python爬取小说详解(一)
整理思路:
首先观察我们要爬取的页面信息。如下:

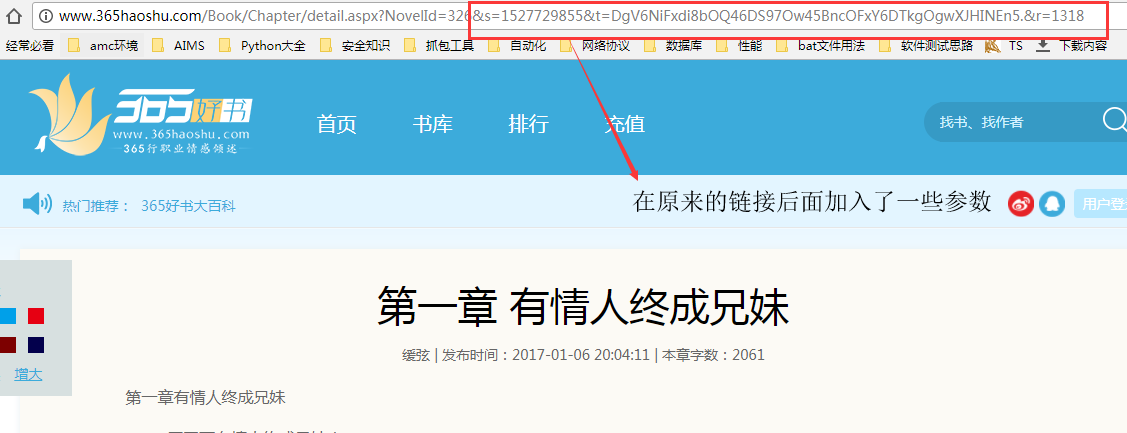
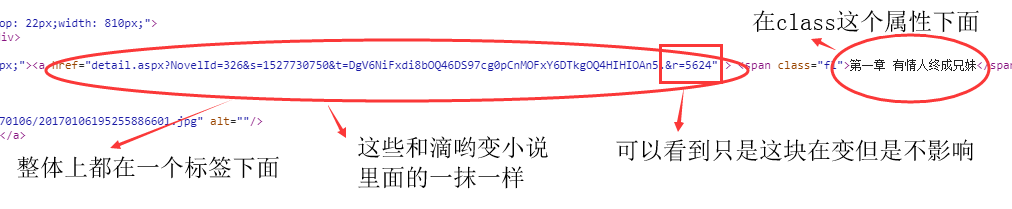
自此我们获得信息有如下:
♦1.小说名称链接小说内容的一个url,url的形式是:http://www.365haoshu.com/Book/Chapter/ +href="detail.aspx?NovelId=3026&s=1527731727&t=DgV6NiFxdi8bOQ40DikZJQ0HCnYMBwZyDikgcA45BnAOKSB.&r=4298" #其中:&r=4298这个变化对小说章节顺序没有发生变化,你可以在后面改一下试一下
♦2.小说的链接和小说名称都在同一个标签下面。
至此我有了简单的思路了:
根据以上条件特点我有了一个总体思路,我分别用两个列表一个存放小说名字,一个存放列链接,然后然依次同时取出小说名字对应链接然后写在一个文件里面。
♦1.根据难度性,我们先把所有的这个HTML内容响应出来放到一个类集合里面<class 'bs4.BeautifulSoup'>
♦2.再根据这个集合在检索小说名字和链接所在所在的tag行,形成一个新的集合<class 'bs4.element.ResultSet'>
♦3.然后再在这个集合里面检索小说名称和小说链接,再形成一个新的类集合<class 'bs4.element.Tag'>
♦4.在检索的同时就把这些检索出来的东西分别存放在两个字符串里面
♦5,按照顺序依次遍历出来并把对应小说的内用写在text文件里面
我们需要用到的库:
♦from bs4 import BeautifulSoup
♦import requests
小说章节链接:
♦http://www.365haoshu.com/Book/Chapter/List.aspx?NovelId=6686
♦小说名称:为你倾心,为我倾城
接下来开始代码部分:
from bs4 import BeautifulSoup#导入BeautifulSoup这个模块爬虫中很关键在第二篇中讲
import requests
#我们大概分三个步骤
#1.获取章节和章节对应的链接信息
#2.获取对应章节的内容
#3.把章节名字已经对应章节的内容写进text文件里面
class spiderstory(object): def __init__(self):
self.url = 'http://www.365haoshu.com/Book/Chapter/'
self.names = []#存放章节名称
self.hrefs = []#存放章节链接
def get_urlandname(self):
response = requests.get(url=self.url + 'List.aspx?NovelId=6686 ')#回去章节目录类型为<class 'requests.models.Response'>
req_parser = BeautifulSoup(response.text,"html.parser")
# req后面跟text和html都行,固定写法,BeautifulSoup默认支持Python的标准HTML解析库数据类型:<class 'bs4.BeautifulSoup'>
# print(req_parser)
# print(type(req_parser))
div = req_parser.find_all('div',class_='user-catalog-ul-li')
# 查找内容,标签为div,属性为class='user-catalog-ul-li',这里 是找到名字和链接所在的标签,数据类型:<class 'bs4.element.ResultSet'>
# print(div)
# print(type(div))
a_bf = BeautifulSoup(str(div))#进行进一步的字符解析因为获取要素类型的值时必须进行这一步
# print(type(a_bf))#<class 'bs4.BeautifulSoup'>
# print(len(a_bf))#1
a = a_bf.find_all('a') # # 查找内容,标签为a#下面需要获取a标签下的href,所以这里首先要精确到a标签下。才能从a标签下获取属性的值
# print(len(a))
# print(a)
for i in a:#注意class类型和列表等一样也是一个一个元素的,所以他可以用for遍历,你可以用len查看一下
#print(i.find('span',class_='fl').string)#查找所有span和属性class='fi'的字符类型的内容,注意因为class和类一样了所写成class_
# print(i)
# print(i['href'])
# print(type(i))
# print(len(i))
# print(i.find('span',class_='fl'))
self.names.append(i.find('span',class_='fl').string)#str只获取指定的文本类型
