Java提高班(二)深入理解线程池ThreadPool
本文你将获得以下信息:
- 线程池源码解读
- 线程池执行流程分析
- 带返回值的线程池实现
- 延迟线程池实现
为了方便读者理解,本文会由浅入深,先从线程池的使用开始再延伸到源码解读和源码分析等高级内容,读者可根据自己的情况自主选择阅读顺序和需要了解的章节。
一、线程池优点
线程池能够更加充分的利用CPU、内存、网络、IO等系统资源,线程池的主要作用如下:
- 利用线程池可以复用线程,控制最大并发数;
- 实现任务缓存策略和拒绝机制;
- 实现延迟执行
阿里巴巴Java开发手册强制规定:线程资源必须通过线程池提供,如下图:

二、线程池使用
本节会介绍7种线程池的创建与使用,线程池的状态介绍,ThreadPoolExecutor参数介绍等。
2.1 线程池创建
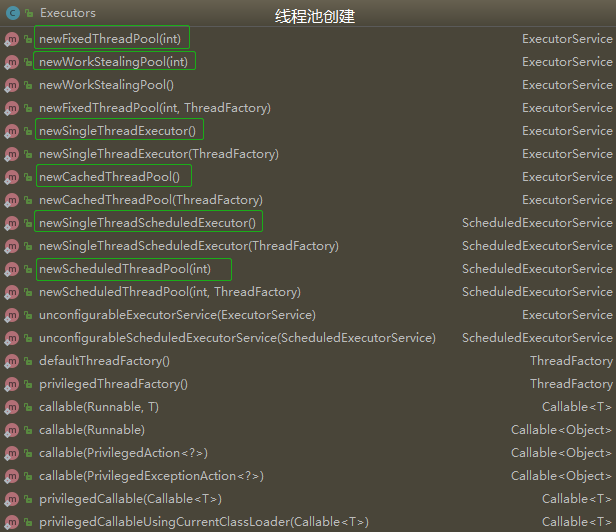
线程池可以使用Executors和ThreadPoolExecutor,其中使用Executors有六种创建线程池的方法,如下图:
// 使用Executors方式创建
ExecutorService singleThreadExecutor = Executors.newSingleThreadExecutor();
ExecutorService cachedThreadPool = Executors.newCachedThreadPool();
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(2);
ScheduledExecutorService singleThreadScheduledExecutor = Executors.newSingleThreadScheduledExecutor();
ScheduledExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(2);
ExecutorService workStealingPool = Executors.newWorkStealingPool();
// 原始创建方式
ThreadPoolExecutor tp = new ThreadPoolExecutor(10, 10, 10L, TimeUnit.SECONDS, new LinkedBlockingQueue<Runnable>());
2.1.1 线程池解读
- newSingleThreadExecutor(),它的特点在于工作线程数目被限制为 1,操作一个无界的工作队列,所以它保证了所有任务的都是被顺序执行,最多会有一个任务处于活动状态,并且不允许使用者改动线程池实例,因此可以避免其改变线程数目。
- newCachedThreadPool(),它是一种用来处理大量短时间工作任务的线程池,具有几个鲜明特点:它会试图缓存线程并重用,当无缓存线程可用时,就会创建新的工作线程;如果线程闲置的时间超过 60 秒,则被终止并移出缓存;长时间闲置时,这种线程池,不会消耗什么资源。其内部使用 SynchronousQueue 作为工作队列。
- newFixedThreadPool(int nThreads),重用指定数目(nThreads)的线程,其背后使用的是无界的工作队列,任何时候最多有 nThreads 个工作线程是活动的。这意味着,如果任务数量超过了活动队列数目,将在工作队列中等待空闲线程出现;如果有工作线程退出,将会有新的工作线程被创建,以补足指定的数目 nThreads。
- newSingleThreadScheduledExecutor() 创建单线程池,返回 ScheduledExecutorService,可以进行定时或周期性的工作调度。
- newScheduledThreadPool(int corePoolSize)和newSingleThreadScheduledExecutor()类似,创建的是个 ScheduledExecutorService,可以进行定时或周期性的工作调度,区别在于单一工作线程还是多个工作线程。
- newWorkStealingPool(int parallelism),这是一个经常被人忽略的线程池,Java 8 才加入这个创建方法,其内部会构建ForkJoinPool,利用Work-Stealing算法,并行地处理任务,不保证处理顺序。
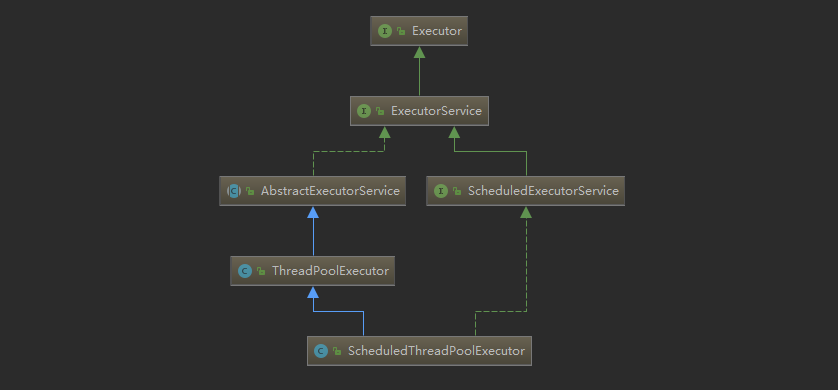
- ThreadPoolExecutor是最原始的线程池创建,上面1-3创建方式都是对ThreadPoolExecutor的封装。
总结: 其中newSingleThreadExecutor、newCachedThreadPool、newFixedThreadPool是对ThreadPoolExecutor的封装实现,newSingleThreadScheduledExecutor、newScheduledThreadPool则为ThreadPoolExecutor子类ScheduledThreadPoolExecutor的封装,用于执行延迟任务,newWorkStealingPool则为Java 8新加的方法。
