IMPLEMENTING A GRU/LSTM RNN WITH PYTHON AND THEANO - 学习笔记
catalogue
. 引言
. LSTM NETWORKS
. LSTM 的变体
. GRUs (Gated Recurrent Units)
. IMPLEMENTATION GRUs
0. 引言
In this post we’ll learn about LSTM (Long Short Term Memory) networks and GRUs (Gated Recurrent Units). LSTMs were first proposed in 1997 by Sepp Hochreiter and Jürgen Schmidhuber, and are among the most widely used models in Deep Learning for NLP today. GRUs, first used in 2014, are a simpler variant of LSTMs that share many of the same properties. Let’s start by looking at LSTMs, and then we’ll see how GRUs are different.
0x1: 长期依赖(Long-Term Dependencies)问题
RNN 的关键点之一就是他们可以用来连接先前的信息到当前的任务上,例如使用过去的视频段来推测对当前段的理解。如果 RNN 可以做到这个,他们就变得非常有用。但是真的可以么?答案是,还有很多依赖因素。
有时候,我们仅仅需要知道先前的信息来执行当前的任务。例如,我们有一个语言模型用来基于先前的词来预测下一个词。如果我们试着预测 “the clouds are in the sky” 最后的词,我们并不需要任何其他的上下文 —— 因此下一个词很显然就应该是 sky。在这样的场景中,相关的信息和预测的词位置之间的间隔是非常小的,RNN 可以学会使用先前的信息。

但是同样会有一些更加复杂的场景。假设我们试着去预测“I grew up in France... I speak fluent French”最后的词。当前的信息建议下一个词可能是一种语言的名字,但是如果我们需要弄清楚是什么语言,我们是需要先前提到的离当前位置很远的 France 的上下文的。这说明相关信息和当前预测位置之间的间隔就肯定变得相当的大。
不幸的是,在这个间隔不断增大时,RNN 会丧失学习到连接如此远的信息的能力。

Relevant Link:
http://www.wildml.com/2015/10/recurrent-neural-network-tutorial-part-4-implementing-a-grulstm-rnn-with-python-and-theano/
1. LSTM NETWORKS
0x1: LSTM如何从模型结构上规避"长周期依赖梯度消失问题"
In previous post we looked at how the vanishing gradient problem prevents standard RNNs from learning long-term dependencies.

LSTMs were designed to combat vanishing gradients through a gating mechanism. To understand what this means, let’s look at how a LSTM calculates a hidden state 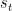


These equations look quite complicated, but actually it’s not that hard. First, notice that a LSTM layer is just another way to compute a hidden state. Previously, we computed the hidden state as 
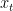
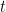

直观上来说,i可以理解为"是否要让本次记忆细胞通过",g可以理解为"本次要通过多少记忆",而i * g乘法可以增加复杂性,通过sigmoid的关系动态调整最终的输入o是否要通过和通过多少

LSTM 通过刻意的设计来避免长期依赖问题。记住长期的信息在实践中是 LSTM 的默认行为,而非需要付出很大代价才能获得的能力,所有 RNN 都具有一种重复神经网络模块的链式的形式。在标准的 RNN 中,这个重复的模块只有一个非常简单的结构,例如一个 tanh 层。我们知道,代价函数的反馈难以让网络前端的神经元学习到本质是"梯度消失问题",即因为偏导数链式求导的关系,导致代价函数C值不断被稀释。LSTM 同样是这样的结构,但是重复的模块拥有一个不同的结构。不同于 单一神经网络层,这里是有四个,以一种非常特殊的方式进行交互

图中图标示例如下,在上面的图例中,每一条黑线传输着一整个向量,从一个节点的输出到其他节点的输入。粉色的圈代表 pointwise 的操作,诸如向量的和,而黄色的矩阵就是学习到的神经网络层。合在一起的线表示向量的连接,分开的线表示内容被复制,然后分发到不同的位置

0x2: LSTM 的核心思想
LSTM 有通过精心设计的称作为"门"的结构(门是一个LSTM神经元里面的一个子结构)来去除或者增加信息到细胞状态的能力。门是一种让信息"选择式通过"的方法。他们包含一个 sigmoid 神经网络层和一个 pointwise 乘法操作

