deeplearning.ai 卷积神经网络 Week 3 目标检测
本周的主题是对象检测(object detection):不但需要检测出物体(image classification),还要能定位出在图片的具体位置(classification with localization),而且要能处理图片中的多个物体(detection)。
1. 例子:无人驾驶中确定图片是否有1)行人;2)小汽车;3)摩托车,并用矩形标记出物体在图像中的位置(bx、by、bh、bw),如果三类目标都没有,则标记为4)背景。使用softmax分类这四种情况。这里只考虑每张图片最多有一个目标的情况。输出y = [pc, bx, by, bh, bw, c1, c2, c3]T。其中pc表示图片中是否有目标,c1、c2、c3表示该对象术语哪一类。如果图片中有一辆车,则标签y = [1, bx, by, bh, bw, 0, 1, 0]T;如果图片中没有目标,则标签y = [0, ?, ?, ?, ?, ?, ?, ?]T,问号表示一旦pc为0,其他参数都不重要。

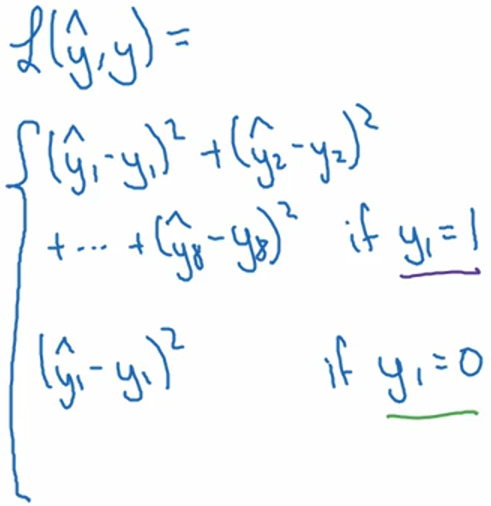
第二个例子是人脸检测,往往我们会需要提取出若干关键点(landmark)(例如眼角、嘴角等)的像素位置,这里我们假设有64个关键点,此时的标签可以设置为 y = [pc, l1x, l1y, l2x, l2y, ..., l64x, l64y]T。pc表示图片中是否有人脸。类似的还有人体检测,也是若干关键点(例如肘关节、肩关节等)。
2. 滑动窗口目标检测(sliding windows detection)
用从小到大不同大小的window去滑动遍历图片的每一部分,送入神经网络看这个区域是否有目标。这种方法的缺点是计算量太大。对于同一个window来说,滑动过程中截取的图片,会有很多共同区域,是不需要重复运算的。所以实际实现的时候(Sermanet et al., 2014, OverFeat: Integrated recognition, localization and detection using convolutional networks),我们是把整张图送给神经网络,最后得到的结果等价于先截取不同部分图片喂给系统,然后把得到结果拼成矩阵。如下图所示,上一行是常规的对14*14*3的图片进行处理,得到1*1*4的结果(对应上一段的例子行人、小汽车、摩托车和背景),下一行是大一些的图片16*16*3,我们不需要把它分割成四个14*14*3的图片分别执行前向传播,而是把它作为一张图片给系统进行计算,其中的公有区域可以共享很多计算,最后得到的2*2*4的结果,每个1*1*4对应一个子图片的结果。

3. 确定bouding box的位置
上一段滑动窗口的方法可以找到目标,但是不能输出最精确的边界框。这一节的内容就是得到更精确的边界框。