2.1.2 单线程池的意义
从以上代码可以看出newSingleThreadExecutor和newSingleThreadScheduledExecutor创建的都是单线程池,那么单线程池的意义是什么呢?
虽然是单线程池,但提供了工作队列,生命周期管理,工作线程维护等功能。
2.2 ThreadPoolExecutor解读
ThreadPoolExecutor作为线程池的核心方法,我们来看一下ThreadPoolExecutor内部实现,以及封装类是怎么调用ThreadPoolExecutor的。
先从构造函数说起,构造函数源码如下:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.acc = System.getSecurityManager() == null ?
null :
AccessController.getContext();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
参数说明:
- corePoolSize:所谓的核心线程数,可以大致理解为长期驻留的线程数目(除非设置了 allowCoreThreadTimeOut)。对于不同的线程池,这个值可能会有很大区别,比如 newFixedThreadPool 会将其设置为 nThreads,而对于 newCachedThreadPool 则是为 0。
- maximumPoolSize:顾名思义,就是线程不够时能够创建的最大线程数。同样进行对比,对于 newFixedThreadPool,当然就是 nThreads,因为其要求是固定大小,而 newCachedThreadPool 则是 Integer.MAX_VALUE。
- keepAliveTime:空闲线程的保活时间,如果线程的空闲时间超过这个值,那么将会被关闭。注意此值生效条件必须满足:空闲时间超过这个值,并且线程池中的线程数少于等于核心线程数corePoolSize。当然核心线程默认是不会关闭的,除非设置了allowCoreThreadTimeOut(true)那么核心线程也可以被回收。
- TimeUnit:时间单位。
- BlockingQueue:任务丢列,用于存储线程池的待执行任务的。
- threadFactory:用于生成线程,一般我们可以用默认的就可以了。
- handler:当线程池已经满了,但是又有新的任务提交的时候,该采取什么策略由这个来指定。有几种方式可供选择,像抛出异常、直接拒绝然后返回等,也可以自己实现相应的接口实现自己的逻辑。
来看一下线程池封装类对于ThreadPoolExecutor的调用:
newSingleThreadExecutor对ThreadPoolExecutor的封装源码如下:
public static ExecutorService newSingleThreadExecutor() {
return new Executors.FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
newCachedThreadPool对ThreadPoolExecutor的封装源码如下:
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
newFixedThreadPool对ThreadPoolExecutor的封装源码如下:
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
ScheduledExecutorService对ThreadPoolExecutor的封装源码如下:
public static ScheduledExecutorService newSingleThreadScheduledExecutor() {
return new DelegatedScheduledExecutorService
(new ScheduledThreadPoolExecutor(1));
}
newSingleThreadScheduledExecutor使用的是ThreadPoolExecutor的子类ScheduledThreadPoolExecutor,如下图所示:
newScheduledThreadPool对ThreadPoolExecutor的封装源码如下:
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
newScheduledThreadPool使用的也是ThreadPoolExecutor的子类ScheduledThreadPoolExecutor。
2.3 线程池状态
查看ThreadPoolExecutor源码可知线程的状态如下:
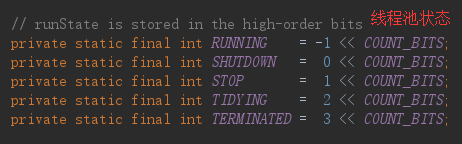
