实用干货丨如何使用Prometheus配置自定义告警规则
前 言
Prometheus是一个用于监控和告警的开源系统。一开始由Soundcloud开发,后来在2016年,它迁移到CNCF并且称为Kubernetes之后最流行的项目之一。从整个Linux服务器到stand-alone web服务器、数据库服务或一个单独的进程,它都能监控。在Prometheus术语中,它所监控的事物称为目标(Target)。每个目标单元被称为指标(metric)。它以设置好的时间间隔通过http抓取目标,以收集指标并将数据放置在其时序数据库(Time Series Database)中。你可以使用PromQL查询语言查询相关target的指标。

本文中,我们将一步一步展示如何:
安装Prometheus(使用prometheus-operator Helm chart)以基于自定义事件进行监控/告警
创建和配置自定义告警规则,它将会在满足条件时发出告警
集成Alertmanager以处理由客户端应用程序(在本例中为Prometheus server)发送的告警
将Alertmanager与发送告警通知的邮件账户集成。
理解Prometheus及其抽象概念
从下图我们将看到所有组成Prometheus生态的组件:
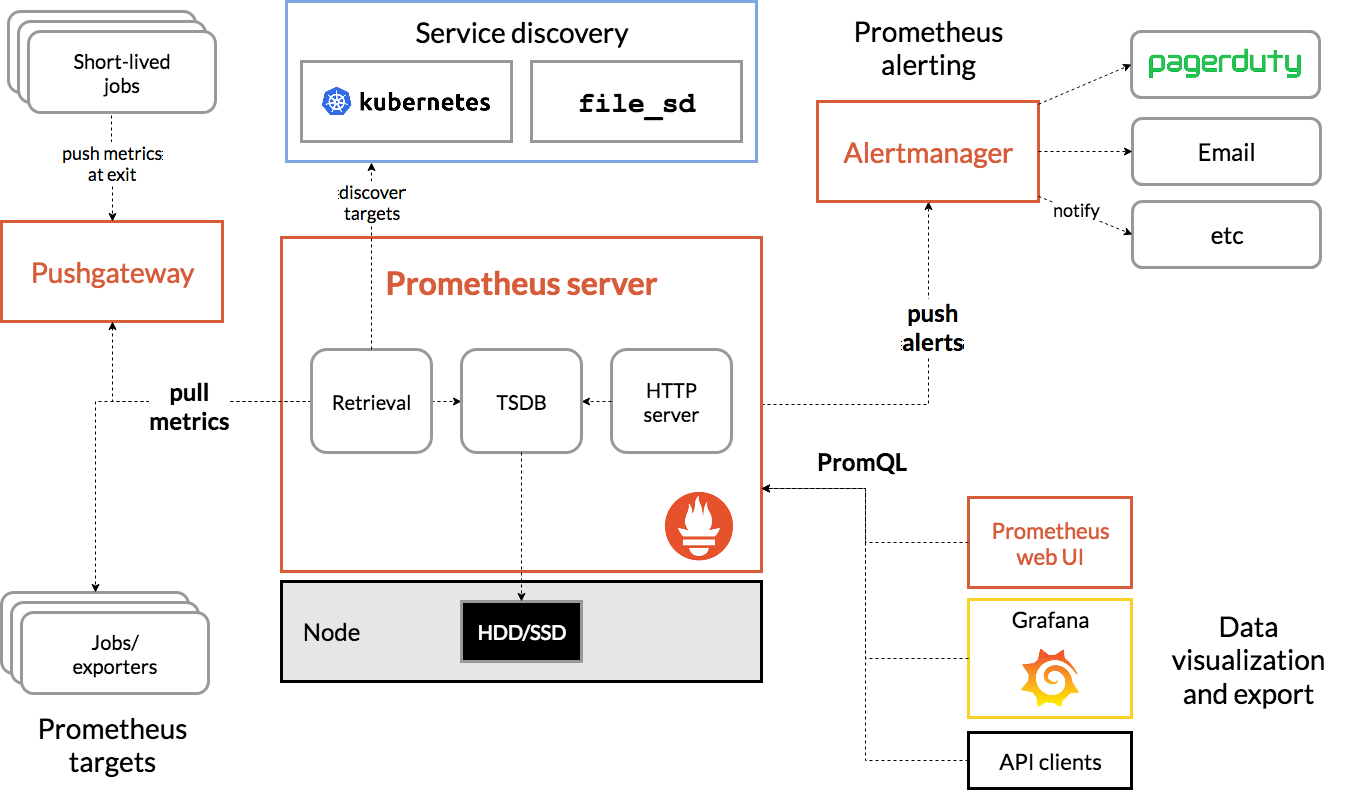
以下是与本文相关的术语,大家可以快速了解:
Prometheus Server:在时序数据库中抓取和存储指标的主要组件
抓取:一种拉取方法以获取指标。它通常以10-60秒的时间间隔抓取。
Target:检索数据的server客户端
服务发现:启用Prometheus,使其能够识别它需要监控的应用程序并在动态环境中拉取指标
Alert Manager:负责处理警报的组件(包括silencing、inhibition、聚合告警信息,并通过邮件、PagerDuty、Slack等方式发送告警通知)。
数据可视化:抓取的数据存储在本地存储中,并使用PromQL直接查询,或通过Grafana dashboard查看。
理解Prometheus Operator
根据Prometheus Operator的项目所有者CoreOS称,Prometheus Operator可以配置原生Kubernetes并且可以管理和操作Prometheus和Alertmanager集群。
该Operator引入了以下Kubernetes自定义资源定义(CRDs):Prometheus、ServiceMonitor、PrometheusRule和Alertmanager。如果你想了解更多内容可以访问链接:
https://github.com/coreos/prometheus-operator/blob/master/Documentation/design.md
在我们的演示中,我们将使用PrometheusRule来定义自定义规则。
首先,我们需要使用 stable/prometheus-operator Helm chart来安装Prometheus Operator,下载链接:
https://github.com/helm/charts/tree/master/stable/prometheus-operator
默认安装程序将会部署以下组件:prometheus-operator、prometheus、alertmanager、node-exporter、kube-state-metrics以及grafana。默认状态下,Prometheus将会抓取Kubernetes的主要组件:kube-apiserver、kube-controller-manager以及etcd。
安装Prometheus软件
前期准备
要顺利执行此次demo,你需要准备以下内容:
一个Google Cloud Platform账号(免费套餐即可)。其他任意云也可以
Rancher v2.3.5(发布文章时的最新版本)
运行在GKE(版本1.15.9-gke.12.)上的Kubernetes集群(使用EKS或AKS也可以)
在计算机上安装好Helm binary
启动一个Rancher实例
直接按照这一直观的入门指南进行操作即可:
https://rancher.com/quick-start
使用Rancher部署一个GKE集群
使用Rancher来设置和配置你的Kubernetes集群:
https://rancher.com/docs/rancher/v2.x/en/cluster-provisioning/hosted-kubernetes-clusters/gke/
部署完成后,并且为kubeconfig文件配置了适当的credential和端点信息,就可以使用kubectl指向该特定集群。
部署Prometheus 软件
首先,检查一下我们所运行的Helm版本
$ helm version
version.BuildInfo{Version:"v3.1.2", GitCommit:"d878d4d45863e42fd5cff6743294a11d28a9abce", GitTreeState:"clean", GoVersion:"go1.13.8"}
当我们使用Helm 3时,我们需要添加一个stable 镜像仓库,因为默认状态下不会设置该仓库。
$ helm repo add stable https://kubernetes-charts.storage.googleapis.com
"stable" has been added to your repositories
$ helm repo update
Hang tight while we grab the latest from your chart repositories...
...Successfully got an update from the "stable" chart repository
Update Complete. ⎈ Happy Helming!⎈
$ helm repo list
NAME URL
stable https://kubernetes-charts.storage.googleapis.com
Helm配置完成后,我们可以开始安装prometheus-operator
$ kubectl create namespace monitoring
namespace/monitoring created
$ helm install --namespace monitoring demo stable/prometheus-operator
manifest_sorter.go:192: info: skipping unknown hook: "crd-install"
manifest_sorter.go:192: info: skipping unknown hook: "crd-install"
manifest_sorter.go:192: info: skipping unknown hook: "crd-install"
manifest_sorter.go:192: info: skipping unknown hook: "crd-install"
manifest_sorter.go:192: info: skipping unknown hook: "crd-install"
manifest_sorter.go:192: info: skipping unknown hook: "crd-install"
NAME: demo
LAST DEPLOYED: Sat Mar 14 09:40:35 2020
NAMESPACE: monitoring
STATUS: deployed
REVISION: 1
NOTES:
The Prometheus Operator has been installed. Check its status by running:
kubectl --namespace monitoring get pods -l "release=demo"
Visit https://github.com/coreos/prometheus-operator for instructions on how
to create & configure Alertmanager and Prometheus instances using the Operator.
