Transfer-Encoding:chunked 返回数据过长导致中文乱码
最近在写一个项目的后台时,前端请求指定资源后,返回JSON格式的数据,突然发现在返回的字节数过大时,最后的message中文数据乱码了,对于同一个接口的请求:当数据小时不会乱码,当数据量大了中文就乱码了。
基本的Controller代码如上,有的人也许一眼发现了问题所在,有人会质疑我的写法,但是在这里我想找的不是这个。
对于这个情况,在抓包后得到的状况如下:(记住大概你觉得陌生的地方,继续往下看)


可以明显的观察到,这里在中文乱码时出现了更多的TCP数据报。
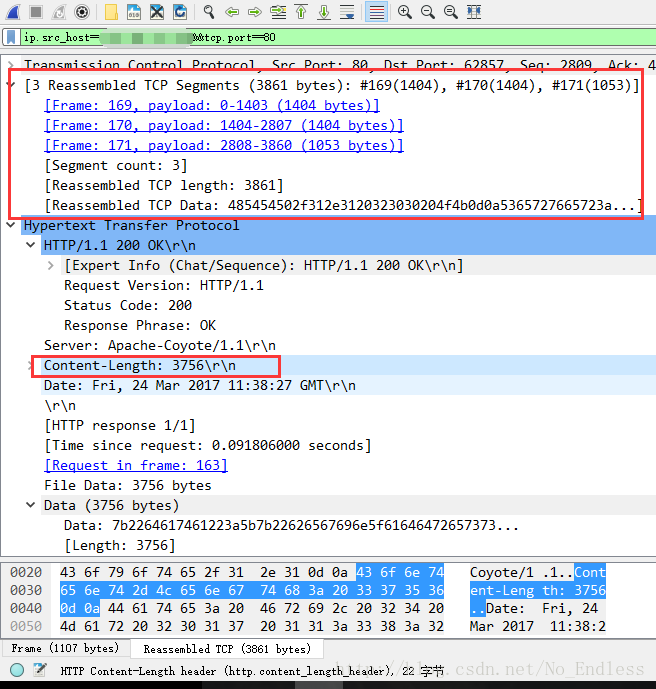
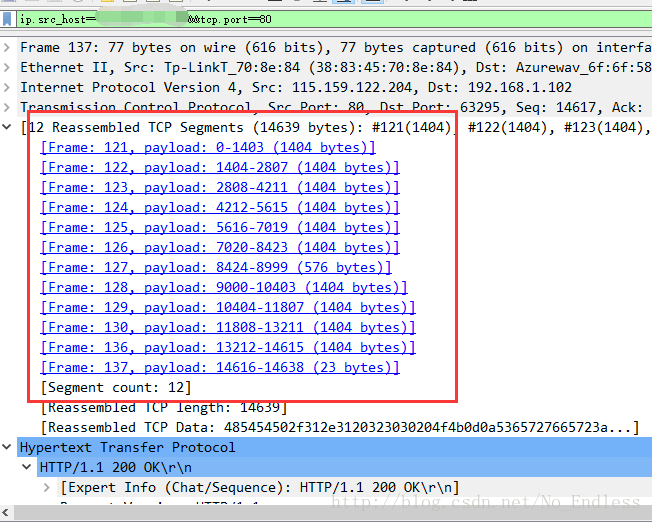
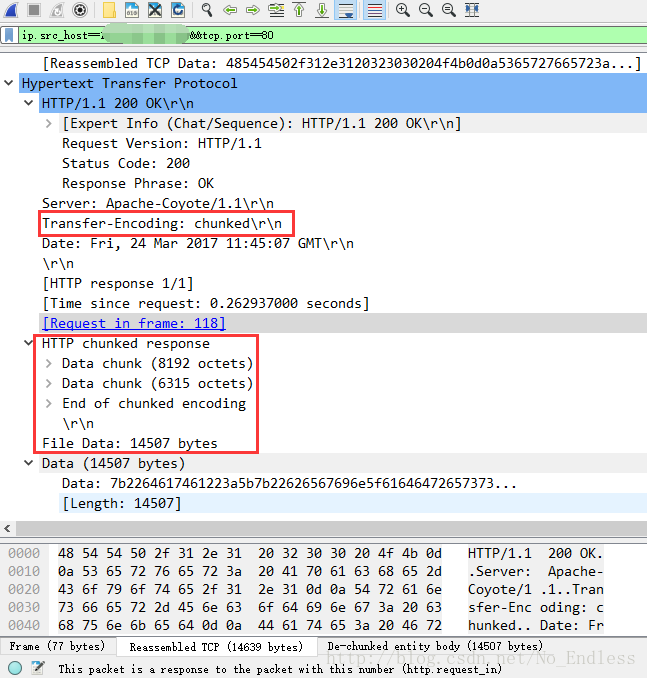
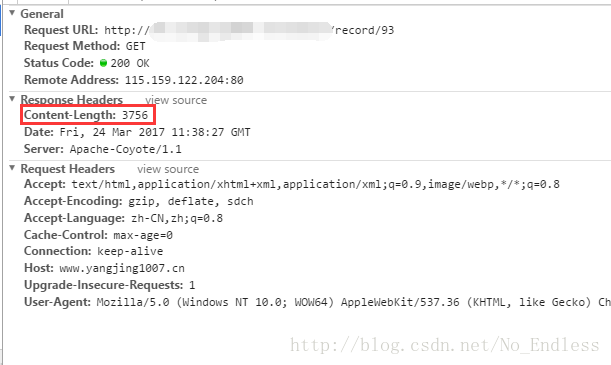
到了抓包的地方,我们就可以观察到HTTP响应头发生了变化,在正常状态下,会返回Content-Length,但是在数据很多,即中文乱码的情况下,Content-Length属性被Transfer-Encoding:chunked属性取代了。



一开始想修改一下Chrome浏览器的编码试试,但是发现在Chrome
55之后的版本,字符集编码的修改功能被移除了。按照Google方面的说法如下:
大概就是,自动检查分析字符集的功能虽然使出现乱码的情况减少,但是拖慢了页面加载时间大概10%~20%;选择功能同时会在页面已经声明其编码的情况下有几率地,使用户因为自己设置的编码而看到乱码,所以页面声明编码时,直接调用选择,否则,默认使用Chrome的UI语言。
当不能预先确定报文体的长度时,或是报文长度过长时,无法使用Content-Length来指明报文体长度,此时就需要通过Transfer-Encoding域来代替。
Transfer-Encoding:chunked用于http传送过程的分块传输技术,原因是http服务器响应的报文长度经常是不可预测的,使用Content-length的实体搜捕并不是总是管用。
分块技术的意思是说,实体被分成许多的块(Data