Sigmoid 层输出 0 到 1 之间的数值,描述每个部分有多少量可以通过。0 代表“不许任何量通过”,1 就指“允许任意量通过"。LSTM 拥有三个门,来保护和控制细胞状态。
1. 忘记门
在我们 LSTM 中的第一步是决定我们会从细胞状态中丢弃什么信息。这个决定通过一个称为忘记门层完成。该门会读取 h_{t-1} 和 x_t,输出一个在 0 到 1 之间的数值给每个在细胞状态 C_{t-1} 中的数字。1 表示“完全保留”,0 表示“完全舍弃”。
让我们回到语言模型的例子中来基于已经看到的预测下一个词。在这个问题中,细胞状态可能包含当前主语的性别,因此正确的代词可以被选择出来。当我们看到新的主语,我们希望忘记旧的主语

2. 输入门层 和 tanh层
下一步是确定什么样的新信息被存放在细胞状态中。这里包含两个部分
. 第一,sigmoid 层称 “输入门层” 决定什么值我们将要更新
. 然后,一个 tanh 层创建一个新的候选值向量,C_t,会被加入到状态中

接着,我们把旧状态与 f_t 相乘,丢弃掉我们确定需要丢弃的信息。接着加上 i_t * {C}_t。这就是新的候选值,根据我们决定更新每个状态的程度进行变化。
在语言模型的例子中,这就是我们实际根据前面确定的目标,丢弃旧代词的性别信息并添加新的信息的地方

3. 输出门
最终,我们需要确定输出什么值。这个输出将会基于我们的细胞状态,但是也是一个过滤后的版本
. 首先,我们运行一个 sigmoid 层来确定细胞状态的哪个部分将输出出去
. 接着,我们把细胞状态C_t通过 tanh 进行处理(得到一个在 - 到 之间的值)并将它和 sigmoid 门的输出相乘,最终我们仅仅会输出我们确定输出的那部分(选择性输出)
在语言模型的例子中,因为他就看到了一个 代词,可能需要输出与一个 动词 相关的信息。例如,可能输出是否代词是单数还是负数,这样如果是动词的话,我们也知道动词需要进行的词形变化

Intuitively, plain RNNs could be considered a special case of LSTMs. If you fix the input gate all 1’s, the forget gate to all 0’s (you always forget the previous memory) and the output gate to all one’s (you expose the whole memory) you almost get standard RNN. There’s just an additional 
Relevant Link:
http://colah.github.io/posts/2015-08-Understanding-LSTMs/
2. LSTM 的变体
不是所有的 LSTM 都长成一个样子的。实际上,几乎所有包含 LSTM 的论文都采用了微小的变体。差异非常小
0x1: peephole connection
一个流形的 LSTM 变体,就是由 Gers & Schmidhuber (2000) 提出的,增加了 “peephole connection”。是说,我们让 门层 也会接受细胞状态的输入

上面的图例中,我们增加了 peephole 到每个门上
0x2: coupled 忘记和输入门
通过使用 coupled 忘记和输入门。不同于之前是分开确定什么忘记和需要添加什么新的信息,这里是一同做出决定
. 我们仅仅会当我们将要输入在当前位置时忘记
. 我们仅仅输入新的值到那些我们已经忘记旧的信息的那些状态

Relevant Link:
https://arxiv.org/pdf/1503.04069.pdf
3. GRUs (Gated Recurrent Units)
GRUs本质上也是LSTM的一个变体,因为使用的比较多,这里单独列一章节讨论。它将忘记门和输入门合成了一个单一的 更新门。同样还混合了细胞状态和隐藏状态,和其他一些改动。最终的模型比标准的 LSTM 模型要简单,也是非常流行的变体。
The idea behind a GRU layer is quite similar to that of a LSTM layer, as are the equations.

