入门大数据---Kafka的搭建与应用
前言
上一章介绍了Kafka是什么,这章就讲讲怎么搭建以及如何使用。
快速开始
Step 1:Download the code
Download the 2.4.1 release and un-tar it.
> tar -xzf kafka_2.12-2.4.1.tgz
> cd kafka_2.12-2.4.1
Step 2: Start the server
Kafka使用Zookeeper,所以如果您还没有启动,请先启动它。您还可以通过Kafka随附的便利脚本启动Zookeeper单节点实例。
> bin/zookeeper-server-start.sh config/zookeeper.properties
现在启动Kafka服务器。
> bin/kafka-server-start.sh config/server.properties
Step 3: Create a topic
让我们用一个分区和一个副本创建一个名为'test'的主题。
> bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic test
现在我们运行list topic命令,我们可以看到主题。
> bin/kafka-topics.sh --list --bootstrap-server localhost:9092
test
或者,除了手动创建主题外,还可以使用代理,在发布不存在的主题时自动进行创建。
Step 4: Send some messages
Kafka有一个命令行客户端,可以接收文件和一些标准输入,并将其作为消息发送给Kafka。默认是一行一行发送的。
运行producer:
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
This is a message
This is another message
Step 5: Start a consumer
Kafka还有一个命令行工具,他将数据进行标准输出。
> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
This is a message
This is another message
如果上面的每个命令在不同的终端运行,那么您键入的输入,将会看到相应的输出。
Step 6: Setting up a multi-broker cluster
配置多个代理,还是在同一个电脑进行演示。
首先为每个代理创建一个配置文件:
> cp config/server.properties config/server-1.properties
> cp config/server.properties config/server-2.properties
现在,根据下面属性对新文件进行配置。
config/server-1.properties:
broker.id=1
listeners=PLAINTEXT://:9093
log.dirs=/tmp/kafka-logs-1
config/server-2.properties:
broker.id=2
listeners=PLAINTEXT://:9094
log.dirs=/tmp/kafka-logs-2
broker.id属性是集群中唯一且永久的名称。我们只需要覆盖端口和日志目录,这是因为我们在同一台计算机上运行它们,并且希望所有代理不要在同一端口上进行注册和覆盖彼此数据。
我们已经有Zookeeper并启动了单个节点,因为我们只需要启动两个新节点(&是在后台启动的意思):
> bin/kafka-server-start.sh config/server-1.properties &
...
> bin/kafka-server-start.sh config/server-2.properties &
...
创建具有三个复制因子的主题:
> bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 3 --partitions 1 --topic my-replicated-topic
然后,现在 有了集群我们应该如何知道每个 broker 在做什么?请运行describe topics命令即可查看:
> bin/kafka-topics.sh --describe --bootstrap-server localhost:9092 --topic my-replicated-topic
...
Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs:
Topic: my-replicated-topic Partition: 0 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0
参数介绍:
“leader”:负责读取和写入数据。
"replicates":副本集合。
"isr":同步"副本"集合。
我们在创建的原始topic上运行同样命令:
> bin/kafka-topics.sh --describe --bootstrap-server localhost:9092 --topic test
Topic:test PartitionCount:1 ReplicationFactor:1 Configs:
Topic: test Partition: 0 Leader: 0 Replicas: 0 Isr: 0
可以看到原始主题没有副本。
让我们发送消息测试下:
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic my-replicated-topic
...
my test message 1
my test message 2
现在让我们使用这些信息:
> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic my-replicated-topic
...
my test message 1
my test message 2
然后测试下容错能力,broker扮演领导者角色,所以让我们杀死他。
> ps aux | grep server-1.properties
> kill -9 7564
领导者已切换为副本之一,并且领导1不再位于同步副本集(isr)中。
但是即使最初读写消息的leader已经下线,消息仍然可用。
> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic my-replicated-topic
...
my test message 1
my test message 2
^C
Step 7: Use Kafka Connect to import/export data
除了实现控制台的导入导出,还可以通过Kafka Connect实现文件的导入导出。
首先我们创建一些测试数据进行演示:
echo -e "hello\nworld" > test.txt
接下来,我们启动两个Connector进行链接,这样它们将在本地专用进行运行。
bin/connect-standalone.sh config/connec.properties config/connect-file-source.properties config/connect-file-sink.properties
connect-standalone.properties包含文件的通用配置,如何要链接kafka代理服务器和序列化的格式,其余配置文件均制定要创建的连接器(如:连接器名称,连接器类和其它配置)。
可以看到
> more test.sink.txt
hello
world
PS:根据配置,我们可以得知数据存储在connect-test里面,因为我们可以通过控制台或者自定义查询。
> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic connect-test --from-beginning
连接器持续处理,因此我们可以追加内容以进行验证
> echo Another line>> test.txt
你可以看到内容已经追加了。
在Kafka上运行应用程序
这个教程从0开始了,如果您已经运行Kafa和Zookeeper可以略过前两步。
Step 1: Download the code
Download 2.4.1并解压。
> tar -xzf kafka_2.12-2.4.1.tgz
> cd kafka_2.12-2.4.1
Step 2: Start the Kafka server
Kafka使用Zookeeper,如果您还没有,请先启动。
> bin/zookeeper-server-start.sh config/zookeeper.properties
现在启动Kafka服务器:
> bin/kafka-server-start.sh config/server.properties
Step 3: Prepare input topic and start Kafka producer
接下来,我们创建streams-plaintext-input的输入主题和streams-wordcount-output的输出主题。
创建streams-plaintext-input:
> bin/kafka-topics.sh --create \
--bootstrap-server localhost:9092 \
--replication-factor 1 \
--partitions 1 \
--topic streams-plaintext-input
创建streams-wordcount-output:
> bin/kafka-topics.sh --create \
--bootstrap-server localhost:9092 \
--replication-factor 1 \
--partitions 1 \
--topic streams-wordcount-output \
--config cleanup.policy=compact
可以使用kafka-topics来展示创建的主题:
> bin/kafka-topics.sh --bootstrap-server localhost:9092 --describe
Step 4: Start the Wordcount Application
以下命令启动Wordcount演示的应用程序:
> bin/kafka-run-class.sh org.apache.kafka.streams.examples.wordcount.WordCountDemo
启动后,它会从输入的流中自动计算每一行数据,然后输出到指定主题。
现在,我们可以单独的在一个终端中启动控制台producer,来写入一些数据:
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic streams-plaintext-input
并通过单独的终端consumer与Wordcount应用程序查看输出结果是否正确。
> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic streams-wordcount-output \
--from-beginning \
--formatter kafka.tools.DefaultMessageFormatter \
--property print.key=true \
--property print.value=true \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
Step 5: Process some data
