python掉包侠与深浅拷贝
今日所得
包
logging模块
hashlib模块
openpyxl模块
深浅拷贝
包
在学习模块的时候我们了解过模块的四种表现形式,其中的一种就是包。
什么是包?
它是一系列模块文件的结合体,表示形式就是一个文件夹,该文件夹的内部通常会有一个__init__.py文件,而包的本质其实还是一个模块。
首次导入包的步骤:
先产生一个执行文件的名称空间
1.创建包下面的__init__.py文件的名称空间
2.执行包下面的__init__.py文件中的代码,将产生的名字放入包下面的__init__.py文件名称空间中
3.在执行文件中拿到一个指向包下面的__init__.py文件名称空间的名字
在导入语句中 .号的左边肯定是一个包(文件夹)
#当你作为包的设计者来说
1.当模块的功能特别多的情况下 应该分文件管理
2.每个模块之间为了避免后期模块改名的问题 你可以使用相对导入(包里面的文件都应该是#被导入的模块) #站在包的开发者 如果使用绝对路径来管理的自己的模块 那么它只需要永远以包的路径为基准依次导入模块
#站在包的使用者 你必须得将包所在的那个文件夹路径添加到system path中(******)
python2如果要导入包 包下面必须要有__init__.py文件
python3如果要导入包 包下面没有__init__.py文件也不会报错
当你在删程序不必要的文件的时候 千万不要随意删除__init__.py文件
logging模块
日志模块,日志模块中有五个等级和四个对象
#5个等级
logging.debug('debug日志') #
logging.info('info日志') #
logging.warning('warning日志') #
logging.error('error日志') #
logging.critical('critical日志') #
#四个对象
#1.logger对象:负责产生日志
#2.filter对象 : 过滤日志(了解)
#3.handler对象:控制日志输出的位置(文件/终端)
#4.formmater对象:规定日志内容的格式
#日志的配置
"""
下面的两个变量对应的值 需要你手动修改
"""
logfile_dir = os.path.dirname(__file__) # log文件的目录
logfile_name = 'a3.log' # log文件名 # 如果不存在定义的日志目录就创建一个
if not os.path.isdir(logfile_dir):
os.mkdir(logfile_dir) # log文件的全路径
logfile_path = os.path.join(logfile_dir, logfile_name)
# log配置字典
LOGGING_DIC = {
'version': 1,
'disable_existing_loggers': False,
'formatters': {
'standard': {
'format': standard_format
},
'simple': {
'format': simple_format
},
},
'filters': {}, # 过滤日志
'handlers': {
#打印到终端的日志
'console': {
'level': 'DEBUG',
'class': 'logging.StreamHandler', # 打印到屏幕
'formatter': 'simple'
},
#打印到文件的日志,收集info及以上的日志
'default': {
'level': 'DEBUG',
'class': 'logging.handlers.RotatingFileHandler', # 保存到文件
'formatter': 'standard',
'filename': logfile_path, # 日志文件
'maxBytes': 1024*1024*5, # 日志大小 5M
'backupCount': 5,
'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了