线程状态解读(以下内容来源于:https://javadoop.com/post/java-thread-pool):
- RUNNING:这个没什么好说的,这是最正常的状态:接受新的任务,处理等待队列中的任务;
- SHUTDOWN:不接受新的任务提交,但是会继续处理等待队列中的任务;
- STOP:不接受新的任务提交,不再处理等待队列中的任务,中断正在执行任务的线程;
- TIDYING:所有的任务都销毁了,workCount 为 0。线程池的状态在转换为 TIDYING 状态时,会执行钩子方法 terminated();
- TERMINATED:terminated() 方法结束后,线程池的状态就会变成这个;
RUNNING 定义为 -1,SHUTDOWN 定义为 0,其他的都比 0 大,所以等于 0 的时候不能提交任务,大于 0 的话,连正在执行的任务也需要中断。
看了这几种状态的介绍,读者大体也可以猜到十之八九的状态转换了,各个状态的转换过程有以下几种:
- RUNNING -> SHUTDOWN:当调用了 shutdown() 后,会发生这个状态转换,这也是最重要的;
- (RUNNING or SHUTDOWN) -> STOP:当调用 shutdownNow() 后,会发生这个状态转换,这下要清楚 shutDown() 和 shutDownNow() 的区别了;
- SHUTDOWN -> TIDYING:当任务队列和线程池都清空后,会由 SHUTDOWN 转换为 TIDYING;
- STOP -> TIDYING:当任务队列清空后,发生这个转换;
- TIDYING -> TERMINATED:这个前面说了,当 terminated() 方法结束后;
2.4 线程池执行
说了那么多下来一起来看线程池的是怎么执行任务的,线程池任务提交有两个方法:
- execute
- submit
其中execute只能接受Runnable类型的任务,使用如下:
ExecutorService singleThreadExecutor = Executors.newSingleThreadExecutor();
singleThreadExecutor.execute(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName());
}
});
submit可以接受Runnable或Callable类型的任务,使用如下:
ExecutorService executorService = Executors.newSingleThreadExecutor();
executorService.submit(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName());
}
});
2.4.1 带返回值的线程池实现
使用submit传递Callable类可以获取执行任务的返回值,Callable是JDK 1.5 添加的特性用于补充Runnable无返回的情况。
ExecutorService executorService = Executors.newSingleThreadExecutor();
Future<Long> result = executorService.submit(new Callable<Long>() {
@Override
public Long call() throws Exception {
return new Date().getTime();
}
});
try {
System.out.println("运行结果:" + result.get());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
2.4.2 延迟线程池实现
在线程池中newSingleThreadScheduledExecutor和newScheduledThreadPool返回的是ScheduledExecutorService,用于执行延迟线程池的,代码如下:
// 延迟线程池
ScheduledExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(2);
scheduledThreadPool.schedule(new Runnable() {
@Override
public void run() {
System.out.println("time:" + new Date().getTime());
}
}, 10, TimeUnit.SECONDS);
完整示例下载地址: https://github.com/vipstone/java-core-example
三、线程池源码解读
阅读线程池的源码有一个小技巧,可以按照线程池执行的顺序进行串连关联阅读,这样更容易理解线程池的实现。
源码阅读流程解读
