Kafka基础简介
kafka是一个分布式的,可分区的,可备份的日志提交服务,它使用独特的设计实现了一个消息系统的功能。 由于最近项目升级,需要将spring的事件机制转变为消息机制,针对后期考虑,选择了kafka作为消息中间件。
kafka的安装
这里为了快速搭建,选择用docker
docker run -d -p 2181:2181 -p 9092:9092 -v /opt/kafka/server.properties:/opt/kafka_2.11-0.10.1.0/config/server.properties --env ADVERTISED_HOST='ip' --env ADVERTISED_PORT=9092 spotify/kafka
kafka的基本概念
这里参照 官网 共有以下几点
Topic:特指Kafka处理的消息源的不同分类,其实也可以理解为对不同消息源的区分的一个标识;
Partition:Topic物理上的分组,一个topic可以设置为多个partition,每个partition都是一个有序的队列,partition中的每条消息都会被分配一个有序的id(offset);
Message:消息,是通信的基本单位,每个producer可以向一个topic(主题)发送一些消息;
Producers:消息和数据生产者,向Kafka的一个topic发送消息的过程叫做producers(producer可以选择向topic哪一个partition发送数据)。
Consumers:消息和数据消费者,接收topics并处理其发布的消息的过程叫做consumer,同一个topic的数据可以被多个consumer接收;
Broker:缓存代理,Kafka集群中的一台或多台服务器统称为broker。
这里有一点是需要注意的
consumer是一个抽象的概念,调用Consumer API的程序都可以称作为一个consumer,它从broker端订阅某个topic的消息。如果只有一个consumer的话,该topic(可能含有多个partition)下所有消息都会被这个consumer接收。但是在分布式的环境中,我们可能会遇到这样一种情景,对于一个有多个partition的topic,我们希望启动多个consumer去消费这些partition(如果发送速度较快,一个consumer是无法消费完的),并且要求topic的一条消息只能发给其中一个consumer,不希望这些conusmer出现重复接收一条消息的情况。对于这种情况,我们应该怎么办呢?kafka给我们提供了一种机制,可以很好来适应这种情况,那就是consumer group(当然也可以应用在第一种情况,实际上,如果只有一个consumer时,是不需要指定consumer group,这时kafka会自动给这个consumer生成一个group名)。
在调用conusmer API时,一般都会指定一个consumer group,该group订阅的topic的每一条消息都发送到这个group的某一台机器上。借用官网一张图来详细介绍一下这种情况,假如kafka集群有两台broker,集群上有一个topic,它有4个partition,partition 0和1在broker1上,partition 2和3在broker2上,这时有两个consumer group同时订阅这个topic,其中一个group有2个consumer,另一个consumer有4个consumer,则它们的订阅消息情况如下图所示:
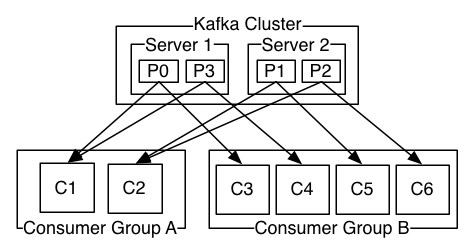
如果group中的consumer数小于topic中的partition数,那么group中的consumer就会消费多个partition;
如果group中的consumer数等于topic中的partition数,那么group中的一个consumer就会消费topic中的一个partition;
如果group中的consumer数大于topic中的partition数,那么group中就会有一部分的consumer处于空闲状态。
同时,同一个gruopid下多个consumer订阅同一个topic,只有一个consumer能消费到数据。
下面我们开始集成kafka到系统
增加pom文件
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.10.1.0</version>
</dependency>
配置文件:
kafka.consumer.zookeeper.connect=ip:2181
kafka.consumer.servers=ip:9092
kafka.consumer.enable.auto.commit=true
kafka.consumer.session.timeout=6000
#消费者偏移提交给zookeeper的频率(以毫秒为单位)
kafka.consumer.auto.commit.interval=100
kafka.consumer.auto.offset.reset=latest
#kafka.consumer.topic=test
kafka.consumer.group.id=test
#根据配置的spring.kafka.listener.concurrency来生成多个并发的KafkaMessageListenerContainer实例
kafka.consumer.concurrency=10 kafka.producer.servers=ip:9092
#生产者重试次数
kafka.producer.retries=0
#每当多个记录被发送到同一分区时,生产者将尝试将记录一起批量处理为更少的请求。
# 这有助于客户端和服务器上的性能。此配置控制默认批量大小(以字节为单位)。
kafka.producer.batch.size=4096
#在正常负载的情况下, 要想减少请求的数量. 加上一个认为的延迟:
# 不是立即发送消息, 而是延迟等待更多的消息一起批量发送. 类似TCP中的Nagle算法
kafka.producer.linger=100
#producer可以使用的最大内存来缓存等待发送到server端的消息
kafka.producer.buffer.memory=40960
生产者配置类
@Configuration
@EnableKafka
public class KafkaProducerConfig {
@Value("${kafka.producer.servers}")
private String servers;
@Value("${kafka.producer.retries}")
private int retries;
@Value("${kafka.producer.batch.size}")
private int batchSize;
@Value("${kafka.producer.linger}")
private int linger;
@Value("${kafka.producer.buffer.memory}")
private int bufferMemory; public Map<String, Object> producerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, servers);
props.put(ProducerConfig.RETRIES_CONFIG, retries);
props.put(ProducerConfig.BATCH_SIZE_CONFIG, batchSize);
props.put(ProducerConfig.LINGER_MS_CONFIG, linger);