chunk),也就是应用层的数据,TCP在传送的过程中,不对它们做任何的解释,而是把应用层产生数据全部理解成二进制流,然后按照一定的长度切成一段的,然后一次性给TCP协议去传输,而具体这些二进制的数据如何做解释,需要应用层来完成,所以在这之前,一快整体应用层的数据需要等它分成的所有TCP
segment到达对方,重新组装后,应用程序才使用自己的解码方法还原它们。
分块传输时,我们设置的CharacterEncoding无效了,其实当Transfer-Encoding时,编码格式就是它的值——chunked,采用chunked编码方式来进行报文体的传输,基本方法是将大块数据分解成多块小数据,每块都可以自指定长度。chunked编码是HTTP/1.1
RFC里定义的一种编码方式,因此所有的HTTP/1.1应用都应当支持此方式。
chunked编码格式在RFC中定义如下:

chunked编码为了分块传输数据,将一个数据信息分成多个有自己长度的块,这样就允许在不知道长度的情况下动态的去传输数据信息,Chunked-Body分块由CRLF(回车换行符)进行分隔,包含有一个16进制的长度size信息和一个数据为“0”的chunk块来表示数据传输完毕。
写了这么多,如果我们回头看就会发现一些对应的HTTP报文,以及问题的根源!
好吧…对于最后,记得在返回JSON时中加入代码段取代简单的设置字符集:
这是我失误的地方,字符集的指定最后还是被chunk给打败了,也许是优先级不够吧,但是也学到了很多东西。
Transfer-Encoding:chunked 返回数据过长导致中文乱码的更多相关文章
- 读取 properties 配置文件含有中文的value内容 导致中文乱码 的解决办法
1.前言 因为装系统的时候把中文写在了系统路径,现在我想把这个路径写在properties里面来读取,可是 发现java 读取会导致中文乱码成 问号????的乱码 ,百度找了好多博客,基本都是一摸一 ...
- js ajax post提交 ie和火狐、谷歌提交的编码不一致,导致中文乱码
今天遇到一个问题找了很久发现: 使用js ajax post提交 ie和火狐.谷歌提交的编码不一致,导致中文乱码 //http://www.cnblogs.com/QGC88 $.ajax({ url ...
