精讲 使用ELK堆栈部署Kafka
使用ELK堆栈部署Kafka
通过优锐课的java架构学习分享,在本文中,我将展示如何使用ELK Stack和Kafka部署建立弹性数据管道所需的所有组件。
在发生生产事件后,恰恰在你最需要它们时,日志可能突然激增并淹没你的日志记录基础结构。 为了防止Logstash和Elasticsearch遭受此类数据突发攻击,用户部署了缓冲机制以充当消息代理。
Apache Kafka是与ELK Stack一起部署的最常见的代理解决方案。 通常,Kafka部署在托运人和索引器之间,用作收集数据的入口点:
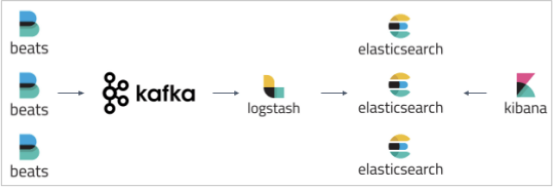
在本文中,我将展示如何使用ELK Stack和Kafka部署建立弹性数据管道所需的所有组件:
- ·Filebeat-收集日志并将其转发到Kafka主题。
- ·Kafka-代理数据流并将其排队。
- ·Logstash-汇总来自Kafka主题的数据,对其进行处理并将其发送到Elasticsearch。
- ·Elasticsearch-为数据建立索引。
- ·Kibana-用于分析数据。
我的环境
要执行以下步骤,我使用本地存储在AWS EC2上设置了一台Ubuntu 16.04计算机。 在现实生活中,你可能会使所有这些组件都在单独的计算机上运行。
我在VPC的公共子网中启动了实例,然后设置了一个安全组,以允许使用SSH和TCP 5601(对于Kibana)从任何地方进行访问。 最后,我添加了一个新的弹性IP地址,并将其与正在运行的实例关联。
本教程使用的示例日志是Apache访问日志。
步骤1:安装Elasticsearch
我们将从在堆栈中安装主要组件Elasticsearch开始。 从7.x版开始,Elasticsearch已与Java捆绑在一起,因此我们可以通过添加Elastic的签名密钥来直接前进:
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
为了在Debian上安装Elasticsearch,我们还需要安装apt-transport-https软件包:
sudo apt-get update sudo apt-get install apt-transport-https
下一步是将存储库定义添加到我们的系统中:
echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list
剩下要做的就是更新你的存储库并安装Elasticsearch:
sudo apt-get update && sudo apt-get install elasticsearch
在引导Elasticsearch之前,我们需要使用Elasticsearch配置文件在/etc/elasticsearch/elasticsearch.yml中应用一些基本配置:
sudo su vim /etc/elasticsearch/elasticsearch.yml
由于我们在AWS上安装Elasticsearch,因此我们将Elasticsearch绑定到localhost。 此外,我们需要将EC2实例的私有IP定义为符合主机资格的节点:
network.host: "localhost" http.port:9200 cluster.initial_master_nodes: ["<InstancePrivateIP"]
保存文件并使用以下命令运行Elasticsearch:
sudo service elasticsearch start
要确认一切正常,请将curl指向:http:// localhost:9200,你应该看到类似以下输出的内容(在开始担心看不到任何响应之前,请给Elasticsearch一两分钟):
{
"name" : "ip-172-31-49-60",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "yP0uMKA6QmCsXQon-rxawQ",
"version" : {
"number" : "7.0.0",
"build_flavor" : "default",
"build_type" : "deb",
"build_hash" : "b7e28a7",
"build_date" : "2019-04-05T22:55:32.697037Z",
"build_snapshot" : false,
"lucene_version" : "8.0.0",
"minimum_wire_compatibility_version" : "6.7.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
步骤2:安装Logstash
接下来,ELK中的“ L” — Logstash。 Logstash将要求我们安装Java 8,这很好,因为这也是运行Kafka的要求:
sudo apt-get install default-jre
验证是否已安装Java:
java -version openjdk version "1.8.0_191" OpenJDK Runtime Environment (build 1.8.0_191-8u191-b12-2ubuntu0.16.04.1-b12) OpenJDK 64-Bit Server VM (build 25.191-b12, mixed mode)