规 则
除了监控之外,Prometheus还让我们创建触发告警的规则。这些规则基于Prometheus的表达式语言。只要满足条件,就会触发告警并将其发送到Alertmanager。之后,我们会看到规则的具体形式。
我们回到demo。Helm完成部署之后,我们可以检查已经创建了什么pod:
$ kubectl -n monitoring get pods
NAME READY STATUS RESTARTS AGE
alertmanager-demo-prometheus-operator-alertmanager-0 2/2 Running 0 61s
demo-grafana-5576fbf669-9l57b 3/3 Running 0 72s
demo-kube-state-metrics-67bf64b7f4-4786k 1/1 Running 0 72s
demo-prometheus-node-exporter-ll8zx 1/1 Running 0 72s
demo-prometheus-node-exporter-nqnr6 1/1 Running 0 72s
demo-prometheus-node-exporter-sdndf 1/1 Running 0 72s
demo-prometheus-operator-operator-b9c9b5457-db9dj 2/2 Running 0 72s
prometheus-demo-prometheus-operator-prometheus-0 3/3 Running 1 50s
为了从web浏览器中访问Prometheus和Alertmanager,我们需要使用port转发。
由于本例中使用的是GCP实例,并且所有的kubectl命令都从该实例运行,因此我们使用实例的外部IP地址访问资源。
$ kubectl port-forward --address 0.0.0.0 -n monitoring prometheus-demo-prometheus-operator-prometheus-0 9090 >/dev/null 2>&1 &
$ kubectl port-forward --address 0.0.0.0 -n monitoring alertmanager-demo-prometheus-operator-alertmanager-0 9093 >/dev/null 2>&1 &
“Alert”选项卡向我们展示了所有当前正在运行/已配置的告警。也可以通过查询名称为prometheusrules的CRD从CLI进行检查:
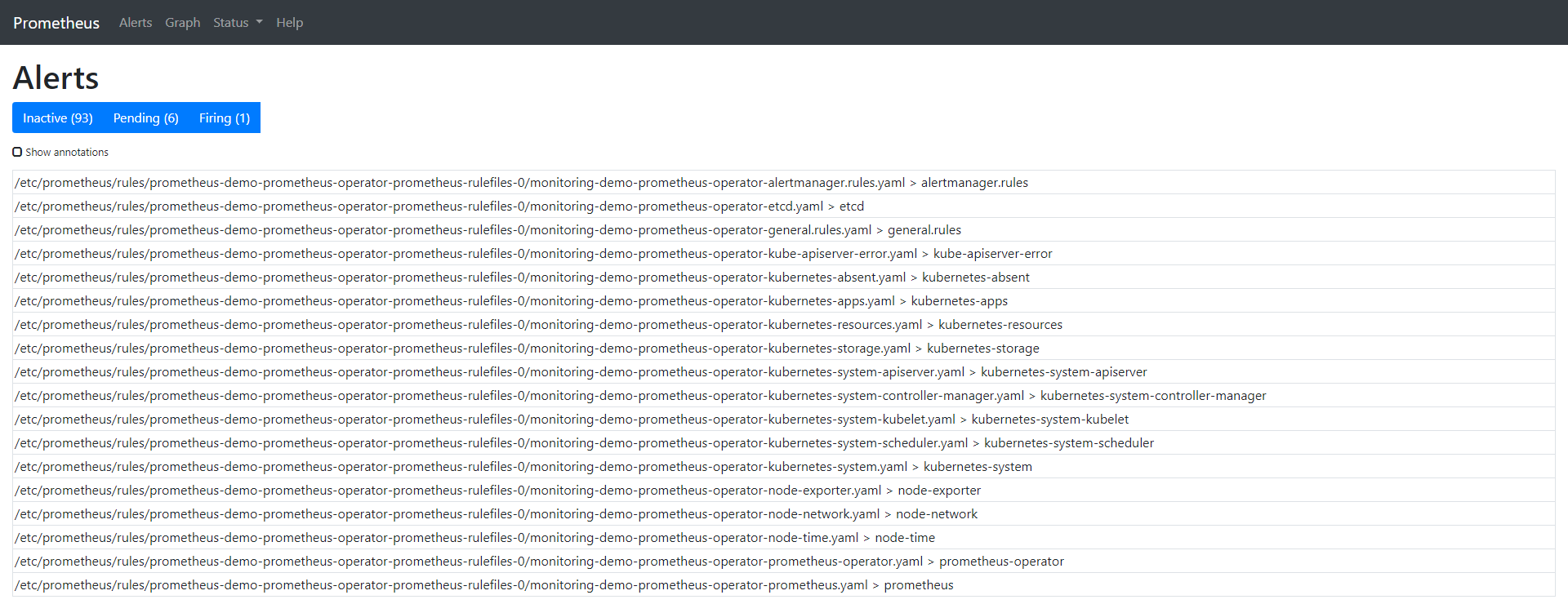
$ kubectl -n monitoring get prometheusrules
NAME AGE
demo-prometheus-operator-alertmanager.rules 3m21s
demo-prometheus-operator-etcd 3m21s
demo-prometheus-operator-general.rules 3m21s
demo-prometheus-operator-k8s.rules 3m21s
demo-prometheus-operator-kube-apiserver-error 3m21s
demo-prometheus-operator-kube-apiserver.rules 3m21s
demo-prometheus-operator-kube-prometheus-node-recording.rules 3m21s
demo-prometheus-operator-kube-scheduler.rules 3m21s
demo-prometheus-operator-kubernetes-absent 3m21s
demo-prometheus-operator-kubernetes-apps 3m21s
demo-prometheus-operator-kubernetes-resources 3m21s
demo-prometheus-operator-kubernetes-storage 3m21s
demo-prometheus-operator-kubernetes-system 3m21s
demo-prometheus-operator-kubernetes-system-apiserver 3m21s
demo-prometheus-operator-kubernetes-system-controller-manager 3m21s
demo-prometheus-operator-kubernetes-system-kubelet 3m21s
demo-prometheus-operator-kubernetes-system-scheduler 3m21s
demo-prometheus-operator-node-exporter 3m21s
demo-prometheus-operator-node-exporter.rules 3m21s
demo-prometheus-operator-node-network 3m21s
demo-prometheus-operator-node-time 3m21s
demo-prometheus-operator-node.rules 3m21s
demo-prometheus-operator-prometheus 3m21s
demo-prometheus-operator-prometheus-operator 3m21s
我们也可以检查位于prometheus容器中prometheus-operator Pod中的物理文件。
$ kubectl -n monitoring exec -it prometheus-demo-prometheus-operator-prometheus-0 -- /bin/sh
Defaulting container name to prometheus.
Use 'kubectl describe pod/prometheus-demo-prometheus-operator-prometheus-0 -n monitoring' to see all of the containers in this pod.
