[Python数据挖掘]第7章、航空公司客户价值分析
一、背景和挖掘目标


二、分析方法与过程
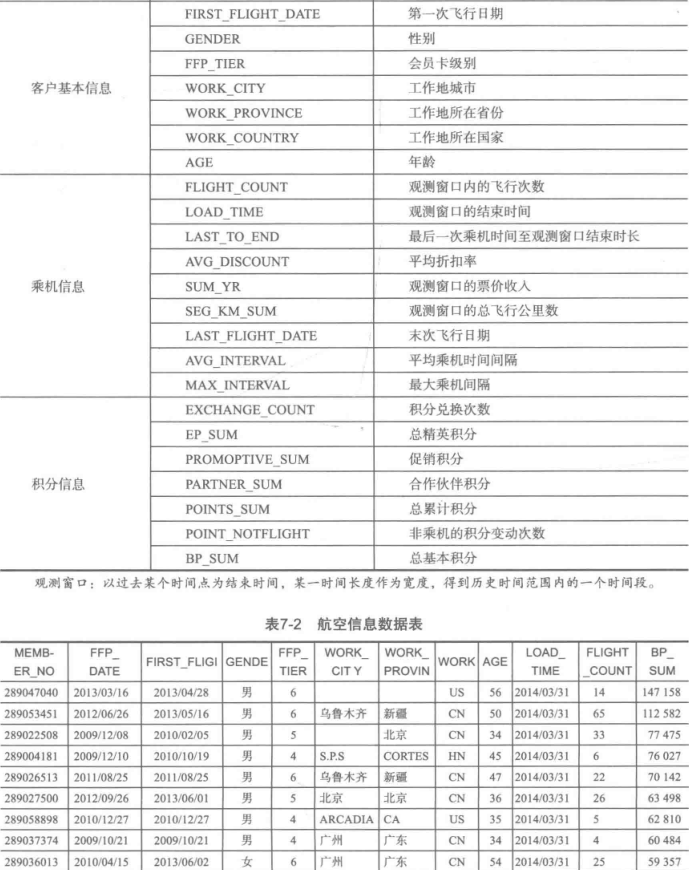
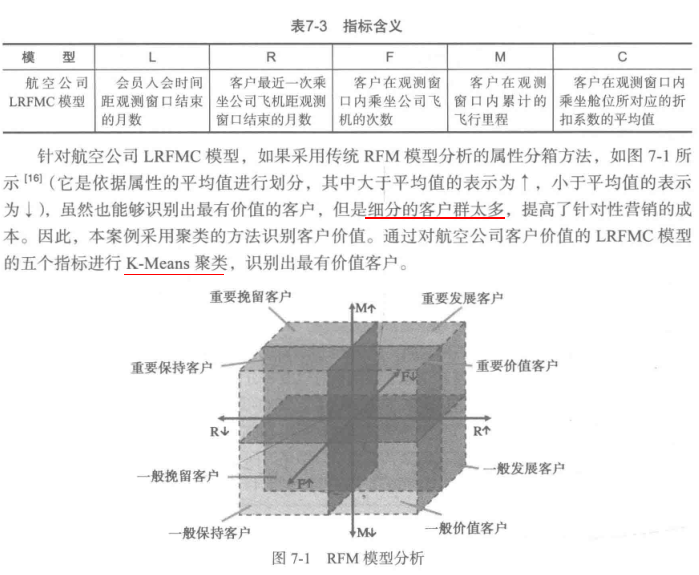
客户价值识别最常用的是RFM模型(最近消费时间间隔Recency,消费频率Frequency,消费金额Monetary)


1、EDA(探索性数据分析)
#对数据进行基本的探索
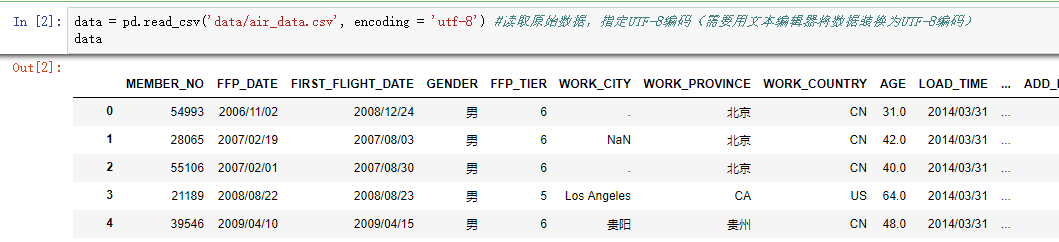
import pandas as pd data = pd.read_csv('data/air_data.csv', encoding = 'utf-8') #读取原始数据,指定UTF-8编码(需要用文本编辑器将数据装换为UTF-8编码) explore = data.describe(percentiles = [], include = 'all').T #包括对数据的基本描述,percentiles参数是指定计算多少的分位数表(如1/4分位数、中位数等);T是转置,转置后更方便查阅
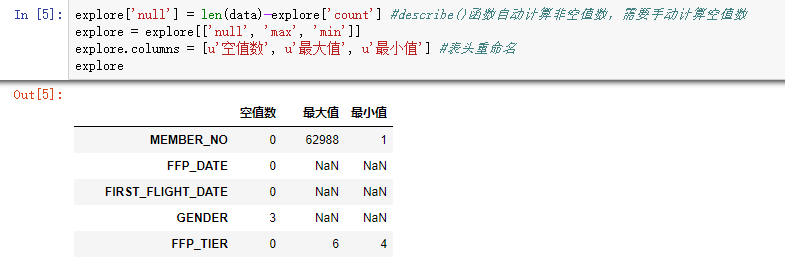
explore['null'] = len(data)-explore['count'] #describe()函数自动计算非空值数,需要手动计算空值数 explore = explore[['null', 'max', 'min']]
explore.columns = [u'空值数', u'最大值', u'最小值'] #表头重命名
'''这里只选取部分探索结果。
describe()函数自动计算的字段有count(非空值数)、unique(唯一值数)、top(频数最高者)、freq(最高频数)、mean(平均值)、std(方差)、min(最小值)、50%(中位数)、max(最大值)''' explore.to_excel('tmp/explore.xls') #导出结果


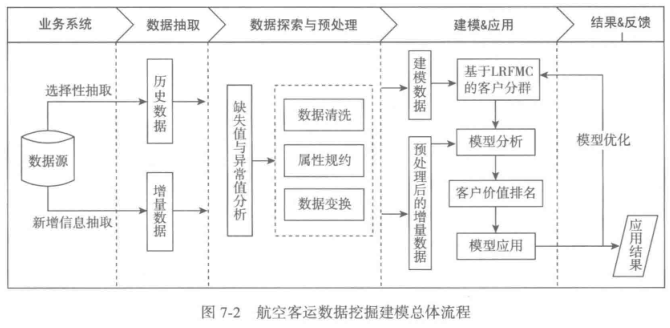
2、数据预处理
1.数据清洗

data = data[data['SUM_YR_1'].notnull()&data['SUM_YR_2'].notnull()] #票价非空值才保留 #只保留票价非零的,或者平均折扣率与总飞行公里数同时为0的记录。
index1 = data['SUM_YR_1'] != 0
index2 = data['SUM_YR_2'] != 0
index3 = (data['SEG_KM_SUM'] == 0) & (data['avg_discount'] == 0) #该规则是“与”
data = data[index1 | index2 | index3] #该规则是“或”
票价为空表示该值缺失,票价为0表示飞这一趟没花钱,二者概念不同
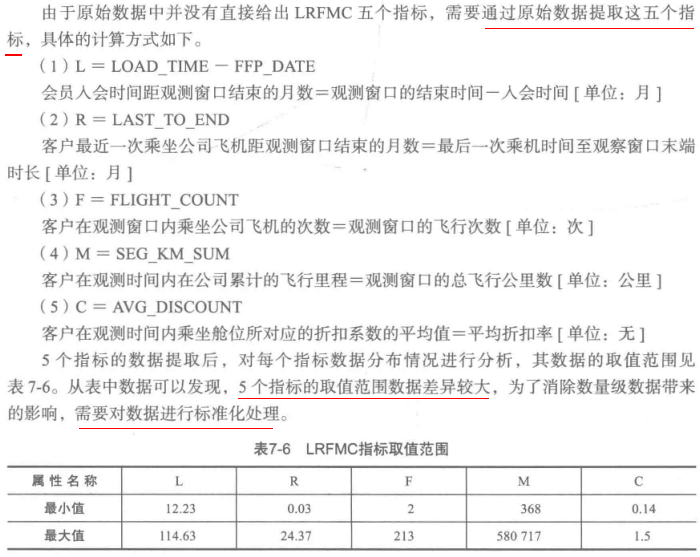
2.属性规约
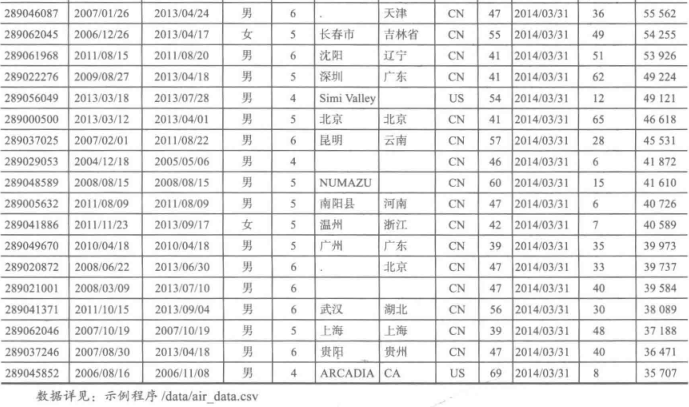
原始数据属性太多,根据之前提出的LRFMC模型,只保留6个与之相关的属性

3.数据变换
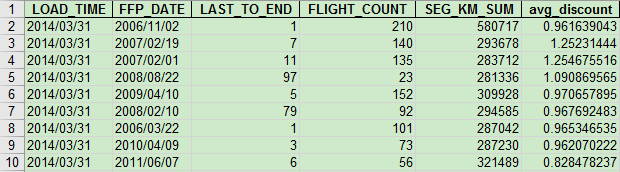
方法1:EXCEL手动操作(方便简单)