},
},
'loggers': {
#logging.getLogger(__name__)拿到的logger配置
'': {
'handlers': ['default', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
'level': 'DEBUG',
'propagate': True, # 向上(更高level的logger)传递
}, # 当键不存在的情况下 默认都会使用该k:v配置
},
} # 使用日志字典配置
logging.config.dictConfig(LOGGING_DIC) # 自动加载字典中的配置
logger1 = logging.getLogger('asajdjdskaj')
logger1.debug('好好的 不要浮躁 努力就有收获')
hashlib模块
#hashlib模块(加密模块)
import hashlib # 这个加密的过程是无法解密的
md = hashlib.md5() # 生成一个帮你造密文的对象
md.update('hello'.encode('utf-8')) # 往对象里传明文数据 update只能接受bytes类型的数据
md.update(b'morning') # 往对象里传明文数据 update只能接受bytes类型的数据
print(md.hexdigest()) # 获取明文数据对应的密文
除了我们常用的md5外,还有一些其他的算法,但是对于不同的算法,使用方法是相同的,密文的长度越长,内部对应的算法越复杂。但是密文太长也有两个缺点,一是时间消耗越长,二是占用空间更大,所以通常情况下使用md5就足够了。
md = hashlib.md5()
#md.update(b'are') # 传入的内容 可以分多次传入 只要传入的内容相同 那么生成的密文肯定相同
md.update(b'a')
md.update(b'r')
md.update(b'e')
print(md.hexdigest())
"""
hashlib模块应用场景
1.密码的密文存储
2.校验文件内容是否一致
"""
#加盐处理
# 公司自己在每一个需要加密的数据之前 先手动添加一些内容
import hashlib
md = hashlib.md5()
md.update(b'oldboy.com') # 加盐处理
md.update(b'hello') # 真正的内容
print(md.hexdigest()) #动态加盐
import hashlib
def get_md5(data):
md = hashlib.md5()
md.update('加盐'.encode('utf-8'))
md.update(data.encode('utf-8'))
return md.hexdigest() password = input('password>>>:')
res = get_md5(password)
print(res)
openpyxl模块
openpyxl比较火的操作excel表格的模块
03版本之前 excel文件的后缀名 叫xls
03版本之后 excel文件的后缀名 叫xlsx
其它操作excel的模块:
xlwd 写excel xlrt读excel
xlwd和xlrt既支持03版本之前的excel文件,也支持03版本之后的excel文件
openpyxl 只支持03版本之后的 xlsx
from openpyxl import Workbook wb = Workbook() # 先生成一个工作簿
wb1 = wb.create_sheet('index',0) # 创建一个表单页 后面可以通过数字控制位置
wb2 = wb.create_sheet('index1')
wb1.title ='login' # 后期可以通过表单页对象点title修改表单页名称 wb1['A3'] = 666 # 在列表中A3的位置添加数字
wb1['A4'] = 444