在容器中,我们可以检查规则的存储路径:
/prometheus $ ls /etc/prometheus/rules/prometheus-demo-prometheus-operator-prometheus-rulefiles-0/
monitoring-demo-prometheus-operator-alertmanager.rules.yaml monitoring-demo-prometheus-operator-kubernetes-system-apiserver.yaml
monitoring-demo-prometheus-operator-etcd.yaml monitoring-demo-prometheus-operator-kubernetes-system-controller-manager.yaml
monitoring-demo-prometheus-operator-general.rules.yaml monitoring-demo-prometheus-operator-kubernetes-system-kubelet.yaml
monitoring-demo-prometheus-operator-k8s.rules.yaml monitoring-demo-prometheus-operator-kubernetes-system-scheduler.yaml
monitoring-demo-prometheus-operator-kube-apiserver-error.yaml monitoring-demo-prometheus-operator-kubernetes-system.yaml
monitoring-demo-prometheus-operator-kube-apiserver.rules.yaml monitoring-demo-prometheus-operator-node-exporter.rules.yaml
monitoring-demo-prometheus-operator-kube-prometheus-node-recording.rules.yaml monitoring-demo-prometheus-operator-node-exporter.yaml
monitoring-demo-prometheus-operator-kube-scheduler.rules.yaml monitoring-demo-prometheus-operator-node-network.yaml
monitoring-demo-prometheus-operator-kubernetes-absent.yaml monitoring-demo-prometheus-operator-node-time.yaml
monitoring-demo-prometheus-operator-kubernetes-apps.yaml monitoring-demo-prometheus-operator-node.rules.yaml
monitoring-demo-prometheus-operator-kubernetes-resources.yaml monitoring-demo-prometheus-operator-prometheus-operator.yaml
monitoring-demo-prometheus-operator-kubernetes-storage.yaml monitoring-demo-prometheus-operator-prometheus.yaml
为了详细了解如何将这些规则加载到Prometheus中,请检查Pod的详细信息。我们可以看到用于prometheus容器的配置文件是etc/prometheus/config_out/prometheus.env.yaml。该配置文件向我们展示了文件的位置或重新检查yaml的频率设置。
$ kubectl -n monitoring describe pod prometheus-demo-prometheus-operator-prometheus-0
完整命令输出如下:
Name: prometheus-demo-prometheus-operator-prometheus-0
Namespace: monitoring
Priority: 0
Node: gke-c-7dkls-default-0-c6ca178a-gmcq/10.132.0.15
Start Time: Wed, 11 Mar 2020 18:06:47 +0000
Labels: app=prometheus
controller-revision-hash=prometheus-demo-prometheus-operator-prometheus-5ccbbd8578
prometheus=demo-prometheus-operator-prometheus
statefulset.kubernetes.io/pod-name=prometheus-demo-prometheus-operator-prometheus-0
Annotations: <none>
Status: Running
IP: 10.40.0.7
IPs: <none>
Controlled By: StatefulSet/prometheus-demo-prometheus-operator-prometheus
Containers:
prometheus:
Container ID: docker://360db8a9f1cce8d72edd81fcdf8c03fe75992e6c2c59198b89807aa0ce03454c
Image: quay.io/prometheus/prometheus:v2.15.2
Image ID: docker-pullable://quay.io/prometheus/prometheus@sha256:914525123cf76a15a6aaeac069fcb445ce8fb125113d1bc5b15854bc1e8b6353
Port: 9090/TCP
Host Port: 0/TCP
Args:
--web.console.templates=/etc/prometheus/consoles
--web.console.libraries=/etc/prometheus/console_libraries
--config.file=/etc/prometheus/config_out/prometheus.env.yaml
--storage.tsdb.path=/prometheus
--storage.tsdb.retention.time=10d
--web.enable-lifecycle
--storage.tsdb.no-lockfile
--web.external-url=http://demo-prometheus-operator-prometheus.monitoring:9090
--web.route-prefix=/
State: Running
Started: Wed, 11 Mar 2020 18:07:07 +0000
Last State: Terminated
Reason: Error
Message: caller=main.go:648 msg="Starting TSDB ..."
level=info ts=2020-03-11T18:07:02.185Z caller=web.go:506 component=web msg="Start listening for connections" address=0.0.0.0:9090
level=info ts=2020-03-11T18:07:02.192Z caller=head.go:584 component=tsdb msg="replaying WAL, this may take awhile"
level=info ts=2020-03-11T18:07:02.192Z caller=head.go:632 component=tsdb msg="WAL segment loaded" segment=0 maxSegment=0
level=info ts=2020-03-11T18:07:02.194Z caller=main.go:663 fs_type=EXT4_SUPER_MAGIC
level=info ts=2020-03-11T18:07:02.194Z caller=main.go:664 msg="TSDB started"
level=info ts=2020-03-11T18:07:02.194Z caller=main.go:734 msg="Loading configuration file" filename=/etc/prometheus/config_out/prometheus.env.yaml
level=info ts=2020-03-11T18:07:02.194Z caller=main.go:517 msg="Stopping scrape discovery manager..."
level=info ts=2020-03-11T18:07:02.194Z caller=main.go:531 msg="Stopping notify discovery manager..."
level=info ts=2020-03-11T18:07:02.194Z caller=main.go:553 msg="Stopping scrape manager..."
level=info ts=2020-03-11T18:07:02.194Z caller=manager.go:814 component="rule manager" msg="Stopping rule manager..."
level=info ts=2020-03-11T18:07:02.194Z caller=manager.go:820 component="rule manager" msg="Rule manager stopped"
level=info ts=2020-03-11T18:07:02.194Z caller=main.go:513 msg="Scrape discovery manager stopped"
level=info ts=2020-03-11T18:07:02.194Z caller=main.go:527 msg="Notify discovery manager stopped"
level=info ts=2020-03-11T18:07:02.194Z caller=main.go:547 msg="Scrape manager stopped"
level=info ts=2020-03-11T18:07:02.197Z caller=notifier.go:598 component=notifier msg="Stopping notification manager..."
level=info ts=2020-03-11T18:07:02.197Z caller=main.go:718 msg="Notifier manager stopped"
level=error ts=2020-03-11T18:07:02.197Z caller=main.go:727 err="error loading config from \"/etc/prometheus/config_out/prometheus.env.yaml\": couldn't load configuration (--config.file=\"/etc/prometheus/config_out/prometheus.env.yaml\"): open /etc/prometheus/config_out/prometheus.env.yaml: no such file or directory"
Exit Code: 1
Started: Wed, 11 Mar 2020 18:07:02 +0000
Finished: Wed, 11 Mar 2020 18:07:02 +0000
Ready: True
Restart Count: 1
Liveness: http-get http://:web/-/healthy delay=0s timeout=3s period=5s #success=1 #failure=6
Readiness: http-get http://:web/-/ready delay=0s timeout=3s period=5s #success=1 #failure=120
Environment: <none>
Mounts:
/etc/prometheus/certs from tls-assets (ro)
/etc/prometheus/config_out from config-out (ro)
/etc/prometheus/rules/prometheus-demo-prometheus-operator-prometheus-rulefiles-0 from prometheus-demo-prometheus-operator-prometheus-rulefiles-0 (rw)