现在我们手动的输入一些输入,并点击RETURN发送到streams-plaintext-input中,数据的 格式是键=null,值=刚输入的值。
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic streams-plaintext-input
all streams lead to kafka
Wordcount将处理输入的数据,然后将数据存在streams-wordcount-output主题中,并在控制台打印,如下所示:
> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic streams-wordcount-output \
--from-beginning \
--formatter kafka.tools.DefaultMessageFormatter \
--property print.key=true \
--property print.value=true \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
all 1
streams 1
lead 1
to 1
kafka 1
我们还可以输入一些数据,演示如下:
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic streams-plaintext-input
hello kafka streams
然后再另一个消费者终端上,我们将看到如下输出:
> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic streams-wordcount-output \
--from-beginning \
--formatter kafka.tools.DefaultMessageFormatter \
--property print.key=true \
--property print.value=true \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
all 1
streams 1
lead 1
to 1
kafka 1
hello 1
kafka 2
streams 2
从上面得知,流处理可以做到实时统计。下面是一些处理原理:


可以看到数据是依次累加的。
Step 6: Teardown the application
使用ctrl+C停止应用。
编写Kafka应用程序
Setting up a Maven Project
新建一个Maven项目,暂且取名KafkaTest,然后引入Kafka包,如下:
<!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka-streams -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>2.5.0</version>
</dependency>
注意:项目依赖于Java1.8,不适合更高版本的Java。
Writing a first Streams application: Pipe
开始编写代码,首先创建一个Pipe.java类。
package myapps;
public class Pipe {
public static void main(String[] args) throws Exception {
}
}
编写Streams应用程序第一步是创建一个java.util.Properties映射,以指定StreamsConfig中定义的不同Streams执行配置值。您需要设置几个重要的配置值:
StreamsConfig.BOOTSTRAP_SERVERS_CONFIG(用于指定建立与Kafka链接的主机和端口)和StreamsConfig.APPLICATION_ID_CONFIG(用于提供Streams的唯一标识符)。
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "streams-pipe");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
此外,您还可以定义一些其它配置,例如定义值的序列化和反序列化:
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass()); props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG,Serdes.String().getClass());
有关Kafka Streams更多配置信息,请参考此表。
在Kafka Streams中,处理逻辑被定义为链接的拓扑,接下来我们先定义一个拓扑构建器:
final StreamsBuilder builder = new StreamsBuilder();
然后使用拓扑生成器,生成streams-plaintext-input生成的源流。
KStream<String, String> source = builder.stream("streams-plaintext-input");
现在我们得到了一个KStream,它从源主题streams-plaintext-input连续生成记录,记录被组织为键值对。我们可以使用此流执行简单操作,将它写入另一个主题streams-pipe-output:
source.to("streams-pipe-output");
请注意,我们还可以将上面两行连为一行:
builder.stream("streams-plaintext-input").to("streams-pipe-output");
通过创建以下操作,我们可以执行从构建器创建的拓扑类型:
final Topology topology = builder.build();
并将其打印为标准输出为:
System.out.println(topology.describe());
如果我们现在打印,它将输出下面的信息:
Topologies:
Sub-topology: 0
Source: KSTREAM-SOURCE-0000000000 (topics: [streams-plaintext-input])
--> KSTREAM-SINK-0000000001
Sink: KSTREAM-SINK-0000000001 (topic: streams-pipe-output)
<-- KSTREAM-SOURCE-0000000000
如上所示,它说明了构造的拓扑具有两个处理器节点,即源节点KSTREAM-SOURCE-0000000000和宿节点KSTREAM-SINK-0000000001。 KSTREAM-SOURCE-0000000000连续从Kafka主题流-明文输入中读取记录,并将它们通过管道传输到其下游节点KSTREAM-SINK-0000000001; KSTREAM-SINK-0000000001会将接收到的每个记录写入另一个Kafka主题streams-pipe-output(->和<-箭头指示此节点的下游和上游处理器节点,即“子级”和“父”)。它还说明了这种简单的拓扑没有与之关联的全局状态存储(我们将在以下各节中讨论状态存储)。
请注意,当我们在代码中构建拓扑时,我们始终可以在任何给定的点上像上面一样描述拓扑,因此作为用户,您可以交互地“尝试”拓扑中定义的计算逻辑,直到对它满意为止。假设我们已经完成了这种简单的拓扑结构,即以一种无限的流方式将数据从一个Kafka主题传送到另一个主题,现在我们可以使用上面刚刚构建的两个组件来构造Streams客户端:在Java中指定的配置映射。 util.Properties实例和拓扑对象。
final KafkaStreams streams=new KafkaStreams(topology,props);
我们可以调用start来执行此对象,在触发close之前,执行不会停止。例如,我们可以添加一个关闭倒计时的闩锁,以捕获该用户终端,并在终止程序时关闭客户端。
final CountDownLatch latch = new CountDownLatch(1);
Runtime.getRuntime().addShutdownHook(new Thread("streams-shutdown-hook") {
@Override
public void run() {
streams.close();
latch.countDown();
}
});
try {
streams.start();
latch.await();
} catch (Throwable e) {
System.exit(1);
}
System.exit(0);
到目前为止,完整的示例代码如下:
package myapps;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.Topology;
import java.util.Properties;
import java.util.concurrent.CountDownLatch;
public class Pipe {
public static void main(String[] args) throws Exception {
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "streams-pipe");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
final StreamsBuilder builder = new StreamsBuilder();
builder.stream("streams-plaintext-input").to("streams-pipe-output");
final Topology topology = builder.build();
final KafkaStreams streams = new KafkaStreams(topology, props);
final CountDownLatch latch = new CountDownLatch(1);
// attach shutdown handler to catch control-c
Runtime.getRuntime().addShutdownHook(new Thread("streams-shutdown-hook") {
@Override
public void run() {
streams.close();
latch.countDown();
}
});
try {
streams.start();
latch.await();
} catch (Throwable e) {
System.exit(1);
}
System.exit(0);
}
}
Writing a second Streams application: Line Split
我们已经学习了如何使用两个关键组建构造Streams客户端:StreamsConfig和Topoloty。现在我们继续通过扩展来添加一些实际逻辑。我们可以复制现有的Pipe.java类来创建另一个程序(取名:LineSplit.java)。
并修改Id与原始程序区分开:
public class LineSplit {
public static void main(String[] args) throws Exception {
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "streams-linesplit");
// ...