data_select.to_excel('tmp/data_select.xls', index = False) #数据写入
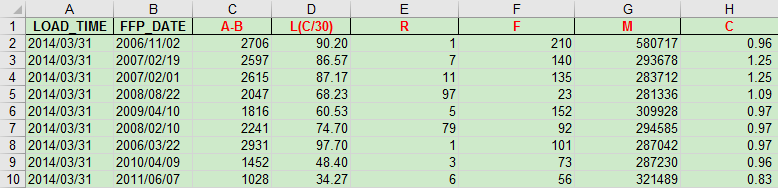
方法2:代码操作(方便新增信息的抽取)
from datetime import datetime #使用匿名函数将LOAD_TIME数据转换成datetime格式,然后才能进行日期加减(匿名函数比for循环效率高)
data_select['LOAD_TIME_convert'] = data_select['LOAD_TIME'].apply(lambda x: datetime.strptime(x, '%Y/%m/%d'))
data_select['FFP_DATE_convert'] = data_select['FFP_DATE'].apply(lambda x: datetime.strptime(x, '%Y/%m/%d')) #构造一个Series序列接收 (LOAD_TIME-FFP_DATE)
data_select['L']=pd.Series() #(LOAD_TIME-FFP_DATE)得到两个日期之间的天数间隔,然后除以30得到月份间隔 这一步相当费时
for i in range(len(data_select)):
data_select['L'][i] =(data_select['LOAD_TIME_convert'][i]-data_select['FFP_DATE_convert'][i]).days/30 data_select = data_select.rename(columns = {'LAST_TO_END': 'R','FLIGHT_COUNT':'F','SEG_KM_SUM':'M','avg_discount':'C'})
data_selected=data_select[['L','R','F','M','C']]
data_selected

接下来进行数据标准化
#标准差标准化
import pandas as pd data = pd.read_excel('data/zscoredata.xls', index = False)
data = (data - data.mean(axis = 0))/(data.std(axis = 0)) #简洁的语句实现了标准化变换,类似地可以实现任何想要的变换。
data.columns=['Z'+i for i in data.columns] #表头重命名。 data.to_excel('tmp/zscoreddata.xls', index = False) #数据写入
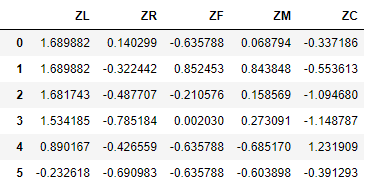
3、模型构建
1.客户聚类
#K-Means聚类算法
import pandas as pd
from sklearn.cluster import KMeans #导入K均值聚类算法 k = 5 #需要进行的聚类类别数 #读取数据并进行聚类分析
data = pd.read_excel('data/zscoreddata.xls') #调用k-means算法,进行聚类分析
kmodel = KMeans(n_clusters = k, n_jobs = 4) #n_jobs是并行数,一般等于CPU数较好