/prometheus from prometheus-demo-prometheus-operator-prometheus-db (rw)
/var/run/secrets/kubernetes.io/serviceaccount from demo-prometheus-operator-prometheus-token-jvbrr (ro)
prometheus-config-reloader:
Container ID: docker://de27cdad7067ebd5154c61b918401b2544299c161850daf3e317311d2d17af3d
Image: quay.io/coreos/prometheus-config-reloader:v0.37.0
Image ID: docker-pullable://quay.io/coreos/prometheus-config-reloader@sha256:5e870e7a99d55a5ccf086063efd3263445a63732bc4c04b05cf8b664f4d0246e
Port: <none>
Host Port: <none>
Command:
/bin/prometheus-config-reloader
Args:
--log-format=logfmt
--reload-url=http://127.0.0.1:9090/-/reload
--config-file=/etc/prometheus/config/prometheus.yaml.gz
--config-envsubst-file=/etc/prometheus/config_out/prometheus.env.yaml
State: Running
Started: Wed, 11 Mar 2020 18:07:04 +0000
Ready: True
Restart Count: 0
Limits:
cpu: 100m
memory: 25Mi
Requests:
cpu: 100m
memory: 25Mi
Environment:
POD_NAME: prometheus-demo-prometheus-operator-prometheus-0 (v1:metadata.name)
Mounts:
/etc/prometheus/config from config (rw)
/etc/prometheus/config_out from config-out (rw)
/var/run/secrets/kubernetes.io/serviceaccount from demo-prometheus-operator-prometheus-token-jvbrr (ro)
rules-configmap-reloader:
Container ID: docker://5804e45380ed1b5374a4c2c9ee4c9c4e365bee93b9ccd8b5a21f50886ea81a91
Image: quay.io/coreos/configmap-reload:v0.0.1
Image ID: docker-pullable://quay.io/coreos/configmap-reload@sha256:e2fd60ff0ae4500a75b80ebaa30e0e7deba9ad107833e8ca53f0047c42c5a057
Port: <none>
Host Port: <none>
Args:
--webhook-url=http://127.0.0.1:9090/-/reload
--volume-dir=/etc/prometheus/rules/prometheus-demo-prometheus-operator-prometheus-rulefiles-0
State: Running
Started: Wed, 11 Mar 2020 18:07:06 +0000
Ready: True
Restart Count: 0
Limits:
cpu: 100m
memory: 25Mi
Requests:
cpu: 100m
memory: 25Mi
Environment: <none>
Mounts:
/etc/prometheus/rules/prometheus-demo-prometheus-operator-prometheus-rulefiles-0 from prometheus-demo-prometheus-operator-prometheus-rulefiles-0 (rw)
/var/run/secrets/kubernetes.io/serviceaccount from demo-prometheus-operator-prometheus-token-jvbrr (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
config:
Type: Secret (a volume populated by a Secret)
SecretName: prometheus-demo-prometheus-operator-prometheus
Optional: false
tls-assets:
Type: Secret (a volume populated by a Secret)
SecretName: prometheus-demo-prometheus-operator-prometheus-tls-assets
Optional: false
config-out:
Type: EmptyDir (a temporary directory that shares a pod's lifetime)
Medium:
SizeLimit: <unset>
prometheus-demo-prometheus-operator-prometheus-rulefiles-0:
Type: ConfigMap (a volume populated by a ConfigMap)
Name: prometheus-demo-prometheus-operator-prometheus-rulefiles-0
Optional: false
prometheus-demo-prometheus-operator-prometheus-db:
Type: EmptyDir (a temporary directory that shares a pod's lifetime)
Medium:
SizeLimit: <unset>
demo-prometheus-operator-prometheus-token-jvbrr:
Type: Secret (a volume populated by a Secret)
SecretName: demo-prometheus-operator-prometheus-token-jvbrr
Optional: false
QoS Class: Burstable
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s
node.kubernetes.io/unreachable:NoExecute for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 4m51s default-scheduler Successfully assigned monitoring/prometheus-demo-prometheus-operator-prometheus-0 to gke-c-7dkls-default-0-c6ca178a-gmcq
Normal Pulling 4m45s kubelet, gke-c-7dkls-default-0-c6ca178a-gmcq Pulling image "quay.io/prometheus/prometheus:v2.15.2"
Normal Pulled 4m39s kubelet, gke-c-7dkls-default-0-c6ca178a-gmcq Successfully pulled image "quay.io/prometheus/prometheus:v2.15.2"
Normal Pulling 4m36s kubelet, gke-c-7dkls-default-0-c6ca178a-gmcq Pulling image "quay.io/coreos/prometheus-config-reloader:v0.37.0"
Normal Pulled 4m35s kubelet, gke-c-7dkls-default-0-c6ca178a-gmcq Successfully pulled image "quay.io/coreos/prometheus-config-reloader:v0.37.0"
Normal Pulling 4m34s kubelet, gke-c-7dkls-default-0-c6ca178a-gmcq Pulling image "quay.io/coreos/configmap-reload:v0.0.1"
Normal Started 4m34s kubelet, gke-c-7dkls-default-0-c6ca178a-gmcq Started container prometheus-config-reloader
Normal Created 4m34s kubelet, gke-c-7dkls-default-0-c6ca178a-gmcq Created container prometheus-config-reloader
Normal Pulled 4m33s kubelet, gke-c-7dkls-default-0-c6ca178a-gmcq Successfully pulled image "quay.io/coreos/configmap-reload:v0.0.1"
Normal Created 4m32s (x2 over 4m36s) kubelet, gke-c-7dkls-default-0-c6ca178a-gmcq Created container prometheus
Normal Created 4m32s kubelet, gke-c-7dkls-default-0-c6ca178a-gmcq Created container rules-configmap-reloader
Normal Started 4m32s kubelet, gke-c-7dkls-default-0-c6ca178a-gmcq Started container rules-configmap-reloader
Normal Pulled 4m32s kubelet, gke-c-7dkls-default-0-c6ca178a-gmcq Container image "quay.io/prometheus/prometheus:v2.15.2" already present on machine
Normal Started 4m31s (x2 over 4m36s) kubelet, gke-c-7dkls-default-0-c6ca178a-gmcq Started container prometheus
让我们清理默认规则,使得我们可以更好地观察我们将要创建的那个规则。以下命令将删除所有规则,但会留下monitoring-demo-prometheus-operator-alertmanager.rules。
$ kubectl -n monitoring delete prometheusrules $(kubectl -n monitoring get prometheusrules | grep -v alert)
$ kubectl -n monitoring get prometheusrules
NAME AGE
demo-prometheus-operator-alertmanager.rules 8m53s
请注意:我们只保留一条规则是为了让demo更容易。但是有一条规则,你绝对不能删除,它位于monitoring-demo-prometheus-operator-general.rules.yaml中,被称为看门狗。该告警总是处于触发状态,其目的是确保整个告警流水线正常运转。
让我们从CLI中检查我们留下的规则并将其与我们将在浏览器中看到的进行比较。
$ kubectl -n monitoring describe prometheusrule demo-prometheus-operator-alertmanager.rules
Name: demo-prometheus-operator-alertmanager.rules
Namespace: monitoring
Labels: app=prometheus-operator
chart=prometheus-operator-8.12.1
heritage=Tiller
release=demo
Annotations: prometheus-operator-validated: true
API Version: monitoring.coreos.com/v1
Kind: PrometheusRule
Metadata:
Creation Timestamp: 2020-03-11T18:06:25Z
Generation: 1
Resource Version: 4871
Self Link: /apis/monitoring.coreos.com/v1/namespaces/monitoring/prometheusrules/demo-prometheus-operator-alertmanager.rules
UID: 6a84dbb0-feba-4f17-b3dc-4b6486818bc0
Spec:
Groups:
Name: alertmanager.rules
Rules:
Alert: AlertmanagerConfigInconsistent
Annotations:
Message: The configuration of the instances of the Alertmanager cluster `{{$labels.service}}` are out of sync.
Expr: count_values("config_hash", alertmanager_config_hash{job="demo-prometheus-operator-alertmanager",namespace="monitoring"}) BY (service) / ON(service) GROUP_LEFT() label_replace(max(prometheus_operator_spec_replicas{job="demo-prometheus-operator-operator",namespace="monitoring",controller="alertmanager"}) by (name, job, namespace, controller), "service", "$1", "name", "(.*)") != 1
For: 5m
Labels:
Severity: critical
Alert: AlertmanagerFailedReload
Annotations:
Message: Reloading Alertmanager's configuration has failed for {{ $labels.namespace }}/{{ $labels.pod}}.
Expr: alertmanager_config_last_reload_successful{job="demo-prometheus-operator-alertmanager",namespace="monitoring"} == 0
For: 10m
Labels:
Severity: warning
Alert: AlertmanagerMembersInconsistent
Annotations:
Message: Alertmanager has not found all other members of the cluster.
Expr: alertmanager_cluster_members{job="demo-prometheus-operator-alertmanager",namespace="monitoring"}
!= on (service) GROUP_LEFT()
count by (service) (alertmanager_cluster_members{job="demo-prometheus-operator-alertmanager",namespace="monitoring"})
For: 5m
Labels:
Severity: critical
Events: <none>
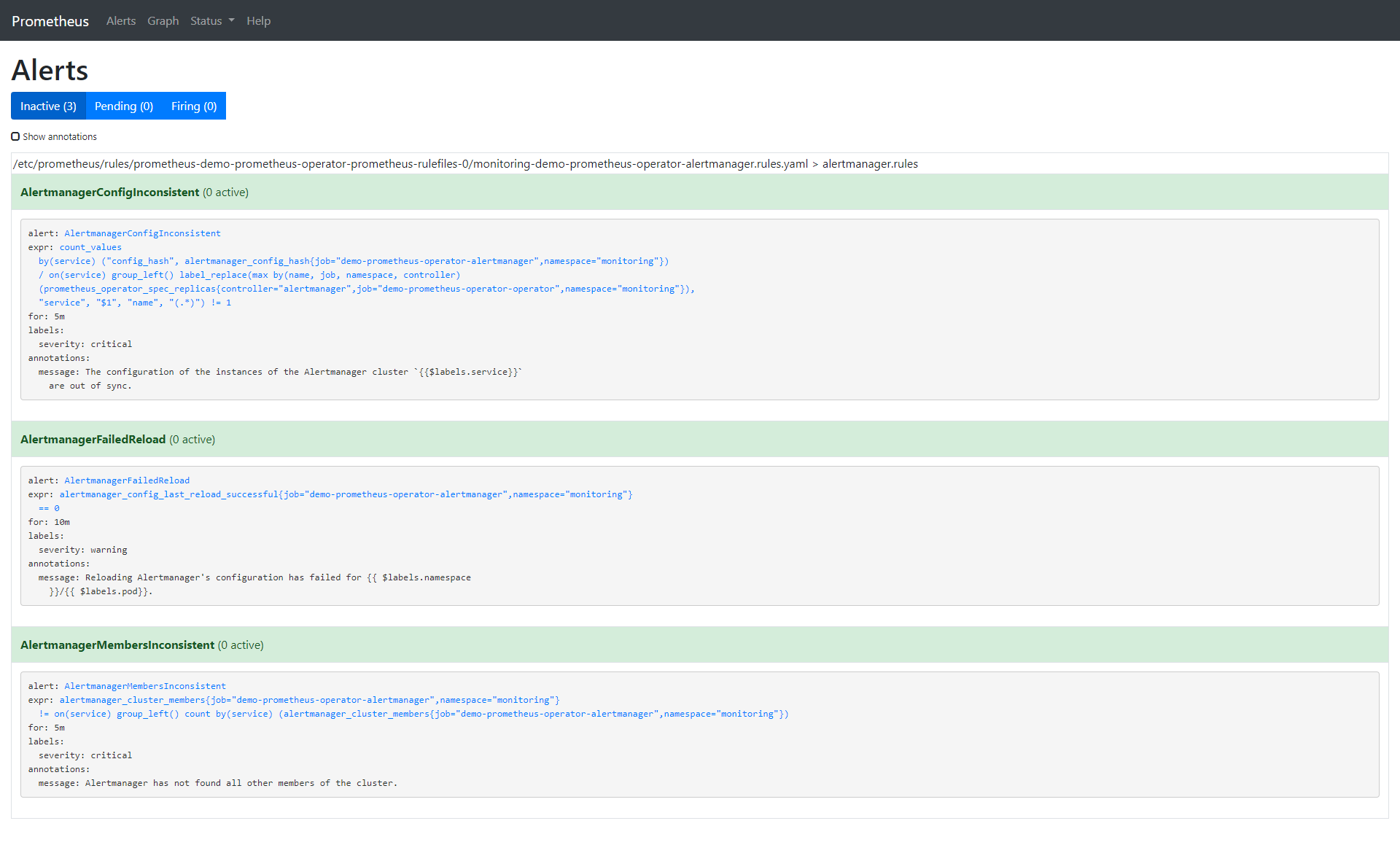
让我们移除所有默认告警并创建一个我们自己的告警:
$ kubectl -n monitoring edit prometheusrules demo-prometheus-operator-alertmanager.rules
prometheusrule.monitoring.coreos.com/demo-prometheus-operator-alertmanager.rules edited
我们的自定义告警如下所示:
$ kubectl -n monitoring describe prometheusrule demo-prometheus-operator-alertmanager.rules
Name: demo-prometheus-operator-alertmanager.rules
Namespace: monitoring
Labels: app=prometheus-operator
chart=prometheus-operator-8.12.1
heritage=Tiller
release=demo
Annotations: prometheus-operator-validated: true
API Version: monitoring.coreos.com/v1
Kind: PrometheusRule
Metadata:
Creation Timestamp: 2020-03-11T18:06:25Z
Generation: 3
Resource Version: 18180
Self Link: /apis/monitoring.coreos.com/v1/namespaces/monitoring/prometheusrules/demo-prometheus-operator-alertmanager.rules
UID: 6a84dbb0-feba-4f17-b3dc-4b6486818bc0
Spec:
Groups:
Name: alertmanager.rules
Rules:
Alert: PodHighCpuLoad
Annotations:
Message: Alertmanager has found {{ $labels.instance }} with CPU too high
Expr: rate (container_cpu_usage_seconds_total{pod_name=~"nginx-.*", image!="", container!="POD"}[5m]) > 0.04
For: 1m
Labels:
Severity: critical
Events: <none>
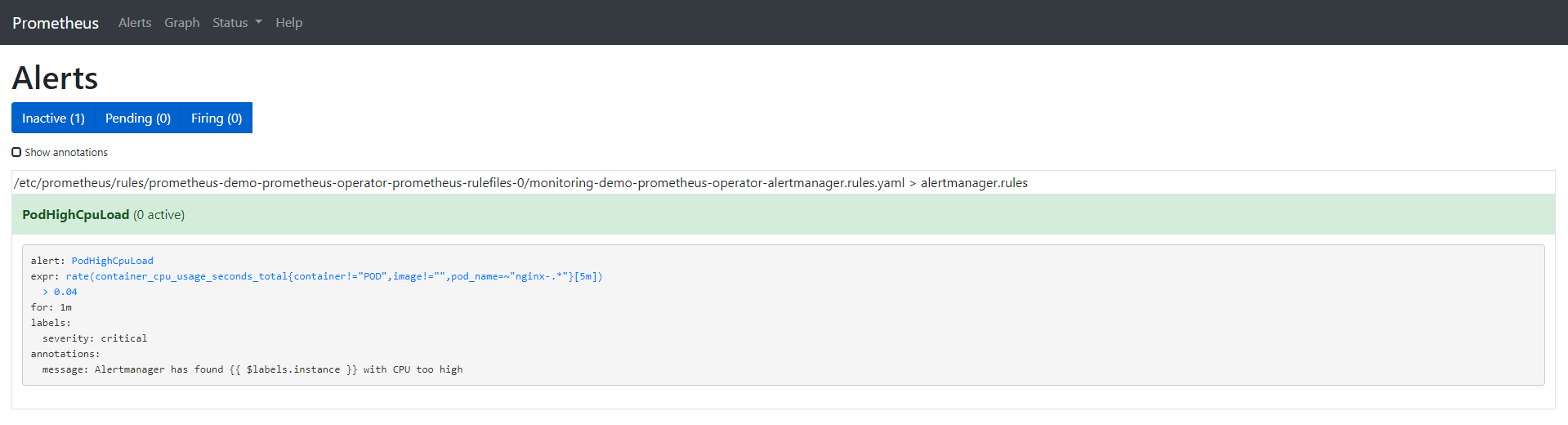
以下是我们创建的告警的选项:
annotation:描述告警的信息标签集。
expr:由PromQL写的表达式
for:可选参数,设置了之后会告诉Prometheus在定义的时间段内告警是否处于active状态。仅在此定义时间后才会触发告警。
label:可以附加到告警的额外标签。如果你想了解更多关于告警的信息,可以访问:
https://prometheus.io/docs/prometheus/latest/configuration/alerting_rules/
现在我们已经完成了Prometheus告警的设置,让我们配置Alertmanager,使得我们能够通过电子邮件获得告警通知。Alertmanager的配置位于Kubernetes secret对象中。
$ kubectl get secrets -n monitoring
NAME TYPE DATA AGE
alertmanager-demo-prometheus-operator-alertmanager Opaque 1 32m
default-token-x4rgq kubernetes.io/service-account-token 3 37m
demo-grafana Opaque 3 32m
demo-grafana-test-token-p6qnk kubernetes.io/service-account-token 3 32m
demo-grafana-token-ff6nl kubernetes.io/service-account-token 3 32m
demo-kube-state-metrics-token-vmvbr kubernetes.io/service-account-token 3 32m
demo-prometheus-node-exporter-token-wlnk9 kubernetes.io/service-account-token 3 32m
demo-prometheus-operator-admission Opaque 3 32m
demo-prometheus-operator-alertmanager-token-rrx4k kubernetes.io/service-account-token 3 32m
demo-prometheus-operator-operator-token-q9744 kubernetes.io/service-account-token 3 32m
demo-prometheus-operator-prometheus-token-jvbrr kubernetes.io/service-account-token 3 32m
prometheus-demo-prometheus-operator-prometheus Opaque 1 31m
prometheus-demo-prometheus-operator-prometheus-tls-assets Opaque 0 31m
我们只对alertmanager-demo-prometheus-operator-alertmanager感兴趣。让我们看一下:
kubectl -n monitoring get secret alertmanager-demo-prometheus-operator-alertmanager -o yaml
apiVersion: v1
data:
alertmanager.yaml: Z2xvYmFsOgogIHJlc29sdmVfdGltZW91dDogNW0KcmVjZWl2ZXJzOgotIG5hbWU6ICJudWxsIgpyb3V0ZToKICBncm91cF9ieToKICAtIGpvYgogIGdyb3VwX2ludGVydmFsOiA1bQogIGdyb3VwX3dhaXQ6IDMwcwogIHJlY2VpdmVyOiAibnVsbCIKICByZXBlYXRfaW50ZXJ2YWw6IDEyaAogIHJvdXRlczoKICAtIG1hdGNoOgogICAgICBhbGVydG5hbWU6IFdhdGNoZG9nCiAgICByZWNlaXZlcjogIm51bGwiCg==
kind: Secret
metadata:
creationTimestamp: "2020-03-11T18:06:24Z"
labels:
app: prometheus-operator-alertmanager
chart: prometheus-operator-8.12.1
heritage: Tiller
release: demo
name: alertmanager-demo-prometheus-operator-alertmanager
namespace: monitoring
resourceVersion: "3018"
selfLink: /api/v1/namespaces/monitoring/secrets/alertmanager-demo-prometheus-operator-alertmanager
uid: 6baf6883-f690-47a1-bb49-491935956c22
type: Opaque
alertmanager.yaml字段是由base64编码的,让我们看看:
$ echo 'Z2xvYmFsOgogIHJlc29sdmVfdGltZW91dDogNW0KcmVjZWl2ZXJzOgotIG5hbWU6ICJudWxsIgpyb3V0ZToKICBncm91cF9ieToKICAtIGpvYgogIGdyb3VwX2ludGVydmFsOiA1bQogIGdyb3VwX3dhaXQ6IDMwcwogIHJlY2VpdmVyOiAibnVsbCIKICByZXBlYXRfaW50ZXJ2YWw6IDEyaAogIHJvdXRlczoKICAtIG1hdGNoOgogICAgICBhbGVydG5hbWU6IFdhdGNoZG9nCiAgICByZWNlaXZlcjogIm51bGwiCg==' | base64 --decode
global:
resolve_timeout: 5m
receivers:
- name: "null"
route:
group_by:
- job
group_interval: 5m
group_wait: 30s
receiver: "null"
repeat_interval: 12h
routes:
- match:
alertname: Watchdog
receiver: "null"
正如我们所看到的,这是默认的Alertmanager配置。你也可以在Alertmanager UI的Status选项卡中查看此配置。接下来,我们来对它进行一些更改——在本例中为发送邮件:
$ cat alertmanager.yaml
global:
resolve_timeout: 5m
route:
group_by: [Alertname]
