flink笔记(三) flink架构及运行方式
架构图
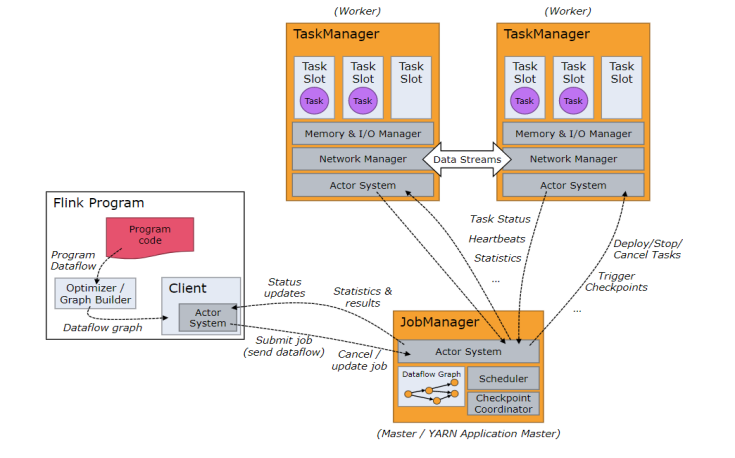
Job Managers, Task Managers, Clients
- JobManager(Master)
- 用于协调分布式执行。它们用来调度task,协调检查点,协调失败时恢复等。
- Flink运行时至少存在一个JobManager。
- 一个高可用的运行模式会存在多个JobManager,它们其中有一个是leader,而其他的都是standby。
- TaskManager(Worker)
- 用于执行一个dataflow的task(或者特殊的subtask)、数据缓冲和data stream的交换。
- Flink运行时至少会存在一个TaskManager。
- TaskManager连接到JobManager,告知自身的可用性进而获得任务分配。
- 客户端不是运行时和程序执行的一部分。但它用于准备并发送dataflow给master,然后户端断开连接或者维持连接以等待接收计算结果。
- JobManager和TaskManager可以以如下方式中的任意一种启动:
- Standalone cluster
- Yarn
- Mesos
- Container(容器, 如 由K8S管理的Docker集群)
Standalone 模式
- 流程如上所示
- 任务提交命令:
- bin/flink run -c mainclass jar_path
- webui 提交(傻瓜式)
On Yarn 模式
两种运行模式
Yarn-session 模式
- 该模式是预先在yarn上面划分一部分资源给flink集群用,flink提交的所有任务,共用这些资源。
- 示意图
- 任务提交
- 先启动一个yarn-session,并指明分配的资源。
- 命令:
- ./yarn-session.sh -n 3 -jm 1024 -tm 1024 /opt/sxt/flinkTest.jar
- -n 容器个数
- -jm jobmanager 进程内存大小
- -tm 指明每个 taskmanager 的进程内存大小
- 启动yarn-session后,就可以提交任务了
- . /flink run -m 节点:端口 jar 文件目录
- 停止yarn上的 flink 集群
- 先找到 application_id
- 然后执行命令:
- yarn application -kill application_id
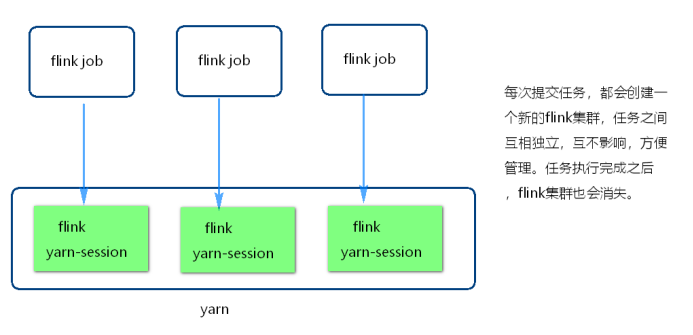
Single job 模式
该模式是每次提交任务,都会创建一个新的flink集群
任务之间互相独立,互不影响,方便管理
任务执行完成之后,flink集群也会消失
示图:
任务提交命令:
- ./flink rum -m yarn-cluster -yn 并行度 jar文件路径
- -m:
- 后面跟的是yarn-cluster,不需要指明地址。
- 这是由于Single job模式是每次提交任务会新建flink集群,所以它的jobmanager是不固定的。
