谈谈一些逻辑相同,性能差异却很大的sql
总结写在前面:
1. 本篇讲述了三个例子,其本质都是揭示了若对索引字段做函数操作,可能会破坏索引值的有序性,由此优化器就决定放弃走树搜索功能。
2. 由第1点提供了一个优化思路,即我们能否避免或转化sql为不对索引字段做函数操作
条件字段函数操作
假设维护一个交易系统,其中交易记录表 tradelog 包含交易流水号(tradeid)、交易员 id(operator)、交易时间(t_modified)等字段。为了便于描述,我们先忽略其他字段。这个表的建表语句如下:
mysql> CREATE TABLE `tradelog` (
`id` int(11) NOT NULL,
`tradeid` varchar(32) DEFAULT NULL,
`operator` int(11) DEFAULT NULL,
`t_modified` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `tradeid` (`tradeid`),
KEY `t_modified` (`t_modified`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
假设,现在已经记录了从 2016 年初到 2018 年底的所有数据,有一个需求是,要统计发生在所有年份中 7 月份的交易记录总数。SQL 语句可能会这么写:
mysql> select count(*) from tradelog where month(t_modified)=7;
我们需要知道:对索引字段做函数操作,可能会破坏索引值的有序性,因此优化器就决定放弃走树搜索功能。
但是放弃走树搜索功能,不表示要放弃使用这棵树。
在这个例子里,优化器可以选择遍历主键索引,也可以选择遍历索引 t_modified,优化器对比索引大小后发现,索引 t_modified 更小,遍历这个索引比遍历主键索引来得更快。因此最终还是会选择索引 t_modified。
用explain命令看一下:

key="t_modified"表示的是,使用了 t_modified 这个索引;我在测试表数据中插入了 10 万行数据,rows=100335,说明这条语句扫描了整个索引的所有值;Extra 字段的 Using index,表示的是使用了覆盖索引。
也就是说,由于在 t_modified 字段加了 month() 函数操作,导致了全索引扫描。
为了能够用上索引的快速定位能力,我们就要把 SQL 语句改成基于字段本身的范围查询。
mysql> select count(*) from tradelog where
-> (t_modified >= '2016-7-1' and t_modified<'2016-8-1') or
-> (t_modified >= '2017-7-1' and t_modified<'2017-8-1') or
-> (t_modified >= '2018-7-1' and t_modified<'2018-8-1');
但这种做法要注意后面可能需要再把其他年份补齐。
不过优化器在个问题上确实有“偷懒”行为,即使是对于不改变有序性的函数,也不会考虑使用索引。
比如,对于 select * from tradelog where id + 1 = 10000 这个 SQL 语句,这个加 1 操作并不会改变有序性,但是 MySQL 优化器还是不能用 id 索引快速定位到 9999 这一行。所以,需要你在写 SQL 语句的时候,手动改写成 where id = 10000 -1 才可以。
隐式类型转换
先看这条sql:
mysql> select * from tradelog where tradeid=110717;
tradeid 这个字段上,本来就有索引,但是 explain 的结果却显示,这条语句需要走全表扫描。
原因是tradeid 的字段类型是 varchar(32),而输入的参数却是整型,所以需要做类型转换。
现在我们遇到两个问题:
1. 数据类型转换的规则是什么?
2. 为什么有数据类型转换,就需要走全索引扫描?
先看第一个问题,数据库里面类型这么多,这种数据类型转换规则更多,如果记不住应该怎么办呢?
这里有一个简单的方法,看 select “10” > 9 的结果:
1. 如果规则是“将字符串转成数字”,那么就是做数字比较,结果应该是 1;
2. 如果规则是“将数字转成字符串”,那么就是做字符串比较,结果应该是 0。
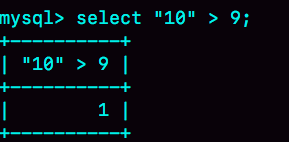
从图中可知,select “10” > 9 返回的是 1,所以我们能确认 MySQL 里的转换规则了:字符串和数字做比较的话,是将字符串转换成数字。
接着我们也就理解上面的sql语句为什么走全表扫描了,因为它触发了前面提到的规则:对索引字段做函数操作,优化器会放弃走树搜索功能。
隐式字符编码转换
假设还有另外一个表 trade_detail,用于记录交易的操作细节。为了便于量化分析和复现,往交易日志表 tradelog 和交易详情表 trade_detail 这两个表里插入一些数据。
mysql> CREATE TABLE `trade_detail` (
`id` int(11) NOT NULL,
`tradeid` varchar(32) DEFAULT NULL,
`trade_step` int(11) DEFAULT NULL, /*操作步骤*/
`step_info` varchar(32) DEFAULT NULL, /*步骤信息*/
PRIMARY KEY (`id`),
KEY `tradeid` (`tradeid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8; insert into tradelog values(1, 'aaaaaaaa', 1000, now());
insert into tradelog values(2, 'aaaaaaab', 1000, now());
insert into tradelog values(3, 'aaaaaaac', 1000, now()); insert into trade_detail values(1, 'aaaaaaaa', 1, 'add');
insert into trade_detail values(2, 'aaaaaaaa', 2, 'update');
