python3爬虫之Urllib库(二)
在上一篇文章中,我们大概讲了一下urllib库中最重要的两个请求方法:urlopen() 和 Request()
但是仅仅凭借那两个方法无法执行一些更高级的请求,如Cookies处理,代理设置等等。
这是就是Handler大显神威的时候了,简单地说,他是各种处理器,有处理验证登录的,有处理Cookies的,有处理代理设置的。
高级用法
首先说一下urllib。request模块中的BaseHandler类,他是所有类的基类,它提供了最基本的方法,如:default_open() protocol_request()等。
下边是各种子类:
HTTPDefaultErrorHandler 用于处理HTTP响应错误
HTTPRedirectHandler 用于处理重定向
HTTPCookieProcessor 用于处理Cookies
ProxyHandler 用于设置代理,默认代理为空
HTTPPasswordMgr 用于管理密码
HTTPBasicAuthHandler 用于认证管理
还有一个类非常重要,他就是 OpenerDirector 我们称为Opener
为什么说这个类呢?之前使用的Request和urlopen()都是封装好的请求方法,利用它们可以完成请求,但是现在我们要实现高级功能,就需要进行深一层的配置,所以就用到了Opener
下面我们看看例子:
代理设置:
在使用爬虫难免需要使用到代理,添加代理:
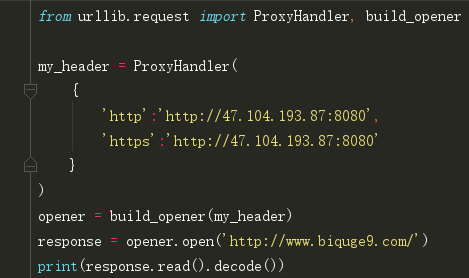
说一下代码:
这个代理是我从西刺代理上找到的,使用了 ProxyHandler类,他的参数是一个字典,key是协议名,value是代理链接。
然后再利用Handler及build_opener()方法构造一个opener,然后使用open()方法发送请求即可。
Cookies
首先我们获取网站的Cookies:
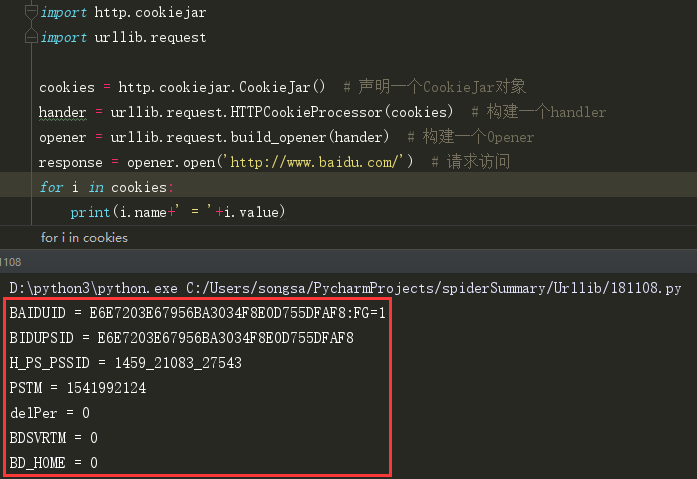
这样输出类每一条Cookie的名称和值
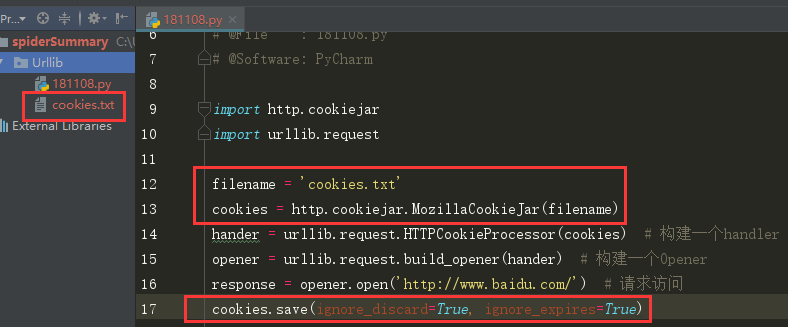
当然,也可以保存Cookie至文件:(因为Cookie实际上也是以文件形式保存的)
但是代码要稍做调整,将CookieJar改为 MozillaCookieJar(filename) 它在生成文件时会用到,是CookieJar的子类