}
}
由于数据源是键值对,我们将值作为文本行,并使用FlatMapValues拆分单词:
KStream<String, String> source = builder.stream("streams-plaintext-input");
KStream<String, String> words = source.flatMapValues(new ValueMapper<String, Iterable<String>>() {
@Override
public Iterable<String> apply(String value) {
return Arrays.asList(value.split("\\W+"));
}
});
运算符将源流作为其输入,并通过按顺序处理其源流中的每个记录并将其值字符串分解为单词列表,并将每个单词作为新记录生成到输出,来生成名为单词的新流。 文字流。 这是一个无状态运算符,不需要跟踪任何以前收到的记录或已处理的结果。 请注意,如果您使用的是JDK 8,则可以使用lambda表达式并将上述代码简化为:
KStream<String, String> source = builder.stream("streams-plaintext-input");
KStream<String, String> words = source.flatMapValues(value -> Arrays.asList(value.split("\\W+")));
最后,我们可以将stream这个词写回到另一个Kafka主题,即streams-linesplit-output。 同样,可以将以下两个步骤串联起来(假设使用了lambda表达式):
KStream<String, String> source = builder.stream("streams-plaintext-input");
source.flatMapValues(value -> Arrays.asList(value.split("\\W+")))
.to("streams-linesplit-output");
如果现在将这种扩展拓扑描述为System.out.println(topology.describe()),则会得到以下内容:
> mvn clean package
> mvn exec:java -Dexec.mainClass=myapps.LineSplit
Sub-topologies:
Sub-topology: 0
Source: KSTREAM-SOURCE-0000000000(topics: streams-plaintext-input) --> KSTREAM-FLATMAPVALUES-0000000001
Processor: KSTREAM-FLATMAPVALUES-0000000001(stores: []) --> KSTREAM-SINK-0000000002 <-- KSTREAM-SOURCE-0000000000
Sink: KSTREAM-SINK-0000000002(topic: streams-linesplit-output) <-- KSTREAM-FLATMAPVALUES-0000000001
Global Stores:
none
如上所示,新的处理器节点KSTREAM-FLATMAPVALUES-0000000001被注入到原始源节点和宿节点之间的拓扑中。 它以源节点为父节点,宿节点为子节点。 换句话说,由源节点获取的每个记录将首先遍历到要添加的新添加的KSTREAM-FLATMAPVALUES-0000000001节点,结果将生成一个或多个新记录。 它们将继续遍历到接收器节点以写回到Kafka。 请注意,此处理器节点是“无状态”的,因为它没有与任何存储(即(存储:[]))相关联。
完整的代码如下所示(使用Lambda表示):
package myapps;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.Topology;
import org.apache.kafka.streams.kstream.KStream;
import java.util.Arrays;
import java.util.Properties;
import java.util.concurrent.CountDownLatch;
public class LineSplit {
public static void main(String[] args) throws Exception {
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "streams-linesplit");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
final StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> source = builder.stream("streams-plaintext-input");
source.flatMapValues(value -> Arrays.asList(value.split("\\W+")))
.to("streams-linesplit-output");
final Topology topology = builder.build();
final KafkaStreams streams = new KafkaStreams(topology, props);
final CountDownLatch latch = new CountDownLatch(1);
// ... same as Pipe.java above
}
}
Writing a third Streams application: Wordcount
现在,我们进一步采取措施,通过对从源文本流中拆分出的单词进行计数来向拓扑添加一些“状态”计算。 按照类似的步骤,让我们基于LineSplit.java类创建另一个程序:
public class WordCount {
public static void main(String[] args) throws Exception {
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "streams-wordcount");
// ...
}
}
为了对单词进行计数,我们可以首先修改flatMapValues运算符以将它们全部视为小写(假设使用了lambda表达式):
source.flatMapValues(new ValueMapper<String, Iterable<String>>() {
@Override
public Iterable<String> apply(String value) {
return Arrays.asList(value.toLowerCase(Locale.getDefault()).split("\\W+"));
}
});
为了进行计数汇总,我们必须首先指定我们要使用groupBy运算符将流键入值字符串(即小写单词)。 此运算符生成一个新的分组流,然后可以由count运算符聚合,该操作会在每个分组键上生成一个运行计数:
KTable<String, Long> counts =
source.flatMapValues(new ValueMapper<String, Iterable<String>>() {
@Override
public Iterable<String> apply(String value) {
return Arrays.asList(value.toLowerCase(Locale.getDefault()).split("\\W+"));
}
})
.groupBy(new KeyValueMapper<String, String, String>() {
@Override
public String apply(String key, String value) {
return value;
}
})
// Materialize the result into a KeyValueStore named "counts-store".
// The Materialized store is always of type <Bytes, byte[]> as this is the format of the inner most store.
