Sqoop 结合多种系统的具体应用
Sqoop与HDFS结合
下面我们结合 HDFS,介绍 Sqoop 从关系型数据库的导入和导出。
Sqoop import
它的功能是将数据从关系型数据库导入 HDFS 中,其流程图如下所示。
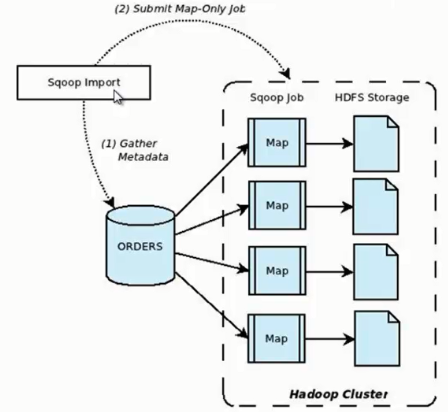
我们来分析一下 Sqoop 数据导入流程,首先用户输入一个 Sqoop import 命令,Sqoop 会从关系型数据库中获取元数据信息,比如要操作数据库表的 schema是什么样子,这个表有哪些字段,这些字段都是什么数据类型等。它获取这些信息之后,会将输入命令转化为基于 Map 的 MapReduce作业。这样 MapReduce作业中有很多 Map 任务,每个 Map 任务从数据库中读取一片数据,这样多个 Map 任务实现并发的拷贝,把整个数据快速的拷贝到 HDFS 上。
下面我们看一下 Sqoop 如何使用命令行来导入数据的,其命令行语法如下所示
sqoop import \
--connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \
--username sqoop \
--password sqoop \
--table user \
--target-dir /junior/sqoop/ \ //可选,不指定目录,数据默认导入到/user下
--where "sex='female'" \ //可选
--as-sequencefile \ //可选,不指定格式,数据格式默认为 Text 文本格式
--num-mappers 10 \ //可选,这个数值不宜太大
--null-string '\\N' \ //可选
--null-non-string '\\N' \ //可选
--connect:指定 JDBC URL。
--username/password:mysql 数据库的用户名。
--table:要读取的数据库表。
--target-dir:将数据导入到指定的 HDFS 目录下,文件名称如果不指定的话,会默认数据库的表名称。
--where:过滤从数据库中要导入的数据。
--as-sequencefile:指定数据导入数据格式。
--num-mappers:指定 Map 任务的并发度。
--null-string,--null-non-string:同时使用可以将数据库中的空字段转化为'\N',因为数据库中字段为 null,会占用很大的空间。
下面我们介绍几种 Sqoop 数据导入的特殊应用。
1、Sqoop 每次导入数据的时候,不需要把以往的所有数据重新导入 HDFS,只需要把新增的数据导入 HDFS 即可,下面我们来看看如何导入新增数据。
sqoop import \
--connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \
--username sqoop \
--password sqoop \
--table user \
--incremental append \ //代表只导入增量数据
--check-column id \ //以主键id作为判断条件
--last-value 999 //导入id大于999的新增数据
上述三个组合使用,可以实现数据的增量导入。
2、Sqoop 数据导入过程中,直接输入明码存在安全隐患,我们可以通过下面两种方式规避这种风险。
1)-P:sqoop 命令行最后使用 -P,此时提示用户输入密码,而且用户输入的密码是看不见的,起到安全保护作用。密码输入正确后,才会执行 sqoop 命令。
sqoop import \
--connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \
--username sqoop \
--table user \
-P
2)--password-file:指定一个密码保存文件,读取密码。我们可以将这个文件设置为只有自己可读的文件,防止密码泄露。
sqoop import \
--connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \
--username sqoop \
--table user \
--password-file my-sqoop-password
Sqoop export
它的功能是将数据从 HDFS 导入关系型数据库表中,其流程图如下所示。
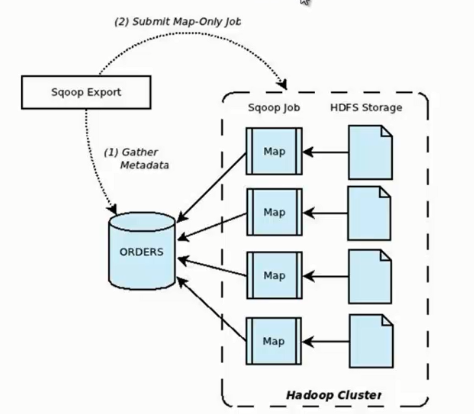
我们来分析一下 Sqoop 数据导出流程,首先用户输入一个 Sqoop export 命令,它会获取关系型数据库的 schema,建立 Hadoop 字段与数据库表字段的映射关系。 然后会将输入命令转化为基于 Map 的 MapReduce作业,这样 MapReduce作业中有很多 Map 任务,它们并行的从 HDFS 读取数据,并将整个数据拷贝到数据库中。
下面我们看一下 Sqoop 如何使用命令行来导出数据的,其命令行语法如下所示。
sqoop export \
--connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \
--username sqoop \
--password sqoop \
--table user \
--export-dir user
--connect:指定 JDBC URL。
--username/password:mysql 数据库的用户名和密码。
--table:要导入的数据库表。
--export-dir:数据在 HDFS 上的存放目录。
下面我们介绍几种 Sqoop 数据导出的特殊应用。
1、Sqoop export 将数据导入数据库,一般情况下是一条一条导入的,这样导入的效率非常低。这时我们可以使用 Sqoop export 的批量导入提高效率,其具体语法如下。