这是cookie内容:
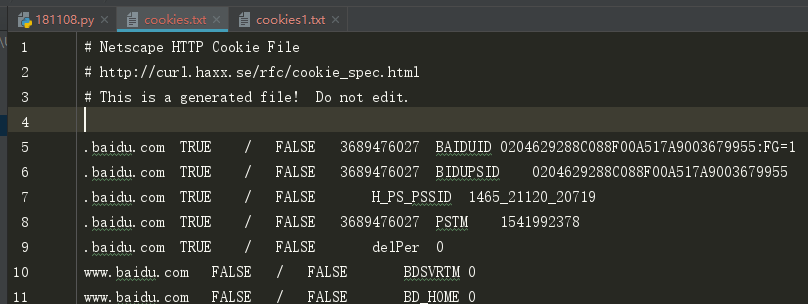
但是也可以使用 http.cookiejar.LWPCookieJar(filename) 来保存数据,但是格式会和MozillaCookieJar(filename)不大一样:
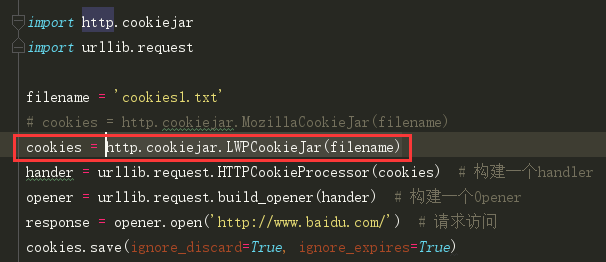

当然,你也可以再网页界面点击F12,手动获取Cookies
刚刚获取了Cookies,现在我们来在请求时获取本地文件Cookies
如从本地LWPCookieJar()类型的文本中获取Cookies:

异常处理
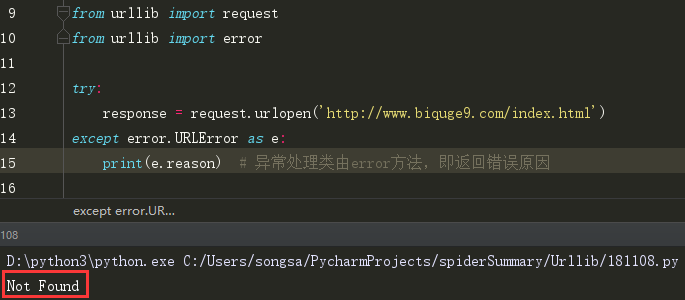
前面我们讲了发起请求,但是当程序报错是怎么办?脚本就会宕掉,这不是我们想要的,所以就有了异常处理
(1)URLError 因页面不存在而报错的异常:
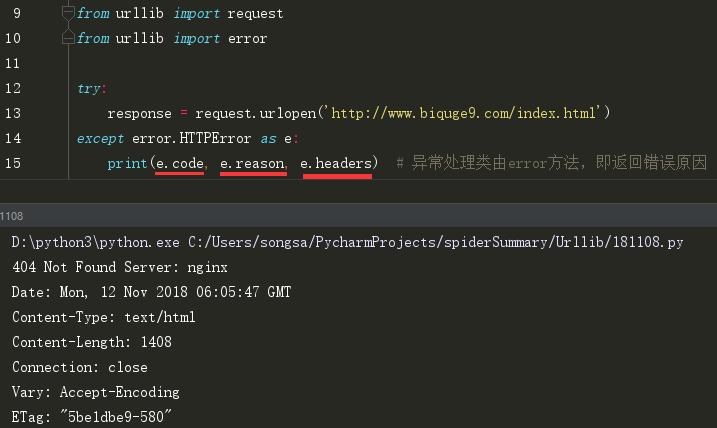
(2)HTTPError 是URLError的子类,专门处理HTTP请求错误,如认证失败等。
有三个属性:
code: 返回HTTP状态码,如200请求成功, 404网页不存在, 500服务器内部错误等。
reason: 同父类一样,用于返回错误原因
headers: 返回请求头
· 
解析链接
urllib库中还有parse模块,用于对url各部分的抽取、合并及连接转换。
(1)urlparse()
这个方法可以识别和分段URL

可以看见,返回的是一个ParseResult类型对象包含六部分。
由此可见,一个完整的URL由6部分组成: :// 之前是scheme, 代表协议; 第一个/符号前是netloc, 代表域名; 后边是path, 即访问路径; 分号;后边是parms, 代表参数; 问号?后边是query, 代表查询条件; 井号#后边是锚点,用于直接定位页面内部的下拉位置。
所以一个标准的链接格式: scheme://netloc/path;params?query#fragment
利用urlparse()方法可将其拆开
urlparse方法API:
urllib.parse.urlparse(urlstring, scheme="", allow_fragments=True)
urlstring: 必填项,是需要操作的url
scheme; 默认协议,如果url中没有协议,就使用默认协议。