由于我们已经在系统中定义了存储库,因此运行安装Logstash所需要做的全部工作:
sudo apt-get install logstash
接下来,我们将配置一个Logstash管道,该管道将从Kafka主题中提取我们的日志,处理这些日志并将其发送到Elasticsearch进行索引。
让我们创建一个新的配置文件:
sudo vim /etc/logstash/conf.d/apache.conf
粘贴以下配置:
input {
kafka {
bootstrap_servers => "localhost:9092"
topics => "apache"
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
date {
match => [ "timestamp" , "dd/MMM/yyyy:HH:mm:ss Z" ]
}
geoip {
source => "clientip"
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
}
}
如你所见,我们正在使用Logstash Kafka输入插件来定义Kafka主机和我们希望Logstash从中提取的主题。 我们正在对日志进行一些过滤,并将数据发送到我们的本地Elasticsearch实例。
保存文件
步骤3:安装Kibana
让我们继续进行到ELK Stack中的下一个组件-Kibana。 和以前一样,我们将使用一个简单的apt命令来安装Kibana:
sudo apt-get install kibana
然后,我们将在以下位置打开Kibana配置文件:/etc/kibana/kibana.yml,并确保定义了正确的配置:
server.port: 5601 elasticsearch.url: "http://localhost:9200"
这些特定的配置告诉Kibana要连接到哪个Elasticsearch以及要使用哪个端口。
现在,我们可以从以下内容开始Kibana:
sudo service kibana start
在浏览器中使用以下命令打开Kibana:http:// localhost:5601。 你将看到Kibana主页。
步骤4:安装Filebeat
如上所述,我们将使用Filebeat收集日志文件并将其转发到Kafka。
要安装Filebeat,我们将使用:
sudo apt-get install filebeat
让我们在以下位置打开Filebeat配置文件:
/etc/filebeat/filebeat.yml sudo vim /etc/filebeat/filebeat.yml
输入以下配置:
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/apache2/access.log
output.kafka:
codec.format:
string: '%{[@timestamp]} %{[message]}'
hosts: ["localhost:9092"]
topic: apache
partition.round_robin:
reachable_only: false
required_acks: 1
compression: gzip
max_message_bytes: 1000000
在输入部分,我们告诉Filebeat要收集哪些日志-Apache访问日志。 在输出部分,我们告诉Filebeat将数据转发到本地Kafka服务器和相关主题(将在下一步中安装)。
请注意使用codec.format指令-这是为了确保正确提取message和timestamp字段。 否则,这些行将以JSON发送到Kafka。
保存文件。
步骤4:安装Kafka
我们的最后也是最后一次安装涉及设置Apache Kafka(我们的消息代理)。
Kafka使用ZooKeeper来维护配置信息和同步,因此我们需要在设置Kafka之前安装ZooKeeper:
sudo apt-get install zookeeperd
接下来,让我们下载并解压缩Kafka:
wget http://apache.mivzakim.net/kafka/2.2.0/kafka_2.12-2.2.0.tgz tar -xvzf kafka_2.12-2.2.0.tgz sudo cp -r kafka_2.12-2.2.0 /opt/kafka
现在我们准备运行Kafka,我们将使用以下脚本进行操作:
sudo /opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.properties
你应该开始在控制台中看到一些INFO消息:
[2019-04-22 11:48:16,489] INFO Registered
kafka:type=kafka.Log4jController MBean
(kafka.utils.Log4jControllerRegistration$)
[2019-04-22 11:48:18,589] INFO starting (kafka.server.KafkaServer)
接下来,我们将为Apache日志创建一个主题:
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic apache Created topic apache.
我们都准备开始管道。
步骤5:启动数据管道
现在我们已经准备就绪,现在该启动所有负责运行数据管道的组件了。
首先,我们将启动Filebeat:
sudo service filebeat start 然后,Logstash: sudo service logstash start
管道开始流式传输日志需要花费几分钟。 要查看Kafka的实际效果,请在单独的标签中输入以下命令:
/opt/kafka/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic apache --from-beginning
如果你的Apache Web服务器确实在处理请求,则应该开始在控制台中查看Filebeat将消息转发到Kafka主题的消息:
2019-04-23T13:50:01.559Z 89.138.90.236 - - [23/Apr/2019:13:50:00 +0000]
"GET /mysite.html HTTP/1.1" 200 426 "-" "Mozilla/5.0
(Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/73.0.3683.86 Safari/537.36"
2019-04-23T13:51:36.581Z 89.138.90.236 - -
[23/Apr/2019:13:51:34 +0000] "GET /mysite.html HTTP/1.1" 200 427 "-"
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36"
为了确保Logstash正在聚合数据并将其运送到Elasticsearch中,请使用:
curl -X GET "localhost:9200/_cat/indices?v"
如果一切正常,你应该看到列出了logstash- *索引:
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open .kibana_task_manager zmMH6yy8Q6yg2jJHxq3MFA 1 0 2 0 45.4kb 45.4kb
yellow open logstash-2019.04.23-000001 rBx5r_gIS3W2dTxHzGJVvQ 1 1 9 0 69.4kb 69.4kb
green open .kibana_1 rv5f8uHnQTCGe8YrcKAwlQ 1 0 5 0
如果你没有看到该索引,恐怕是时候进行一些调试了。 查看此博客文章,了解调试Logstash的一些技巧。
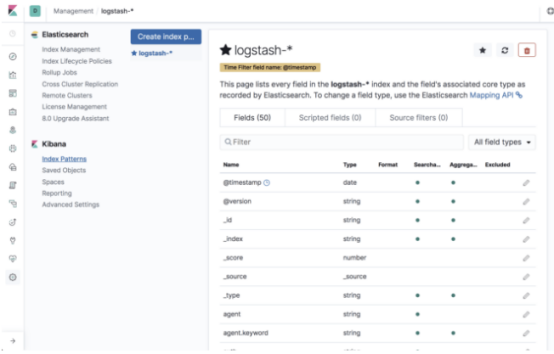
我们现在要做的就是在Kibana中定义索引模式以开始分析。 这是在管理→Kibana索引模式下完成的。
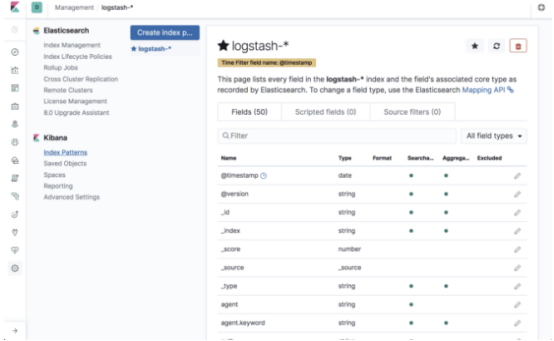
Kibana将识别索引,因此只需在相关字段中对其进行定义,然后继续选择时间戳字段的下一步:
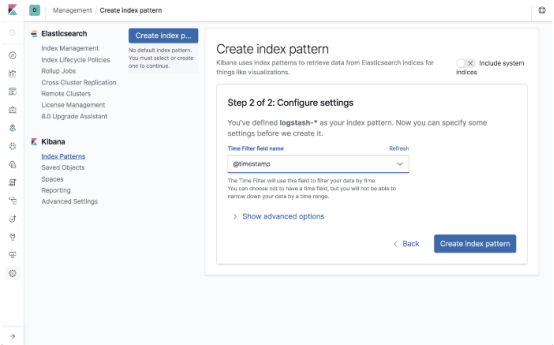
创建索引模式后,你将看到所有已解析和映射字段的列表:
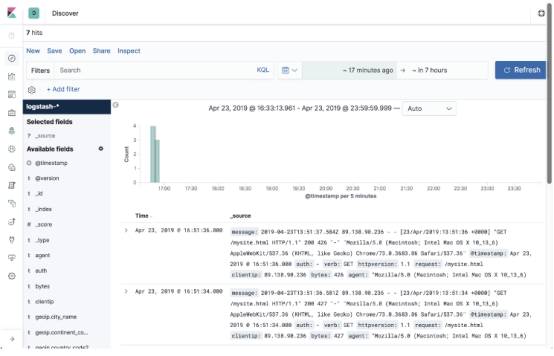
打开“发现”页面开始分析数据!
总结:
弹性数据管道是任何生产级ELK部署中所必需的。 日志对于将事件组合在一起至关重要,在紧急情况下最需要它们。 我们无法让我们的日志记录基础结构在最需要的确切时间点发生故障。 Kafka和类似的代理在缓冲数据流方面发挥着重要作用,因此Logstash和Elasticsearch不会在突然爆发的压力下崩溃。
上面的示例是课程的基本设置。 生产部署将包括多个Kafka实例,大量数据和更复杂的管道。 这将涉及大量的工程时间和资源,需要加以考虑。 不过,这里的说明将帮助你了解入门方法。 我还建议你看一下我们的文章,解释如何记录Kafka本身。
> 喜欢这篇文章的可以点个赞,欢迎大家留言评论,记得关注我,每天持续更新技术干货、职场趣事、海量面试资料等等
> 如果你对java技术很感兴趣也可以交流学习,共同学习进步。
> 不要再用"没有时间“来掩饰自己思想上的懒惰!趁年轻,使劲拼,给未来的自己一个交代
文章写道这里,欢迎完善交流。最后奉上近期整理出来的一套完整的java架构思维导图,分享给大家对照知识点参考学习。有更多JVM、Mysql、Tomcat、Spring Boot、Spring Cloud、Zookeeper、Kafka、RabbitMQ、RockerMQ、Redis、ELK、Git等Java干货
精讲 使用ELK堆栈部署Kafka的更多相关文章
- 第三百七十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目
第三百七十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目 scrapyd模块是专门用于部署scrapy项目的,可以部署和管理scrapy项目 下载地址:h ...