我们先从线程池的任务提交方法execute()开始阅读,从execute()我们会发现线程池执行的核心方法是addWorker(),在addWorker()中我们发现启动线程调用了start()方法,调用start()方法之后会执行Worker类的run()方法,run里面调用runWorker(),运行程序的关键在于getTask()方法,getTask()方法之后就是此线程的关闭,整个线程池的工作流程也就完成了,下来一起来看吧(如果本段文章没看懂的话也可以看完源码之后,回过头来再看一遍)。
3.1 execute() 源码解读
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
// 如果当前线程数少于核心线程数,那么直接添加一个 worker 来执行任务,
// 创建一个新的线程,并把当前任务 command 作为这个线程的第一个任务(firstTask)
if (workerCountOf(c) < corePoolSize) {
// 添加任务成功,那么就结束了。提交任务嘛,线程池已经接受了这个任务,这个方法也就可以返回了
// 至于执行的结果,到时候会包装到 FutureTask 中。
// 返回 false 代表线程池不允许提交任务
if (addWorker(command, true))
return;
c = ctl.get();
}
// 到这里说明,要么当前线程数大于等于核心线程数,要么刚刚 addWorker 失败了
// 如果线程池处于 RUNNING 状态,把这个任务添加到任务队列 workQueue 中
if (isRunning(c) && workQueue.offer(command)) {
/* 这里面说的是,如果任务进入了 workQueue,我们是否需要开启新的线程
* 因为线程数在 [0, corePoolSize) 是无条件开启新的线程
* 如果线程数已经大于等于 corePoolSize,那么将任务添加到队列中,然后进到这里
*/
int recheck = ctl.get();
// 如果线程池已不处于 RUNNING 状态,那么移除已经入队的这个任务,并且执行拒绝策略
if (! isRunning(recheck) && remove(command))
reject(command);
// 如果线程池还是 RUNNING 的,并且线程数为 0,那么开启新的线程
// 到这里,我们知道了,这块代码的真正意图是:担心任务提交到队列中了,但是线程都关闭了
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
// 如果 workQueue 队列满了,那么进入到这个分支
// 以 maximumPoolSize 为界创建新的 worker,
// 如果失败,说明当前线程数已经达到 maximumPoolSize,执行拒绝策略
else if (!addWorker(command, false))
reject(command);
}
3.2 addWorker() 源码解读
// 第一个参数是准备提交给这个线程执行的任务,之前说了,可以为 null
// 第二个参数为 true 代表使用核心线程数 corePoolSize 作为创建线程的界线,也就说创建这个线程的时候,
// 如果线程池中的线程总数已经达到 corePoolSize,那么不能响应这次创建线程的请求
// 如果是 false,代表使用最大线程数 maximumPoolSize 作为界线
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// 这个非常不好理解
// 如果线程池已关闭,并满足以下条件之一,那么不创建新的 worker:
// 1. 线程池状态大于 SHUTDOWN,其实也就是 STOP, TIDYING, 或 TERMINATED
// 2. firstTask != null
// 3. workQueue.isEmpty()
// 简单分析下:
// 还是状态控制的问题,当线程池处于 SHUTDOWN 的时候,不允许提交任务,但是已有的任务继续执行
// 当状态大于 SHUTDOWN 时,不允许提交任务,且中断正在执行的任务
// 多说一句:如果线程池处于 SHUTDOWN,但是 firstTask 为 null,且 workQueue 非空,那么是允许创建 worker 的
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
for (;;) {
int wc = workerCountOf(c);
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
// 如果成功,那么就是所有创建线程前的条件校验都满足了,准备创建线程执行任务了
// 这里失败的话,说明有其他线程也在尝试往线程池中创建线程
if (compareAndIncrementWorkerCount(c))
break retry;
// 由于有并发,重新再读取一下 ctl
c = ctl.get();
// 正常如果是 CAS 失败的话,进到下一个里层的for循环就可以了