.count(Materialized.<String, Long, KeyValueStore<Bytes, byte[]>> as("counts-store"));
请注意,count运算符具有一个Materialized参数,该参数指定运行计数应存储在名为counts-store的状态存储中。 可以实时查询此Counts存储,详细信息在《开发人员手册》中进行了描述。
我们还可以将计数KTable的changelog流写回到另一个Kafka主题,即streams-wordcount-output。 由于结果是更改日志流,因此应在启用日志压缩的情况下配置输出主题streams-wordcount-output。 请注意,这次值类型不再是String而是Long,因此默认的序列化类不再适用于将其写入Kafka的情况。 我们需要为Long类型提供重写的序列化方法,否则将抛出运行时异常:
counts.toStream().to("streams-wordcount-output", Produced.with(Serdes.String(), Serdes.Long()));
请注意,为了从主题streams-wordcount-output读取变更日志流,需要将反序列化值设置为org.apache.kafka.common.serialization.LongDeserializer。 有关详细信息,请参见“使用流应用程序播放”部分。 假设可以使用JDK 8中的lambda表达式,则上述代码可以简化为:
KStream<String, String> source = builder.stream("streams-plaintext-input");
source.flatMapValues(value -> Arrays.asList(value.toLowerCase(Locale.getDefault()).split("\\W+")))
.groupBy((key, value) -> value)
.count(Materialized.<String, Long, KeyValueStore<Bytes, byte[]>>as("counts-store"))
.toStream()
.to("streams-wordcount-output", Produced.with(Serdes.String(), Serdes.Long()));
如果我们再次将该增强拓扑描述为System.out.println(topology.describe()),则会得到以下内容:
> mvn clean package
> mvn exec:java -Dexec.mainClass=myapps.WordCount
Sub-topologies:
Sub-topology: 0
Source: KSTREAM-SOURCE-0000000000(topics: streams-plaintext-input) --> KSTREAM-FLATMAPVALUES-0000000001
Processor: KSTREAM-FLATMAPVALUES-0000000001(stores: []) --> KSTREAM-KEY-SELECT-0000000002 <-- KSTREAM-SOURCE-0000000000
Processor: KSTREAM-KEY-SELECT-0000000002(stores: []) --> KSTREAM-FILTER-0000000005 <-- KSTREAM-FLATMAPVALUES-0000000001
Processor: KSTREAM-FILTER-0000000005(stores: []) --> KSTREAM-SINK-0000000004 <-- KSTREAM-KEY-SELECT-0000000002
Sink: KSTREAM-SINK-0000000004(topic: Counts-repartition) <-- KSTREAM-FILTER-0000000005
Sub-topology: 1
Source: KSTREAM-SOURCE-0000000006(topics: Counts-repartition) --> KSTREAM-AGGREGATE-0000000003
Processor: KSTREAM-AGGREGATE-0000000003(stores: [Counts]) --> KTABLE-TOSTREAM-0000000007 <-- KSTREAM-SOURCE-0000000006
Processor: KTABLE-TOSTREAM-0000000007(stores: []) --> KSTREAM-SINK-0000000008 <-- KSTREAM-AGGREGATE-0000000003
Sink: KSTREAM-SINK-0000000008(topic: streams-wordcount-output) <-- KTABLE-TOSTREAM-0000000007
Global Stores:
none
完整的代码如下所示(假设用了lambda表达式):
package myapps;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.Topology;
import org.apache.kafka.streams.kstream.KStream;
import java.util.Arrays;
import java.util.Locale;
import java.util.Properties;
import java.util.concurrent.CountDownLatch;
public class WordCount {
public static void main(String[] args) throws Exception {
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "streams-wordcount");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
final StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> source = builder.stream("streams-plaintext-input");
source.flatMapValues(value -> Arrays.asList(value.toLowerCase(Locale.getDefault()).split("\\W+")))
.groupBy((key, value) -> value)
.count(Materialized.<String, Long, KeyValueStore<Bytes, byte[]>>as("counts-store"))
.toStream()
.to("streams-wordcount-output", Produced.with(Serdes.String(), Serdes.Long()));
final Topology topology = builder.build();
final KafkaStreams streams = new KafkaStreams(topology, props);
final CountDownLatch latch = new CountDownLatch(1);
// ... same as Pipe.java above
}
}
核心概念
Stream Processing Topology

Kafka Streams提供了两种定义流拓扑的方法:Kafka Streams DSL提供了通用的数据转换操作,例如开箱即用的map,filter,join和aggregation。低级处理器API允许开发人员定义和链接自定义处理器以及状态存储进行交互。
Time
Kafka几种时间概念:
事件时间-事件或数据记录发生的时间点,即最初是在“源”上创建的。示例:如果事件是汽车中GPS传感器报告的地理位置变化,则关联的事件时间将是GPS传感器捕获位置变化的时间。
