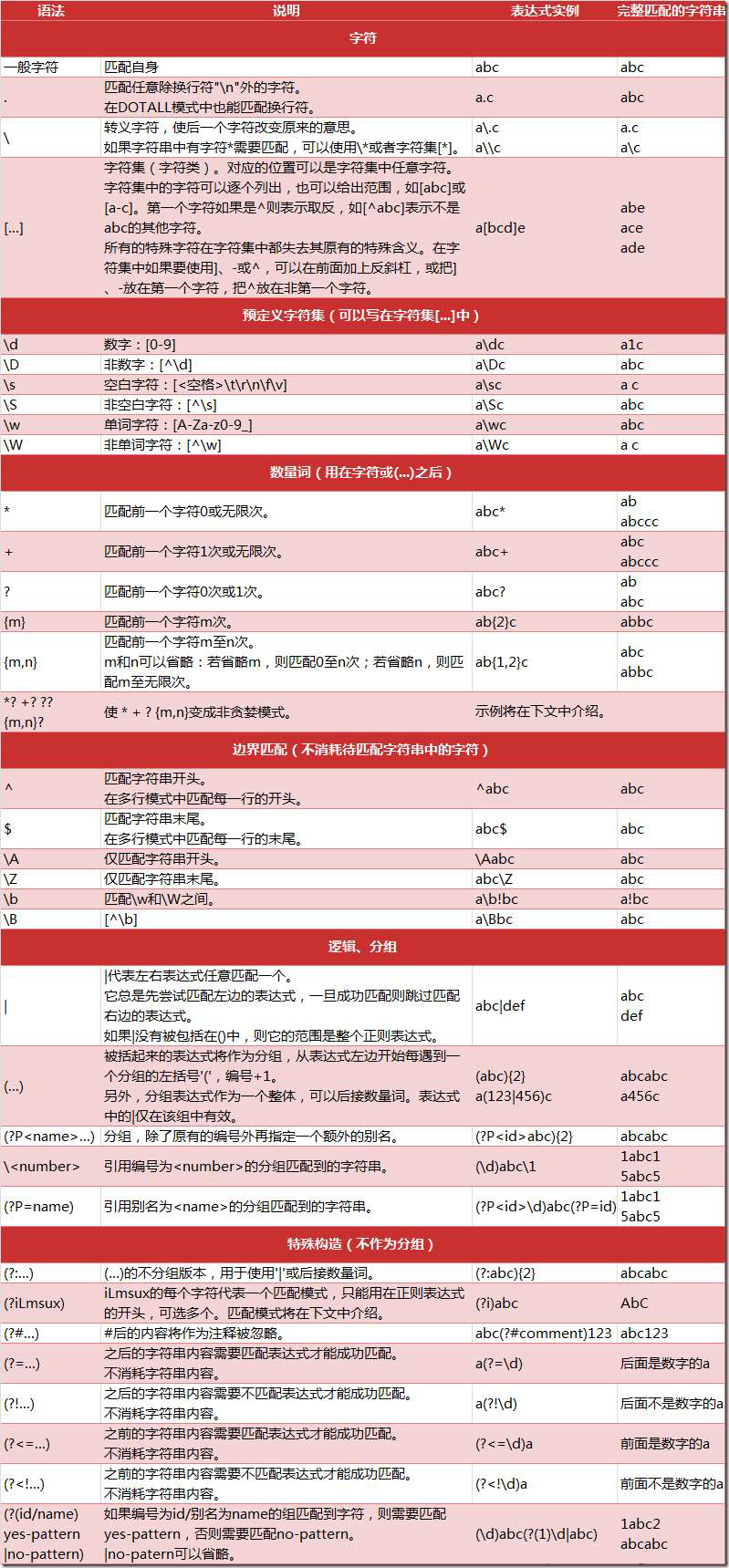
regex(python)
正则表达式
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2018/7/26 16:39
# @Author : jackendoff
# @Site :
# @File : 正则学习.py
# @Software: PyCharm # re模块的使用过程
import re
# '''
# re模块的使用过程
# re.match(pattern, string, flags=0)
# 从头匹配一个符合规则的字符串,从起始位置开始匹配,匹配成功返回一个对象,未匹配成功返回None
# · pattern: 正则模型
# · string: 要匹配的字符
# · flags: 匹配模式
# 这个方法并不是完全匹配,当pattern结束时若string还有剩余字符,仍视为成功,想要完全匹配,可以在表达式末尾加上边界匹配符‘$’
# '''
# result = re.match('^\d{3}$', '124')
# print(result.group()) # 返回被re匹配的字符串124
# print(result.start()) # 返回匹配开始的位置0
# print(result.end()) # 返回匹配结束的位置3
# print(result.span()) # 返回一个元组包含匹配(开始,结束)的位置(0, 3) '''
re.search函数会在字符串内查找模式匹配,只要找到第一个匹配然后返回,如果字符串没有匹配,则返回None
格式:re.search(pattern, string, flags=0)
match()和search()的区别:
match()函数只检测re是不是在string的开始位置匹配,search()会扫描
整个string查找匹配;
也就是说match()只有在0位置匹配成功的化才有返回,如果不是开始位置匹配成功的话,match()就返回none。 '''
# import re
# ret = re.search(r'\d+', '阅读次数为9999')
# print(ret.group()) # 运行结果9999
#
# print(re.match('super', 'superstition').span()) # 结果(0, 5)
# print(re.match('super', 'insuperstition')) # 结果None
# print(re.search('super', 'superstition').span()) # 结果(0, 5)
# print(re.search('super', 'insuperstition').span()) # 结果(2, 7) '''
re.findall遍历匹配,可以获取字符串中所有匹配字符串,返回一个列表
'''