// 可是如果是因为其他线程的操作,导致线程池的状态发生了变更,如有其他线程关闭了这个线程池
// 那么需要回到外层的for循环
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
/*
* 到这里,我们认为在当前这个时刻,可以开始创建线程来执行任务了,
* 因为该校验的都校验了,至于以后会发生什么,那是以后的事,至少当前是满足条件的
*/
// worker 是否已经启动
boolean workerStarted = false;
// 是否已将这个 worker 添加到 workers 这个 HashSet 中
boolean workerAdded = false;
Worker w = null;
try {
final ReentrantLock mainLock = this.mainLock;
// 把 firstTask 传给 worker 的构造方法
w = new Worker(firstTask);
// 取 worker 中的线程对象,之前说了,Worker的构造方法会调用 ThreadFactory 来创建一个新的线程
final Thread t = w.thread;
if (t != null) {
// 这个是整个类的全局锁,持有这个锁才能让下面的操作“顺理成章”,
// 因为关闭一个线程池需要这个锁,至少我持有锁的期间,线程池不会被关闭
mainLock.lock();
try {
int c = ctl.get();
int rs = runStateOf(c);
// 小于 SHUTTDOWN 那就是 RUNNING,这个自不必说,是最正常的情况
// 如果等于 SHUTDOWN,前面说了,不接受新的任务,但是会继续执行等待队列中的任务
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
// worker 里面的 thread 可不能是已经启动的
if (t.isAlive())
throw new IllegalThreadStateException();
// 加到 workers 这个 HashSet 中
workers.add(w);
int s = workers.size();
// largestPoolSize 用于记录 workers 中的个数的最大值
// 因为 workers 是不断增加减少的,通过这个值可以知道线程池的大小曾经达到的最大值
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
// 添加成功的话,启动这个线程
if (workerAdded) {
// 启动线程
t.start();
workerStarted = true;
}
}
} finally {
// 如果线程没有启动,需要做一些清理工作,如前面 workCount 加了 1,将其减掉
if (! workerStarted)
addWorkerFailed(w);
}
// 返回线程是否启动成功
return workerStarted;
}
在这段代码可以看出,调用了t.start();
3.3 runWorker() 源码解读
根据上面代码可知,调用了Worker的t.start()之后,紧接着会调用Worker的run()方法,run()源码如下:
public void run() {
runWorker(this);
}
runWorker()源码如下:
// worker 线程启动后调用,while 循环(即自旋!)不断从等待队列获取任务并执行
// worker 初始化时,可指定 firstTask,那么第一个任务也就可以不需要从队列中获取
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
// 该线程的第一个任务(若有)
Runnable task = w.firstTask;
w.firstTask = null;
// 允许中断
w.unlock();
boolean completedAbruptly = true;
try {
// 循环调用 getTask 获取任务
while (task != null || (task = getTask()) != null) {
w.lock();
// 若线程池状态大于等于 STOP,那么意味着该线程也要中断
/**
* 若线程池STOP,请确保线程 已被中断
* 如果没有,请确保线程未被中断
* 这需要在第二种情况下进行重新检查,以便在关中断时处理shutdownNow竞争
*/
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
// 这是一个钩子方法,留给需要的子类实现
beforeExecute(wt, task);
Throwable thrown = null;
try {
// 到这里终于可以执行任务了
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