kmodel.fit(data) #训练模型 # kmodel.cluster_centers_ #查看聚类中心
# kmodel.labels_ #查看各样本对应的类别 #简单打印结果
s = pd.Series(['客户群1','客户群2','客户群3','客户群4','客户群5'], index=[0,1,2,3,4]) #创建一个序列s
r1 = pd.Series(kmodel.labels_).value_counts() #统计各个类别的数目
r2 = pd.DataFrame(kmodel.cluster_centers_) #找出聚类中心
r = pd.concat([s,r1,r2], axis = 1) #横向连接(0是纵向),得到聚类中心对应的类别下的数目
r.columns =[u'聚类名称'] +[u'聚类个数'] + list(data.columns) #重命名表头
print(r)
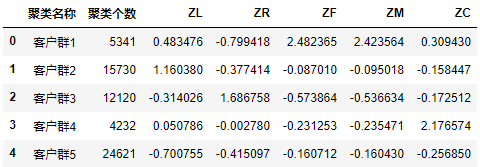
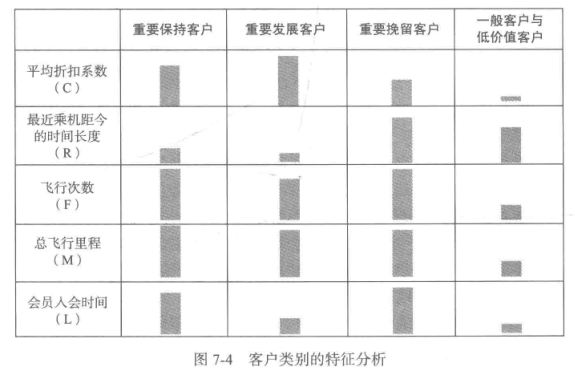
2.客户价值分析
#雷达图代码摘自 https://blog.csdn.net/Just_youHG/article/details/83904618
def plot_radar(data):
'''
the first column of the data is the cluster name;
the second column is the number of each cluster;
the last are those to describe the center of each cluster.
'''
kinds = data.iloc[:, 0]
labels = data.iloc[:, 2:].columns
centers = pd.concat([data.iloc[:, 2:], data.iloc[:,2]], axis=1)
centers = np.array(centers)
n = len(labels)
angles = np.linspace(0, 2*np.pi, n, endpoint=False)
angles = np.concatenate((angles, [angles[0]])) fig = plt.figure()
ax = fig.add_subplot(111, polar=True) # 设置坐标为极坐标 # 画若干个五边形
floor = np.floor(centers.min()) # 大于最小值的最大整数
ceil = np.ceil(centers.max()) # 小于最大值的最小整数
for i in np.arange(floor, ceil + 0.5, 0.5):
ax.plot(angles, [i] * (n + 1), '--', lw=0.5 , color='black') # 画不同客户群的分割线
for i in range(n):
ax.plot([angles[i], angles[i]], [floor, ceil], '--', lw=0.5, color='black') # 画不同的客户群所占的大小
for i in range(len(kinds)):
