hadoop1.0 和 Hadoop 2.0 的区别
1.Hadoop概述
在Google三篇大数据论文发表之后,Cloudera公司在这几篇论文的基础上,开发出了现在的Hadoop。但Hadoop开发出来也并非一帆风顺的,Hadoop1.0版本有诸多局限。在后续的不断实践之中,Hadoop2.0横空出世,而后Hadoop2.0逐渐成为大数据中的主流。那么Hadoop1.0究竟存在哪些缺陷,在它升级到Hadoop2.0的时候又做出了怎样的调整,最终使得Hadoop2.0成为大数据的基石呢?
2.Hadoop1.0
首先我们来看hadoop1.0的整体结构。在hadoop1.0中有两个模块,一个是分布式文件系统HDFS(Hadoop Distrbuted File System)。另一个则是分布式计算框架MapReduce。我们分别来看看这两个模块的架构吧。
2.1HDFS1.0
对HDFS来说,其主要的运行架构则是master-slave架构,即主从架构。其中呢,master主节点称之为Namenode节点,而slave从节点称为DataNode节点。
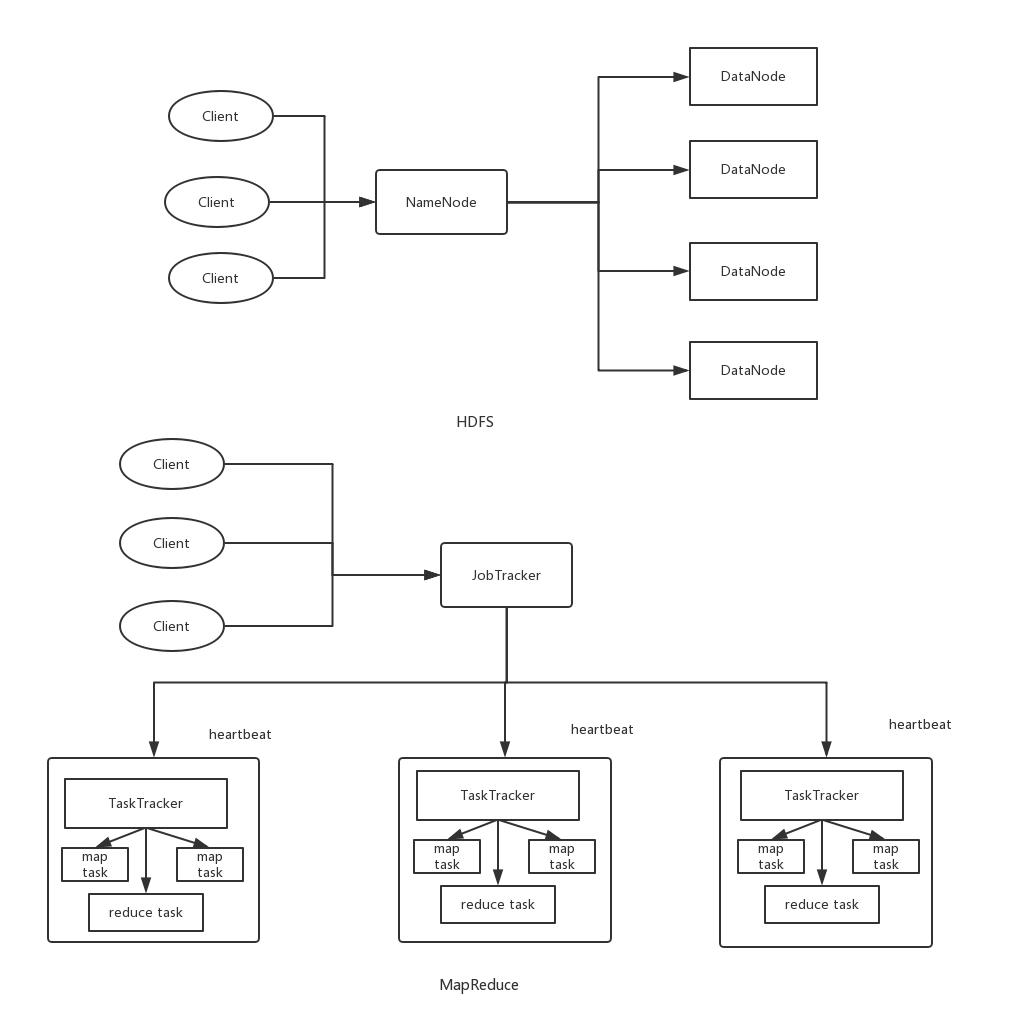
这个NameNode的职责是什么呢?