wb1.cell(row=6,column=3,value=8888) # 在列表的第6行第3列添加值8888
wb1['A5'] = '=sum(A3:A4)' # 将列表的A3和A4位置进行加法运算,输出结果到A5上 wb.save('test.xlsx') # 保存新建的excel文件,要注意保存之前要确认文件是否关闭,未关闭会报错。
from openpyxl import load_workbook # 读文件
wb = load_workbook('test.xlsx',read_only=True,data_only=True)
print(wb)
print(wb.sheetnames) # ['login', 'Sheet', 'index1']
print(wb['login']['A3'].value) # 读出文件中login里A3处的值
深浅拷贝
l1 = [1,2,3,[4,5,6]]
l2 = l1
print(id(l1),id(l2)) # 值拷贝
#浅拷贝
import copy
l1 = [1,2,3,[4,5,6]]
l2 = copy.copy(l1)
print(l1,l2) # 值相同
print(id(l1),id(l2)) # 地址不同
l1[0]=0
print(l1,l2) # l1=[0, 2, 3, [4, 5, 6]],l2=[1, 2, 3, [4, 5, 6]]
l1[3].append(7)
print(l1,l2) # l1=[0, 2, 3, [4, 5, 6, 7]],l2=[1, 2, 3, [4, 5, 6, 7]]
浅拷贝图示
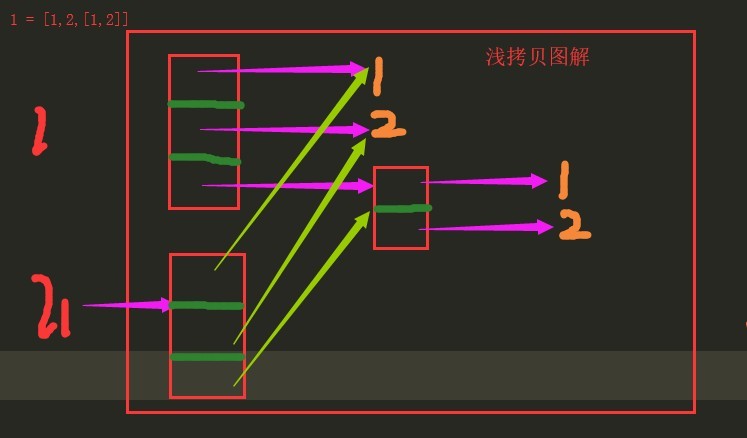
对于浅拷贝来说,只是在内存中重新创建了开辟了一个空间存放一个新列表,但是新列表中的元素与原列表中的元素是公用的,当原列表中存放的是可变类型,浅拷贝指向的是原可变类型,所以当原列表中可变类型中的元素发生变化,浅拷贝的也会跟着一起变。
#深拷贝
l2 = copy.deepcopy(l1)
l1[3].append(7)
print(l1,l2) # l1 = [1, 2, 3, [4, 5, 6, 7]],l2=[1, 2, 3, [4, 5, 6]]
深拷贝图示
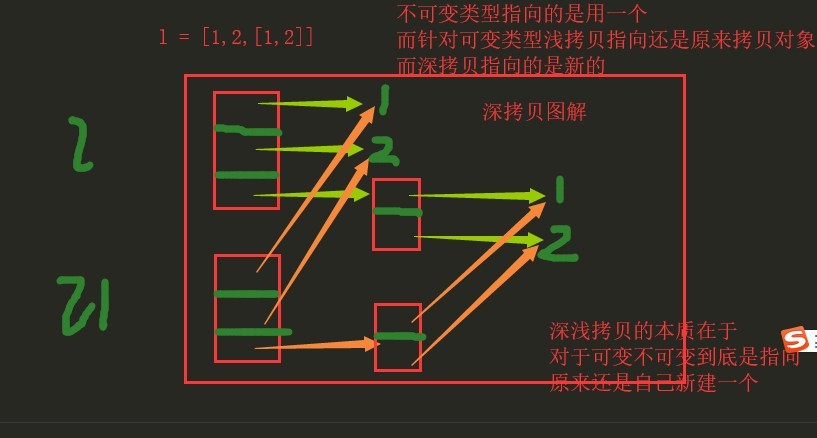
对于深copy来说,列表是在内存中重新创建的,列表中可变的数据类型是重新创建的,列表中的不可变的数据类型是公用的。
总结:深浅拷贝中,不可变的数据类型都是公用的,但在浅拷贝只是指向可变数据类型,而深拷贝则是完全新建一个。
python掉包侠与深浅拷贝的更多相关文章
- python学习笔记:深浅拷贝的使用和原理
在理解深浅拷贝之前,我们先熟悉下变量对象和数据类型 1.变量和对象 变量-引用-对象(可变对象,不可变对象) 在python中一切都是对象,比如[1,2],'hello world',123,{'k1 ...
- python之路(三)-深浅拷贝
深浅拷贝用法来自copy模块. 导入模块:import copy 浅拷贝:copy.copy 深拷贝:deepcopy 字面理解:浅拷贝指仅仅拷贝数据集合的第一层数据,深拷贝指拷贝数据集合的所有层.所 ...
- python变量存储和深浅拷贝
python的变量及其存储 在高级语言中,变量是对内存及其地址的抽象.对于python而言,python的一切变量都是对象,变量的存储,采用了引用语义的方式,存储的只是一个变量的值所在的内存地址,而不 ...
- python内存相关以及深浅拷贝讲解
3.9 内存相关 3.9.1 id,查看内存地址 >>> v1 = [11,22,33] >>> v2 = [11,22,33] >>> prin ...
- Python collection模块与深浅拷贝
collection模块是对Python的通用内置容器:字典.列表.元组和集合的扩展,它包含一些专业的容器数据类型: Counter(计数器):dict子类,用于计算可哈希性对象的个数. Ordere ...