- -yn:
- 指明taskmanager个数。
- 其余参数可使用:./flink -h 来查看
- -m:
- ./flink rum -m yarn-cluster -yn 并行度 jar文件路径
运行原理
flink on yarn 内部实现图
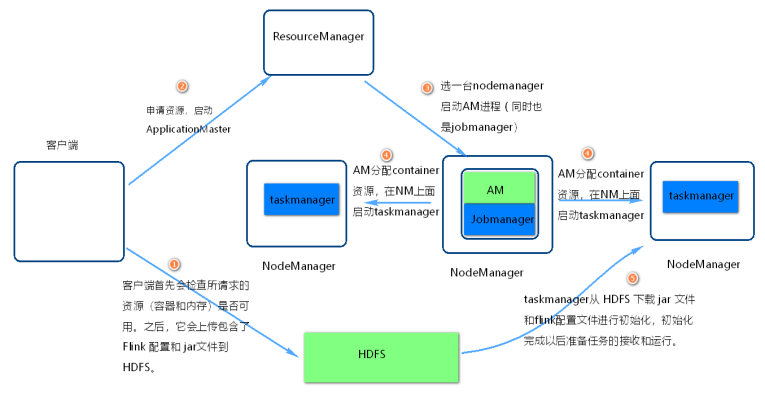
步骤1
- 当启动一个新的 Flink YARN Client会话,客户端首先会检查所请求的资源(容器和内存)是否可用。
- 之后,它会上传包含了 Flink 配置文件和 jar包到 HDFS.
步骤2
- 客户端的请求一个container资源去启动 ApplicationMaster 进程
步骤3
- ResourceManager选一台NodeManager机器启动AM。
- 注意点1:
- 因为客户端已经将配置文件和jar包作为容器的资源注册了,所以 NodeManager 会负责准备容器做一些初始化工作(例如,下载文件)。
- 一旦这些完成了,ApplicationMaster (AM) 就启动了。
- 注意点2:
- JobManager 和 AM 运行在同一个容器中。
- 一旦它们成功地启动了,AM 知道 JobManager 的地址(它自己)。
- 它会为 TaskManager 生成一个新的 Flink 配置文件(这样它们才能连上 JobManager)。
- 该文件也同样会上传到 HDFS。另外,AM 容器同时提供了 Flink 的 Web 界面服务。
步骤4
- AM 开始为 Flink 的 TaskManager 分配容器(container),在对应的nodemanager上面启动taskmanager
步骤5
- 初始化工作,从 HDFS 下载 jar 文件和修改过的配置文件。
- 一旦这些步骤完成了,Flink 就安装完成并准备接受任务了。
flink笔记(三) flink架构及运行方式的更多相关文章
- Flink学习笔记-新一代Flink计算引擎
说明:本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKh ...
- Flink学习笔记:Flink Runtime
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- Flink(三)Flink开发IDEA环境搭建与测试
一.IDEA开发环境 1.pom文件设置 <properties> <maven.compiler.source>1.8</maven.compiler.source&g ...
- 揭秘 Flink 1.9 新架构,Blink Planner 你会用了吗?
本文为 Apache Flink 新版本重大功能特性解读之 Flink SQL 系列文章的开篇,Flink SQL 系列文章由其核心贡献者们分享,涵盖基础知识.实践.调优.内部实现等各个方面,带你由浅 ...
- 开篇 | 揭秘 Flink 1.9 新架构,Blink Planner 你会用了吗?