A GRU has two gates
. a reset gate r
. an update gate z
Intuitively, the reset gate determines how to combine the new input with the previous memory, and the update gate defines how much of the previous memory to keep around. If we set the reset to all 1’s and update gate to all 0’s we again arrive at our plain RNN model(类LSTM模型和传统RNN最大的区别就在于它使用了门来进行选择性遗忘和记忆). The basic idea of using a gating mechanism to learn long-term dependencies is the same as in a LSTM, but there are a few key differences:
- A GRU has two gates, an LSTM has three gates.
- GRUs don’t possess and internal memory (
) that is different from the exposed hidden state. They don’t have the output gate that is present in LSTMs.
- The input and forget gates are coupled by an update gate
and the reset gate
is applied directly to the previous hidden state. Thus, the responsibility of the reset gate in a LSTM is really split up into both
- We don’t apply a second nonlinearity when computing the output.

Relevant Link:
http://www.jianshu.com/p/9dc9f41f0b29
4. IMPLEMENTATION GRUs
Remember that a GRU (LSTM) layer is just another way of computing the hidden state. So all we really need to do is change the hidden state computation in our forward propagation function.
def forward_prop_step(x_t, s_t1_prev):
# This is how we calculated the hidden state in a simple RNN. No longer!
# s_t = T.tanh(U[:,x_t] + W.dot(s_t1_prev)) # Get the word vector
x_e = E[:,x_t] # GRU Layer
z_t1 = T.nnet.hard_sigmoid(U[].dot(x_e) + W[].dot(s_t1_prev) + b[])
r_t1 = T.nnet.hard_sigmoid(U[].dot(x_e) + W[].dot(s_t1_prev) + b[])
c_t1 = T.tanh(U[].dot(x_e) + W[].dot(s_t1_prev * r_t1) + b[])
s_t1 = (T.ones_like(z_t1) - z_t1) * c_t1 + z_t1 * s_t1_prev # Final output calculation
# Theano's softmax returns a matrix with one row, we only need the row
o_t = T.nnet.softmax(V.dot(s_t1) + c)[] return [o_t, s_t1]
0x1: code
train.py
#! /usr/bin/env python import sys
import os
import time
import numpy as np
from utils import *
from datetime import datetime
from gru_theano import GRUTheano LEARNING_RATE = float(os.environ.get("LEARNING_RATE", "0.001"))
VOCABULARY_SIZE = int(os.environ.get("VOCABULARY_SIZE", ""))
EMBEDDING_DIM = int(os.environ.get("EMBEDDING_DIM", ""))
HIDDEN_DIM = int(os.environ.get("HIDDEN_DIM", ""))
NEPOCH = int(os.environ.get("NEPOCH", ""))
MODEL_OUTPUT_FILE = os.environ.get("MODEL_OUTPUT_FILE")
INPUT_DATA_FILE = os.environ.get("INPUT_DATA_FILE", "./data/reddit-comments-2015.csv")
PRINT_EVERY = int(os.environ.get("PRINT_EVERY", "")) if not MODEL_OUTPUT_FILE:
ts = datetime.now().strftime("%Y-%m-%d-%H-%M")
MODEL_OUTPUT_FILE = "GRU-%s-%s-%s-%s.dat" % (ts, VOCABULARY_SIZE, EMBEDDING_DIM, HIDDEN_DIM) # Load data
x_train, y_train, word_to_index, index_to_word = load_data(INPUT_DATA_FILE, VOCABULARY_SIZE) # Build model