YOLO算法(Redmon et al., 2015, You Only Look Once: Unified real-time object detection):把输入图片分成网格(这里选择了3*3,实际部署的时候会选择更密的网格比如19*19,这些网格之间是没有交集的,是纯纯的切开,不像滑动窗口),然后把这些格子逐一送给神经网络做前向计算(这里的逐一只是表达每个格子单独作用,实际情况是像滑动窗口的卷积实现一样把整张图片送给系统,只计算一次前向传播),每个格子会输出一个8*1的向量(y = [pc, bx, by, bh, bw, c1, c2, c3]T),所以最终输出3*3*8的矩阵。然后再是精细化的把每个网格内的物体拼成一个整体,最终得到精确的边界框。
每个grid内的bx和by的取值范围是0~1之间,因为中心点必定在当前网格内(否则就属于其他网格),而bh和bw是有可能大于1的(即物体长度或者宽度大于网格边长)。这是一种最方便的参数化方法,论文里有一些更复杂的参数化方法。
NG推荐读YOLO的论文,友情提示说这篇论文非常难懂,他自己第一次看完全不知道作者在说什么,咨询了好一些资深的研究员,他们也不清楚。
4. 交并比函数(Intersection over union,IoU)
IoU一方面可以用来评价object detection算法,另一方面也可以作为参数改善算法。具体做法是计算两个边界框(一个是真实值,一个是预测值)交集和并集面积的比值。一般约定俗成的标准是0.5(这个值并没有什么理论依据,只是习惯,NG说也看到人设成更严格的0.6、0.7,但很少看到有人设到0.5以下),即IoU≥0.5,就说检测正确。如果预测完美等同于真实值,则 IoU=1。
5. 非极大值抑制(Non-max suppression)
算法可能会对同一个对象作出多次检测,非极大值抑制的目的是保证算法对每个对象只检测一次。
如果只检测一个目标,具体做法是:
1)每个边界框都会给检测出物体的概率,丢掉所有概率低于某个阈值(比如0.6)的边界框。
2)选出剩下边界框中最大概率那个并高亮,对于剩下的边界框,只要它和最大概率边界框的IoU小于某个阈值(比如0.5),则它就会被抑制(变暗)。重复执行这一步,直到遍历完所有的边界框。
3)这时候图上所有的边界框要么被高亮,要么变暗,可以直接扔掉变暗的边界框,只留下被高亮的,这些就是我们的预测结果。
如果是检测多个目标,比如三个,则把上述流程针对不同的目标重复三遍。
6. Anchor boxes
目的是让一个格子可以检测出多个对象。具体做法是引入人手工设计的模型(这里叫anchor boxes),比如行人就对应瘦高的竖着的矩形,汽车就对应矮胖的躺着的矩形。这时,标签y被拓展成16*1的向量,每个格子可以被标记出两个物体(标签的前八个元素对应anchor box 1,后八个对应anchor box 2)。这种做法有效的原因就是让目标检测更有针对性。
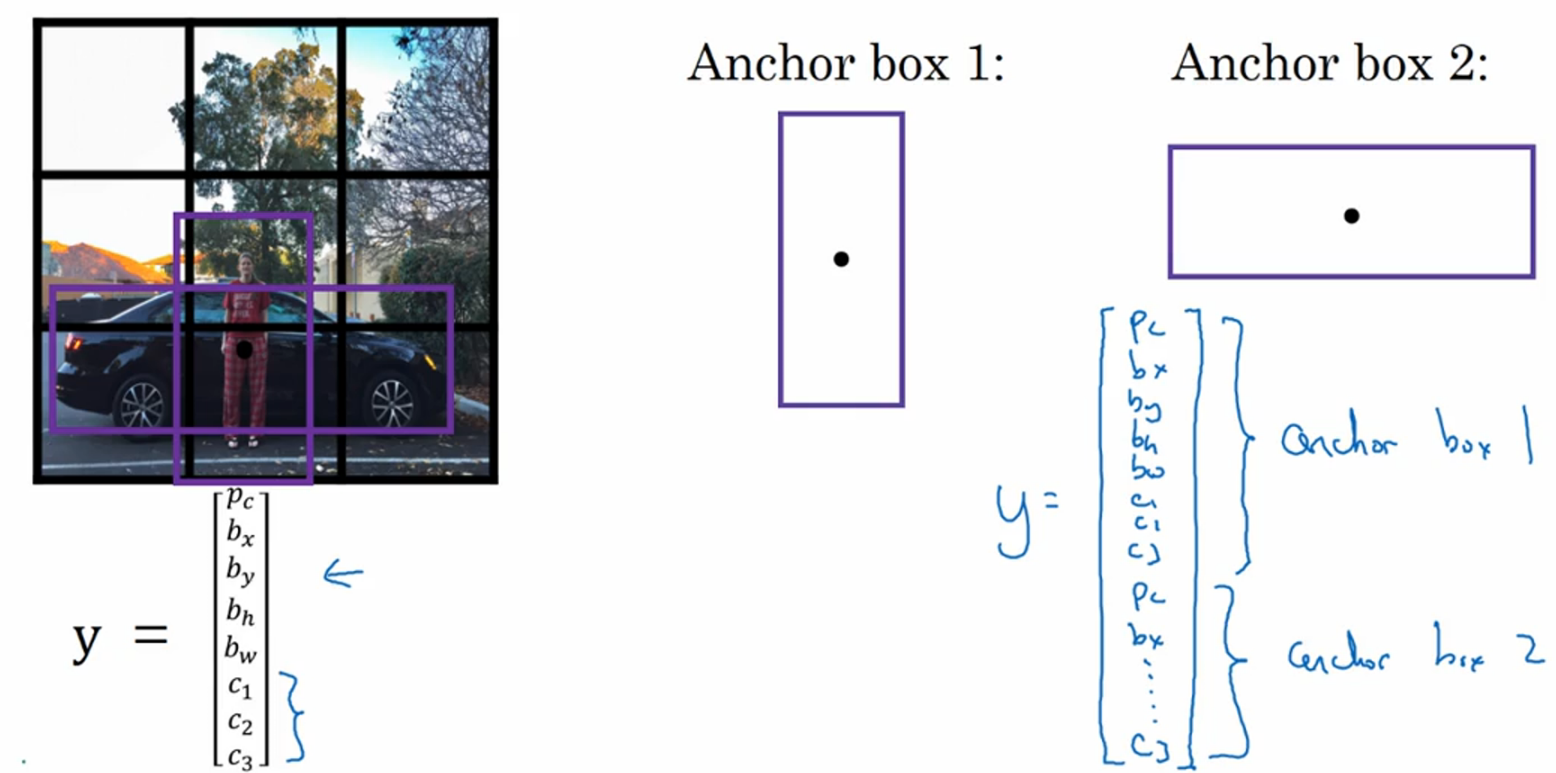
