们再查看MySQL的3个库,发现表都自动创建好啦。好神奇。
接下来是插入表数据,注意,在写INSERT语句时一定要写把字段列表写出来,否则会出现下列错误提示:
错误代码: 1064
partition table, insert must provide ColumnList
我们试着插入一些数据:
INSERT INTO TB_TEST(ID,TITLE) VALUES(,'goods1');
INSERT INTO TB_TEST(ID,TITLE) VALUES(,'goods2');
INSERT INTO TB_TEST(ID,TITLE) VALUES(,'goods3');
我们会发现这些数据被写入到第一个节点中了,那什么时候数据会写到第二个节点中呢?
我们插入下面的数据就可以插入第二个节点了
INSERT INTO TB_TEST(ID,TITLE) VALUES(,'goods5000001');
因为我们采用的分片规则是每节点存储500万条数据,所以当ID大于5000000则会存储到第二个节点上。
目前只设置了两个节点,如果数据大于1000万条,会怎么样呢?执行下列语句测试一下
INSERT INTO TB_TEST(ID,TITLE) VALUES(,'goods10000001');
MyCat分片规则
rule.xml用于定义分片规则 ,我们这里讲解两种最常见的分片规则
(1)按主键范围分片rang-long
在配置文件中我们找到
<tableRule name="auto-sharding-long">
<rule>
<columns>id</columns>
<algorithm>rang-long</algorithm>
</rule>
</tableRule>
tableRule 是定义具体某个表或某一类表的分片规则名称 columns用于定义分片的列 algorithm代表算法名称 我们接着找rang-long的定义
<function name="rang-long"
class="org.opencloudb.route.function.AutoPartitionByLong">
<property name="mapFile">autopartition-long.txt</property>
</function>
Function用于定义算法 mapFile 用于定义算法需要的数据,我们打开autopartition-long.txt
# range start-end ,data node index
# K=,M=.
-500M=
500M-1000M=
1000M-1500M=
(2)一致性哈希murmur
当我们需要将数据平均分在几个分区中,需要使用一致性hash规则
我们找到function的name为murmur 的定义,将count属性改为3,因为我要将数据分成3片
<function name="murmur"
class="org.opencloudb.route.function.PartitionByMurmurHash">
<property name="seed"></property><!-- 默认是0 -->
<property name="count"></property><!-- 要分片的数据库节点数量,必须指定,否则没法分片 -->
<property name="virtualBucketTimes"></property><!-- 一个实际的数据库节点被映射为这么多虚拟节点,默认是160倍,也就是虚拟节点数是物理节点数的160倍 -->
<!-- <property name="weightMapFile">weightMapFile</property> 节点的权重,没有指定权重的节点默认是1。以properties文件的格式填写,
以从0开始到count-1的整数值也就是节点索引为key,以节点权重值为值。所有权重值必须是正整数,否则以1代替 -->
<!-- <property name="bucketMapPath">/etc/mycat/bucketMapPath</property>
用于测试时观察各物理节点与虚拟节点的分布情况,如果指定了这个属性,会把虚拟节点的murmur hash值与物理节点的映射按行输出到这个文件,没有默认值,如果不指定,就不会输出任何东西 -->
</function>
我们再配置文件中可以找到表规则定义
<tableRule name="sharding-by-murmur">
<rule>
<columns>id</columns>
<algorithm>murmur</algorithm>
</rule>
</tableRule>
但是这个规则指定的列是id ,如果我们的表主键不是id ,而是order_id ,那么我们应该重新定义一个tableRule:
<tableRule name="sharding-by-murmur-order">
<rule>
<columns>order_id</columns>
<algorithm>murmur</algorithm>
</rule>
</tableRule>
在schema.xml中配置逻辑表时,指定规则为sharding-by-murmur-order
<table name="tb_order" dataNode="dn1,dn2,dn3" rule="sharding-by-murmur-order" />
我们测试一下,创建订单表 ,并插入数据,测试分片效果。
开源数据库中间件-MyCat的更多相关文章
- 【Jmeter】压测mysql数据库中间件mycat
背景 因为博主所负责测试的项目需要数据库有较大的吞吐量,在最近进行了升级,更新了一个数据库中间件 - - mycat.查询了一些资料,了解到这是阿里的一个开源项目,基于mysql,是针对磁盘的读与写, ...
- 开源分布式数据库中间件MyCat源码分析系列
MyCat是当下很火的开源分布式数据库中间件,特意花费了一些精力研究其实现方式与内部机制,在此针对某些较为重要的源码进行粗浅的分析,希望与感兴趣的朋友交流探讨. 本源码分析系列主要针对代码实现,配置. ...