ax.plot(angles, centers[i], lw=2, label=kinds[i])
#ax.fill(angles, centers[i]) ax.set_thetagrids(angles * 180 / np.pi, labels) # 设置显示的角度,将弧度转换为角度
plt.legend(loc='lower right', bbox_to_anchor=(1.5, 0.0)) # 设置图例的位置,在画布外 ax.set_theta_zero_location('N') # 设置极坐标的起点(即0°)在正北方向,即相当于坐标轴逆时针旋转90°
ax.spines['polar'].set_visible(False) # 不显示极坐标最外圈的圆
ax.grid(False) # 不显示默认的分割线
ax.set_yticks([]) # 不显示坐标间隔 plt.show() plot_radar(r) #调用雷达图作图函数
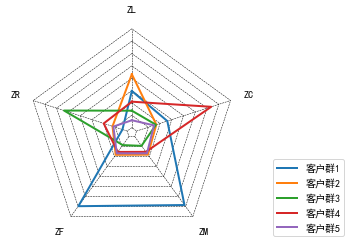
4、决策支持


三、【拓展思考】客户流失分析
1、目标

2、数据预处理
参考自https://blog.csdn.net/zhouchen1998/article/details/85113535
import pandas as pd
from datetime import datetime def clean(data):
'''
数据清洗,去除空记录
'''
data = data[data['SUM_YR_1'].notnull() & data['SUM_YR_2'].notnull()] # 票价非空值才保留 # 只保留票价非零的,或者平均折扣率与总飞行公里数同时为0的记录。
index1 = data['SUM_YR_1'] != 0
index2 = data['SUM_YR_2'] != 0
index3 = (data['SEG_KM_SUM'] == 0) & (data['avg_discount'] == 0) # 该规则是“与”
data = data[index1 | index2 | index3] # 该规则是“或” #取出需要的属性列
data = data[['LOAD_TIME', 'FFP_DATE', 'LAST_TO_END', 'FLIGHT_COUNT', 'avg_discount', 'SEG_KM_SUM', 'LAST_TO_END',
'P1Y_Flight_Count', 'L1Y_Flight_Count']]
return data def LRFMCK(data):
'''
经过计算得到我的指标数据
'''
# 其中K为标签标示用户类型
data2 = pd.DataFrame(columns=['L', 'R', 'F', 'M', 'C', 'K'])
time_list = []
for i in range(len(data['LOAD_TIME'])):
str1 = data['LOAD_TIME'][i].split('/')
str2 = data['FFP_DATE'][i].split('/')
temp = datetime(int(str1[0]), int(str1[1]), int(str1[2])) - datetime(int(str2[0]), int(str2[1]), int(str2[2]))