#print(i.get('href'))#获取有两种方法:1.i.get('href' 2.i['href']
self.hrefs.append(self.url + i['href'])#注意如果TypeError: must be str, not NoneType,所以这里追加到字符串里面必须以字符的形式加
print(self.names)
print(self.hrefs)
def get_text(self,url):
# print(self.hrefs[0])
respons2 =requests.get(url=url)
# print(respons2)
c = BeautifulSoup(str(respons2.text),'html.parser')
# print(c)
b = c.find_all('p', class_='p-content')
text = []
for temp in b:#获取标签里面的文本只能进行遍历每个满足条件的文本才能获取
text.append(temp.string) #b.string#获取解析后的文本,获取所有的文本类型 print(text)
return text
def writer(self,name,path,text1):
''' 写入TXT文档'''
with open(path,'a',encoding='utf-8') as f:
f.write(name + '\n')#写入名字并换行
f.writelines(text1)#追加内容
f.write('\n\n')#换两行
if __name__ == "__main__": # 运行入口
a= spiderstory()
a.get_urlandname()
# a.get_text()
for i in range(len(a.names)):
name = a.names[i]
text = str(a.get_text(a.hrefs[i]))#注意TypeError: write() argument must be str, not None,写入文档必须是字符串
a.writer(name,'F:\小说.txt',text)
print(a)
以上是我写的整体代码以及一些调试的方法:
代码整理如下:
from bs4 import BeautifulSoup
import requests
class spiderstory(object): def __init__(self):
self.url = 'http://www.365haoshu.com/Book/Chapter/'
self.names = []#存放章节名称
self.hrefs = []#存放章节链接 def get_urlandname(self):
'''获取章节名称和和章节URL'''
response = requests.get(url=self.url + 'List.aspx?NovelId=6686 ')
req_parser = BeautifulSoup(response.text,"html.parser")
div = req_parser.find_all('div',class_='user-catalog-ul-li')
a_bf = BeautifulSoup(str(div))
a = a_bf.find_all('a')
for i in a:
self.names.append(i.find('span',class_='fl').string)
self.hrefs.append(self.url + i['href']) def get_text(self,url):
'''获取对应章节内容'''
respons2 =requests.get(url=url)
c = BeautifulSoup(str(respons2.text),'html.parser')
b = c.find_all('p', class_='p-content')
text = []
for temp in b:
text.append(temp.string)
return text def writer(self,name,path,text1):
''' 写入TXT文档'''
with open(path,'a',encoding='utf-8') as f:
f.write(name + '\n')
f.writelines(text1)
f.write('\n\n') if __name__ == "__main__": # 运行入口
a= spiderstory()
a.get_urlandname()
for i in range(len(a.names)):
name = a.names[i]
text = str(a.get_text(a.hrefs[i]))
a.writer(name,'F:\小说.txt',text)
print(a)
python爬取小说详解(一)的更多相关文章
- 用Python爬取小说《一念永恒》
我们首先选定从笔趣看网站爬取这本小说. 然后开始分析网页构造,这些与以前的分析过程大同小异,就不再多叙述了,只需要找到几个关键的标签和user-agent基本上就可以了. 那么下面,我们直接来看代码. ...