# import re
#
# ret = re.findall(r'\d+', '阅读次数:9999次,转发次数:887次,评论次数:3次')
# print(ret) # 运行结果['9999', '887', '3'] '''
sub将匹配到的数据进行替换
使用re替换string中每一个匹配的字符串后返回替换后的字符串
格式:re.sub(pattern, repl, string,count)
''' # import re
#
# ret = re.sub(r'\d+', '10000', '阅读次数:9999次, 转发次数:883次, 评论次数:3次')
# print(ret) # 运行结果 阅读次数:10000次, 转发次数:10000次, 评论次数:10000次 import re
# def add(temp):
# strNum = temp.group()
# print(strNum) # 运行结果997
# num = int(strNum) + 1
# return str(num) # 返回一个字符串 # ret = re.sub(r'\d+', add, 'python = 997') # 可以分解为result = re.search(r'\d+', 'python=997') --》add(result)
# print(ret) # 运行结果python = 998
#
# ret = re.sub(r'\d+', add, 'python = 99')
# print(ret) # 运行结果python = 100 '''
import re
def add(temp):
strNum = temp.group()
print(strNum) # 运行结果997
num = int(strNum) + 1
return str(num)
result = re.search(r'\d+', 'python=997')
print(add(result))
''' '''
split根据匹配进行切割字符串,并返回一个列表
按照能够匹配的字符串string分割都返回列表。
可以使用re.split来分割字符串
格式:re.split(pattern, string[,maxspit]) ''' import re ret = re.split(r":| ", 'info:xiaozhang 33 shandong')
print(ret) # 运行结果 ['info', 'xiaozhang', '33', 'shandong'] '''
pyhton里数量词默认是贪婪的,总是尽可能多地匹配字符;
非贪婪则相反,总是尝试匹配尽可能少的字符
在'*','+','?','{m, n}后面加上?,使贪婪变为非贪婪。'
'''
量词:
* 重复0次或更多次
+ 重复一次或更多次
?重复0次或一次
{n} 重复n次
{n,} 重复n次或更多次
{n,m} 重复n到m次
贪心匹配(默认)
惰性匹配: 量词 + ''?''