处理时间-事件或数据记录恰好由流处理应用程序处理的时间点,即消费记录时的时间点。处理时间可能比原始事件时间晚几毫秒,几小时或几天等。示例:设想一个分析应用程序读取并处理从汽车传感器报告的地理位置数据,并将其呈现给车队管理仪表板。在这里,分析应用程序中的处理时间可能是事件发生后的毫秒或秒(例如,基于Apache Kafka和Kafka Streams的实时管道)或几小时(例如,基于Apache Hadoop或Apache Spark的批处理管道)。
摄取时间-Kafka代理将事件或数据记录存储在主题分区中的时间点。事件时间与事件时间的区别在于,摄取记录是在Kafka代理将记录添加到目标主题时生成的,而不是在“源头”创建记录时生成的。处理时间的区别在于处理时间是流处理应用程序处理记录的时间。例如,如果一条记录从未被处理过,则没有处理时间的概念,但是它仍然具有提取时间。
Aggregations
聚合操作采用一个输入流或表,并通过将多个输入记录合并为一个输出记录来产生一个新表。 聚合的示例是计算计数或总和。
在Kafka Streams DSL中,聚合的输入流可以是KStream或KTable,但输出流始终是KTable。 这使得Kafka Streams在产生和发出值之后,如果其他记录无序到达,则可以更新汇总值。 当发生这种无序到达时,聚合的KStream或KTable会发出新的聚合值。 由于输出是KTable,因此在后续处理步骤中,新值将被视为使用相同的键覆盖旧值。
Windowing
窗口化使您可以控制如何对具有相同键的记录进行分组,以进行有状态操作(例如聚合或加入所谓的窗口)。每个记录键都跟踪Windows。
Kafka Streams DSL中提供了窗口操作。使用窗口时,可以为窗口指定宽限期。该宽限期控制Kafka Streams将等待给定窗口多长时间的无序数据记录。如果在窗口的宽限期过去之后到达记录,则该记录将被丢弃,并且不会在该窗口中进行处理。具体来说,如果一条记录的时间戳指示它属于某个窗口,则该记录将被丢弃,但是当前流时间大于该窗口的末尾加上宽限期。
乱序记录在现实世界中始终是可能的,并且应在您的应用程序中适当考虑。这取决于有效时间语义,如何处理乱序记录。在处理时间的情况下,语义是“正在处理记录时”,这意味着乱序记录的概念不适用,因为根据定义,任何记录都不会乱序。因此,无序记录只能被认为是事件时间。在这两种情况下,Kafka Streams都能正确处理乱序记录。
Duality of Streams and Tables
流处理时支持容错的状态处理或针对最新处理结果交互查询。
States
为复杂数据定义状态,提高可查询性。
PROCESSING GUARANTEES处理保证
Kafka从0.11.0 版本开始能够精准的只对数据处理一次。
Out-of-Order Handling乱序处理
从多个主题接收的数据无法保证它们的顺序不是乱的,所以只能在延迟,成本和正确性间做出平衡。
Architecture
Kafka实现了并发,分布式,高可用,这些都是底层实现的,具体背后原理这节就剖析下。
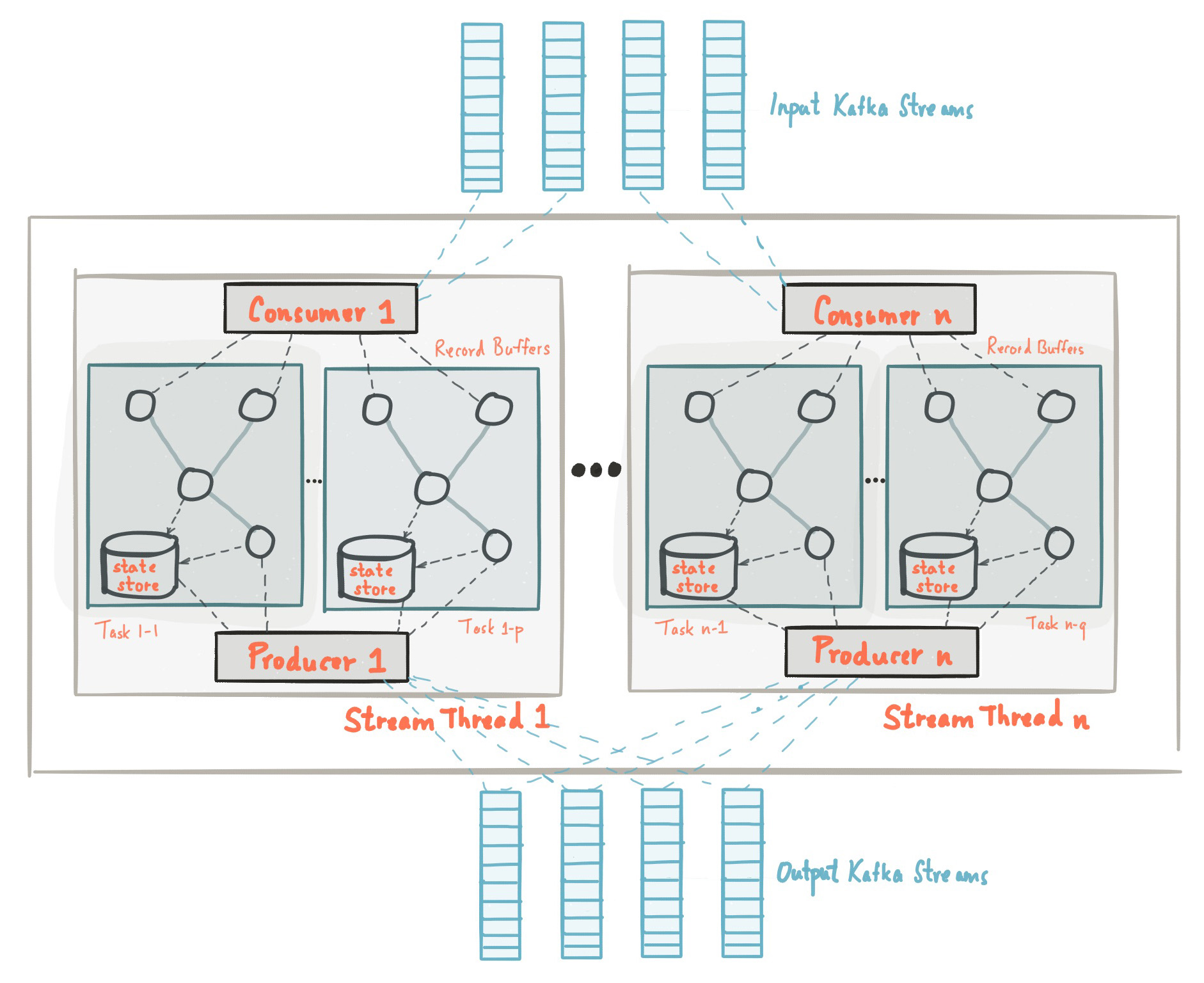
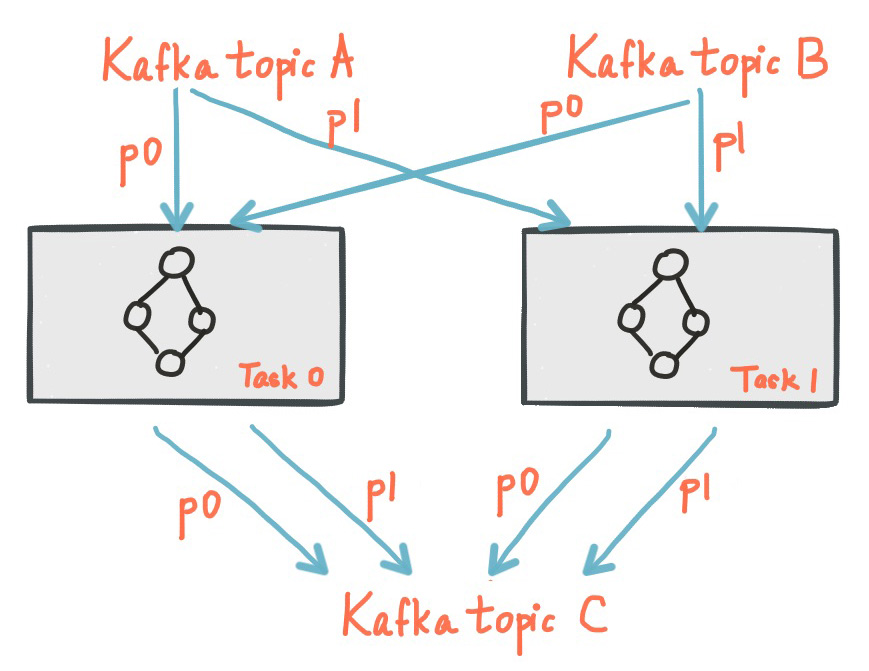
Stream Partitions and Tasks
分区的数量决定了最大执行任务的数量。
下面显示了两个任务 ,每个 任务都有输入流的一个分区。
Threading Model
Kafka并行处理,如上图所示。
Local State Stores
Kafka Streams提供了所谓的状态存储,流处理应用程序可以使用它们来存储和查询数据,这是实现有状态操作时的一项重要功能。 例如,当您调用诸如join()或gregation()之类的有状态运算符时,或在对流进行窗口化时,Kafka Streams DSL会自动创建并管理此类状态存储。
Kafka Streams应用程序中的每个流任务都可以嵌入一个或多个本地状态存储,可以通过API进行访问以存储和查询处理所需的数据。 Kafka Streams为此类本地状态存储提供容错和自动恢复。
下图显示了两个流任务及其专用的本地状态存储。
Fault Tolerance容错能力
Kafka Streams建立在Kafka本地集成的容错功能的基础上。 Kafka分区具有高可用性并可以复制;因此,当流数据持久保存到Kafka时,即使应用程序失败并需要对其进行重新处理,该数据仍然可用。 Kafka Streams中的任务利用Kafka客户客户端提供的容错功能来处理故障。如果任务在失败的计算机上运行,Kafka Streams会在应用程序的其余运行实例之一中自动重新启动任务。
此外,Kafka Streams还确保本地状态存储也对故障具有鲁棒性。对于每个状态存储,它维护一个复制的变更日志Kafka主题,在其中跟踪任何状态更新。这些变更日志主题也进行了分区,因此每个本地状态存储实例以及访问该存储的任务都有自己的专用变更日志主题分区。在changelog主题上启用了日志压缩,因此可以安全清除旧数据,以防止主题无限期增长。如果任务在发生故障的计算机上运行并在另一台计算机上重新启动,则Kafka Streams通过在恢复对新启动的任务的处理之前重播相应的变更日志主题,来保证将其关联的状态存储恢复到故障之前的内容。结果,故障处理对最终用户是完全透明的。
请注意,任务(重新)初始化的成本通常主要取决于通过重播状态存储的关联变更日志主题来恢复状态的时间。为了最大程度地缩短恢复时间,用户可以将其应用程序配置为具有本地状态的备用副本(即状态的完全复制副本)。当任务迁移发生时,Kafka Streams然后尝试将任务分配给已经存在此类备用副本的应用程序实例,以最小化任务(重新)初始化成本。请参阅“ Kafka流配置”部分中的num.standby.replicas。
Kafka Streams开发人员指南
Writing a Streams Application
Kafka依赖项:
| Group ID | Artifact ID | Version | Description |
|---|---|---|---|
| org.apache.kafka | kafka-streams | 2.5.0 | (必需)Kafka Streams的基本库。 |
| org.apache.kafka | kafka-clients | 2.5.0 | (必需)Kafka客户端库。 包含内置的串行器/解串器。 |
| org.apache.kafka | kafka-streams-scala | 2.5.0 | (可选)Kafka Streams DSL for Scala库用于编写Scala Kafka Streams应用程序。 当不使用SBT时,您需要在工件ID的后缀中加上您的应用程序正在使用的正确版本的Scala(_2.12,_2.13) |
pom.xml示例:
<dependency>
<groupid>org.apache.kafka</groupid>
<artifactid>kafka-streams</artifactid>
<version>2.5.0</version>
</dependency>
<dependency>
<groupid>org.apache.kafka</groupid>
<artifactid>kafka-clients</artifactid>
<version>2.5.0</version>
</dependency>
<!-- Optionally include Kafka Streams DSL for Scala for Scala 2.12 -->
<dependency>
<groupid>org.apache.kafka</groupid>
<artifactid>kafka-streams-scala_2.12</artifactid>
<version>2.5.0</version>
</dependency>
在您的应用程序中创建Kafka流示例:
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.kstream.StreamsBuilder;