- 分布式数据库中间件Mycat百亿级数据存储(转)
此文转自: https://www.jianshu.com/p/9f1347ef75dd 2013年阿里的Cobar在社区使用过程中发现存在一些比较严重的问题,如高并发下的假死,心跳连接的故障,只实现 ...
- 数据库中间件MyCat学习总结(1)——MyCat入门简介
为什么需要MyCat? 虽然云计算时代,传统数据库存在着先天性的弊端,但是NoSQL数据库又无法将其替代.如果传统数据易于扩展,可切分,就可以避免单机(单库)的性能缺陷. MyCat的目标就是:低成本 ...
- 分布式数据库中间件 MyCat 搞起来!
关于 MyCat 的铺垫文章已经写了三篇了: MySQL 只能做小项目?松哥要说几句公道话! 北冥有 Data,其名为鲲,鲲之大,一个 MySQL 放不下! What?Tomcat 竟然也算中间件? ...
- 数据库中间件mycat简单入门
当在项目中mysql数据库成为瓶颈的时候,我们一般会使用主从复制,分库分表的方式来提高数据库的响应速度,比如mysql主从复制,在没有数据库中间件的情况下,我们只能由开发工程师在程序中控制,这对于一个 ...
- 数据库中间件MyCat学习总结(2)——MyCat-Web原理介绍
Mycat是一个分库分表的基于java开发的数据库中间件,使用过程中需要有一个监控系统,mycat-web应运而生.mycat-web是一个使用SpringMVC + Mybatis的监控平台,使用常 ...
- 分布式数据库中间件 MyCat | 分库分表实践
MyCat 简介 MyCat 是一个功能强大的分布式数据库中间件,是一个实现了 MySQL 协议的 Server,前端人员可以把它看做是一个数据库代理中间件,用 MySQL 客户端工具和命令行访问:而 ...
- 数据库中间件mycat安装与使用
1.下载 # wget http://dl.mycat.io/1.6-RELEASE/Mycat-server-1.6-RELEASE-20161028204710-linux.tar.gz 2.安装 ...
随机推荐
- Flume NG部署
本次配置单节点的Flume NG 1.下载flume安装包 下载地址:(http://flume.apache.org/download.html) apache-flume-1.6.0-bin.ta ...
- Elasticsearch支持的字段类型
es支持下列简单的字段类型: String: string Whole number: byte, short, integer, long Floating point: float, double ...
- OpenCV之cvAddWeighted直接C语言实现版addWeighted,应对上下平滑融合拼接
关于OpenCV中的cvAddWeighted的介绍可参见<opencv中的cvAddWeighted函数> cvAddWeighted有个问题,它只能实现两张图片的直接融合,往往产生明显 ...
- 截取网卡IP地址
方法一: ifconfig eth1|awk 'NR==2 {print $2}' 方法二"" ifconfig eth1|grep -Po "(?<=inet ) ...
- 一、基于Qt的图像矩形区域改色
Qt环境下图像的打开和涂色 一.设计目标 能够在 Qt QtCreator 环境下打开常用图像格式文件,诸如 bmp.jpg.png 图像等,然后将他们转化为 Qt 中的 QImage 类,并进行矩形 ...
- vue指令总结(二)
一.vue指令 1.v-text v-text是用于操作纯文本,它会替代显示对应的数据对象上的值.当绑定的数据对象上的值发生改变,插值处的内容也会随之更新.注意:此处为单向绑定,数据对象上的值改变,插 ...
- tableviewcell折叠问题,(类似qq列表展开形式) 多个cell同时展开,OC版 和 Swift
之前没有用到过这块,但是今天看到,就试了试,但是发现,网上的有的方法不能多个cell同时展开,只能一个一个的展开. 我就尝试用用数组记录展开的标记的方法,功能实现了, 直接上代码: // // Vie ...
- SCSI add-single-device and remove-single-device
众所周知,SATA和SCSI是支持热插拔的,但是新装了这类支持热插拔的驱动器,系统不会马上识别的,往往我们需要重启系统来识别,但是有另外一种方法可以很方面的让系统识别新的设备. 作为系统管理员,需要了 ...
- java基础——线程池
第2章 线程池 2.1 线程池概念 线程池,其实就是一个容纳多个线程的容器,其中的线程可以反复使用,省去了频繁创建线程对象的操作,无需反复创建线程而消耗过多资源. 我们详细的解释一下为什么要使用线程池 ...
- ES6学习(二):函数的扩展
chapter07 函数的扩展 7.1 函数默认值 7.1.1 参数默认值简介 传统做法的弊端(||):如果传入的参数相等于(==)false的话,仍会被设为默认值,需要多加入一个if判断,比较麻烦. ...