.*?x 前面取任意长度字符直到取到x
字符:
. 匹配除换行以外的任意字符
\w 匹配字母或数字或下划线
\d 匹配数字(digit)
\s 匹配任意空白符(space)
\n 匹配一个换行符
\t 匹配一个制表符(TAB)
\b 匹配一个单词的结尾
^ 匹配字符串的开始
$ 匹配字符串的结尾
\W 匹配非字母或数字或下划线
\D 匹配非数字
\S 匹配非空白符
a|b 匹配字符a或者字符b
( ) 匹配括号内的表达式,也表示一个组(search)
[...] 匹配字符组中的字符
[^...] 匹配除字符组以外的所有字符
pyhton re模块
python正则
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2018/7/8 9:27
# @Author : jackendoff
# @Site :
# @File : text.py
# @Software: PyCharm import re # find_str = re.findall('a', 'jai jack') # 匹配所有,并显示所有
# print(find_str)
#
# search_str = re.search('a', 'jia jack') # 匹配找到的第一个,并显示
# print(search_str)
# search_gp = search_str.group()
# print(search_gp)
#
# match_str = re.match('a', 'a bc') # 匹配第一个
# print(match_str)
# match_gp = match_str.group()
# print(match_gp)
#
# find_str = re.findall('[a-z]\d', 'ji58a991') # 匹配a-z和数字
# print(find_str)
# find_str = re.findall('([a-z])\d', 'ji58a991') # 匹配a-z和数字
# print(find_str)
# find_str = re.findall('(?:[a-z])\d', 'ji58a991') # ()代表‘组’在findall里优先显示 '?:'代表‘取消优先’
# print(find_str)
#
# search_str = re.search('([a-z])(\d)', 'jia123nfdj8684') # 匹配a-z和数字 分组
# search_gpp = search_str.group() # 显示匹配的数字和字母
# print(search_gpp)
# search_gp = search_str.group(1) # 显示第一个组
# print(search_gp)
# search_gp = search_str.group(2) # 显示第二个组
# print(search_gp) # sp_str = re.split('\d', 'jia4jfa5f78a') # 依据数字分割
# print(sp_str)
# split_str = re.split('[a1]', 'jiafd54f1k') # 先根据a分割,仔根据1分割
# print(split_str)
#
# sub_str = re.sub('[\d]', '0', 'jia123fd6', 2) # 将数字替换成0,2表示只替换两个
# print(sub_str)
# sub_str = re.subn('[\d]', '0', 'jia123fd6') # 将数字替换成0,返回一个元组(替换的结果,替换了多少次)
# print(sub_str) # obj = re.compile('\d{3}') # 将正则表达式编译成一个正则对象(当表达式特别复杂的时候此对象可以多次使用)匹配三个数字
# obj_str = obj.search('jia123kill') # 直接使用对象调用search进行匹配
# o_str = obj_str.group()
# print(o_str) # ret = re.finditer('\d', 'jia5fd55fs6f5') # finditer返回一个存放匹配结果的迭代器(节省内存)
# print(ret)
# # for i in ret:
# print(i.group())
正则案例,windows命令行 超多
1. 初步使用
In [1]: import re
In [11]: re.match(r"abc","abcde").group()
In [12]: re.match(r"bc","abcde").group()
In [14]: re.search(r"bc","abcde").group() 2. 匹配单个字符
-----------------------.匹配任意字符(除\n)-------------------------------
In [5]: re.match(r".","A").group()
In [6]: re.match(r".","a").group()
In [7]: re.match(r".",".").group()
In [8]: re.match(r".","\n").group()
In [9]: re.match(r".","x").group()
In [10]: re.match(r"A.C","ABC").group() -------------------------[]匹配集合中任何一个字符---------------------------
In [11]: re.match(r"[aA]BC","ABC").group()
In [12]: re.match(r"[aA]BC","aBC").group()
In [13]: re.match(r"[aA]BC","xBC").group()
In [14]: re.match(r"[0123456789]BC","1BC").group()
In [15]: re.match(r"[0123456789]BC","9BC").group()
-------------------------[-]表示范围-----------------------------