import org.apache.kafka.streams.processor.Topology;
StreamsBuilder builder = ...; // when using the DSL
Topology topology = builder.build();
//
// OR
//
Topology topology = ...; // when using the Processor API
Properties props = ...;
KafkaStreams streams = new KafkaStreams(topology, props);
此时,内部结构已初始化,但处理尚未开始。 您必须通过调用KafkaStreams#start()方法显式启动Kafka Streams线程:
streams.start();
捕获异常:
streams.setUncaughtExceptionHandler((Thread thread, Throwable throwable) -> {
// here you should examine the throwable/exception and perform an appropriate action!
});
要停止应用程序实例,请调用KafkaStreams#close()方法:
streams.close();
为了允许您的应用程序正常响应SIGTERM关机,建议您添加一个关机钩子并调用KafkaStreams#close。
这是Java 8+中的关闭挂钩示例:
Runtime.getRuntime().addShutdownHook(new Thread(streams::close));
停止应用程序后,Kafka会将应用程序迁移到所有可用的其余实例。
Configuring a Streams Application
在使用Kafka之前必须对Kafka Stream进行配置。
1.创建一个java.util.Properties实例
2.使用参数进行配置,如下
import java.util.Properties;
import org.apache.kafka.streams.StreamsConfig;
Properties settings = new Properties();
// Set a few key parameters
settings.put(StreamsConfig.APPLICATION_ID_CONFIG, "my-first-streams-application");
settings.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "kafka-broker1:9092");
// Any further settings
settings.put(... , ...);
配置参数参考:
- 必须的配置参数:
| Parameter Name | Importance | Description | Default Value |
|---|---|---|---|
| application.id | Required | 流处理应用程序的标识符。 在Kafka集群中必须唯一。 | None |
| bootstrap.servers | Required | 用于建立与Kafka集群的初始连接的主机/端口对列表。 | None |
- 可选配置参数
这是可选的Streams javadocs,按重要性级别排序:
High:这些参数可能会对性能产生重大影响。 确定这些参数的值时要小心。
Medium:这些参数可能会对性能产生一些影响。 您的特定环境将确定应该在这些参数上进行多少调整。
Low:这些参数对性能的影响不太普遍或不太明显。
| Parameter Name | Importance | Description | Default Value |
|---|---|---|---|
| application.server | Low | 指向嵌入式host:port对。 | the empty string |
| buffered.records.per.partition | Low | 每个分区要缓冲的最大记录数。 | 1000 |
| cache.max.bytes.buffering | Medium | 用于所有线程的记录缓存的最大内存字节数。 | 10485760 bytes |
| client.id | Medium | 发出请求时传递给服务器的ID字符串。 | the empty string |
| commit.interval.ms | Low | 保存任务为止的频率。 | 30000 milliseconds |
| default.deserialization.exception.handler | Medium | 实现DeserializationExceptionHandler接口异常处理类。 | LogAndContinueExceptionHandler |
| default.production.exception.handler | Medium | 实现ProductionExceptionHandler接口异常处理类。 | DefaultProductionExceptionHandler |
| key.serde | Medium | 记录键的默认序列化器/反序列化器实现了Serde接口。 | Serdes.ByteArray().getClass().getName() |
| metric.reporters | Low | 用作指标报告者的类列表。 | the empty list |
| metrics.num.samples | Low | 维护以计算标本的样本数。 | 2 |
| metrics.recording.level | Low | 指标的最高记录级别。 | INFO |
| metrics.sample.window.ms | Low | 计算指标样本的时间窗口。 | 30000 milliseconds |
| num.standby.replicas | Medium | 每个任务的备用副本数。 | 0 |
| num.stream.threads | Medium | 执行流处理的线程数。 | 1 |
| partition.grouper | Low | 实现PartitionGrouper接口的Partition grouper类。 |
See Partition Grouper |
| processing.guarantee | Low | 处理方式。 | See Processing Guarantee |
| poll.ms | Low | 阻止等待输入时间。 | 100 milliseconds |
| replication.factor | High | 应用程序创建的changelog主题和重新分区主题的复制因子。 | 1 |
| retries | Medium | 返回可重试错误的代理请求的重试次数。 | 0 |
| retry.backoff.ms | Medium | 重试请求之前的时间。 | 100 |
| state.cleanup.delay.ms | Low | 分区迁移后,在删除状态之前等待的时间。 | 600000 milliseconds |
| state.dir | High | 状态存储的目录位置。 | /tmp/kafka-streams |
| timestamp.extractor | Medium | 实现TimestampExtractor接口的时间戳提取器类。 |
See Timestamp Extractor |
| upgrade.from | Medium | 滚动升级过程中要升级的版本。 | See Upgrade From |
| value.serde | Medium | 记录值的默认序列化器/反序列化器实现了Serde接口。 |
Serdes.ByteArray().getClass().getName() |