// 这里不允许抛出 Throwable,所以转换为 Error
thrown = x; throw new Error(x);
} finally {
// 也是一个钩子方法,将 task 和异常作为参数,留给需要的子类实现
afterExecute(task, thrown);
}
} finally {
// 置空 task,准备 getTask 下一个任务
task = null;
// 累加完成的任务数
w.completedTasks++;
// 释放掉 worker 的独占锁
w.unlock();
}
}
completedAbruptly = false;
} finally {
// 到这里,需要执行线程关闭
// 1. 说明 getTask 返回 null,也就是说,这个 worker 的使命结束了,执行关闭
// 2. 任务执行过程中发生了异常
// 第一种情况,已经在代码处理了将 workCount 减 1,这个在 getTask 方法分析中说
// 第二种情况,workCount 没有进行处理,所以需要在 processWorkerExit 中处理
processWorkerExit(w, completedAbruptly);
}
}
3.4 getTask() 源码解读
runWorker里面的有getTask(),来看下具体的实现:
// 此方法有三种可能
// 1. 阻塞直到获取到任务返回。默认 corePoolSize 之内的线程是不会被回收的,它们会一直等待任务
// 2. 超时退出。keepAliveTime 起作用的时候,也就是如果这么多时间内都没有任务,那么应该执行关闭
// 3. 如果发生了以下条件,须返回 null
// 池中有大于 maximumPoolSize 个 workers 存在(通过调用 setMaximumPoolSize 进行设置)
// 线程池处于 SHUTDOWN,而且 workQueue 是空的,前面说了,这种不再接受新的任务
// 线程池处于 STOP,不仅不接受新的线程,连 workQueue 中的线程也不再执行
private Runnable getTask() {
boolean timedOut = false; // Did the last poll() time out?
for (;;) {
// 允许核心线程数内的线程回收,或当前线程数超过了核心线程数,那么有可能发生超时关闭
// 这里 break,是为了不往下执行后一个 if (compareAndDecrementWorkerCount(c))
// 两个 if 一起看:如果当前线程数 wc > maximumPoolSize,或者超时,都返回 null
// 那这里的问题来了,wc > maximumPoolSize 的情况,为什么要返回 null?
// 换句话说,返回 null 意味着关闭线程。
// 那是因为有可能开发者调用了 setMaximumPoolSize 将线程池的 maximumPoolSize 调小了
// 如果此 worker 发生了中断,采取的方案是重试
// 解释下为什么会发生中断,这个读者要去看 setMaximumPoolSize 方法,
// 如果开发者将 maximumPoolSize 调小了,导致其小于当前的 workers 数量,
// 那么意味着超出的部分线程要被关闭。重新进入 for 循环,自然会有部分线程会返回 null
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
// CAS 操作,减少工作线程数
decrementWorkerCount();
return null;
}
int wc = workerCountOf(c);
// Are workers subject to culling?
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
try {
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
timedOut = true;
} catch (InterruptedException retry) {
// 如果此 worker 发生了中断,采取的方案是重试
// 解释下为什么会发生中断,这个读者要去看 setMaximumPoolSize 方法,
// 如果开发者将 maximumPoolSize 调小了,导致其小于当前的 workers 数量,
// 那么意味着超出的部分线程要被关闭。重新进入 for 循环,自然会有部分线程会返回 null
timedOut = false;
}
}
}
四、线程池执行流程
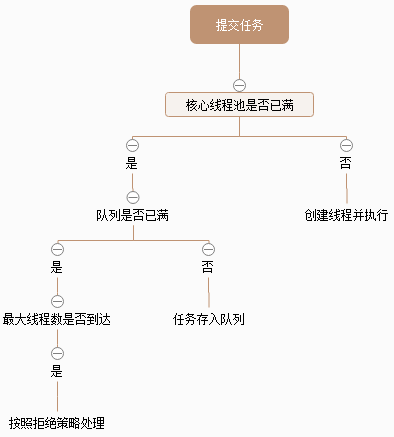
线程池的执行流程如下图:
五、总结
本文总结以问答的形式展示,引自《深度解读 java 线程池设计思想及源码实现》,最下方附参考地址。
1、线程池有哪些关键属性?