time_list.append(temp.days)
data2['L'] = pd.Series(time_list)
data2['R'] = data['LAST_TO_END']
data2['F'] = data['FLIGHT_COUNT']
data2['M'] = data['SEG_KM_SUM']
data2['C'] = data['avg_discount']
temp = data['L1Y_Flight_Count'] / data['P1Y_Flight_Count']
for i in range(len(temp)):
if temp[i] >=0.9:
# 未流失客户
temp[i] = 'A'
elif 0.5 < temp[i] < 0.9:
# 准流失客户
temp[i] = 'B'
else:
temp[i] = 'C'
data2['K'] = temp
data2.to_csv('data/data_changed.csv', encoding='utf-8') def standard():
'''
标准差标准化
'''
data = pd.read_csv('data/data_changed.csv', encoding='utf-8').iloc[:, 1:6]
# 简洁的语句实现了标准化变换,类似地可以实现任何想要的变换
data = (data - data.mean(axis=0)) / (data.std(axis=0))
data.columns = ['Z' + i for i in data.columns]
data2 = pd.read_csv('data/data_changed.csv', encoding='utf-8')
data['K'] = data2['K']
data.to_csv('data/data_standard.csv', index=False) if __name__ == '__main__':
data = pd.read_csv('data/air.csv', encoding='utf-8', engine='python')
data=clean(data)
data.to_csv('data/data_filter.csv', index = False, encoding='utf-8')
data = pd.read_csv('data/data_filter.csv', encoding='utf-8') #不重新读取的话,调用LRFMCK会报错,我也不知道为什么
LRFMCK(data)
standard()
不知道为什么,总是要反复写入文件和读取文件,不然会莫名其妙的报错。猜测可能是csv文件与xls文件不同导致

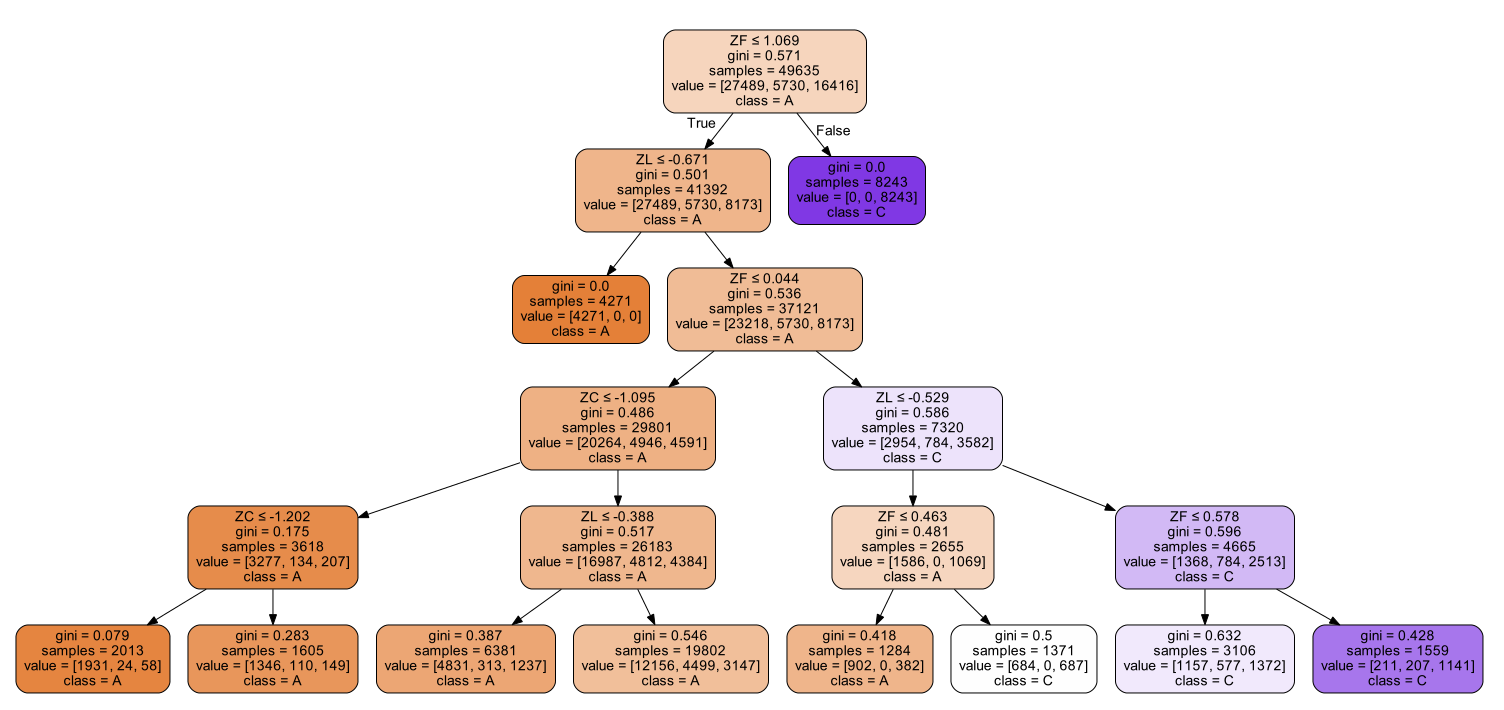
3、模型构建
import pandas as pd
from sklearn import tree
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix #导入混淆矩阵函数
import pydotplus # 读取数据
def getDataSet(fileName):
data = pd.read_csv(fileName)
dataSet = []