model = GRUTheano(VOCABULARY_SIZE, hidden_dim=HIDDEN_DIM, bptt_truncate=-) # Print SGD step time
t1 = time.time()
model.sgd_step(x_train[], y_train[], LEARNING_RATE)
t2 = time.time()
print "SGD Step time: %f milliseconds" % ((t2 - t1) * .)
sys.stdout.flush() # We do this every few examples to understand what's going on
def sgd_callback(model, num_examples_seen):
dt = datetime.now().isoformat()
loss = model.calculate_loss(x_train[:], y_train[:])
print("\n%s (%d)" % (dt, num_examples_seen))
print("--------------------------------------------------")
print("Loss: %f" % loss)
generate_sentences(model, , index_to_word, word_to_index)
save_model_parameters_theano(model, MODEL_OUTPUT_FILE)
print("\n")
sys.stdout.flush() for epoch in range(NEPOCH):
train_with_sgd(model, x_train, y_train, learning_rate=LEARNING_RATE, nepoch=, decay=0.9,
callback_every=PRINT_EVERY, callback=sgd_callback)
gru_theano.py
# -*- coding: utf- -*- import numpy as np
import theano as theano
import theano.tensor as T
from theano.gradient import grad_clip
import time
import operator class GRUTheano:
def __init__(self, word_dim, hidden_dim=, bptt_truncate=-):
# Assign instance variables
self.word_dim = word_dim
self.hidden_dim = hidden_dim
self.bptt_truncate = bptt_truncate
# Initialize the network parameters
E = np.random.uniform(-np.sqrt(. / word_dim), np.sqrt(. / word_dim), (hidden_dim, word_dim))
U = np.random.uniform(-np.sqrt(. / hidden_dim), np.sqrt(. / hidden_dim), (, hidden_dim, hidden_dim))
W = np.random.uniform(-np.sqrt(. / hidden_dim), np.sqrt(. / hidden_dim), (, hidden_dim, hidden_dim))
V = np.random.uniform(-np.sqrt(. / hidden_dim), np.sqrt(. / hidden_dim), (word_dim, hidden_dim))
b = np.zeros((, hidden_dim))
c = np.zeros(word_dim)
# Theano: Created shared variables
self.E = theano.shared(name='E', value=E.astype(theano.config.floatX))
self.U = theano.shared(name='U', value=U.astype(theano.config.floatX))
self.W = theano.shared(name='W', value=W.astype(theano.config.floatX))
self.V = theano.shared(name='V', value=V.astype(theano.config.floatX))
self.b = theano.shared(name='b', value=b.astype(theano.config.floatX))
self.c = theano.shared(name='c', value=c.astype(theano.config.floatX))
# SGD / rmsprop: Initialize parameters
self.mE = theano.shared(name='mE', value=np.zeros(E.shape).astype(theano.config.floatX))
self.mU = theano.shared(name='mU', value=np.zeros(U.shape).astype(theano.config.floatX))
self.mV = theano.shared(name='mV', value=np.zeros(V.shape).astype(theano.config.floatX))
self.mW = theano.shared(name='mW', value=np.zeros(W.shape).astype(theano.config.floatX))
self.mb = theano.shared(name='mb', value=np.zeros(b.shape).astype(theano.config.floatX))
self.mc = theano.shared(name='mc', value=np.zeros(c.shape).astype(theano.config.floatX))
# We store the Theano graph here
self.theano = {}
self.__theano_build__() def __theano_build__(self):