sqoop export \
--Dsqoop.export.records.per.statement=10 \
--connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \
--username sqoop \
--password sqoop \
--table user \
--export-dir user \
--batch
--Dsqoop.export.records.per.statement:指定每次导入10条数据,--batch:指定是批量导入。
2、在实际应用中还存在这样一个问题,比如导入数据的时候,Map Task 执行失败, 那么该 Map 任务会转移到另外一个节点执行重新运行,这时候之前导入的数据又要重新导入一份,造成数据重复导入。 因为 Map Task 没有回滚策略,一旦运行失败,已经导入数据库中的数据就无法恢复。Sqoop export 提供了一种机制能保证原子性, 使用--staging-table 选项指定临时导入的表。Sqoop export 导出数据的时候会分为两步:第一步,将数据导入数据库中的临时表,如果导入期间 Map Task 失败,会删除临时表数据重新导入;第二步,确认所有 Map Task 任务成功后,会将临时表名称为指定的表名称。
sqoop export \
--connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \
--username sqoop \
--password sqoop \
--table user \
--staging-table staging_user
3、在 Sqoop 导出数据过程中,如果我们想更新已有数据,可以采取以下两种方式。
1)通过 --update-key id 更新已有数据。
sqoop export \
--connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \
--username sqoop \
--password sqoop \
--table user \
--update-key id
2)使用 --update-key id和--update-mode allowinsert 两个选项的情况下,如果数据已经存在,则更新数据,如果数据不存在,则插入新数据记录。
sqoop export \
--connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \
--username sqoop \
--password sqoop \
--table user \
--update-key id \
--update-mode allowinsert
4、如果 HDFS 中的数据量比较大,很多字段并不需要,我们可以使用 --columns 来指定插入某几列数据。
sqoop export \
--connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \
--username sqoop \
--password sqoop \
--table user \
--column username,sex
5、当导入的字段数据不存在或者为null的时候,我们使用--input-null-string和--input-null-non-string 来处理。
sqoop export \
--connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \
--username sqoop \
--password sqoop \
--table user \
--input-null-string '\\N' \
--input-null-non-string '\\N'
Sqoop与其它系统结合
Sqoop 也可以与Hive、HBase等系统结合,实现数据的导入和导出,用户需要在 sqoop-env.sh 中添加HBASE_HOME、HIVE_HOME等环境变量。
1、Sqoop与Hive结合比较简单,使用 --hive-import 选项就可以实现。
sqoop import \
--connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \
--username sqoop \
--password sqoop \
--table user \
--hive-import
2、Sqoop与HBase结合稍微麻烦一些,需要使用 --hbase-table 指定表名称,使用 --column-family 指定列名称。
sqoop import \
--connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \
--username sqoop \
--password sqoop \
--table user \
--hbase-table user \
--column-family city
Sqoop 结合多种系统的具体应用的更多相关文章
- Hadoop数据收集与入库系统Flume与Sqoop
Hadoop提供了一个中央化的存储系统,其有利于进行集中式的数据分析与数据共享. Hadoop对存储格式没有要求.可以存储用户访问日志.产品信息以及网页数据等数据. 常见的两种数据来源.一种是分散的数 ...
- Sqoop与HDFS、Hive、Hbase等系统的数据同步操作
Sqoop与HDFS结合 下面我们结合 HDFS,介绍 Sqoop 从关系型数据库的导入和导出. Sqoop import 它的功能是将数据从关系型数据库导入 HDFS 中,其流程图如下所示. 我们来 ...
