Learn to See in the Dark(论文阅读笔记)
最近做项目看了一篇论文《Learn to See in the Dark》下面是一些论文笔记
概括:
这篇论文主要介绍的是在低光照的环境下用两个标准的FCN网络,通过控制变量法来对比不同的去噪,增加信噪比(SNR)的方案,最终找到一个很好的解决方案。下面是详细介绍:
图片噪声影响:
由于图片拍摄的一些参数的设置不同,图片总是会出现一些噪声,或者的模糊等现象。高ISO可以提亮,但也会放大噪声。直接缩放或者拉伸直方图来降噪,也有一定效果,但并不能弥补光子不足的缺陷,如果增加曝光时间可以补充光子不足,但是一旦出现相机抖动,或者是物体移动就会出现图像模糊等现象。在弱光条件下可以通过开发光圈、延长曝光时间、使用闪光灯等来增加SNR,但是这些方法都存在自身的缺陷。
论文中要解决的问题:
暗光条件下的快速成像系统一直都是计算摄影界的一大挑战,目前,许多关于图像去噪,去模糊和低光图像增强等技术相继提出,但这些技术通常假设这些在昏暗环境下捕获到的图像带有中等程度的噪音。相反,论文更感兴趣的是在极端低光条件下,如光照严重受限 (例如月光) 和短时间曝光 (理想情况下是视频率) 等条件下的图像成像系统。在这种情况下,传统相机的处理方式显然已不适用,图像必须根据原始的传感器数据来重建。
论文中的数据集:
文中提到的数据集,是他们在固定位置用三脚架拍的。采用app远程设置光圈、ISO等参数,室外光照在0.2勒克斯和5勒克斯之间,室内的更加黑暗。数据采集的原则是高曝光的只要保持视觉效果好即可,不一味追求移除全部噪声。他们称自己的数据集叫SID。数据集包含了室内和室外图像。室外图像通常是在月光或街道照明条件下拍摄。在室外场景下,相机的亮度一般在0.2 lux 和5 lux 之间。室内图像通常更暗。在室内场景中的相机亮度一般在0.03 lux 和0.3 lux 之间。输入图像的曝光时间设置为1/30和1/10秒。相应的参考图像 (真实图像) 的曝光时间通常会延长100到300倍:即10至30秒。数据集一共有5049张照片
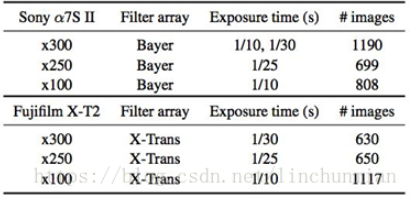
在每种条件下,随机选择大约20%的图像是组成测试集,另外选定10%的数据用于模型验证。

数据集下载可以参考:项目中download_dataset.py文件
数据集Sony类型有25GB,Fuji类型有52GB
相关数据处理工作:
去噪:全变分、小波域变换、稀疏编码、核范数最小化、BM3D(光滑、稀疏、低秩、自适应)。缺点:数据集一般都是合成的。一般认为BM3D在真实图片的表现结果比大部分其他算法好(Benchmarking denoising algorithms with real photographs)。多图效果不错,但本文想单图。
低光照图像增强:直方图均衡化、图像灰度校正(伽马校正)、暗通道反转、小波变换、Retinex model、光强映射估计。这些方法都认为退化图已经包含比较好的潜在信息,而没有考虑噪声和颜色扭曲的影响。
方法:
提出了一种端到端的学习方法,直接使用原始传感器的数据,方法结构图:

他们将两个标准的FCN结构作为模型的核心架构,分别是多尺度聚集网络(multi-scale context aggregation network (CAN))和U-net(U-net: Convolutional networks for biomedical image segmentation)。
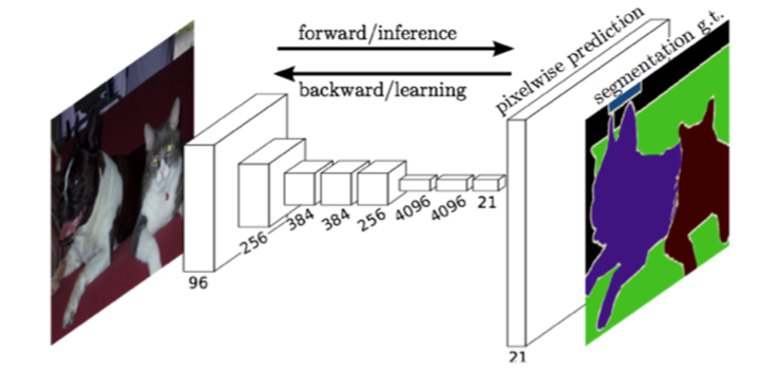
FCN全卷积网络可以参考:《Fully Convolutional Networks for Semantic Segmentation》
使用了FCN结构说明,对于这个模型可以输入任意像素的图片,
FCN结构示意图:
CAN上下文聚合网络可以参考:https://arxiv.org/pdf/1511.07122.pdf
U-net可以参考:https://arxiv.org/abs/1505.04597
U-Net 架构包括一个捕获上下文信息的收缩路径和一个支持精确本地化的对称扩展路径。我们证明了这样一个网络可以使用非常少的图像进行端到端的训练,并且在 ISBI 神经元结构分割挑战赛中取得了比以前最好的方法(一个滑动窗口的卷积网络)更加优异的性能。我们使用相同的网络,在透射光显微镜图像(相位对比度和 DIC)上进行训练,以很大的优势获得了 2015 年 ISBI 细胞追踪挑战赛。此外,网络推断速度很快。一个 512x512 的图像分割在最新的 GPU 上花费了不到一秒。
U-Nrt架构:

其中U-net是本文默认的网络。
模型训练:
使用 L1 损失和 Adam 优化器,从零开始训练我们的网络。在训练期间,网络输入是原始的短曝光图像,在 sRGB 空间中的真实数据是相应的长曝光时间图像(由一个原始图像处理库 libraw 处理过得参考图像)。为每台相机训练一个网络,并将原始图像和参考图像之间曝光时间的倍数差作为的放大因子(例如,x100,x250,或x300)。在每次训练迭代中,随机裁剪一个512×512的补丁用于训练并利用翻转、旋转等操作来随机增强数据。初始学习率设定为0.0001,在2000次迭代后学习率降为0.00001,训练一共进行4000次迭代。
对比分析结果:
与传统方法的对比,提出的方法具有放大的功能。