allow_fragments:是否忽略 fragments 如果被设置为False,fragments就会被忽略,它会被解析为前边的一部分。
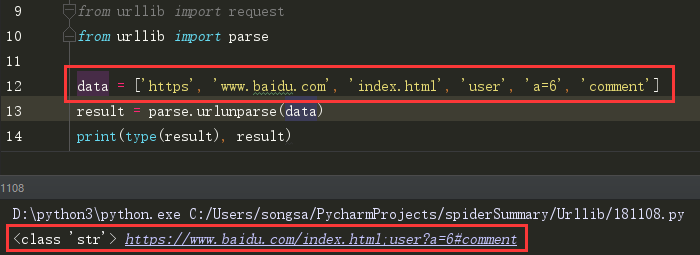
(2)urlunparse()
用于组成url,接收一个可迭代对象,但它的长度必须为6
(3)urlsplit()
这个方法和urlsplit()相似,只是不单独解析params部分,只返回5个结果。

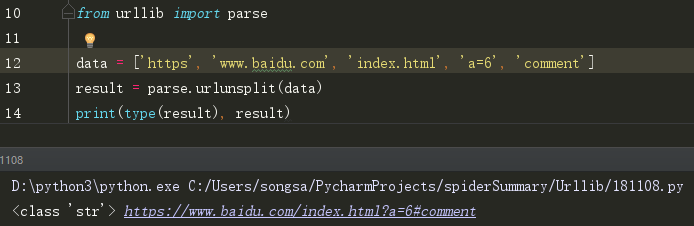
(4)urlunsplit()
这个和urlunparse相似,可以接收列表、元祖等长度为5的参数,组成url
(5)urljoin()
用于拼接链接 首先有一个base_url参数作为基础链接, 将新链接作为第二个参数传入,这个方法会分析base_url的scheme, netloc, path这三个内容对新链接进行补充(注意是将对第二个链接没有的参数进行补充,有的话并不会进行替换),最终返回结果

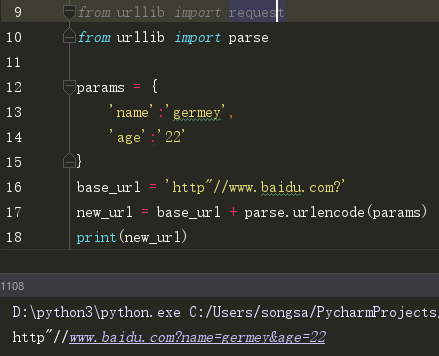
(6)urlencode()
这个方法在构造GET请求时非常有用
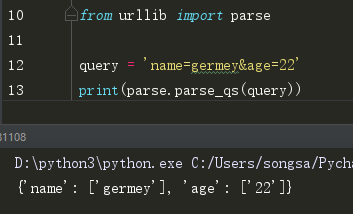
(7)parse_qs()
有序列化,就会有反序列化,这个方法可以将get参数反序列化为字典:
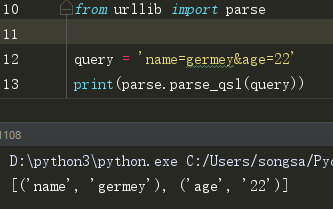
*(8)parse_qsl()方法,用于将参数转化为元组形式的列表, 返回结果每个元组中,第一个参数为参数名,第二个参数为参数值。
(9)quote()
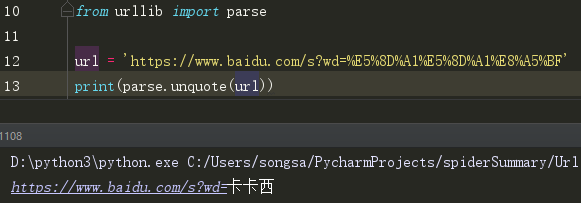
该方法可以将内容转化为URL编码的格式。 但当url中有中文时有可能会乱码。


(10)u你quote() 可以将URL进行解码
至此,urllib库基本就已经说完了,如有疑问或建议请评论留言进行补充。不甚感激
python3爬虫之Urllib库(二)的更多相关文章
- python3爬虫之Urllib库(一)
上一篇我简单说了说爬虫的原理,这一篇我们来讲讲python自带的请求库:urllib 在python2里边,用urllib库和urllib2库来实现请求的发送,但是在python3种在也不用那么麻烦了 ...