for item in data.values:
dataSet.append(list(item[:5]))
label = list(data['K'])
return dataSet, label # 作图评估
def cm_plot(y, yp):
cm = confusion_matrix(y, yp) #混淆矩阵
plt.matshow(cm, cmap=plt.cm.Greens) #画混淆矩阵图,配色风格使用cm.Greens,更多风格请参考官网。
plt.colorbar() #颜色标签
for x in range(len(cm)): #数据标签
for y in range(len(cm)):
plt.annotate(cm[x,y], xy=(x, y), horizontalalignment='center', verticalalignment='center')
plt.ylabel('True label') #坐标轴标签
plt.xlabel('Predicted label') #坐标轴标签
return plt data, label = getDataSet('data/data_standard.csv')
train_data, test_data, train_label, test_label = train_test_split(data, label, test_size=0.2) #使用决策树
clf = tree.DecisionTreeClassifier(max_depth=5)
clf = clf.fit(train_data, train_label) # 可视化
dataLabels = ['ZL', 'ZR', 'ZF', 'ZM', 'ZC', ]
data_list = []
data_dict = {}
for each_label in dataLabels:
for each in data:
data_list.append(each[dataLabels.index(each_label)])
data_dict[each_label] = data_list
data_list = []
lenses_pd = pd.DataFrame(data_dict)
#print(lenses_pd.keys()) #画决策树的决策流程
dot_data = StringIO()
tree.export_graphviz(clf, out_file=dot_data, feature_names=lenses_pd.keys(),
class_names=clf.classes_, filled=True, rounded=True, special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_pdf("tree.pdf") cm_plot(test_label, clf.predict(test_data)).show()

[Python数据挖掘]第7章、航空公司客户价值分析的更多相关文章
- Python数据挖掘-航空公司客户价值分析
出处:http://www.ithao123.cn/content-11127869.html 航空公司客户价值分析 目标:企业针对不同价值的客户制定个性化的服务,将有限的资源集中于高价值客户. 1. ...