# Send all notifications to me.
receiver: demo-alert
group_wait: 30s
group_interval: 5m
repeat_interval: 12h
routes:
- match:
alertname: DemoAlertName
receiver: 'demo-alert'
receivers:
- name: demo-alert
email_configs:
- to: your_email@gmail.com
from: from_email@gmail.com
# Your smtp server address
smarthost: smtp.gmail.com:587
auth_username: from_email@gmail.com
auth_identity: from_email@gmail.com
auth_password: 16letter_generated token # you can use gmail account password, but better create a dedicated token for this
headers:
From: from_email@gmail.com
Subject: 'Demo ALERT'
首先,我们需要对此进行编码:
$ cat alertmanager.yaml | base64 -w0
我们获得编码输出后,我们需要在我们将要应用的yaml文件中填写它:
cat alertmanager-secret-k8s.yaml
apiVersion: v1
data:
alertmanager.yaml: <paste here de encoded content of alertmanager.yaml>
kind: Secret
metadata:
name: alertmanager-demo-prometheus-operator-alertmanager
namespace: monitoring
type: Opaque
$ kubectl apply -f alertmanager-secret-k8s.yaml
Warning: kubectl apply should be used on resource created by either kubectl create --save-config or kubectl apply
secret/alertmanager-demo-prometheus-operator-alertmanager configured
该配置将会自动重新加载并在UI中显示更改。
接下来,我们部署一些东西来对其进行监控。对于本例而言,一个简单的nginx deployment已经足够:
$ cat nginx-deployment.yaml
apiVersion: apps/v1 # for versions before 1.9.0 use apps/v1beta2
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 3 # tells deployment to run 2 pods matching the template
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
$ kubectl apply -f nginx-deployment.yaml
deployment.apps/nginx-deployment created
根据配置yaml,我们有3个副本:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-deployment-5754944d6c-7g6gq 1/1 Running 0 67s