- Sqoop简介
一 Sqoop是什么 Sqoop:SQL-to-Hadoop 连接传统关系型数据库和Hadoop的桥梁 把关系型数据库的数据导入到 Hadoop 系统 ( 如 HDFS.HBase 和 Hive) ...
- 数据迁移之Sqoop
一 简介 Apache Sqoop(TM)是一种用于在Apache Hadoop和结构化数据存储(如关系数据库)之间高效传输批量数据的工具 . 官方下载地址:http://www.apache.org ...
- 为什么我会认为SAP是世界上最好用最牛逼的ERP系统,没有之一?
为什么我认为SAP是世界上最好用最牛逼的ERP系统,没有之一?玩过QAD.Tiptop.用友等产品,深深觉得SAP是贵的有道理! 一套好的ERP系统,不仅能够最大程度承接适配企业的管理和业务流程,在技 ...
- linux系统运维常用基本命令详解
1.ls 文件属性: -:普通文件 d:目录文件 b:块设备 c:字符设备文件 l:符号连接文件 p:命令管道 s:套接字文件 文件权限: 9位数字,每3位一组 文件硬链接次数 ...
- Oracle系统学习摘要
对于企业级大型系统,Oracle数据库的重要性不言而喻,作为长期使用Sql server的developer,花了点时间学习了一个Oracle的系列课程,总结一下. 1.oracle一些基础命令 sq ...
- 转 系统级编程语言性能PK
http://www.solidot.org/story?sid=35754 看了此文,为什么我现在如此看好Rust C/C++已经统治系统编程很久,除了ObjectiveC之外语言都无法获得很高的关 ...
- zz Windows 10安装教程:硬盘安装Win10 系统步骤(适合32位和64位)
Windows 10安装教程:硬盘安装Win10 系统步骤(适合32位和64位) Posted on 2015年01月28日 by 虾虾 22 Comments 最新的Windows 10 MSD ...
随机推荐
- Excel基础
一.基础 一个Excel文档称为工作簿(workbook).一个工作簿中可以包含多个工作表(sheet) ctrl+向右箭头 查看最后一列 ctrl+向下箭头 查看最后一行 二.合并单元格 三.等高 ...
- 深入instanceof
本文转自这里 规范中 instanceof 运算符定义 11.8.6 The instanceof operator The production RelationalExpression: Rela ...
- [Java IO]03_字符流
Java程序中,一个字符等于两个字节. Reader 和 Writer 两个就是专门用于操作字符流的类. Writer Writer是一个字符流的抽象类. 它的定义如下: public abstra ...
- jQuery-1.9.1源码分析系列(十) 事件系统——事件绑定
事件绑定的方式有很多种.使用了jQuery那么原来那种绑定方式(elem.click = function(){...})就不推荐了,原因? 最主要的一个原因是elem.click = fn这种方式只 ...
- C#程序开发中经常遇到的10条实用的代码
1 读取操作系统和CLR的版本 OperatingSystem os = System.Environment.OSVersion; Console.WriteLine("Platform: ...
- Effective java笔记(十),序列化
将一个对象编码成字节流称作将该对象「序列化」.相反,从字节流编码中重新构建对象被称作「反序列化」.一旦对象被「序列化」后,它的编码就可以从一台虚拟机传递到另一台虚拟机,或被存储到磁盘上,供以后「反序列 ...
- 多个提高C#编程能力的建议
1.总是用属性 (Property) 来代替可访问的数据成员 2.在 readonly 和 const 之间,优先使用 readonly 3.在 as 和 强制类型转换之间,优先使用 as 操作符 4 ...
- PHP5各个版本的新功能和新特性总结
因为 PHP 那“集百家之长”的蛋疼语法,加上社区氛围不好,很多人对新版本,新特征并无兴趣.本文将会介绍自 PHP5.2 起,直至 PHP5.6 中增加的新特征 本文目录:PHP5.2 以前:auto ...
- Asp.net 面向接口可扩展框架之类型转化基础服务
新框架正在逐步完善,可喜可贺的是基础服务部分初具模样了,给大家分享一下 由于基础服务涉及面太广,也没开发完,这篇只介绍其中的类型转化部分,命名为类型转化基础服务,其实就是基础服务模块的类型转化子模块 ...
- 【Java每日一题】20161214
package Dec2016; import java.util.ArrayList; import java.util.List; public class Ques1214 { public s ...