- 航空公司客户价值分析(KMeans聚类)
PS.图片可能不清楚,代码 数据集都在 https://github.com/xubin97/Data-Mining_exp1 项目介绍: 本案例的目标是客户价值识别,通过航空公司客户数据识别不同价值 ...
- 基于R语言的航空公司客户价值分析
分析航空公司现状 1.行业内竞争 民航的竞争除了三大航空公司之间的竞争之外,还将加入新崛起的各类小型航空公司.民营航空公司,甚至国外航空巨头.航空产品生产过剩,产品同质化特征愈加明显,于是航空公司从价 ...
- 利用KMeans聚类进行航空公司客户价值分析
准确的客户分类的结果是企业优化营销资源的重要依据,本文利用了航空公司的部分数据,利用Kmeans聚类方法,对航空公司的客户进行了分类,来识别出不同的客户群体,从来发现有用的客户,从而对不同价值的客户类 ...
- [Python数据挖掘]第6章、电力窃漏电用户自动识别
一.背景与挖掘目标 相关背景自查 二.分析方法与过程 1.EDA(探索性数据分析) 1.分布分析 2.周期性分析 2.数据预处理 1.数据清洗 过滤非居民用电数据,过滤节假日用电数据(节假日用电量明显 ...
- [Python数据挖掘]第4章、数据预处理
数据预处理主要包括数据清洗.数据集成.数据变换和数据规约,处理过程如图所示. 一.数据清洗 1.缺失值处理:删除.插补.不处理 ## 拉格朗日插值代码(使用缺失值前后各5个未缺失的数据建模) impo ...
- [Python数据挖掘]第2章、Python数据分析简介
<Python数据分析与挖掘实战>的数据和代码,可从“泰迪杯”竞赛网站(http://www.tipdm.org/tj/661.jhtml)下载获得 1.Python数据结构 2.Nump ...
- [Python数据挖掘]第8章、中医证型关联规则挖掘
一.背景和挖掘目标 二.分析方法与过程 1.数据获取 2.数据预处理 1.筛选有效问卷(根据表8-6的标准) 共发放1253份问卷,其中有效问卷数为930 2.属性规约 3.数据变换 ''' 聚类 ...
- [Python数据挖掘]第5章、挖掘建模(下)
四.关联规则 Apriori算法代码(被调函数部分没怎么看懂) from __future__ import print_function import pandas as pd #自定义连接函数,用 ...
随机推荐
- ORACLE中dba,user,v$等开头的常用表和视图
一.Oracle表明细及说明1.dba_开头表 dba_users 数据库用户信息 dba_segments 表段信息 dba_extents ...
- JS操作字符串
JS操作字符串 1.函数:split() 把字符串按分隔符分割成数组. 语法:字符串.split(separator,limit); separator:分隔符. 功能:使用一个指定的分隔符把一个字符 ...
- tomcat 启动方式
<?xml version="1.0" encoding="UTF-8"?><Context docBase="wexin" ...
- TCP三次握手那些事
临近5月,春招和实习招聘逐渐进入尾声.本文主要讨论面试中经常提问的TCP连接的机制,附带一些扩展知识. 参加面试的时候,过半的面试官都会问TCP相关问题,而最常见的问题就是:讲一下TCP三次握手(四次 ...
- poj1416
#include<iostream> using namespace std; int target,datanum; ],temproad[]; int N,flag,maxsum; ] ...
- MongoDB - 2
Aggregation Framework: $project: a document stream by renaming, adding, or removing fields #alter Da ...
- php 数据库乱码。。。php 移动临时文件
数据库乱码,三个位置 处理好不会乱码 第一前台,传到后台: 第二后台,传到数据库: 第三数据库,存入数据库: 详解 https://www.cnblogs.com/zhoujinyi/p/46188 ...
- table的thead,tbody,tfoot
为了让大表格(table)在下载的时候可以分段的显示,就是说在浏览器解析HTML时,table是作为一个整体解释的,使用tbody可以优化显示. 如果表格很长,用tbody分段,可以一部分一部分地显示 ...
- Uncaught TypeError: Cannot read property 'getters' of undefined
vuex下新建的模板没有加 export default permission导致错误
- 后台发送get请求
第一步:编写Controller,让后台去请求接口 package controller; import java.util.List; import org.springframework.bean ...