| windowstore.changelog .additional.retention.ms |
Low | 添加到Windows的maintainMs,以确保不会过早从日志中删除数据。 | 86400000 milliseconds = 1 day |
- 默认值
| 参数名称 | 参数值 | 说明 |
|---|---|---|
| auto.offset.reset | earliest | 当有已提交的offset时,从已提交的offset开始消费。没有时,从头开始消费。 |
| auto.offset.reset | latest | 当有已提交的offset时,从已提交的offset开始消费。没有时,从最新产生的数据开始消费。 |
| auto.offset.reset | none | 当有已提交的offset时,从已提交的offset开始消费。没有时,则抛出异常。 |
| enable.auto.commit | false | |
| linger.ms | 100 | |
| max.poll.interval.ms | Integer.MAX_VALUE | |
| max.poll.records | 1000 | |
| rocksdb.config.setter |
- 推荐弹性配置参数
| Parameter Name | Corresponding Client | Default value | Consider setting to |
|---|---|---|---|
| acks | Producer | acks=1 |
acks=all |
| replication.factor | Streams | 1 |
3 |
| min.insync.replicas | Broker | 1 |
2 |
Streams DSL
KStream
含义是追加一个数据。
KTable
含义是更新一个数据。
GlobalKTable
和KTable的区别是,GlobalKTable会把进入的每个主题写入所有分区,而KTable只会选择其中一个进行写入。
从Kafka获取源
Reading from Kafka Description Stream input topic->KStream 从topic构建流。举例: builder.stream("input-topic", Consumed.with(Serdes.String(),Serdes.Long()));Table Input topic->KTable 从topic构建table。 Global Table Input topic->GlobalKTable 从topic构建global table。 builder.globalTable( "word-counts-input-topic", Materialized.<String, Long, KeyValueStore<Bytes, byte[]>>as( "word-counts-global-store") .withKeySerde(Serdes.String()) .withValueSerde(Serdes.Long()) );无状态的转换
无状态转换就是不需要状态进行处理。比如随时处理当前的数据,形象比喻无脑族。
转换会导致分区的:
FlatMap
GroupBy
Map
SelectKey
转换不会导致分区的:
Branch
Filter
Inverse Filter
flatMapValues
Foreach
GroupByKey
Cogroup
mapValues
Merge
Peek
Print
有状态转换
需要根据之前和现在的数据统一汇总,比如计算wordcount。可以必须为有脑族。
来个处理流程图:
聚合(Aggregating)
Aggregate
Aggregate (windowed)
Count
Count (windowed)
Reduce
Reduce (windowed)
所有的聚合都会忽略空值。然后使用累加器进行累加。
链接(Joining)
受支持情况
Join operands Type (INNER) JOIN LEFT JOIN OUTER JOIN KStream-to-KStream Windowed Supported Supported Supported KTable-to-KTable Non-windowed Supported Supported Supported KTable-to-KTable Foreign-Key Join Non-windowed Supported Supported Not Supported KStream-to-KTable Non-windowed Supported Supported Not Supported KStream-to-GlobalKTable Non-windowed Supported Supported Not Supported KTable-to-GlobalKTable N/A Not Supported Not Supported Not Supported KStream-KStream Join
KStream->KStream始终是窗口链接。空的值不进行链接。
数据必须是共分区的,双方的数据也必须是共分区的。
Inner Join (windowed)
Left Join (windowed)
Outer Join (windowed)
KTable-KTable Equi-Join
KTable->KTable始终是非窗口链接。
数据必须是共分区的,双方的数据也必须是共分区的。
Inner Join
Left Join
Outer Join
KTable-KTable Foreign-Key Join
非窗口链接。
Inner Join
Left Join
Outer Join
KStream-KTable Join
非窗口链接。
KStream和KTable结合最终产生KStream。
KStream-GlobalKTable Join
非窗口链接。
不需要数据共享分区。
Windowing
窗口可以控制相同的键进行分组,并且对键进行有状态跟踪。
DSL支持以下类型窗口:
Window name Behavior Short description Tumbling time window Time-based 固定大小,不重叠,无间隙的窗口 Hopping time window Time-based 固定大小的重叠窗口 Sliding time window Time-based 固定大小的重叠窗口,可处理记录时间戳之间的差异 Session window Session-based 动态大小,无重叠 Tumbling time windows(翻滚窗口)
描述图如下:

-
大小为5分钟,前进间隔为1分钟的跳跃窗口展示如下:

Sliding time windows
滑动窗口仅用于链接。
Session Windows
会话窗口通常具有不同的开始时间和结束时间。


Processor API
Processor API使开发人员可以定义和连接自定义处理器,并与状态存储进行交互。
Data Types and Serialization(数据类型和序列化)
Testing a Streams Application(测试流应用程序)
Interactive Queries(交互式查询)
Memory Management(内存管理)
Running Streams Applications(运行流应用程序)
Managing Streams Application Topics(管理Streams应用程序主题)
Streams Security(流安全性)
Application Reset Tool(应用程序重置工具)
入门大数据---Kafka的搭建与应用的更多相关文章
- 入门大数据---基于Zookeeper搭建Kafka高可用集群
一.Zookeeper集群搭建 为保证集群高可用,Zookeeper 集群的节点数最好是奇数,最少有三个节点,所以这里搭建一个三个节点的集群. 1.1 下载 & 解压 下载对应版本 Zooke ...