In [16]: re.match(r"[0-9]BC","9BC").group()
In [17]: re.match(r"[0-9]BC","2BC").group()
In [18]: re.match(r"[0-9a-zA-Z]BC","ABC").group()
In [19]: re.match(r"[0-9a-zA-Z]BC","aBC").group()
In [21]: re.match(r"[0-9a-zA-Z]BC","&BC").group()
In [22]: re.match(r"[0-35-9]BC","1BC").group()
In [24]: re.match(r"[0-35-9]BC","4BC").group()
-------------------------[^]对匹配范围取反-----------------------------
In [25]: re.match(r"[^4]BC","4BC").group()
In [26]: re.match(r"[^4]BC","1BC").group()
In [27]: re.match(r"[^4]BC","9BC").group()
In [28]: re.match(r"[^4a-z]BC","aBC").group()
In [29]: re.match(r"[^4a-z]BC","zBC").group()
In [30]: re.match(r"[^4a-z]BC","ZBC").group() -------------------------\d匹配数字字符 \D匹配非数字---------------------
In [31]: re.match(r"[0-9]BC","4BC").group()
In [32]: re.match(r"\dBC","4BC").group()
In [33]: re.match(r"\dBC","2BC").group() In [34]: re.match(r"\DBC","2BC").group()
In [35]: re.match(r"\DBC","aBC").group()
In [36]: re.match(r"\DBC","xBC").group()
--------------------------\w匹配单词字符 \w匹配非单词------------------------
In [38]: re.match(r"\wBC", "ABC").group()
In [39]: re.match(r"\wBC", "aBC").group()
In [40]: re.match(r"\wBC", "1BC").group()
In [41]: re.match(r"\wBC", "_BC").group()
In [42]: re.match(r"[\da-zA-Z_]BC", "1BC").group()
In [43]: re.match(r"[\da-zA-Z_]BC", "ABC").group()
In [44]: re.match(r"[\da-zA-Z_]BC", "aBC").group()
In [45]: re.match(r"[\da-zA-Z_]BC", "_BC").group() In [46]: re.match(r"\WBC", "_BC").group()
In [47]: re.match(r"\WBC", "$BC").group()
In [48]: re.match(r"\WBC", " BC").group() 3. 匹配多个字符
In [50]: re.match(r"嫦娥\w号", "嫦娥一号升空了", re.A).group()
In [51]: re.match(r"嫦娥\d号", "嫦娥1号升空了", re.A).group()
In [52]: re.match(r"嫦娥\d\d号", "嫦娥11号升空了", re.A).group()
In [53]: re.match(r"嫦娥\d\d\d号", "嫦娥111号升空了", re.A).group()
In [54]: re.match(r"嫦娥\d\d\d\d\d\d号", "嫦娥111111号升空了", re.A).group() In [55]: re.match(r"嫦娥\d{6}号", "嫦娥111111号升空了", re.A).group()
In [56]: re.match(r"嫦娥\d{6}号", "嫦娥11号升空了", re.A).group()
In [57]: re.match(r"嫦娥\d{2,6}号", "嫦娥11号升空了", re.A).group()
In [58]: re.match(r"嫦娥\d{2,6}号", "嫦娥11111号升空了", re.A).group() In [59]: re.match(r"嫦娥\d{1,}号", "嫦娥11111号升空了").group()
In [60]: re.match(r"嫦娥\d{1,}号", "嫦娥11111111111号升空了").group()
In [61]: re.match(r"嫦娥\d+号", "嫦娥11111111111号升空了").group()
In [63]: re.match(r"嫦娥\d+号", "嫦娥号升空了").group() In [64]: re.match(r"嫦娥\d{0,}号", "嫦娥号升空了").group()
In [65]: re.match(r"嫦娥\d{0,}号", "嫦娥1111号升空了").group()
In [66]: re.match(r"嫦娥\d*号", "嫦娥1111号升空了").group()
In [67]: re.match(r"嫦娥\d*号", "嫦娥号升空了").group() In [81]: re.match(r"嫦娥\d{0,1}号", "嫦娥号升空了").group()
In [82]: re.match(r"嫦娥\d{0,1}号", "嫦娥1号升空了").group()
In [83]: re.match(r"嫦娥\d?号", "嫦娥1号升空了").group()
In [84]: re.match(r"嫦娥\d?号", "嫦娥11号升空了").group() 4. 匹配开始和结束位置