用CAN替换U-net、用sRGB替换原始信号,SSIM或L2替换L1等等。其中不用原始信号那个掉得最快,其余的差并不太多。

总结:
1.本文设计了数据驱动的方法,能有效提高成像表现,还贡献了SID数据集。
2.对于低光照图片的处理方法提供了一种全新的思路,能有效的解决这类问题
3.不足之处在于对于训练的内存要求太大。数据集也比较大
项目地址:web.engr.illinois.edu/~cchen156/SID.html
GitHub地址:github.com/cchen156/Learning-to-See-in-the-Dark
中文翻译:https://blog.csdn.net/linchunmian/article/details/80291921
Learn to See in the Dark(论文阅读笔记)的更多相关文章
- Learning to See in the Dark论文阅读笔记
这是一篇图像增强的论文,作者创建了一个数据集合,和以往的问题不同,作者的创建的see in the dark(SID)数据集合是在极其暗的光照下拍摄的,这个点可以作为一个很大的contribution ...
- 论文阅读笔记 - YARN : Architecture of Next Generation Apache Hadoop MapReduceFramework
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
- 论文阅读笔记 - Mesos: A Platform for Fine-Grained ResourceSharing in the Data Center
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
- 论文阅读笔记 Word Embeddings A Survey
论文阅读笔记 Word Embeddings A Survey 收获 Word Embedding 的定义 dense, distributed, fixed-length word vectors, ...
- 论文阅读笔记 Improved Word Representation Learning with Sememes
论文阅读笔记 Improved Word Representation Learning with Sememes 一句话概括本文工作 使用词汇资源--知网--来提升词嵌入的表征能力,并提出了三种基于 ...
- [置顶]
人工智能(深度学习)加速芯片论文阅读笔记 (已添加ISSCC17,FPGA17...ISCA17...)
这是一个导读,可以快速找到我记录的关于人工智能(深度学习)加速芯片论文阅读笔记. ISSCC 2017 Session14 Deep Learning Processors: ISSCC 2017关于 ...
- Nature/Science 论文阅读笔记
Nature/Science 论文阅读笔记 Unsupervised word embeddings capture latent knowledge from materials science l ...
- 论文阅读笔记(二十一)【CVPR2017】:Deep Spatial-Temporal Fusion Network for Video-Based Person Re-Identification
Introduction (1)Motivation: 当前CNN无法提取图像序列的关系特征:RNN较为忽视视频序列前期的帧信息,也缺乏对于步态等具体信息的提取:Siamese损失和Triplet损失 ...
- 论文阅读笔记(十八)【ITIP2019】:Dynamic Graph Co-Matching for Unsupervised Video-Based Person Re-Identification
论文阅读笔记(十七)ICCV2017的扩刊(会议论文[传送门]) 改进部分: (1)惩罚函数:原本由两部分组成的惩罚函数,改为只包含 Sequence Cost 函数: (2)对重新权重改进: ① P ...
- [论文阅读笔记] GEMSEC,Graph Embedding with Self Clustering
[论文阅读笔记] GEMSEC: Graph Embedding with Self Clustering 本文结构 解决问题 主要贡献 算法原理 参考文献 (1) 解决问题 已经有一些工作在使用学习 ...
随机推荐
- python 3 print function
if episode % 50 == 0: print('Episode {} Total Reward: {} counter: {}'.format(episode,G,counter))
- MDK5使用技巧
1.文本美化 修改 修改字体以及颜色如下: 修改用户自定义的关键字,如下: 代码编辑技巧 1.TAB键的妙用 使用TAB键可以整体向右移动相应位,使用SHIFT+TAB键整体左移相应位. 2.快速定位 ...
- C程序设计语言(2)文摘
第一章 导言 1.1 入门 1.2 变量与算术表达式 1.3 for语句 1.4 符号常量 1.5 字符输入输出 #include "stdafx.h" main(int argc ...
- guestfish修改镜像内容
1.安装guestfish yum install libguestfs-tools 注意,如果要修改windows镜像需要安装 yum install libguestfs-winsupport 2 ...
- Shell编程-04-Shell中变量数值计算
目录 算术运算符 算术运算命令 数值运算用法 算术运算符 在任何一门形式的语言中均会存在算术运算的情况,Shell常见的运算符如下所示: 运算符 含义 + - * / % 加 减 乘 除 求余 ...
- c+内存管理机制
内存管理是C++最令人切齿痛恨的问题,也是C++最有争议的问题,C++高手从中获得了更好的性能,更大的自由,C++菜鸟的收获则是一遍一遍的 检查代码和对C++的痛恨,但内存管理在C++中无处不在,内存 ...
- 测试嵌入GeoGebra网页
使用 http://ggbstudy.top/tools/ggb2html/ 将GGB文件免费托管,然后在博客内容中点击“HTML”按钮插入GGB网页地址: <iframe src=" ...
- D3 datum()
datum()和data()功能类似. datum():将指定数据赋值给被选择元素.data():将数据数组与选择集的元素结合. var p = d3.selectAll('p'); p.datum( ...
- Spring中ApplicationContext和beanfactory区别---解析一
BeanFacotry是spring中比较原始的Factory.如XMLBeanFactory就是一种典型的BeanFactory.原始的BeanFactory无法支持spring的许多插件,如AOP ...
- jenkins启动失败,提示Starting Jenkins Jenkins requires Java8 or later, but you are running 1.7.0
# 背景 centos安装jenkins后,先启动jenkins服务,结果报错如下: 但自己明明已经安装了java8的 # 解决方法 既然安装了java8的话,那么证明是jenkins启动的是还是用的 ...