E, V, U, W, b, c = self.E, self.V, self.U, self.W, self.b, self.c x = T.ivector('x')
y = T.ivector('y') def forward_prop_step(x_t, s_t1_prev, s_t2_prev):
# This is how we calculated the hidden state in a simple RNN. No longer!
# s_t = T.tanh(U[:,x_t] + W.dot(s_t1_prev)) # Word embedding layer
x_e = E[:, x_t] # GRU Layer
z_t1 = T.nnet.hard_sigmoid(U[].dot(x_e) + W[].dot(s_t1_prev) + b[])
r_t1 = T.nnet.hard_sigmoid(U[].dot(x_e) + W[].dot(s_t1_prev) + b[])
c_t1 = T.tanh(U[].dot(x_e) + W[].dot(s_t1_prev * r_t1) + b[])
s_t1 = (T.ones_like(z_t1) - z_t1) * c_t1 + z_t1 * s_t1_prev # GRU Layer
z_t2 = T.nnet.hard_sigmoid(U[].dot(s_t1) + W[].dot(s_t2_prev) + b[])
r_t2 = T.nnet.hard_sigmoid(U[].dot(s_t1) + W[].dot(s_t2_prev) + b[])
c_t2 = T.tanh(U[].dot(s_t1) + W[].dot(s_t2_prev * r_t2) + b[])
s_t2 = (T.ones_like(z_t2) - z_t2) * c_t2 + z_t2 * s_t2_prev # Final output calculation
# Theano's softmax returns a matrix with one row, we only need the row
o_t = T.nnet.softmax(V.dot(s_t2) + c)[] return [o_t, s_t1, s_t2] [o, s, s2], updates = theano.scan(
forward_prop_step,
sequences=x,
truncate_gradient=self.bptt_truncate,
outputs_info=[None,
dict(initial=T.zeros(self.hidden_dim)),
dict(initial=T.zeros(self.hidden_dim))]) prediction = T.argmax(o, axis=)
o_error = T.sum(T.nnet.categorical_crossentropy(o, y)) # Total cost (could add regularization here)
cost = o_error # Gradients
dE = T.grad(cost, E)
dU = T.grad(cost, U)
dW = T.grad(cost, W)
db = T.grad(cost, b)
dV = T.grad(cost, V)
dc = T.grad(cost, c) # Assign functions
self.predict = theano.function([x], o)
self.predict_class = theano.function([x], prediction)
self.ce_error = theano.function([x, y], cost)
self.bptt = theano.function([x, y], [dE, dU, dW, db, dV, dc]) # SGD parameters
learning_rate = T.scalar('learning_rate')
decay = T.scalar('decay') # rmsprop cache updates
mE = decay * self.mE + ( - decay) * dE **
mU = decay * self.mU + ( - decay) * dU **
mW = decay * self.mW + ( - decay) * dW **
mV = decay * self.mV + ( - decay) * dV **
mb = decay * self.mb + ( - decay) * db **
mc = decay * self.mc + ( - decay) * dc ** self.sgd_step = theano.function(
[x, y, learning_rate, theano.Param(decay, default=0.9)],
[],
updates=[(E, E - learning_rate * dE / T.sqrt(mE + 1e-)),
(U, U - learning_rate * dU / T.sqrt(mU + 1e-)),
(W, W - learning_rate * dW / T.sqrt(mW + 1e-)),
(V, V - learning_rate * dV / T.sqrt(mV + 1e-)),
(b, b - learning_rate * db / T.sqrt(mb + 1e-)),
(c, c - learning_rate * dc / T.sqrt(mc + 1e-)),
(self.mE, mE),
(self.mU, mU),
(self.mW, mW),
(self.mV, mV),
(self.mb, mb),
(self.mc, mc)
]) def calculate_total_loss(self, X, Y):
return np.sum([self.ce_error(x, y) for x, y in zip(X, Y)]) def calculate_loss(self, X, Y):
# Divide calculate_loss by the number of words
num_words = np.sum([len(y) for y in Y])
return self.calculate_total_loss(X, Y) / float(num_words)