该算法没办法处理以下几种情况:1)如果只有两个anchor box,却有三类物体;2)如果两个物体分到同一个格子,并且它们的anchor box也是一样的。不过幸运的是这两种情况出现的概率不大,尤其是当我们把格子分得很细(比如19*19)。一般anchor box是手工设计的,可以选择5个甚至10个不同的anchor box,覆盖更多的不同的形状。更高阶的版本是用k-means算法选择anchor box。
7. Region proposal (候选区域)
NG说region proposal的想法在目标检测领域也很有影响力,但是他自己相对用的比较少。
R-CNN(Girshik et. al., 2013. Rich feature hierarchies for accurate object detection and semantic segmentation.),意思是带区域(regions)的卷积网络,它尝试选出一些区域,在这些区域上运行卷机网络分类器是有意义的。具体做法是先用一个分割算法(segmentation algorithm),先找出可能2000多个色块(blob),然后在这2000多个色块上放置边界框并跑分类器,这样要处理的区域会少很多。
Fast R-CNN(Girshik, 2015. Fast R-CNN),用卷积的方式实现sliding window,并对所有候选区域执行分类计算。但得到候选区域的聚类算法依旧很慢。
Faster R-CNN(Ren et. al., 2016. Faster R-CNN: Towards real-time object detection with region proposal networks.),用卷积神经网络找候选区域。
NG说R-CNN的加速版本还是比YOLO慢得多。R-CNN需要两步:先找候选区域,再检测特征。相比之下,能够一步做完的YOLO是长远看来更有希望的方向。NG说这只是他一家之言。
deeplearning.ai 卷积神经网络 Week 3 目标检测的更多相关文章
- deeplearning.ai 卷积神经网络 Week 3 目标检测 听课笔记
本周的主题是对象检测(object detection):不但需要检测出物体(image classification),还要能定位出在图片的具体位置(classification with loca ...
- deeplearning.ai 卷积神经网络 Week 4 特殊应用:人脸识别和神经风格转换 听课笔记
本周课程的主题是两大应用:人脸检测和风格迁移. 1. Face verification vs. face recognition Verification: 一对一的问题. 1) 输入:image, ...
- deeplearning.ai 卷积神经网络 Week 1 卷积神经网络 听课笔记
1. 传统的边缘检测(比如Sobel)手工设计了3*3的filter(或者叫kernel)的9个权重,在深度学习中,这9个权重都是学习出来的参数,会比手工设计的filter更好,不但可以提取90度.0 ...