insert into trade_detail values(3, 'aaaaaaaa', 3, 'commit');
insert into trade_detail values(4, 'aaaaaaab', 1, 'add');
insert into trade_detail values(5, 'aaaaaaab', 2, 'update');
insert into trade_detail values(6, 'aaaaaaab', 3, 'update again');
insert into trade_detail values(7, 'aaaaaaab', 4, 'commit');
insert into trade_detail values(8, 'aaaaaaac', 1, 'add');
insert into trade_detail values(9, 'aaaaaaac', 2, 'update');
insert into trade_detail values(10, 'aaaaaaac', 3, 'update again');
insert into trade_detail values(11, 'aaaaaaac', 4, 'commit');
如果要查询 id=2 的交易的所有操作步骤信息,SQL 可以这么写:
mysql> select d.* from tradelog l, trade_detail d where d.tradeid=l.tradeid and l.id=2; /*语句Q1*/

这个结果可以分为3步:
第 1 步,是根据 id 在 tradelog 表里找到 L2 这一行;
第 2 步,是从 L2 中取出 tradeid 字段的值;
第 3 步,根据 tradeid 值到 trade_detail 表中查条件匹配的行。explain 的结果里面第二行的 key=NULL 表示的就是,这个过程是通过遍历主键索引的方式,一个一个地判断 tradeid 的值是否匹配。
我们发现第 3 步不符合预期。因为表 trade_detail 里 tradeid 字段上是有索引的,我们本来是希望通过使用 tradeid 索引能够快速定位到等值的行。但这里并没有。
通过观察两个表的差异我们发现:这两个表的字符集不同,一个是 utf8,一个是 utf8mb4。
通常如果这时候我们去搜索,可以得到这样的答案:不同字符集的表连接查询的时候可能用不上关联字段的索引。
但我想更进一步探求原因。单独把第3步拎出来:
mysql> select * from trade_detail where tradeid=$L2.tradeid.value;
其中,$L2.tradeid.value 的字符集是 utf8mb4。
我们知道,字符集 utf8mb4 是 utf8 的超集。
所以当这两个类型的字符串在做比较的时候,MySQL 内部的操作是,先把 utf8 字符串转成 utf8mb4 字符集,再做比较。
这个设定很好理解,utf8mb4 是 utf8 的超集。类似地,在程序设计语言里面,做自动类型转换的时候,为了避免数据在转换过程中由于截断导致数据错误,也都是“按数据长度增加的方向”进行转换的。
实际上这个语句等同于下面这个写法:
select * from trade_detail where CONVERT(traideid USING utf8mb4)=$L2.tradeid.value;
CONVERT() 函数,在这里的意思是把输入的字符串转成 utf8mb4 字符集。
这就再次触发了我们上面说到的原则:对索引字段做函数操作,优化器会放弃走树搜索功能。
作为对比验证,我们实现另一个需求,“查找 trade_detail 表里 id=4 的操作,对应的操作者是谁”。
mysql>select l.operator from tradelog l , trade_detail d where d.tradeid=l.tradeid and d.id=4;

类似上面的分析,我们最后可以将关键sql简化为:
select operator from tradelog where traideid =CONVERT($R4.tradeid.value USING utf8mb4);
这里的 CONVERT 函数是加在输入参数上的,这样就可以用上索引。
理解了原理以后,假设现在要优化下面sql语句:
select d.* from tradelog l, trade_detail d where d.tradeid=l.tradeid and l.id=2;
1. 比较常见的优化方法是,把 trade_detail 表上的 tradeid 字段的字符集也改成 utf8mb4,这样就没有字符集转换的问题了。
2.如果能够修改字段的字符集的话,是最好不过了。但如果数据量比较大, 或者业务上暂时不能做这个 DDL 的话,那就只能采用修改 SQL 语句的方法了。
mysql> select d.* from tradelog l , trade_detail d where d.tradeid=CONVERT(l.tradeid USING utf8) and l.id=2;

主动把 l.tradeid 转成 utf8,就避免了字符编码转换,从 explain 结果可以看到,这次索引走对了。
谈谈一些逻辑相同,性能差异却很大的sql的更多相关文章
- Memcache缓存用好了,性能有了很大的提高
web服务器1 web服务器2 web服务器3如果每台web服务器都向mysql服务器表插入信息并且要做出相应最新编号反馈出现这样的高并发时候怎么减少服务器压力,同时用户体验还要好 可以使用Memca ...
- [转] 剖析 epoll ET/LT 触发方式的性能差异误解(定性分析)
http://blog.chinaunix.net/uid-17299695-id-3059078.html PS:Select和Poll都是水平触发,epoll默认也是水平触发 ET模式仅当状态发生 ...
- 固态硬盘和机械硬盘的比较和SQLSERVER在两种硬盘上的性能差异
固态硬盘和机械硬盘的比较和SQLSERVER在两种硬盘上的性能差异 在看这篇文章之前可以先看一下下面的文章: SSD小白用户收货!SSD的误区如何解决 这样配会损失性能?实测6种特殊装机方式 听说固态 ...