Relevant Link:
http://www.wildml.com/2015/10/recurrent-neural-network-tutorial-part-4-implementing-a-grulstm-rnn-with-python-and-theano/
https://github.com/dennybritz/rnn-tutorial-gru-lstm/blob/master/gru_theano.py
Copyright (c) 2017 LittleHann All rights reserved
IMPLEMENTING A GRU/LSTM RNN WITH PYTHON AND THEANO - 学习笔记的更多相关文章
- Requests:Python HTTP Module学习笔记(一)(转)
Requests:Python HTTP Module学习笔记(一) 在学习用python写爬虫的时候用到了Requests这个Http网络库,这个库简单好用并且功能强大,完全可以代替python的标 ...
- python网络爬虫学习笔记
python网络爬虫学习笔记 By 钟桓 9月 4 2014 更新日期:9月 4 2014 文章文件夹 1. 介绍: 2. 从简单语句中開始: 3. 传送数据给server 4. HTTP头-描写叙述 ...
- Python Built-in Function 学习笔记
Python Built-in Function 学习笔记 1. 匿名函数 1.1 什么是匿名函数 python允许使用lambda来创建一个匿名函数,匿名是因为他不需要以标准的方式来声明,比如def ...
- Python快速入门学习笔记(二)
注:本学习笔记参考了廖雪峰老师的Python学习教程,教程地址为:http://www.liaoxuefeng.com/wiki/001374738125095c955c1e6d8bb49318210 ...
- python数据分析入门学习笔记
学习利用python进行数据分析的笔记&下星期二内部交流会要讲的内容,一并分享给大家.博主粗心大意,有什么不对的地方欢迎指正~还有许多尚待完善的地方,待我一边学习一边完善~ 前言:各种和数据分 ...
- python网络爬虫学习笔记(二)BeautifulSoup库
Beautiful Soup库也称为beautiful4库.bs4库,它可用于解析HTML/XML,并将所有文件.字符串转换为'utf-8'编码.HTML/XML文档是与“标签树一一对应的.具体地说, ...
- Python之xml学习笔记
XML处理模块 xml是实现不同语言或程序之间进行数据交换的协议,跟json差不多,但json使用起来更简单,至今很多传统公司如金融行业的很多系统的接口还主要是xml. xml的格式如下,就是通过&l ...
- python网络爬虫学习笔记(一)Request库
一.Requests库的基本说明 引入Rquests库的代码如下 import requests 库中支持REQUEST, GET, HEAD, POST, PUT, PATCH, DELETE共7个 ...
- Python基础教程学习笔记:第一章 基础知识
Python基础教程 第二版 学习笔记 1.python的每一个语句的后面可以添加分号也可以不添加分号:在一行有多条语句的时候,必须使用分号加以区分 2.查看Python版本号,在Dos窗口中输入“p ...
随机推荐
- Python XML解析之DOM
DOM说明: DOM:Document Object Model API DOM是一种跨语言的XML解析机制,DOM把整个XML文件或字符串在内存中解析为树型结构方便访问. https://docs. ...
- SQLServer之UNIQUE约束
UNIQUE约束添加规则 1.唯一约束确保表中的一列数据没有相同的值. 2.与主键约束类似,唯一约束也强制唯一性,但唯一约束用于非主键的一列或者多列的组合,且一个表可以定义多个唯一约束. 使用SSMS ...
- SQL UCASE() 函数
UCASE() 函数 UCASE 函数把字段的值转换为大写. SQL UCASE() 语法 SELECT UCASE(column_name) FROM table_name SQL UCASE() ...
- Java 通过地址获取经纬度 - 高德地图
一.添加依赖 <dependency> <groupId>org.hibernate</groupId> <artifactId>hibernate-v ...
- springMVC第二天——高级参数绑定与其它特性
大纲摘要: 1.高级参数绑定 a) 数组类型的参数绑定 b) List类型的绑定 2.@RequestMapping注解的使用 3.Controller方法返回值 4.Springmvc中异常处理 5 ...
- MicroPython实例之TPYBoard开发板控制OLED显示中文
0x00 前言 之前看到一篇文章是关于TPYBoard v102控制OLED屏显示的,看到之后就想尝试一下使用OLED屏来显示中文.最近利用空余时间搞定了这个实验,特此将实验过程及源码分享出来,方便以 ...
- Golang 入门系列(五)GO语言中的面向对象
前面讲了很多Go 语言的基础知识,包括go环境的安装,go语言的语法等,感兴趣的朋友可以先看看之前的文章.https://www.cnblogs.com/zhangweizhong/category/ ...
- 基于HTML5 的互联网+地铁行业
前言 近几年,互联网与交通运输的融合,改变了交易模式,影响着运输组织和经营方式,改变了运输主体的市场结构.模糊了运营与非营运的界限,也更好的实现了交通资源的集约共享,同时使得更多依靠外力和企业推动交通 ...
- 个人hp笔记本默认设置更改
1.将F1-F12默认的多媒体键(调静音亮度控制声音大小等)改为功能键: (****笔记本型号为惠普****) ·进入BIOS方法:关机状态下,按电源键开机,立刻连续多次点击ESC,看到 F1.F2. ...
- 【学习总结】GirlsInAI ML-diary day-7-数据类型转换
[学习总结]GirlsInAI ML-diary 总 原博github链接-day7 回顾之前见到的常见数据类型 int 整数 float 浮点数 bool 布尔值 string 字符串 ... 1- ...