- linux单机部署kafka(filebeat+elk组合)
filebeat+elk组合之kafka单机部署 准备: kafka下载链接地址:http://kafka.apache.org/downloads.html 在这里下载kafka_2.12-2.10 ...
- 生产环境Docker部署ELK跨区访问kafka不通问题的解决
由于分布式系统的日志集中采集的需求非常强烈,我们组通过调研和实践搭建了一套基于Docker的日志收集系统Amethyst. 我们首先在测试环境搭建了一套基于Docker swarm集群的ELK分布式环 ...
- 【原创】分布式之redis复习精讲
引言 为什么写这篇文章? 博主的<分布式之消息队列复习精讲>得到了大家的好评,内心诚惶诚恐,想着再出一篇关于复习精讲的文章.但是还是要说明一下,复习精讲的文章偏面试准备,真正在开发过程中, ...
- 转 Redis 总结精讲 看一篇成高手系统-4
转 Redis 总结精讲 看一篇成高手系统-4 2018年05月31日 09:00:05 hjm4702192 阅读数:125633 本文围绕以下几点进行阐述 1.为什么使用redis 2.使用r ...
- 分布式之redis复习精讲
看到一片不错的精简的redis文档,转载之,便于复习梳理之用 转自:https://www.cnblogs.com/rjzheng/p/9096228.html ------------------- ...
- 【转载】分布式之redis复习精讲
注: 本篇文章转自:分布式之redis复习精讲 引言 为什么写这篇文章? 博主的<分布式之消息队列复习精讲>得到了大家的好评,内心诚惶诚恐,想着再出一篇关于复习精讲的文章.但是还是要说明一 ...
- ELK 安装部署实战 (最新6.4.0版本)
一.实战背景 根据公司平台的发展速度,对于ELK日志分析日益迫切.主要的需求有: 1.用户行为分析 2.运营活动点击率分析 作为上述2点需求,安装最新版本6.4.0是非常有必要的,大家可根据本人之前博 ...
- 【转】分布式之redis复习精讲
转自:https://www.cnblogs.com/rjzheng/p/9096228.html 引言 为什么写这篇文章? 博主的<分布式之消息队列复习精讲>得到了大家的好评,内心诚惶诚 ...
随机推荐
- Oracle的操作经验
采用Oracle进行sql语句 建表并设置主键,主键自增,某一字段唯一性约束等 <---如果表存在则删除---> declare num number; begin select coun ...
- 一百一十三、SAP的SCAT录屏操作,类似按键精灵可用于批量修改数据
一.输入事务代码SCAT,输入Z开头的程序名,点击左上角的新建图标 二.输入标题和模块名 三.保存为本地对象 四.包属性修改为CATT,然后保存 五.可以看到我们新建的一条内容,点击小铅笔修改 六.点 ...
- torch.cuda.FloatTensor
Pytorch中的tensor又包括CPU上的数据类型和GPU上的数据类型,一般GPU上的Tensor是CPU上的Tensor加cuda()函数得到. 一般系统默认是torch.FloatTensor ...
- JAVA作用域和排序算法介绍
一.作用域 1.作用域的概念 所谓的作用域是指引用可以作用到的范围. 一个引用的作用域是从引用定义位置到包裹它的最近的大括号的结束位置.只有在作用域范围内才可以访问到引用,超出作用域无法访问引用. 定 ...
- javaBean命名属性时的小注意点
javabean属性命名的时,第一个和第二个字母最好不要是大写字母,不然使用eclipse自动生成getter和setter方法时,会出现奇怪的问题,导致struts2封装属性的封装不上. priva ...
- 大数据高可用集群环境安装与配置(04)——安装JAVA运行环境
Hadoop运行在java环境,所以在安装Hadoop之前,需要安装好jdk 提前下载好jdk安装包(jdk-8u161-linux-x64.tar.gz),将它上传到指定的安装目录当中,然后运行安装 ...
- Python Learning Day7
破解极验滑动验证 博客园登录url: https://account.cnblogs.com/signin?returnUrl=https%3A%2F%2Fwww.cnblogs.com%2F 代码逻 ...
- 三、在SAP中文本如何换行
一.在一段文字前面,加上右斜杠符合\ ,这句话就会换行了,如图: 效果如下:
- java内存机制 垃圾回收
gc机制一 1.JVM的gc概述 gc即垃圾收集机制是指jvm用于释放那些不再使用的对象所占用的内存.java语言并不要求jvm有gc,也没有规定gc如何工作.不过常用的jvm都有gc,而且大多数gc ...
- Innodb特性以及实现原理
Innodb五大特性 1.insert buffer2.double write3.自适应哈希索引4.异步io5.邻接页刷新 1.insert buffer(change buffer) 作用:将非聚 ...