- 入门大数据---Kafka生产者详解
一.生产者发送消息的过程 首先介绍一下 Kafka 生产者发送消息的过程: Kafka 会将发送消息包装为 ProducerRecord 对象, ProducerRecord 对象包含了目标主题和要发 ...
- 入门大数据---Kafka消费者详解
一.消费者和消费者群组 在 Kafka 中,消费者通常是消费者群组的一部分,多个消费者群组共同读取同一个主题时,彼此之间互不影响.Kafka 之所以要引入消费者群组这个概念是因为 Kafka 消费者经 ...
- 入门大数据---Kafka深入理解分区副本机制
一.Kafka集群 Kafka 使用 Zookeeper 来维护集群成员 (brokers) 的信息.每个 broker 都有一个唯一标识 broker.id,用于标识自己在集群中的身份,可以在配置文 ...
- 入门大数据---通过Yarn搭建MapReduce和应用实例
上一篇中我们了解了MapReduce和Yarn的基本概念,接下来带领大家搭建下Mapreduce-HA的框架. 结构图如下: 开始搭建: 一.配置环境 注:可以现在一台计算机上进行配置,然后分发给其它 ...
- 入门大数据---Hive的搭建
本博客主要介绍Hive和MySql的搭建: 学习视频一天就讲完了,我看完了自己搭建MySql遇到了一堆坑,然后花了快两天才解决完,终于把MySql搭建好了.然后又去搭建Hive,又遇到了很多坑,就这 ...
- 入门大数据---Kafka简介
一.简介 ApacheKafka 是一个分布式的流处理平台.它具有以下特点: 支持消息的发布和订阅,类似于 RabbtMQ.ActiveMQ 等消息队列: 支持数据实时处理: 能保证消息的可靠性投递: ...
- 入门大数据---基于Zookeeper搭建Spark高可用集群
一.集群规划 这里搭建一个 3 节点的 Spark 集群,其中三台主机上均部署 Worker 服务.同时为了保证高可用,除了在 hadoop001 上部署主 Master 服务外,还在 hadoop0 ...
- 入门大数据---Flume的搭建
一.下载并解压到指定目录 崇尚授人以渔的思想,我说给大家怎么下载就行了,就不直接放连接了,大家可以直接输入官网地址 http://flume.apache.org ,一般在官网的上方或者左边都会有Do ...
随机推荐
- 学习scrapy框架爬小说
一.背景:近期学习python爬虫技术,感觉挺有趣.由于手动自制爬虫感觉效率低,了解到爬虫界有先进的工具可用,尝试学学scrapy爬虫框架的使用. 二.环境:centos7,python3.7,scr ...
- 核心记账业务可用jdk7的PriorityBlockingQueue优先阻塞队列结合乐观锁实现
-- 1.优先级阻塞队列 当前核心记账业务是悲观锁实现,但考虑到高并发和死锁的问题,可以用PriorityBlockingQueue优先阻塞队列结合乐观锁实现,对于并发时出现锁无法update时可以重 ...
- Java实现最优二叉查找树
1 问题描述 在了解最优二叉查找树之前,我们必须先了解何为二叉查找树? 引用自百度百科一段讲解: 二叉排序树(Binary Sort Tree)又称二叉查找树(Binary Search Tree), ...
- java实现第六届蓝桥杯熊怪吃核桃
熊怪吃核桃 题目描述 森林里有一只熊怪,很爱吃核桃.不过它有个习惯,每次都把找到的核桃分成相等的两份,吃掉一份,留一份.如果不能等分,熊怪就会扔掉一个核桃再分.第二天再继续这个过程,直到最后剩一个核桃 ...
- Mac上查看当前安卓手机上打开的app的包名和主程序入口
1.连接上手机,数据线链接或者无线连接随便 2.打开你需要查看的app 3.打开终端,输入命令: adb shell dumpsys window w |grep \/ |grep name=
- 制作seata docker镜像
seata是阿里巴巴的一款开源的分布式事务框架,官方已经支持docker了,但是因为业务的需要,需要自己定制. 制作docker镜像 官方的Dockerfile.下载seata-server-1.1. ...
- 168.Excel列表名称
Document 2020-03-16 Excel表列名称 1 -> A. 2 -> B: 26 -> Z 27 -> AA 28 -> AB 示例: 输入: s = & ...
- 别再写一摞if-else了!再写开除!两种设计模式带你消灭它!
代码洁癖狂们!看到一个类中有几十个if-else是不是很抓狂? 设计模式学了用不上吗?面试的时候问你,你只能回答最简单的单例模式,问你有没有用过反射之类的高级特性,回答也是否吗? 这次就让设计模式(模 ...
- PowerApps Component Framework PCF 部署
PowerApps PCF 可以满足复杂的功能, 我们可以使用PCF来创建复杂的PowerApps. 这里附上微软的package code componet 教程(https://docs.micr ...
- sublime Text3 实现2:1:1三分屏效果
小trick, 水一篇博客 先上效果图 由于写题啥的时候需要重定向输入输出改数据对拍, 设置成这样的效果就非常直观的看数据 直接切题, 首选项--快捷键--default里搜索alt+shift+1( ...