.在正则中表示匹配除\n之外的任意字符 如果要再正则中表示.本身的含义 使用\. In [68]: re.match(r"\w@163.com","123456@163.com").group()
In [69]: re.match(r"\w{4,20}@163.com","123456@163.com").group()
In [70]: re.match(r"\w{4,20}@163.com","123456@163Acom").group()
In [71]: re.match(r"\w{4,20}@163\.com","123456@163Acom").group()
In [72]: re.match(r"\w{4,20}@163\.com","123456@163.com").group() In [73]: re.match(r"\w{4,20}@163\.com","123456@163.com.cc").group()
In [74]: re.match(r"\w{4,20}@163\.com",".ccc.123456@163.com").group()
In [75]: re.match(r"\w{4,20}@163\.com","123456@163.com.cc").group()
In [76]: re.match(r"\w{4,20}@163\.com$","123456@163.com.cc").group()
In [77]: re.search(r"\w{4,20}@163\.com$","123456@163.com.cc").group()
In [78]: re.search(r"\w{4,20}@163\.com$","ccc.123456@163.com").group()
In [79]: re.match(r"\w{4,20}@163\.com$","ccc.123456@163.com").group() In [80]: re.search(r"^\w{4,20}@163\.com$","ccc.123456@163.com").group()
In [81]: re.search(r"^\w{4,20}@163\.com$","123456@163.com").group() 5. 分组 ----------------------()将感兴趣的数据放到分组中-------------------------
In [86]: re.match(r"嫦娥\d+号", "嫦娥9号升空了").group()
In [87]: re.match(r"嫦娥(\d+)号", "嫦娥9号升空了").group()
In [88]: re.match(r"嫦娥(\d+)号", "嫦娥9号升空了").group(0)
In [89]: re.match(r"嫦娥(\d+)号", "嫦娥9号升空了").group(1)
In [90]: re.search(r"(^\w{4,20})@163\.com$","123456@163.com").group(1)
In [91]: re.search(r"(^\w{4,20})@(163)\.com$","123456@163.com").group(1)
In [92]: re.search(r"(^\w{4,20})@(163)\.com$","123456@163.com").group(2) ----------------------|匹配左右任何一个正则表达式--------------------------
In [93]: re.search(r"(^\w{4,20})@163\.com$|^\w{4,20}@qq\.com$","123456@163.com").group(1)
In [94]: re.search(r"(^\w{4,20})@163\.com$|^\w{4,20}@qq\.com$","123456@163.com").group(0)
In [95]: re.search(r"(^\w{4,20})@163\.com$|^\w{4,20}@qq\.com$","123456@qq.com").group(0) ---------------------(|)匹配()中任何一个正则表达式并将匹配结果放到分组中-------
In [96]: re.search(r"(^\w{4,20})@(163|qq)\.com$","123456@qq.com").group(0)
In [97]: re.search(r"(^\w{4,20})@(163|qq)\.com$","123456@163.com").group(0)
In [98]: re.search(r"(^\w{4,20})@(163|qq)\.com$","123456@263.com").group(0)
In [99]: re.search(r"(^\w{4,20})@(163|qq|263)\.com$","123456@263.com").group(0)
In [100]: re.search(r"(^\w{4,20})@(163|qq|263|126)\.com$","123456@263.com").group(0)
In [101]: re.search(r"(^\w{4,20})@(163|qq|263|126)\.com$","123456@263.com").group(1)
In [102]: re.search(r"(^\w{4,20})@(163|qq|263|126)\.com$","123456@263.com").group(2) ---------------------引用分组(匿名 只能通过分组号引用)--------------------------------
In [103]: re.match(r"<\w+>.*", "<html>hh</html>").group()
In [104]: re.match(r"<(\w+)>.*", "<html>hh</html>").group()
In [105]: re.match(r"<(\w+)>.*", "<html>hh</html>").group(1)
In [106]: re.match(r"<(\w+)>.*</\1>", "<html>hh</html>").group(1)