props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, bufferMemory);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
return props;
}
public ProducerFactory<String, String> producerFactory() {
return new DefaultKafkaProducerFactory<>(producerConfigs());
}
@Bean
public KafkaTemplate<String, String> kafkaTemplate() {
return new KafkaTemplate<String, String>(producerFactory());
}
}
消费者配置类
@Configuration
@EnableKafka
public class KafkaConsumerConfig {
@Value("${kafka.consumer.servers}")
private String servers;
@Value("${kafka.consumer.enable.auto.commit}")
private boolean enableAutoCommit;
@Value("${kafka.consumer.session.timeout}")
private String sessionTimeout;
@Value("${kafka.consumer.auto.commit.interval}")
private String autoCommitInterval;
@Value("${kafka.consumer.group.id}")
private String groupId;
@Value("${kafka.consumer.auto.offset.reset}")
private String autoOffsetReset;
@Value("${kafka.consumer.concurrency}")
private int concurrency; @Bean
public KafkaListenerContainerFactory<ConcurrentMessageListenerContainer<String, String>> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
factory.setConcurrency(concurrency);
factory.getContainerProperties().setPollTimeout(3000);
return factory;
} public ConsumerFactory<String, String> consumerFactory() {
return new DefaultKafkaConsumerFactory<>(consumerConfigs());
} public Map<String, Object> consumerConfigs() {
Map<String, Object> propsMap = new HashMap<>();
propsMap.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, servers);
propsMap.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, enableAutoCommit);
propsMap.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, autoCommitInterval);
propsMap.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, sessionTimeout);
propsMap.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
propsMap.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
propsMap.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
propsMap.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, autoOffsetReset);
return propsMap;
}
}
生产者
@Component
public class KafkaSender {
private static final Logger logger = LoggerFactory.getLogger(KafkaSender.class);
@Autowired
private KafkaTemplate<String, String> kafkaTemplate; /**
* 发送消息方法
*/
public void send() {
Message message = new Message();
message.setId(System.currentTimeMillis());
message.setMsg(UUID.randomUUID().toString());
message.setSendTime(new Date());
logger.info("+++++++++++++++++++++ message = {}", JSON.toJSONString(message));
kafkaTemplate.send("xmz", JSON.toJSONString(message));
}
消费者
@Component
public class KafkaReceiver3 {
private static final Logger logger = LoggerFactory.getLogger(KafkaReceiver3.class); @KafkaListener(topics = {"xmz"})
public void listen(ConsumerRecord <?, ?>> record) {
Optional<?> kafkaMessage = Optional.ofNullable(record.value());
if (kafkaMessage.isPresent()) {
longAdder.increment();
Object message = kafkaMessage.get();
int partition = record.partition();
logger.info("----------------- record =" + record);
logger.info("------------------ message =" + message);
}
} }
以上,我们就把kafka集成进来了
Kafka基础简介的更多相关文章
- 最简单流处理引擎——Kafka Streaming简介
Kafka在0.10.0.0版本以前的定位是分布式,分区化的,带备份机制的日志提交服务.而kafka在这之前也没有提供数据处理的顾服务.大家的流处理计算主要是还是依赖于Storm,Spark Stre ...
- [转帖]kafka基础知识点总结
kafka基础知识点总结 https://blog.csdn.net/qq_25445087/article/details/80270790 需要学习. 1.kafka简介 kafka是由Apach ...