corePoolSize 到 maximumPoolSize 之间的线程会被回收,当然 corePoolSize 的线程也可以通过设置而得到回收(allowCoreThreadTimeOut(true))。
workQueue 用于存放任务,添加任务的时候,如果当前线程数超过了 corePoolSize,那么往该队列中插入任务,线程池中的线程会负责到队列中拉取任务。
keepAliveTime 用于设置空闲时间,如果线程数超出了 corePoolSize,并且有些线程的空闲时间超过了这个值,会执行关闭这些线程的操作
rejectedExecutionHandler 用于处理当线程池不能执行此任务时的情况,默认有抛出 RejectedExecutionException 异常、忽略任务、使用提交任务的线程来执行此任务和将队列中等待最久的任务删除,然后提交此任务这四种策略,默认为抛出异常。
2、线程池中的线程创建时机?
如果当前线程数少于 corePoolSize,那么提交任务的时候创建一个新的线程,并由这个线程执行这个任务;
如果当前线程数已经达到 corePoolSize,那么将提交的任务添加到队列中,等待线程池中的线程去队列中取任务;
如果队列已满,那么创建新的线程来执行任务,需要保证池中的线程数不会超过 maximumPoolSize,如果此时线程数超过了 maximumPoolSize,那么执行拒绝策略。
3、任务执行过程中发生异常怎么处理?
如果某个任务执行出现异常,那么执行任务的线程会被关闭,而不是继续接收其他任务。然后会启动一个新的线程来代替它。
4、什么时候会执行拒绝策略?
- workers 的数量达到了 corePoolSize,任务入队成功,以此同时线程池被关闭了,而且关闭线程池并没有将这个任务出队,那么执行拒绝策略。这里说的是非常边界的问题,入队和关闭线程池并发执行,读者仔细看看 execute 方法是怎么进到第一个 reject(command) 里面的。
- workers 的数量大于等于 corePoolSize,准备入队,可是队列满了,任务入队失败,那么准备开启新的线程,可是线程数已经达到 maximumPoolSize,那么执行拒绝策略。
六、参考资料
书籍:《码出高效:Java开发手册》
Java核心技术36讲:http://t.cn/EwUJvWA
深度解读 java 线程池设计思想及源码实现:https://javadoop.com/post/java-thread-pool
Java线程池-ThreadPoolExecutor源码解析(基于Java8):https://www.imooc.com/article/42990
课程推荐:

Java提高班(二)深入理解线程池ThreadPool的更多相关文章
- java核心知识点学习----重点学习线程池ThreadPool
线程池是多线程学习中需要重点掌握的. 系统启动一个新线程的成本是比较高的,因为它涉及与操作系统交互.在这种情形下,使用线程池可以很好的提高性能,尤其是当程序中需要创建大量生存期很短暂的线程时,更应该考 ...
- Java并发编程之深入理解线程池原理及实现
Java线程池在实际的应用开发中十分广泛.虽然Java1.5之后在JUC包中提供了内置线程池可以拿来就用,但是这之前仍有许多老的应用和系统是需要程序员自己开发的.因此,基于线程池的需求背景.技术要求了 ...
- 【转】Java学习---深入理解线程池
[原文]https://www.toutiao.com/i6566022142666736131/ 我们使用线程的时候就去创建一个线程,这样实现起来非常简便,但是就会有一个问题: 如果并发的线程数量很 ...