- Python基础入门知识点——深浅拷贝
深浅拷贝 对象引用.浅拷贝.深拷贝(拓展.难点.重点) Python中,对象的赋值,拷贝(深/浅拷贝)之间是有差异的,如果使用的时候不注意,就可能产生意外的结果 其实这个是由于共享内存导致的结果 拷贝 ...
- 从零开始的Python学习Episode 8——深浅拷贝
深浅拷贝 一.浅拷贝 列表中存储的是数据的内存地址,当我们要查询或修改列表中的数据时,我们是通过列表中的地址找到要访问的内存.当我们修改列表中的数据时,如果修改的是一个不可变类型(整型,长整型,浮点数 ...
- python set集合 以及 深浅拷贝
set集合 特点: 无序, 不重复, 元素必须可哈希(不可变) 作用: 去重复 本身是可变的数据类型. 有增删改查操作. frozenset()冻结的集合. 不可变的. 可hash的 深浅拷贝() 1 ...
- python神坑系列之深浅拷贝
深浅拷贝 1.注意在拷贝中只有使用了.deepcopy方法才能进行深度拷贝!其余的一律是浅拷贝 #深拷贝import copy lst = copy.deepcopy(lst1) 浅拷贝: 拷贝的是 ...
随机推荐
- mysql数据库大规模数据读写并行时导致的锁表问题
问题介绍 最近在给学校做的一个项目中,有一个功能涉及到考核分数问题. 我当时一想,这个问题并不是很难,于是就直接采用了这样的方法:拿着一个表中的数据作为索引,去挨个遍历相关表中的数据,最后经过算分的过 ...
- Codeforce 370A Rook, Bishop and King 数学规律
这个题目挺有意思的,给定 起终点,要你求车,象,王分别最少要走多少步 车横竖都能走,而且每步任意走几格,所以它是最容易处理的,如果在同行或者同列,就是1,否则就是2 象要找下规律,象任意对角线都能走, ...
- LeetCode——739. 每日温度
根据每日 气温 列表,请重新生成一个列表,对应位置的输入是你需要再等待多久温度才会升高超过该日的天数.如果之后都不会升高,请在该位置用 0 来代替. 例如,给定一个列表 temperatures = ...
- 61)普通类的.h和.cpp分离
//标头.h文件 //这个是在C中这样写 #ifndef HH_01//开始写小写 hh_01 然后选中这个 crtl+shift+u 就变成大写了 #define HH_01 #endif //在C ...
- python3.x设置默认编码(sys.stdout.encoding和sys.defaultencoding)
查了一会资料得出的结论是如果你用的是python3.x,那么就最好别去设置sys.defaultencoding或者sys.stdout.encoding记住在需要编码的时候用encode,解码的时候 ...
- LGOJ1264 K-联赛
这题其实不难想到 Description link 题意太长了,概括不来,去题库里扫一眼吧(但是很好懂) Solution \[Begin\] 考虑一个事情:每一个队伍的输局是没有用的 贪心一下,让每 ...
- 【模式分解】无损连接&保持函数依赖
首先引入定义 无损分解指的是对关系模式分解时,原关系模型下任一合法的关系值在分解之后应能通过自然联接运算恢复起来.反之,则称为有损分解. 保持函数依赖的分解指的是对关系分解时,原关系的闭包与分解后关系 ...
- ae基础二
纯色文本操作快捷键:选中图层点击快捷键(变换)锚点:a(调节中心点)位置:p(左右移动)(利用位置k帧做动画)缩放:s(水平翻转垂直翻转)旋转:r(围绕中心点(锚点)进行旋转)不透明度:tu选中索引 ...
- Tensorflow学习教程------下载图像识别模型inceptionV3
# coding: utf-8 import tensorflow as tf import os import tarfile import requests #inception模型下载地址 in ...
- keras中保存自定义层和loss
在keras中保存模型有几种方式: (1):使用callbacks,可以保存训练中任意的模型,或选择最好的模型 logdir = './callbacks' if not os.path.exists ...