- NameNode管理着整个文件系统,负责接收用户的操作请求
- NameNode管理着整个文件系统的目录结构,所谓目录结构类似于我们Windows操作系统的体系结构
- NameNode管理着整个文件系统的元数据信息,所谓元数据信息指定是除了数据本身之外涉及到文件自身的相关信息
- NameNode保管着文件与block块序列之间的对应关系以及block块与DataNode节点之间的对应关系
在hadoop1.0中,namenode有且只有一个,虽然可以通过SecondaryNameNode与NameNode进行数据同步备份,但是总会存在一定的延时,如果NameNode挂掉,但是如果有部份数据还没有同步到SecondaryNameNode上,还是可能会存在着数据丢失的问题。
值得一提的是,在HDFS中,我们真实的数据是由DataNode来负责来存储的,但是数据具体被存储到了哪个DataNode节点等元数据信息则是由我们的NameNode来存储的。
这种架构实现的好处的简单,但其局限同样明显:
- 单点故障问题:因为NameNode含有我们用户存储文件的全部的元数据信息,当我们的NameNode无法在内存中加载全部元数据信息的时候,集群的寿命就到头了。
- 拓展性问题:NameNode在内存中存储了整个分布式文件系统中的元数据信息,并且NameNode只能有一台机器,无法拓展。单台机器的NameNode必然有到达极限的地方。
- 性能问题:当HDFS中存储大量的小文件时,会使NameNode的内存压力增加。
- 隔离性问题:单个namenode难以提供隔离性,即:某个用户提交的负载很大的job会减慢其他用户的job。
2.2MapReduce
对MapReduce来说,同样时一个主从结构,是由一个JobTracker(主)和多个TaskTracker(从)组成。
而JobTracker在hadoop1.0的MapReduce中做了很多事情,可以说当爹又当妈。
- 负责接收client提交给的计算任务。
- 负责将接收的计算任务分配给各个的TaskTracker进行执行。
- 通过heartbeat(心跳)来管理TaskTracker机器的情况,同时监控任务task的执行状况。
这个架构的缺陷:
- 单点故障:依旧是单点故障问题,如果JobTracker挂掉了会导致MapReduce作业无法执行。
- 资源浪费:JobTracker完成了太多的任务,造成了过多的资源消耗,当map-reduce job非常多的时候,会造成很大的内存开销,潜在来说,也增加了JobTracker失效的风险,这也是业界普遍总结出老Hadoop的Map-Reduce只能支持4000节点主机的上限;
- 只支持简单的MapReduce编程模型:要使用Hadoop进行编程的话只能使用基础的MapReduce,而无法使用诸如Spark这些计算模型。并且它也不支持流式计算和实时计算。
3.Hadoop2.0

Hadoop2.0比起Hadoop1.0来说,最大的改进是加入了资源调度框架Yarn,我们依旧分为HDFS和Yarn/MapReduce2.0两部分来讲述Hadoop的改进。
3.1HDFS2.0
针对Hadoop1.0中NameNode制约HDFS的扩展性问题,提出HDFSFederation以及高可用HA。此时NameNode间相互独立,也就是说它们之间不需要相互协调。且多个NameNode分管不同的目录进而实现访问隔离和横向扩展。
这样NameNode的可拓展性自然而然可用增加,据统计Hadoop2.0中最多可以达到10000个节点同时运行,并且这样的架构改进也解决了NameNode单点故障问题。