nginx-deployment-5754944d6c-lhvx8 1/1 Running 0 67s
nginx-deployment-5754944d6c-whhtr 1/1 Running 0 67s
在Prometheus UI中,使用我们为告警配置的相同表达式:
rate (container_cpu_usage_seconds_total{pod_name=~"nginx-.*", image!="", container!="POD"}[5m])
我们可以为这些Pod检查数据,所有Pod的值应该为0。
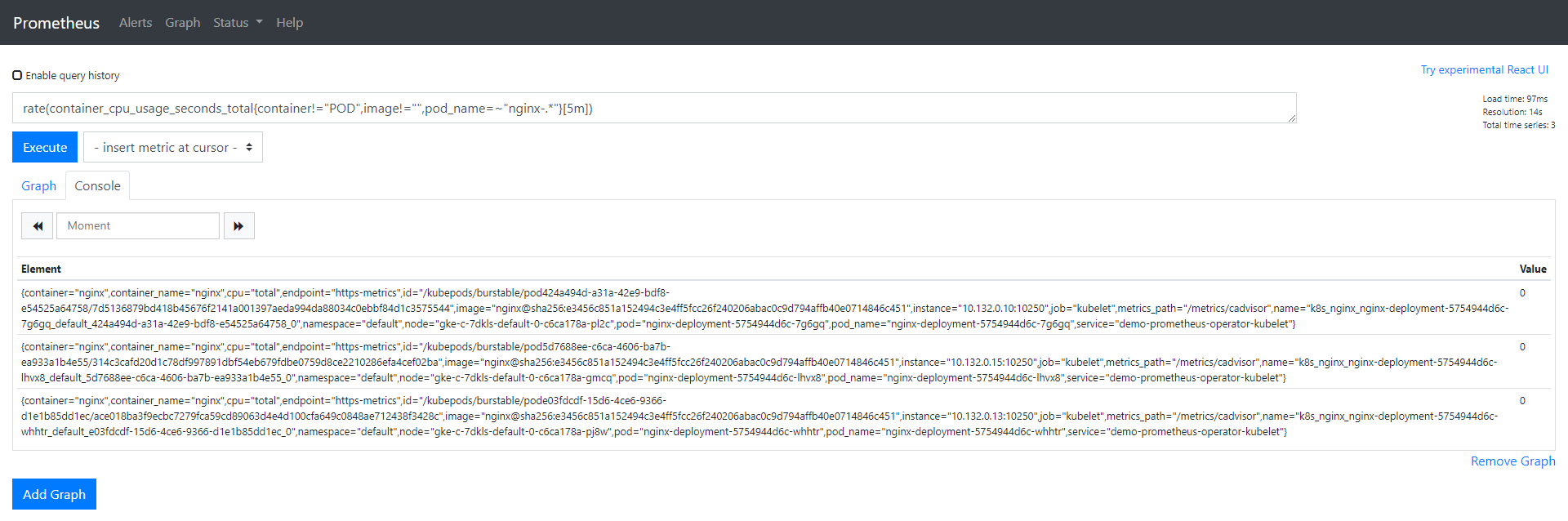
让我们在其中一个pod中添加一些负载,然后来看看值的变化,当值大于0.04时,我们应该接收到告警:
$ kubectl exec -it nginx-deployment-5754944d6c-7g6gq -- /bin/sh
# yes > /dev/null
该告警有3个阶段:
Inactive:不满足告警触发条件
Pending:条件已满足
Firing:触发告警
我们已经看到告警处于inactive状态,所以在CPU上添加一些负载,以观察到剩余两种状态:
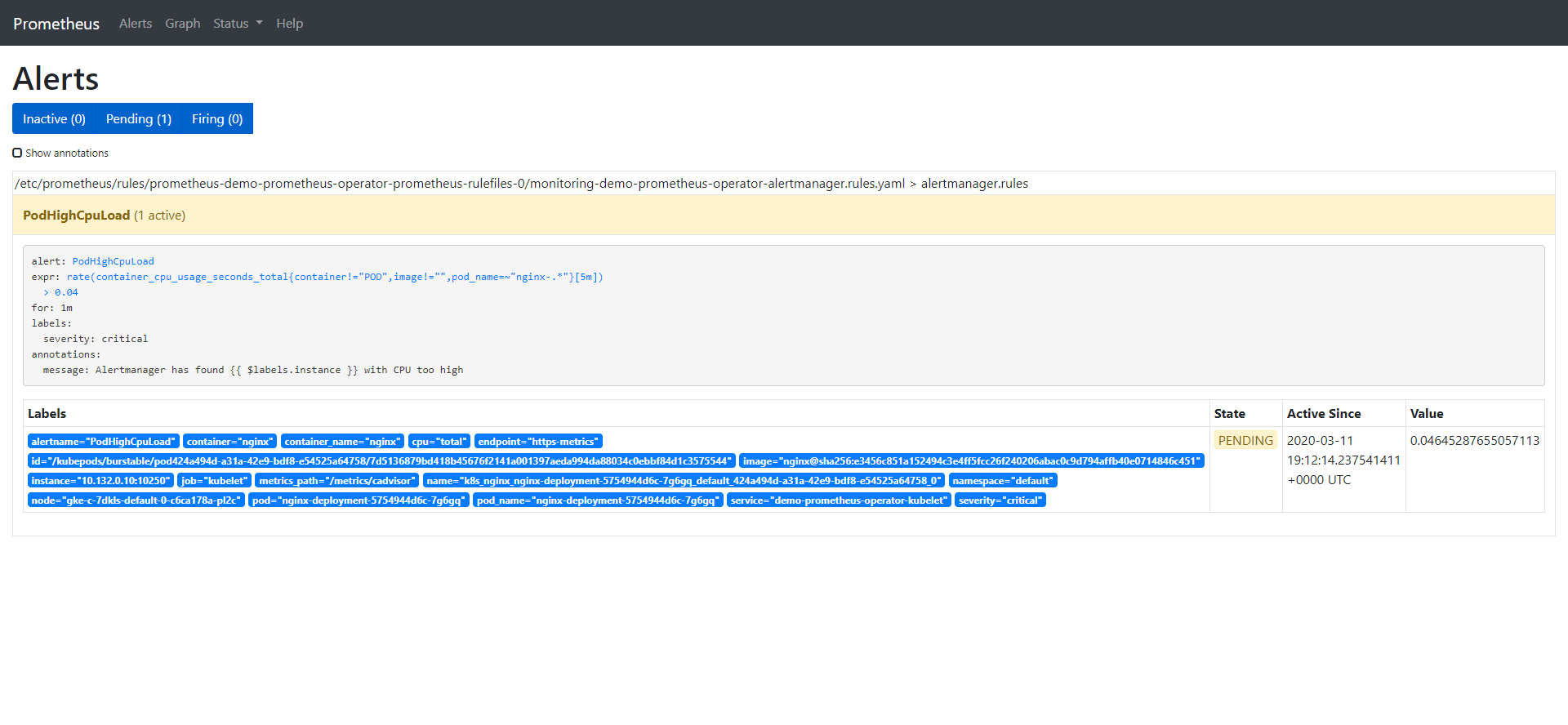
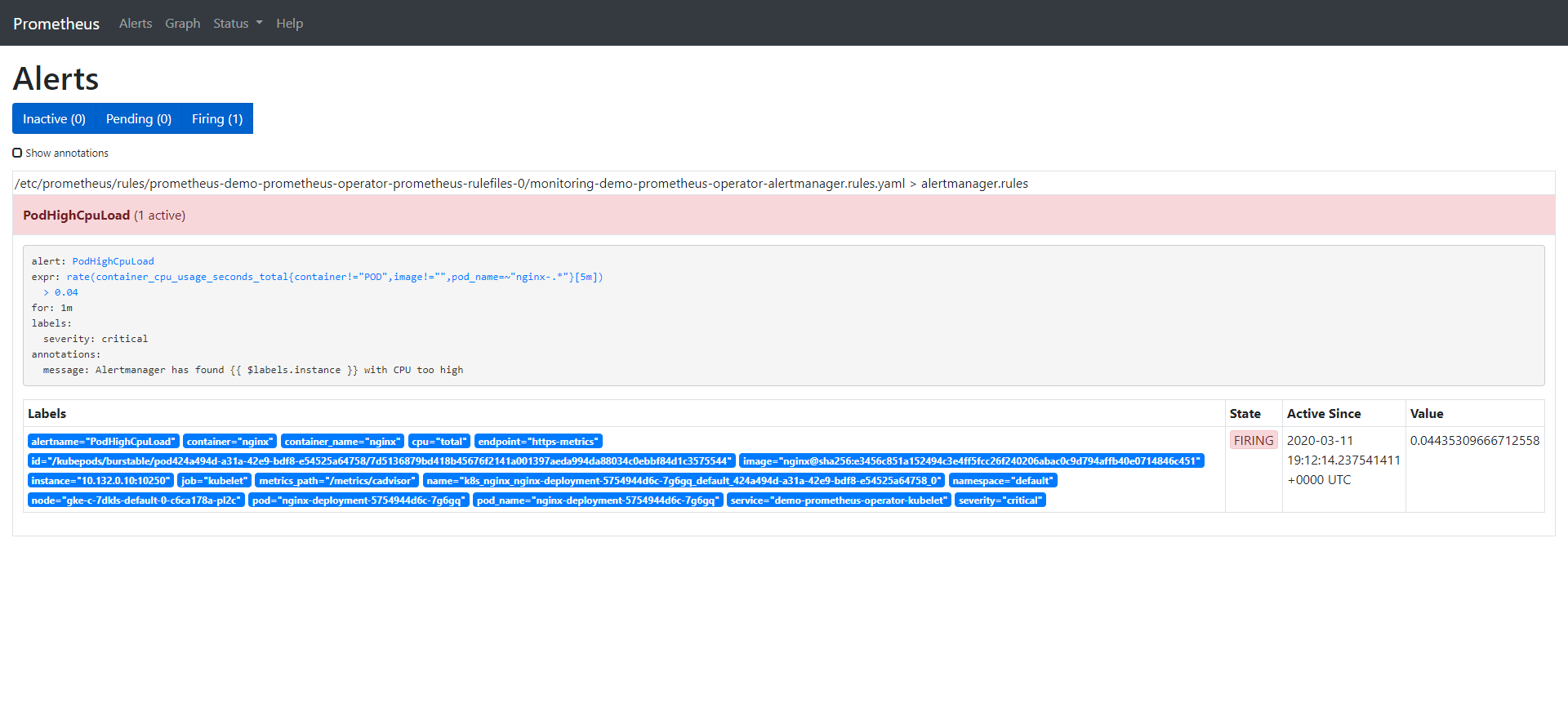
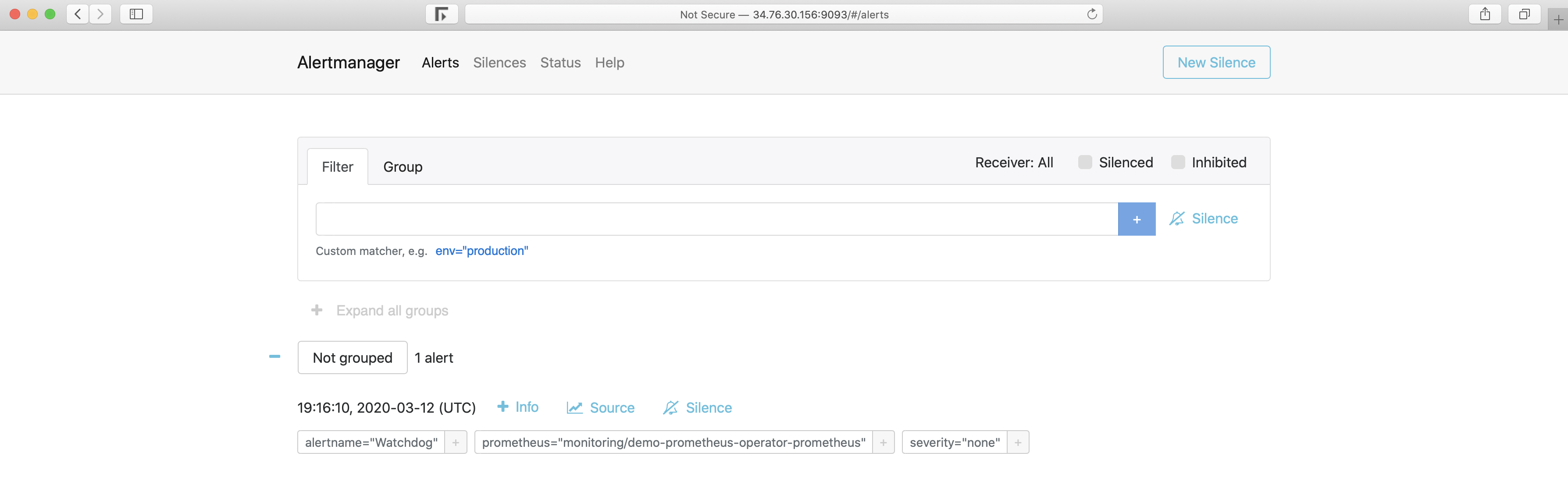
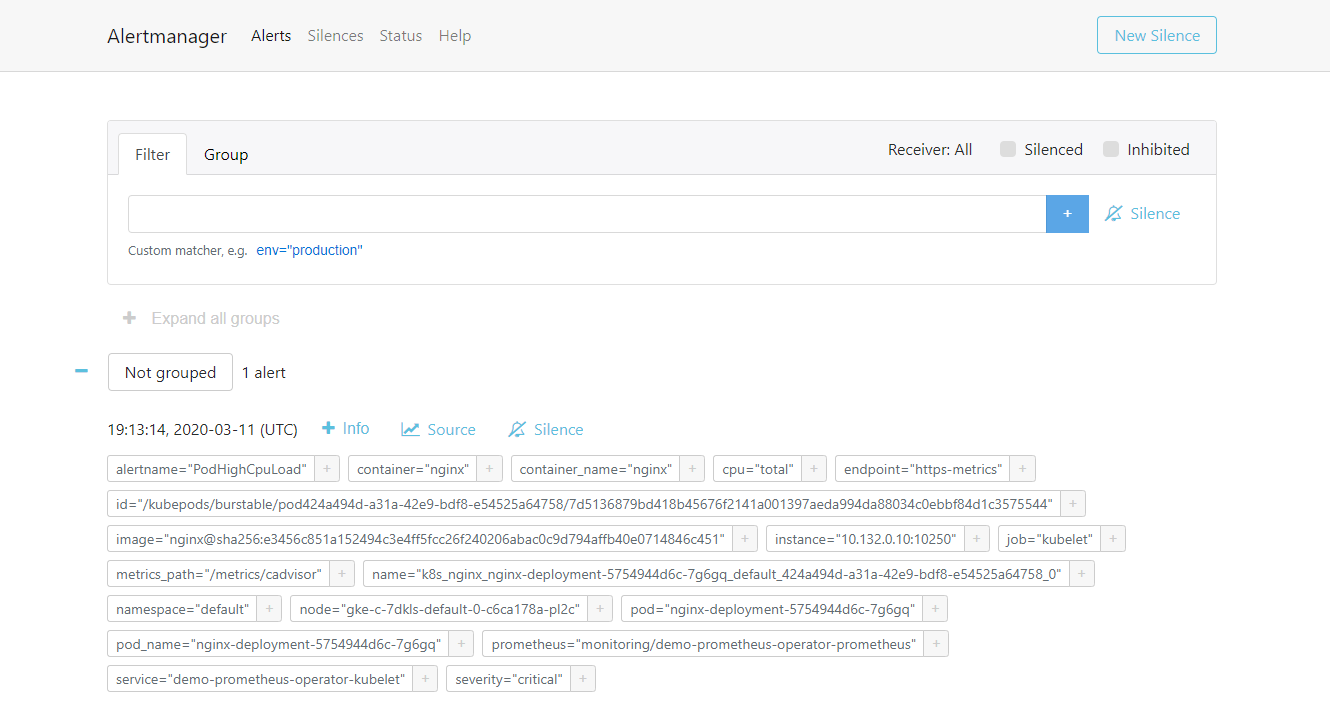
告警一旦触发,将会在Alertmanager中显示:
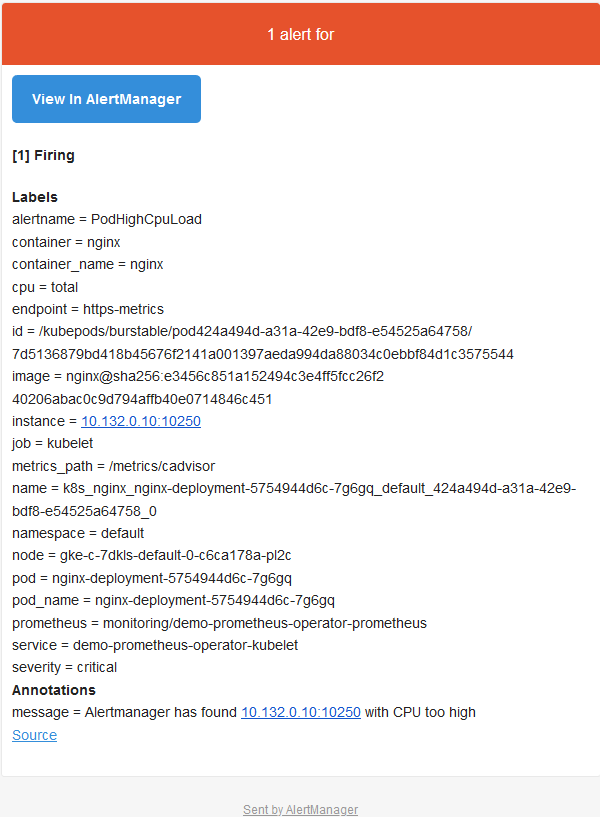
Alertmanger配置为当我们收到告警时发送邮件。所以此时,如果我们检查收件箱,会看到类似以下内容:
总 结
我们知道监控的重要性,但是如果没有告警,它将是不完整的。发生问题时,告警可以立即通知我们,让我们立即了解到系统出现了问题。而Prometheus涵盖了这两个方面:既有监控解决方案又通过Alertmanager组件发出告警。本文中,我们看到了如何在Prometheus配置中定义告警以及告警在触发时如何到达Alertmanager。然后根据Alertmanager的定义/集成,我们收到了一封电子邮件,其中包含触发的告警的详细信息(也可以通过Slack或PagerDuty发送)。
实用干货丨如何使用Prometheus配置自定义告警规则的更多相关文章
- prometheus linux系统告警规则 实例
#prometheus linux系统告警规则 实例 #根据实际情况修改参数 #rules.linux.yml groups: - name: linux rules: - alert: Node-D ...
- Prometheus监控学习笔记之Prometheus 2.0 告警规则介绍
0x00 变化 Prometheus 2.0 已经发布一段时间了,从今天开始我将分几篇文章为大家介绍其中的一些变化. 此篇文章主要介绍 2.0 的告警规则声明的新写法. 从 1.x 到 2.0 规则声 ...
- ElastAlert配置和告警规则各种用法
config.yaml配置说明 #用来加载rule的目录,默认是example_rules rules_folder: example_rules #用来设置定时向elasticsearch发送请求 ...
- Prometheus之告警规则的编写
Prometheus之告警规则的编写 一.前置知识 二.需求 三.实现步骤 1.编写告警规则 2.修改prometheus.yml执行告警规则的位置 3.配置文件截图 4.页面上看告警数据信息 5.查 ...
- Prometheus中使用的告警规则