- deeplearning.ai 卷积神经网络 Week 1 卷积神经网络
1. 传统的边缘检测(比如Sobel)手工设计了3*3的filter(或者叫kernel)的9个权重,在深度学习中,这9个权重都是学习出来的参数,会比手工设计的filter更好,不但可以提取90度.0 ...
- deeplearning.ai 卷积神经网络 Week 2 深度卷积网络:实例研究 听课笔记
1. Case study:学习经典网络的原因是它们可以被迁移到其他任务中. 1.1)几种经典的网络: a)LeNet-5(LeCun et al., 1998. Gradient-based lea ...
- deeplearning.ai 卷积神经网络 Week 2 卷积神经网络经典架构
1. Case study:学习经典网络的原因是它们可以被迁移到其他任务中. 1.1)几种经典的网络: a)LeNet-5(LeCun et al., 1998. Gradient-based lea ...
- AI佳作解读系列(二)——目标检测AI算法集杂谈:R-CNN,faster R-CNN,yolo,SSD,yoloV2,yoloV3
1 引言 深度学习目前已经应用到了各个领域,应用场景大体分为三类:物体识别,目标检测,自然语言处理.本文着重与分析目标检测领域的深度学习方法,对其中的经典模型框架进行深入分析. 目标检测可以理解为是物 ...
- Google AI推出新的大规模目标检测挑战赛
来源 | Towards Data Science 整理 | 磐石 就在几天前,Google AI在Kaggle上推出了一项名为Open Images Challenge的大规模目标检测竞赛.当今计算 ...
- 吴恩达deepLearning.ai循环神经网络RNN学习笔记_看图就懂了!!!(理论篇)
前言 目录: RNN提出的背景 - 一个问题 - 为什么不用标准神经网络 - RNN模型怎么解决这个问题 - RNN模型适用的数据特征 - RNN几种类型 RNN模型结构 - RNN block - ...
随机推荐
- PAT Advanced 1099 Build A Binary Search Tree (30) [⼆叉查找树BST]
题目 A Binary Search Tree (BST) is recursively defined as a binary tree which has the following proper ...
- PAT Advanced 1043 Is It a Binary Search Tree (25) [⼆叉查找树BST]
题目 A Binary Search Tree (BST) is recursively defined as a binary tree which has the following proper ...
- vi粘贴代码后格式混乱的问题
最近在远程终端使用vi发现从其他地方复制代码的后,粘贴到vi里面出现格式变乱的问题. 主要是因为终端通常无法区分输入是来自用户输入还是来自粘贴,所以终端也不能通知 vim 输入来自何处.在 vim 里 ...
- RFC文档(http部分)
Request For Comments(RFC),是一系列以编号排定的文件.文件收集了有关互联网相关信息,以及UNIX和互联网社区的软件文件.目前RFC文件是由Internet Society(IS ...
- 常用DIV+CSS命名大全集合
一.命名规则说明: - TOP 1).所有的命名最好都小写 2).属性的值一定要用双引号("")括起来,且一定要有值如class="divcss5",i ...
- ServiceComb 集成 Shiro 实践|火影专场发布
Shiro简介 Apache Shiro是一款功能强大.易用的轻量级开源Java安全框架,它主要提供认证.鉴权.加密和会话管理等功能.Spring Security可能是业界用的最广泛的安全框架,但是 ...
- 在scala命令行中加入类库
在scala命令行中加入scala的类库. scala -toolcp $HOME/.ivy2/cache/org.scalanlp/breeze_2.12/jars/breeze_2.12-0.13 ...
- Ambiguous HTTP method Actions require an explicit HttpMethod binding for Swagger 2.0 异常
网上看了很多关于此异常的解决方案,但是大多数都是不能用的,今天把正确的解决方案记录下来,以帮助需要的人 问题:有些接口没有设置HttpPost或HttpGet,非接口设置访问权限为private,控制 ...
- 12 Spring Data JPA:orm思想和hibernate以及jpa的概述和jpa的基本操作
spring data jpa day1:orm思想和hibernate以及jpa的概述和jpa的基本操作 day2:springdatajpa的运行原理以及基本操作 day3:多表操作,复杂查询 d ...
- Java clone方法的使用
浅克隆 Person p2 = (Person) p1.clone(); clone()方法使用后得到p2,p2和p1指向不同的地址.但是如果p1中的属性是引用类型,那么不再对这个引用类型进行复制,而 ...