In [107]: re.match(r"<(\w+)>.*</\1>", "<html>hh</htm>").group(1)
In [108]: re.match(r"<(\w+)><(\w+)>(.*)</\2></\1>", "<html><h1>www.itcast.cn</h1></html>").group(1)
In [109]: re.match(r"<(\w+)><(\w+)>(.*)</\2></\1>", "<html><h1>www.itcast.cn</h1></html>").group()
In [110]: re.match(r"<(\w+)><(\w+)>(.*)</\2></\1>", "<html><h1>www.itcast.cn</h2></html>").group() In [111]: re.match(r"(\d{3,4})-(\d{6,8})", "010-12345678").group(1)
In [112]: re.match(r"(\d{3,4})-(\d{6,8})", "010-12345678").group(2)
In [113]: re.match(r"((\d{3,4})-(\d{6,8}))", "010-12345678").group(2)
In [114]: re.match(r"((\d{3,4})-(\d{6,8}))", "010-12345678").group(1)
In [115]: re.match(r"((\d{3,4})-(\d{6,8}))", "010-12345678").group(3) ------------------创建有名分组 给分组起名 使用有名分组------------------------
In [116]: re.match(r"((?P<quhao>\d{3,4})-(?P<zuoji>\d{6,8}))", "010-12345678").group(3)
In [118]: re.match(r"(?P<quhao>\d{3,4})-(?P<zuoji>\d{6,8}) (?P=quhao)-(?P=zuoji)", "010-12345678 010-12345678").group() In [119]: re.match(r"(?P<quhao>\d{3,4})-(?P<zuoji>\d{6,8}) (?P=quhao)-(?P=zuoji)", "010-12345678 010-12345678").group(1) In [120]: re.match(r"(?P<quhao>\d{3,4})-(?P<zuoji>\d{6,8}) (?P=quhao)-(?P=zuoji)", "010-12345678 010-12345678").group(2) In [121]: re.match(r"((?P<quhao>\d{3,4})-(?P<zuoji>\d{6,8})) (?P=quhao)-(?P=zuoji)", "010-12345678 010-12345678").group(2) In [122]: re.match(r"((?P<quhao>\d{3,4})-(?P<zuoji>\d{6,8})) (?P=quhao)-(?P=zuoji)", "010-12345678 010-12345678").group(1) In [123]: re.match(r"((?P<quhao>\d{3,4})-(?P<zuoji>\d{6,8})) (?P=quhao)-(?P=zuoji)", "010-12345678 010-12345678").group(2) In [124]: re.match(r"((?P<quhao>\d{3,4})-(?P<zuoji>\d{6,8})) (?P=quhao)-(?P=zuoji)", "010-12345678 010-12345678").group(3) 6. 高级函数
----------------------------------------------------------------------------
In [127]: ret = re.match(r"\d+", "阅读次数为 9999").group()
In [129]: ret = re.search(r"\d+", "阅读次数为 9999").group()
In [131]: re.search(r"\d+", "阅读次数为 9999").group() ---------------------------------------------------------------------------- In [132]: re.findall(r"\d+", "阅读次数为 9999").group() # 不可以用.group()
In [133]: re.findall(r"\d+", "阅读次数为 9999")
In [134]: re.findall(r"\d+", "阅读次数为") # 没匹配到返回空列表 ----------------------------------------------------------------------------
In [135]: re.sub(r"\d+","999", "python=666")
In [136]: re.sub(r"\d+","999", "python=666 cpp=688")
In [137]: re.sub(r"\d+","999", "python=666 cpp=688", 1)
In [138]: re.sub(r"\d+","999", "python=666 cpp=688") In [139]: def add(matchobj):
...: data = matchobj.group()
...: number = int(data) + 1000
...: return str(number) In [140]: re.sub(r"\d+",add, "python=666 cpp=688") In [141]: data = """
...: <div>
...: <p>岗位职责:</p>
...: <p>完成推荐算法、数据统计、接口、后台等服务器端相关工作</p>
...: <p><br></p>
...: <p>必备要求:</p>