- 温故知新-java多线程&深入理解线程池
文章目录 摘要 java中的线程 java中的线程池 线程池技术 线程池的实现原理 简述 ThreadPoolExecutor是如何运行的? 线程池运行的状态和线程数量 任务执行机制 队列缓存 Wor ...
- Java中的线程池用过吧?来说说你是怎么理解线程池吧?
前言 Java中的线程池用过吧?来说说你是怎么使用线程池的?这句话在面试过程中遇到过好几次了.我甚至这次标题都想写成[Java八股文之线程池],但是有点太俗套了.虽然,线程池是一个已经被说烂的知识点了 ...
- 【转】java提高篇(二)-----理解java的三大特性之继承
[转]java提高篇(二)-----理解java的三大特性之继承 原文地址:http://www.cnblogs.com/chenssy/p/3354884.html 在<Think in ja ...
- java并发编程(4)--线程池的使用
转载:http://www.cnblogs.com/dolphin0520/p/3932921.html 一. java中的ThreadPoolExecutor类 java.util.concurre ...
- Java多线程学习(八)线程池与Executor 框架
目录 历史优质文章推荐: 目录: 一 使用线程池的好处 二 Executor 框架 2.1 简介 2.2 Executor 框架结构(主要由三大部分组成) 2.3 Executor 框架的使用示意图 ...
- java核心知识点 --- 线程池ThreadPool
线程池是多线程学习中需要重点掌握的. 系统启动一个新线程的成本是比较高的,因为它涉及与操作系统交互.在这种情形下,使用线程池可以很好的提高性能,尤其是当程序中需要创建大量生存期很短暂的线程时,更应该考 ...
随机推荐
- php一些高级函数方法
PHP高级函数 1.call_user_func (http://php.net/manual/zh/function.call-user-func.php) 2.get_class (http:// ...
- ssh 连接失败 sz rz 安装
sz 下载命令, rz上传命令的安装 sudo apt-get install lrzsz 1. 检查sshd服务的状态以及端口是否正常, 如下为正常状态 sudo netstat -nlp | gr ...
- pom string
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://mave ...
- SpringBoot报错:Failed to load ApplicationContext( Failed to bind properties under 'logging.level')
引起条件: SpringBoot2.0下yml文件配置SLF4j日志输出日志级别 logging: level: debug 解决方法: 指定系统包路径 logging: root: debug 指定 ...
- JS与IOS、Android的交互
一.JS与Android 放在了assets文件夹下了(注意若使用的是AS这个IDE,assets文件夹应放在src/main目录下) <!DOCTYPE html> <html&g ...
- R语言读入数据库的中英名词互译测试并计分脚本(考试用)
1. 分子生物学中英文.csv,输入文件,两列,以tab键分隔的txt文本,没有列名 2. 错误的名解.csv, 如果在测试中拼写错误,会写出到这个文件,可用这个容易犯错的名词进行新的测试 3. 注意 ...
- c# 通过MailHelper发送QQ邮件
发送的方法 appsetting内容 第一个是发送邮件qq账号,第二个是QQ邮箱的POP3/SMTP服务码(下面会说怎么获取),第三个是服务器,第四个是端口 获取QQ邮箱的POP3/SMTP服务码 1 ...
- ueditorUE 去掉本地保存成功的提示框!
网上修改什么JS的太麻烦,这样比较暴力,仅供参考 这里直接修改的样式: ue.ready(function () { $(".edui-editor-mess ...
- CABaRet: Leveraging Recommendation Systems for Mobile Edge Caching
CABaRet:利用推荐系统进行移动边缘缓存 本文为SIGCOMM 2018 Workshop (Mobile Edge Communications, MECOMM)论文. 笔者翻译了该论文.由于时 ...
- Python代码缩进与测试模块
一.Python代码缩进 Python 函数没有明显的 begin 和 end ,没有标明函数的开始和结束的花括号.唯一的分隔符是一个冒号 ( : ),接着代码本身是缩进的. 例如:缩进 bui ...