- 6.python3爬虫之urllib库
# 导入urllib.request import urllib.request # 向指定的url发送请求,并返回服务器响应的类文件对象 response = urllib.request.urlo ...
- python爬虫之urllib库(二)
python爬虫之urllib库(二) urllib库 超时设置 网页长时间无法响应的,系统会判断网页超时,无法打开网页.对于爬虫而言,我们作为网页的访问者,不能一直等着服务器给我们返回错误信息,耗费 ...
- python爬虫之urllib库(一)
python爬虫之urllib库(一) urllib库 urllib库是python提供的一种用于操作URL的模块,python2中是urllib和urllib2两个库文件,python3中整合在了u ...
- python爬虫之urllib库(三)
python爬虫之urllib库(三) urllib库 访问网页都是通过HTTP协议进行的,而HTTP协议是一种无状态的协议,即记不住来者何人.举个栗子,天猫上买东西,需要先登录天猫账号进入主页,再去 ...
- 爬虫之urllib库
一.urllib库简介 简介 Urllib是Python内置的HTTP请求库.其主要作用就是可以通过代码模拟浏览器发送请求.它包含四个模块: urllib.request :请求模块 urllib.e ...
- python爬虫之urllib库介绍
一.urllib库 urllib是Python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在Python3中的为urllib.request和urllib. ...
- 爬虫中urllib库
一.urllib库 urllib是Python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在Python3中的为urllib.request和urllib. ...
- python 爬虫之 urllib库
文章更新于:2020-03-02 注:代码来自老师授课用样例. 一.初识 urllib 库 在 python2.x 版本,urllib 与urllib2 是两个库,在 python3.x 版本,二者合 ...
随机推荐
- C# 调用NPOI 修改Excel 完成实时更新公式结果
C# 调用NPOI,修改EXCEL中的数据后并保存后,不会对公式进行更新操作.打开Excel表需要更新一下公式才生效 强制更新公式:C# 调用sheet.ForceFormulaRecalculati ...
- 去除pycharm的波浪线
PyCharm使用了较为严格的PEP8的检查规则,如果代码命名不规范,甚至多出的空格都会被波浪线标识出来,导致整个编辑器里铺满了波浪线,右边的滚动条也全是黄色或灰色的标记线,很是影响编辑.这里给大家分 ...
- Java基础知识——windows系统下安装JDK
(作者声明:文章引用了其他作者的文章,但因为笔记内容时间过久,已经忘记从哪里摘录下来的了.若无意间侵犯到原作者您的权利,对不起!您可以联系我,我这边会马上进行修改,谢谢!) 1.首先我们需要下载jav ...
- AI software can catch shoplifters before they steal
日本研发出智能软件 不等下手就能识别小偷 AI software can catch shoplifters before they steal 在汤姆·克鲁斯主演的电影<少数派报告>中, ...
- Google常用拓展插件
1.web前端助手(FEhelper)提供一些实用的前端小工具,功能十分贴心 2.bookMarks Manager 一个书签管理工具 3.Clear Cache 清除浏览器的缓存,有很多供选择的条目 ...
- FusionCharts可使用JavaScript渲染iPhone/iPod/iPad图表
FusionCharts使用JavaScript: FusionCharts允许用户创建建立JavaScript图表(也就是web上的HTML5 /Canvas图表).这个特性允许用户在不支持Flas ...
- [:space:]的用法(转)
转自:http://blog.itpub.net/27181165/viewspace-1061688/ 在linux中通常会使用shell结合正则表达式来过滤字符,本文将以一个简单的例子来说明+,* ...
- 微信小程序(底部导航的实现)
详情请看官方文档介绍: https://mp.weixin.qq.com/debug/wxadoc/dev/framework/config.html 在根目录配置文件app.json中配置底部导航: ...
- 【洛谷1967】货车运输(最大生成树+倍增LCA)
点此看题面 大致题意: 有\(n\)个城市和\(m\)条道路,每条道路有一个限重.多组询问,每次询问从\(x\)到\(y\)的最大载重为多少. 一个贪心的想法 首先,让我们来贪心一波. 由于要求最大载 ...
- Being a Good Boy in Spring Festival(博弈)
Being a Good Boy in Spring Festival Problem Description一年在外 父母时刻牵挂春节回家 你能做几天好孩子吗寒假里尝试做做下面的事情吧 陪妈妈逛一次 ...