...: <p>良好的自我驱动力和职业素养,工作积极主动、结果导向</p>
...: <p> <br></p>
...: <p>技术要求:</p>
...: <p>1、一年以上 Python 开发经验,掌握面向对象分析和设计,了解设计模式</p>
...: <p>2、掌握HTTP协议,熟悉MVC、MVVM等概念以及相关WEB开发框架</p>
...: <p>3、掌握关系数据库开发设计,掌握 SQL,熟练使用 MySQL/PostgreSQL 中的一种<br></p>
...: <p>4、掌握NoSQL、MQ,熟练使用对应技术解决方案</p>
...: <p>5、熟悉 Javascript/CSS/HTML5,JQuery、React、Vue.js</p>
...: <p> <br></p>
...: <p>加分项:</p>
...: <p>大数据,数理统计,机器学习,sklearn,高性能,大并发。</p>
...:
...: </div>""" In [142]: re.sub(r"<\w+>","",data)
In [143]: re.sub(r"<\w+>|\n","",data)
In [144]: re.sub(r"<\w+>|\n|</\w+>","",data)
In [145]: re.sub(r"</?\w+>|\n|","",data)
In [146]: re.sub(r"</?\w+>|\n| ","",data) 7. 贪婪模式和非贪婪模式<>
----------------------------------------------------------------------------
In [147]: re.split(r"\s","123456_abcdef ghjkl\t12312312")
In [148]: re.split(r"\s|_","123456_abcdef ghjkl\t12312312")
In [149]: re.search(r"\d+", "嫦娥199999号升空了")
In [150]: re.search(r"\d+", "嫦娥1999999999号升空了").group()
In [151]: re.search(r"\d+\d+", "1999999999").group()
In [152]: re.search(r"(\d+)(\d+)", "1999999999").group()
In [153]: re.search(r"(\d+)(\d+)", "1999999999").group(1)
In [154]: re.search(r"(\d+)(\d+)", "1999999999").group(2)
In [155]: re.search(r"(\d+?)(\d+)", "1999999999").group(2) In [156]: re.search(r"(\d+?)(\d+)", "1999999999").group(1)
In [157]: url = """<img data-original="https://rpic.douyucdn.cn/appCovers/2016/11/13/1213973_2016111319
...: 17_small.jpg" src="https://rpic.douyucdn.cn/appCovers/2016/11/13/1213973_201611131917_small.j
...: pg" style="display: inline;">
...: """ In [158]: re.search(r"https:.*\.jpg",url).group()
In [159]: re.search(r"https:.*?\.jpg",url).group() 8 r标识原生字符串
----------------------------------------------------------------------------
In [160]: path = "c:\a\b\c"
In [161]: path
Out[161]: 'c:\x07\x08\\c' In [162]: print(path)
c\c
In [163]: path = "c:\\a\\b\\c" In [164]: path
Out[164]: 'c:\\a\\b\\c' In [165]: path = "c:\\a\\b\c"
Out[166]: 'c:\\a\\b\\c' In [167]: re.match("c:\\a",path).group()
In [168]: re.match(r"c:\\a",path).group()
In [169]: re.match("c:\\\\a",path).group()
In [170]: re.match("c:\\\\a\\\\b",path).group()
In [171]: re.match("c:\\\\a\\\\b\\\\c",path).group()
In [172]: re.match(r"c:\\a\\b\\c",path).group()
regex(python)的更多相关文章
- Python 正则表达式(RegEx)
版权所有,未经许可,禁止转载 章节 Python 介绍 Python 开发环境搭建 Python 语法 Python 变量 Python 数值类型 Python 类型转换 Python 字符串(Str ...
- Python re 模块
Python re 模块 TOC 介绍 作用 正则表达式语法 贪婪和非贪婪 普通字符和特殊字符 分组(比较重要) re modul level 方法 正则表达式对象 匹配对象 常用例子 注意事项 Ja ...
- Python正则表达式与re模块
在线正则表达式测试 http://tool.oschina.net/regex/ 常见匹配模式 模式 描述 \w 匹配字母数字及下划线 \W 匹配非字母数字下划线 \s 匹配任意空白字符,等价于 [\ ...
- Python 删除文件与文件夹
版权所有,未经许可,禁止转载 章节 Python 介绍 Python 开发环境搭建 Python 语法 Python 变量 Python 数值类型 Python 类型转换 Python 字符串(Str ...