参考网站:https://awesome-prometheus-alerts.grep.to/rules 这个网站上有好多常用软件的告警规则,但是有些并不一定实用,有些使用起来会有错误,这里就把这些都 ...
- 实用干货!Java开发企业级权限管理系统视频教程
全程手把手带你运用Java技术栈,打造一套基于最流行的RBAC拓展模型的,分布式的,有界面的,高灵活性,高拓展性的企业级权限管理系统.学完本课程你将可以轻松应对绝大多数企业开发中与权限管理及后台系统相 ...
- Prometheus Operator自定义监控项
Prometheus Operator默认的监控指标并不能完全满足实际的监控需求,这时候就需要我们自己根据业务添加自定义监控.添加一个自定义监控的步骤如下: 1.创建一个ServiceMonitor对 ...
- Web API配置自定义路由
默认访问Web API时,是无需指定method名.它会按照默认的路由来访问.如果你的Web API中出现有方法重载时,也许得配置自定义路由: 标记1为自定义路由,标记2为默认路由,需要把自定义路由排 ...
- 阿里云容器服务--配置自定义路由服务应对DDOS攻击
阿里云容器服务--配置自定义路由服务应对DDOS攻击 摘要: 容器服务中,除了slb之外,自定义路由服务(基于HAProxy)也可以作为DDOS攻击的一道防线,本文阐述了几种方法来应对普通规模的DDO ...
随机推荐
- 编辑距离算法-DP问题
Levenshtein Distance The Levenshtein distance is a string metric for measuring the difference betwee ...
- cesium入门示例-探测效果
动画实现方式通过多个canvas实现,参考的https://www.yueyanshaosun.cn/ysCesium/views/5_geometricObj2_entityCanvas.html ...
- [洛谷P2613] [模板] 有理数取余
刷水题. 传送门 看似高精而非高精乃是此题最大亮点. 边读边取模技能get~ #include<cstdio> #define ll long long #define mod 19260 ...
- Java Servlet XML文件配置
- POJ 3678 2-SAT
题意:有n个顶点里面可以放数字1或0,给m个限制,每个限制给出两个顶点编号和两编号内数字运算后的结果 思路:很直接的2-SAT,每个点分为1和0两种情况,按限制要求建边,跑tarjan然后判断点是否在 ...
- AtomicBoolean介绍
网上资料: 使用 AtomicBoolean 高效并发处理 "只初始化一次" 的功能要求: 1 privatestatic AtomicBoolean initialized = ...
- 在MySql中如何定义像Java中类型的Boolean类型
在MySql中如何定义像Java中类型的Boolean类型数据..其实,mysql中 是没有直接定义成Boolean这种数据类型.它只能定义成 tinyint(1) ;如果长度是1,tinyint(1 ...
- Python拾遗(2)
包括Python中的常用数据类型. int 在64位平台上,int类型是64位整数: 从堆上按需申请名为PyIntBlcok的缓存区域存储整数对象 使用固定数组缓存[-5, 257]之间的小数字,只需 ...
- appium ios真机自动化环境搭建&运行(送源码)
appium ios真机自动化环境搭建&运行(送源码) 原创: f i n 测试开发社区 6天前 Appium测试环境的搭建相对比较烦琐,不少初学者在此走过不少弯路 首先是熟悉Mac的使用 ...
- 使用js闭包的好处
使用闭包有以下几大好处: a:希望一个变量长期驻扎在内存中. b:避免全局变量的污染.