本文为 Apache Flink 新版本重大功能特性解读之 Flink SQL 系列文章的开篇,Flink SQL 系列文章由其核心贡献者们分享,涵盖基础知识.实践.调优.内部实现等各个方面,带你由浅 ...
- Flink 笔记(一)
简介 Flink是一个低延迟.高吞吐.统一的大数据计算引擎, Flink的计算平台可以实现毫秒级的延迟情况下,每秒钟处理上亿次的消息或者事件. 同时Flink提供了一个Exactly-once的一致性 ...
- 《从0到1学习Flink》—— Apache Flink 介绍
前言 Flink 是一种流式计算框架,为什么我会接触到 Flink 呢?因为我目前在负责的是监控平台的告警部分,负责采集到的监控数据会直接往 kafka 里塞,然后告警这边需要从 kafka topi ...
- 8、Flink Table API & Flink Sql API
一.概述 上图是flink的分层模型,Table API 和 SQL 处于最顶端,是 Flink 提供的高级 API 操作.Flink SQL 是 Flink 实时计算为简化计算模型,降低用户使用实时 ...
- Twitter 新一代流处理利器——Heron 论文笔记之Heron架构
Twitter 新一代流处理利器--Heron 论文笔记之Heron架构 标签(空格分隔): Streaming-process realtime-process Heron Architecture ...
随机推荐
- c-指针的理解
c-指针的理解 最近在学习MFC,其中的代码有点看的不是很深刻,究其原因还是对c语言中的指针理解的不是很好,下面详细的给大家介绍一下指针,如有不当之处,欢迎各位读者指正. 一.指针的概念 C语言里,变 ...
- primecoin在ubuntu16.04上部署服务:
primecoin在ubuntu16.04上部署服务: 一.下载Tomcat,Jdk,primecoin(公司内部文件) 注意Tomcat版本需要高于Jdk的,不然会报错. 二.把它们都解压到你要的安 ...
- java程序中的经常出现的的异常处理课后总结
一.JDK中常见的异常情况 1.常见异常总结图 2.java中异常分类 Throwable类有两个直接子类: (1)Exception:出现的问题是可以被捕获的 (2)Error:系统错误,通常由JV ...
- Unity3d fbx纹理不显示 原因
Unity3d 导入fbx文件后纹理不显示(3ds Max中显示正常) 原因: 1.纹理图片没有导入fbx同一文件夹中 2.纹理图片没有在fbx文件之前导入(现导入纹理图片,再导入fbx文件)
- Redis集合类型
集合是元素无序且唯一的列表 命令 增加元素 SADD key member [member ...] > SADD letters a (integer) 1 > SADD letters ...
- 有关WordPress的Rss导入指南
我是用cublog转过来.有一个软件博客备份软件(blog_backup)可以备份那个的blog.我用他备份后导出成rss2的文件.但我导入了很多次不成功.后来发现,原来blog_backup导出的格 ...
- Android程序的入口点是什么,不是Main()吗
很多初入Android开发的网页可能不知道Android程序的入口点是什么,不是main()吗,当然我相信回复onCreate的在字面上不算错,但是你们想的是Activity中的onCreate 方法 ...
- 三 进制、精度,Java的类型转换
进制的表示: 0b010 : 二进制表示形式:前面+0n 0100 : 八进制表示形式: 前面+0 0x001 : 16进制表示形式:前面+0x 计算机以补码的方式进行运算 进制的转换: 10进制 ...
- 区块链 - 哈希(Hash)
章节 区块链 – 介绍 区块链 – 发展历史 区块链 – 比特币 区块链 – 应用发展阶段 区块链 – 非对称加密 区块链 – 哈希(Hash) 区块链 – 挖矿 区块链 – 链接区块 区块链 – 工 ...
- iOS大V博客
王巍的博客:王巍目前在日本横滨任职于LINE.工作内容主要进行Unity3D开发,8小时之外经常进行iOS/Mac开发.他的陈列柜中已有多款应用,其中番茄工作法工具非常棒. http://onevca ...