- Python 异常处理(Try...Except)
版权所有,未经许可,禁止转载 章节 Python 介绍 Python 开发环境搭建 Python 语法 Python 变量 Python 数值类型 Python 类型转换 Python 字符串(Str ...
- Python 打开文件(File Open)
版权所有,未经许可,禁止转载 章节 Python 介绍 Python 开发环境搭建 Python 语法 Python 变量 Python 数值类型 Python 类型转换 Python 字符串(Str ...
- Python PIP包管理器
版权所有,未经许可,禁止转载 章节 Python 介绍 Python 开发环境搭建 Python 语法 Python 变量 Python 数值类型 Python 类型转换 Python 字符串(Str ...
- 正则表达式(BREs,EREs,PREs)差异比较
我想各位也和我一样,再linux下使用grep,egrep, awk , sed, vi的搜索时,会经常搞不太清楚,哪此特殊字符得使用转义字符'\' .. 哪些不需要, grep与egrep的差异 ...
- 【转】linux shell 正则表达式(BREs,EREs,PREs)差异比较
我想各位也和我一样,再linux下使用grep,egrep, awk , sed, vi的搜索时,会经常搞不太清楚,哪此特殊字符得使用转义字符'\' .. 哪些不需要, grep与egrep的差异 ...
随机推荐
- cf 223B.Two Strings
神奇(%%题解) 题意:判断B串作为A串的子序列,不是不可以把A全部覆盖掉. 这样的话就是判断是不是A[i]最右匹配B的点和最左匹配B的点相交(重合)就好.(不重合的话B自然会空出中间一段,那么肯定不 ...
- 干货分享|Law Essay写作高分攻略
很多法学院的留学生对于Law Essay写作不是特别擅长,理论知识都了解,但是写出来的essay分数就是不高.同学们要从哪些方面入手呢?Law Essay写作要怎么拿高分?具体就跟小编一起来看看吧! ...
- Notepad++配置
笔记来源于视频: http://baidu.iqiyi.com/watch/498601896985630918.html?page=videoMultiNeed notepad++ 有个很重要问题, ...
- 14. react 基础 redux 的编写 TodoList 功能
1. 安装 redux 监听工具 ( 需要翻墙 ) 打开 谷歌商店 搜索 redux devtool 安装第一个即可 2. 安装 redux yarn add redux 3. 创建 一个 store ...
- OpenSSL加密证书
用于建立安全站点的工具,颁发证书,例如https,ftps等 默认配置文件: [root@bogon CA]# cat /etc/pki/tls/openssl.cnf [ CA_default ] ...
- Exchange 2016 OWA更改css样式
css文件目录:E:\Exchange 2016\FrontEnd\HttpProxy\owa\auth\15.1.1713\themes\resources\logon.css ##更改左侧页面颜色 ...
- Jackknife,Bootstrap, Bagging, Boosting, AdaBoost, RandomForest 和 Gradient Boosting的区别
Bootstraping: 名字来自成语“pull up by your own bootstraps”,意思是依靠你自己的资源,称为自助法,它是一种有放回的抽样方法,它是非参数统计中一种重要的估计统 ...
- D语言-运算符
Part 0:概念 表达式:表达式是由非赋值运算符或特殊运算符和值组成的,每个表达式都可以计算出一个值 Part 1:非赋值运算符 §1.1 基本的运算符 基本的运算符有+,-,*,/,% 我相信你除 ...
- 定时任务莫名停止,Spring 定时任务存在 Bug?
专注于Java领域优质,技术欢迎关注 作者: 鸭血粉丝 来自:Java极客技术 Hello~各位读者新年好,我是鸭血粉丝(大家可以称呼我为「阿粉」).这里阿粉给大家拜个年,祝大家蒸蒸日上烫烫烫,年年有 ...
- C语言-字、半字、内存位宽相关
1.32位系统:32位系统指的是32位数据线,但是一般地址线也是32位,这个地址线32位决定了内存地址只能有32位二进制,所以逻辑上的大小为2的32次方.内存限制就为4G.实际上32位系统中可用的内存 ...