- 现代3D图形编程学习-基础简介(2) (译)
本书系列 现代3D图形编程学习 基础简介(2) 图形和渲染 接下去的内容对渲染的过程进行粗略介绍.遇到的部分内容不是很明白也没有关系,在接下去的章节中,会被具体阐述. 你在电脑屏幕上看到的任何东西,包 ...
- 现代3D图形编程学习-基础简介(1) (译)
本书系列 现代3D图形编程学习 基础简介 并不像本书的其他章节,这章内容没有相关的源代码或是项目.本章,我们将讨论向量,图形渲染理论,以及OpenGL. 向量 在阅读这本书的时候,你需要熟悉代数和几何 ...
- kafka原理简介并且与RabbitMQ的选择
kafka原理简介并且与RabbitMQ的选择 kafka原理简介,rabbitMQ介绍,大致说一下区别 Kafka是由LinkedIn开发的一个分布式的消息系统,使用Scala编写,它以可水平扩展和 ...
- Zookeeper与Kafka基础概念和原理
1.zookeeper概念介绍 在介绍ZooKeeper之前,先来介绍一下分布式协调技术,所谓分布式协调技术主要是用来解决分布式环境当中多个进程之间的同步控制,让他们有序的去访问某种共享资源,防止造成 ...
- kafka 基础知识梳理及集群环境部署记录
一.kafka基础介绍 Kafka是最初由Linkedin公司开发,是一个分布式.支持分区的(partition).多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特 ...
- Kafka(1)--kafka基础知识
Kafka 的简介: Kafka 是一款分布式消息发布和订阅系统,具有高性能.高吞吐量的特点而被广泛应用与大数据传输场景.它是由 LinkedIn 公司开发,使用 Scala 语言编写,之后成为 Ap ...
- 1.CSS基础简介
一.基础简介 1.简介 CSS(Cascading Style Sheet)可译为“层叠样式表”或“级联样式表”,它定义如何显示 HTML 元素,用于控制Web页面的外观.通过使用CSS实现页面的内容 ...
随机推荐
- 数据库SQLServr安装时出现--"需要更新以前的Visual Studio 2010实例"--状态失败
在电脑中安装过Visual Studio比较低版本的软件的时候 将原本的Microsoft Visual Studio 2010 Service Pack 1进行了更改 导致sql比较高版本的不能很好 ...
- 自己制作一个USB自动挖矿器
先讲下设备效果: 对面坐着一位同事中午去吃饭没锁屏幕,这时候你想用他的电脑去挖矿, 挖矿,当然不可能跑到他的座位上,关掉360然后下载个挖矿软件什么的.... 这时候你只需要花十块钱制作如下设备,然后 ...
- 三色GDOI
前面说点什么.. 翻了翻别人的游记.. 发现自己从来没写过gdoi的游记.. 那就.. 一起写完它吧.. GDOI2015 肇庆 没啥印象,只有复联2的首映.. 那时候真的是什么都不懂.. 就是外出打 ...
- Shell中sed使用
sed是一种在线编辑器,它一次处理一行内容.处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往 ...
- Java实现生产者与消费者模式
生产者不断向队列中添加数据,消费者不断从队列中获取数据.如果队列满了,则生产者不能添加数据:如果队列为空,则消费者不能获取数据.借助实现了BlockingQueue接口的LinkedBlockingQ ...
- 旧项目Makefile 迁移CMake的一种方法:include Makefile
有些c++旧项目用Makefile,要迁移CMake的时候非常痛苦,有些像static pattern的语法和make自带命令 cmake要重写一套非常的麻烦. 因此这里用trick的方法实现了一种i ...
- 实现lodash.get功能
function deepGet(object, path, defaultValue) { return (!Array.isArray(path) ? path.replace(/\[/g, '. ...
- C# datatable 重新排序
DataTable table = distributionManageService.Tb_fund_withdrawaGetPageList(pagination, queryJson);//设置 ...
- 3.1circle
就是括号匹配的题目,如果有交集就是NO #include<iostream> #include<cstring> #include<stdio.h> #includ ...
- js数组和对象相等判断、拷贝详解(结合几个现象讲解引用数据类型的趣事)
序言 最近遇到几个js引用数据类型造成的bug,今天结合bug详细分析一下,避免以后再犯,也希望能帮大家提个醒,强化js基本功. 目录 1.浅拷贝.深拷贝,解决变量赋值相互影响问题 2.判断2个数组. ...