- 详细记录了python爬取小说《元尊》的整个过程,看了你必会~
学了好几天的渗透测试基础理论,周末了让自己放松一下,最近听说天蚕土豆有一本新小说,叫做<元尊>,学生时代的我可是十分喜欢读天蚕土豆的小说,<斗破苍穹>相信很多小伙伴都看过吧.今 ...
- 用python爬取小说章节内容
在学爬虫之前, 最好有一些html基础, 才能更好的分析网页. 主要是五步: 1. 获取链接 2. 正则匹配 3. 获取内容 4. 处理内容 5. 写入文件 代码如下: #导入相关model fro ...
- python爬取小说
运行结果: 代码: import requests from bs4 import BeautifulSoup from selenium import webdriver import os cla ...
- python入门学习之Python爬取最新笔趣阁小说
Python爬取新笔趣阁小说,并保存到TXT文件中 我写的这篇文章,是利用Python爬取小说编写的程序,这是我学习Python爬虫当中自己独立写的第一个程序,中途也遇到了一些困难,但是最后 ...
- Python爬取CSDN博客文章
0 url :http://blog.csdn.net/youyou1543724847/article/details/52818339Redis一点基础的东西目录 1.基础底层数据结构 2.win ...
- Python3爬取小说并保存到文件
问题 python课上,老师给同学们布置了一个问题,因为这节课上学的是正则表达式,所以要求利用python爬取小说网的任意小说并保存到文件. 我选的网站的URL是'https://www.biquka ...
- Python实战项目网络爬虫 之 爬取小说吧小说正文
本次实战项目适合,有一定Python语法知识的小白学员.本人也是根据一些网上的资料,自己摸索编写的内容.有不明白的童鞋,欢迎提问. 目的:爬取百度小说吧中的原创小说<猎奇师>部分小说内容 ...
- python爬虫——爬取小说 | 探索白子画和花千骨的爱恨情仇(转载)
转载出处:药少敏 ,感谢原作者清晰的讲解思路! 下述代码是我通过自己互联网搜索和拜读完此篇文章之后写出的具有同样效果的爬虫代码: from bs4 import BeautifulSoup imp ...
随机推荐
- Oracle的服务端_默认_启动的服务
- Spring分配置文件开发
---------------------siwuxie095 Spring 分配置文件开发 Spring 分配置文件开 ...
- 手工kill掉VNC进程的故障处理
1.模拟Kill掉已经启动的VNC服务 1)启动桌面1的服务 [root@testdb ~]# vncserver :1 New 'testdb:1 (root)' desktop is testdb ...
- Python爬虫利器一之Requests库的用法
前言 之前我们用了 urllib 库,这个作为入门的工具还是不错的,对了解一些爬虫的基本理念,掌握爬虫爬取的流程有所帮助.入门之后,我们就需要学习一些更加高级的内容和工具来方便我们的爬取.那么这一节来 ...
- ubuntu 卡在登陆界面无法进入桌面,但是可以进入命令行界面
ubuntu 卡在登陆界面无法进入桌面,但是可以进入命令行界面(初步断定是Xwindows界面软件出问题了,所以重装即可!)Solve: 1.Ctrl+Alt+F1进入命令行界面,root账户登陆2. ...
- 文字如何实现完美UI?文本排版设计告诉你
一部手机,电量充足,网络通畅,就足以让我们打发一天的时光,尽情沉浸在手机时代的缤纷世界里.这个信息资源无穷尽的手机网络世界,是设计师和开发者们在不停的探索中一路一步精心打造.如何进一步美化这个世界,优 ...
- redis centos 上以 tar.gz 安装redis
1.下载安装文件#wget http://download.redis.io/releases/redis-3.2.3.tar.gz 2.删除文件 rm -rf /usr/local/redisrm ...
- PHP 微信公众号开发 - 获取用户信息
项目微信公众号开发,记录获取用户微信号信息,和用户openid 1,登录微信公众平台 点击登录微信公众平台 2,获取公众号开发信息 登陆之后在 开发->基本配置 3,设置IP白名单 在这里添加服 ...
- redhat6.7在线安装postgresql9
原文:http://wandejun1012.iteye.com/blog/2015777 1.安装postgresql9.0 yum 仓库 rpm -i http://yum.postgresql. ...
- m2e 插件
官网 http://www.eclipse.org/m2e/ 在线安装地址 http://download.eclipse.org/technology/m2e/releases 插件简介 Launc ...