再来说说高可用(HA),HA主要指的是可以同时启动2个NameNode。其中一个处于工作(Active)状态,另一个处于随时待命(Standby)状态。这样,当一个NameNode所在的服务器宕机时,可以在数据不丢失的情况下,手工或者自动切换到另一个NameNode提供服务。
3.2Yarn/MapReduce2
针对Hadoop1.0中MR的不足,引入了Yarn框架。Yarn框架中将JobTracker资源分配和作业控制分开,分为Resource Manager(RM)以及Application Master(AM)。
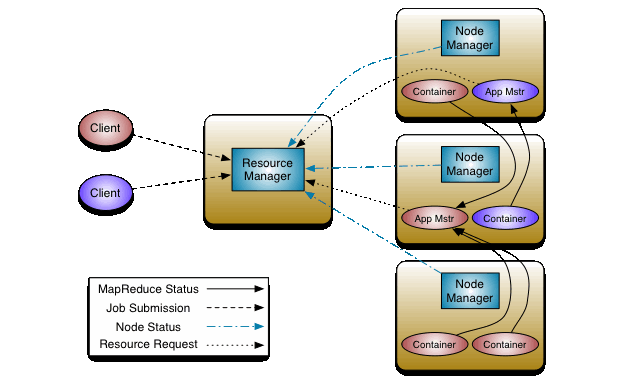
而Yarn框架作为一个通用的资源调度和管理模块,同时支持多种其他的编程模型,比如最出名的Spark。
Yarn的主要三个组件如下:
Resource Manager:ResourceManager包含两个主要的组件:定时调用器(Scheduler)以及应用管理器(ApplicationManager)。
定时调度器(Scheduler):定时调度器负责向应用程序分配资源,它不做监控以及应用程序的状态跟踪,并且它不保证会重启由于应用程序本身或硬件出错而执行失败的应用程序。
应用管理器(ApplicationManager):应用程序管理器负责接收新任务,协调并提供在ApplicationMaster容器失败时的重启功能。
Application Master:每个应用程序的ApplicationMaster负责从Scheduler申请资源,以及跟踪这些资源的使用情况以及任务进度的监控。
Node Manager:NodeManager是ResourceManager在每台机器的上代理,负责容器的管理,并监控他们的资源使用情况(cpu,内存,磁盘及网络等),以及向ResourceManager/Scheduler提供这些资源使用报告。
关于Hadoop1.0和2.0的一点点感悟
没有什么是一开始就完美的,当下最流行的Hadoop也一样。从上面说的,我们可以知道Hadoop1.0是比较简陋的,这样做的目的就是为了易于实现。Hadoop这样做也契合了敏捷开发的原则,也可以说契合产品经理口中的最小可行性产品(MVP),就是先实现一个简单些,但核心功能齐全的版本出来,让市场对其进行检验,而有了结果之后再进行拓展升级。
在当时那种许多公司都苦恼于没有自己的大数据环境的情况下,Hadoop一炮而红。这时候再根据市场,也就是开源社区给出的反馈,不断迭代,更新升级。最终成为大数群山中最为坚固的一座山峰。
我们在平时的产品开发中应该也要像Hadoop学习,先做出最小可行性产品出来,再在后面进行更新升级,不断完善。当然这对一些完美主义者来说,可能会让他感到比较痛苦。
你看,世间的事多是相通,技术的发展过程其实也暗合产品之道。有时候我们或许可以跳出技术之外,思考它背后产品的逻辑,这其中又有哪些是我们可以学习的,这些同样是珍贵的宝藏,所谓他山之石,可以攻玉,莫过于此~~
以上~
推荐阅读:
从分治算法到 MapReduce
Actor并发编程模型浅析
大数据存储的进化史 --从 RAID 到 Hadoop Hdfs
一个故事告诉你什么才是好的程序员
hadoop1.0 和 Hadoop 2.0 的区别的更多相关文章
- 从 Hadoop 1.0 到 Hadoop 2.0 ,你需要了解这些
学习大数据,刚开始接触的是 Hadoop 1.0,然后过度到 Hadoop 2.0 ,这里为了书写方便,本文中 Hadoop 1.0 采用 HV1 的缩写方式,Hadoop 2.0 采用 HV2 的缩 ...
- Apache Hadoop 3.0.0 Release Notes
http://hadoop.apache.org/docs/r3.0.0/hadoop-project-dist/hadoop-common/release/3.0.0/RELEASENOTES.3. ...