- 比较一下以“反射”和“表达式”执行方法的性能差异
由于频繁地使用反射会影响性能,所以ASP.NET MVC采用了表达式树的方式来执行目标Action方法.具体来说,ASP.NET MVC会构建一个表达式来体现针对目标Action方法的执行,并且将该表 ...
- JMeter下Groovy和BeanShell语言在不同组件中性能差异实践探究
一般而言JMeter下性能最好的是jar包这类java原生请求,对于JMeter并没有原生支持的请求,一般都会将其直接编译为jar包,然后再JMeter中调用,这样性能最好. 但是有些需求并不适合用j ...
- 关于JS动画和CSS3动画的性能差异
本文章为综合其它资料所得. 根据Google Developer,Chromium项目里,渲染线程分为main thread和compositor thread. 如果CSS动画只是改变transfo ...
- SQL Server ->> DISABLE索引后插入更新数据再REBUILD索引 和 保留索引直接插入更新数据的性能差异
之前对于“DISABLE索引后插入更新数据再REBUILD索引 和 保留索引直接插入更新数据的性能差异”这两种方法一直认为其实应该差不多,因为无论如何索引最后都需要被维护,只不过是个时间顺序先后的问题 ...
- 使用ab.exe监测100个并发/100次请求情况下同步/异步访问数据库的性能差异
ab.exe介绍 ab.exe是apache server的一个组件,用于监测并发请求,并显示监测数据 具体使用及下载地址请参考:http://www.cnblogs.com/gossip/p/439 ...
- 痞子衡嵌入式:对比MbedTLS算法库纯软件实现与i.MXRT上DCP,CAAM硬件加速器实现性能差异
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家介绍的是MbedTLS算法库纯软件实现与i.MXRT上DCP,CAAM硬件加速器实现性能差异. 近期有 i.MXRT 客户在集成 OTA SBL ...
随机推荐
- jquery mobile AJAX特性的陷阱
简单情况是 MVC 重定向,URL不变 试了N种方式,跳来跳去,无解,服务端跳,写JS跳,生成跳转中间页跳.失败 后来一看,明明已经跳到新页了,样式什么还是原页的,有点火大了. 出去溜一圈,喝杯水,和 ...
- 奇异值分解SVD
在介绍奇异值分解(SVD)之前我们先来回顾一下关于矩阵的一些基础知识. 矩阵基础知识 方阵 给定一个$ n×m $的矩阵$ A $,若n和m相等也就是矩阵的行和列相等那矩阵$ A $就是一个方阵. 单 ...
- 机器学习入门 - 逻辑(Logistic)回归(5)
原文地址:http://www.bugingcode.com/machine_learning/ex7.html 把所有的问题都转换为程序问题,可以通过程序来就问题进行求解了. 这里的模拟问题来之于C ...
- JavaIO 流(1)IO流介绍
IO流定义: 流的本质是一组单向有序,分起始和终止的数据传输过程.需要导入import java.io.* IO流分类: 按数据类型分为:字节流和字符流 字节流: 按字节进行读取(可以处理任意类型数据 ...
- 你还记得2017年火爆的VR街机店,这一年他们过得还好吗?
对于当下太过急于成功.一夜暴富的人们来说,似乎总是会急不可耐地去抓住每一个有可能成为大势的风口.在这份普遍存在的浮躁心理下,蕴含着极大的不确定性--既让大众认识到太多的创新产品和服务,也让很多参与者痛 ...
- 2019-04-18-NFV基础概念
NFV技术的起源和概念 在移动互联网时代,运营商面临内外困局.就自身而言,采用的流量增长-网络扩容-收入增长的商业模型正在失效,庞大.僵化的电信基础网络,不能够满足用户的丰富需求:就竞争对手而言,互联 ...
- Jetson TX2镜像刷板法
使用Nvidia官方自带的脚本,备份镜像.恢复镜像,快速在新板子中部署DL环境 在之前的一篇博客中,详细介绍了使用JetPack刷系统以及使用离线包部署DL环境(cuda.cudnn.opencv.c ...
- 5.7之sql_model
问题发生背景 今天在部署项目的时候发现,测试后台接口,直接报 500,仔细一看原来是操作数据库的时候报错了,在本地测试的时候是没遇到类似的问题,数据库的版本是一样的,后面查找资料,说是 MySQL 5 ...
- Ubuntu 16.04 apt 国内源
一.推荐几个 Ubuntu 16.04 国内的 apt 源 1. 阿里源 # deb cdrom:[Ubuntu 16.04 LTS _Xenial Xerus_ - Release amd64 (2 ...
- 一文了解各大图数据库查询语言(Gremlin vs Cypher vs nGQL)| 操作入门篇
文章的开头我们先来看下什么是图数据库,根据维基百科的定义:图数据库是使用图结构进行语义查询的数据库,它使用节点.边和属性来表示和存储数据. 虽然和关系型数据库存储的结构不同(关系型数据库为表结构,图数 ...