- Sqoop安装与使用(sqoop-1.4.5 on hadoop 1.0.4)
1.什么是Sqoop Sqoop即 SQL to Hadoop ,是一款方便的在传统型数据库与Hadoop之间进行数据迁移的工具,充分利用MapReduce并行特点以批处理的方式加快数据传输,发展至今 ...
- Hadoop 2.0 中的资源管理框架 - YARN(Yet Another Resource Negotiator)
1. Hadoop 2.0 中的资源管理 http://dongxicheng.org/mapreduce-nextgen/hadoop-1-and-2-resource-manage/ Hadoop ...
- hadoop 2.0 详细配置教程(转载)
转载: http://www.cnblogs.com/scotoma/archive/2012/09/18/2689902.html 作者:杨鑫奇 PS:文章有部分参考资料来自网上,并经过实践后写出, ...
- CentOS 7安装Hadoop 3.0.0
最近在学习大数据,需要安装Hadoop,自己弄了好久,最后终于弄好了.网上也有很多文章关于安装Hadoop的,但总会遇到一些问题,所以把在CentOS 7安装Hadoop 3.0.0的整个过程记录下来 ...
- [转] Hadoop 2.0 详细安装过程
1. 准备 创建用户 useradd hadoop passwd hadoop 创建相关的目录 定义代码及工具存放的路径 mkdir -p /home/hadoop/source mkdir -p / ...
- HTML4.01和XHTML1.0和XHTML1.1的一些区别
接触web前端以来,一直使用的都是html5,因此一直没搞明白HTML4.01和XHTML1.0和XHTML1.1之间的区别,今天在看<精通CSS>一书,有简单介绍这几个,在这儿记录下. ...
- Hadoop 1.0 和 2.0 中的数据处理框架 - MapReduce
1. MapReduce - 映射.化简编程模型 1.1 MapReduce 的概念 1.1.1 map 和 reduce 1.1.2 shufftle 和 排序 MapReduce 保证每个 red ...
随机推荐
- [Swift]LeetCode129. 求根到叶子节点数字之和 | Sum Root to Leaf Numbers
Given a binary tree containing digits from 0-9 only, each root-to-leaf path could represent a number ...
- [Swift]LeetCode275. H指数 II | H-Index II
Given an array of citations sorted in ascending order (each citation is a non-negative integer) of a ...
- [Swift]LeetCode286. 墙和门 $ Walls and Gates
You are given a m x n 2D grid initialized with these three possible values. -1 - A wall or an obstac ...
- [Swift]LeetCode476. 数字的补数 | Number Complement
Given a positive integer, output its complement number. The complement strategy is to flip the bits ...
- [Swift]LeetCode902. 最大为 N 的数字组合 | Numbers At Most N Given Digit Set
We have a sorted set of digits D, a non-empty subset of {'1','2','3','4','5','6','7','8','9'}. (Not ...
- PHP实现用户注册并保存数据到文件
首先我们实现功能时,分析实现的步骤是什么,就这个而言,我们应该接收用户提交的数据并进行校验,然后保存在文件,最后给用户反馈. 这里需要注意的是为了避免嵌套过深,这里使用自定义函数来实现,其代码如下: ...
- Java编程——学习大纲
Java基础 Java基础--JDK的安装和配置 Java基础--Eclipse使用 Java基础--基本概念.数据类型.运算符 Java扩展--整型和浮点型在计算机中的存储格式 Java基础--流程 ...
- python之Django学习笔记(二)---Django从工程创建、app创建到表建模在页面的显示
创建工程: 在命令行中切换目录至需要创建工程的目录,然后在命令行中输入如下命令创建djangoTestPro工程 D:\PycharmProjects\untitled\MyTestProject&g ...
- BBS论坛(十八)
18.首页轮播图实现 (1)front/css/front_base.css .main-container{ width: 990px; margin: 0 auto; overflow: hidd ...
- 深入解析 H.265 编码模式,带你了解Apple全面推进H.265的原因
今天我们聊聊视频编码.视频文件亘古以来存在一个矛盾:高清画质和视频体积的冲突,相同编码标准下,视频更高清,视频体积更大.因此,应用更先进的视频编码标准,降低视频体积,可以大幅降低网站的流量消耗. 目前 ...