- [Done]SnowFlake生成Long类型主键返回前台过长导致精度缺失的问题
问题描述: 在开发过程中,项目的主键生成器是SnowFlake,其生成的long主键是28位, 但是js中Long的最大值:https://blog.csdn.net/sunmerZeal/artic ...
- 中小学教育缴费----支付宝回传数据.net core 接收中文乱码
问题描述: 中小学教育缴费,发送账单到家长支付宝,家长支付成功之后,支付宝回传数据,验签的时候失败了,排查之后发现账单名称乱码了.支付宝回传的时候中文传的是GBK编码格式,但是我接收的是%D5˵%A5 ...
- MySQL对JSON类型UTF-8编码导致中文乱码探讨
前言 继上文发表之后,结合评论意见并亲自验证最终发现是编码的问题,但是对于字符编码还是有点不解,于是乎,有了本文,我们来学习字符编码,在学习的过程中,我发现对于MySQL中JSON类型的编码导致数据中 ...
- 使用Kettle抽取数据时,出现中文乱码问题解决方案
使用Kettle在不同的数据库抽取数据时,有时会出现中文乱码问题:其解决方案如下: 1.查看数据库的字符集是否是UTF-8(最常用的字符集) 2.如果数据库设置正确仍然存在中文乱码,则可能是因为有的客 ...
- 关于hibernate插入数据到mysql数据库中文乱码问题的解决
要想解决这个问题就要找到问题的症结所在 1.首先将数据提交到action输出看action里的数据是不是中文乱码,结果很遗憾并不是这里的问题 2.设置数据库连接url: 3.打开mysql安装文件里的 ...
- 前台get传递含中文数据到后台出现中文乱码
博客:(前后台文件编码相同)前台传后台中文乱码 4月4日补充 jsp页面第一句没有下面一句或者页面发布后查看源代码时第一句已经不在了 <%@ page language="java&q ...
- JMeter_响应数据为空以及中文乱码
一.响应数据为空 最近做测试接口,使用同样的请求方式.地址.参数和header,在postman中能正常响应,接收数据的也正常,但是在Jmeter中,虽然响应正常,但是响应数据却为空! Jmeter接 ...
随机推荐
- C博客作业06—结构体&指针
1.本章学习总结 1.1思维导图 1.2本章学习体会 明白了结构体的定义及使用方法 学会了fopen,fclose,feof等文件操作函数,学会使用c语言进行文件操作 大作业中的部分函数出现未知错误且 ...
- 初识阿里开源诊断工具Arthas
上个月,阿里开源了一个名为Arthas的监控工具.恰逢近期自己在写多线程处理业务,由此想到了一个问题. 如果在本机开发调试,IDE可以看到当前的活动线程,例如IntelliJ IDEA,线程是运行还是 ...
- ELK安装成windows服务
一.Elasticsearch安装成windows服务 我的es所在路径为:D:\ELK5.5.0\elasticsearch-5.5.0 Java 安装目录为:C:\Program Files\Ja ...
- linux安装spark-2.3.0集群
(安装spark集群的前提是服务器已经配置了jdk并且安装hadoop集群(主要是hdfs)并正常启动,hadoop集群安装可参考<hadoop集群搭建(hdfs)>) 1.配置scala ...
- python3字典:获取json响应值来进行断言的用法详解
在Python中我们做接口经常用到一些json的返回值我们常把他转化为字典,在前面的python数据类型详解(全面)中已经谈到对字典的的一些操作,今天我们就获取json返回值之后,然后转化为字典后的获 ...
- Java_多线程2_线程池
线程池(pool): 线程池的作用: 1.节省资源,减少线程的数量和创建销毁线程的开销2.合理的管理线程的分配 线程池的创建: 1.newCachedThreadPool //优点:很灵活,弹性的线程 ...
- canvas+js绘制折线图
效果: 源码: <!DOCTYPE html> <html lang="en"> <head> <meta charset="U ...
- Go语言管道
Channel概念 Channel 是Go中的一个核心类型,你可以把它看成一个管道.Channel是引用类型,操作符是箭头 <- . Channel 是 CSP 模式的具体实现,用于多个 gor ...
- [转] Akka 使用系列之二: 测试
[From] http://www.algorithmdog.com/akka-test 通过上一篇文章,我们已经大致了解怎么使用 Akka,期待细致用法.这篇文章将介绍如何用 Akka-testki ...
- c# Equals方法
很多C#的教材都会强调对象相等的概念.我们都知道,在C#的世界里存在两种等同性.一种是逻辑等同性:如果两个对象在逻辑上代表同样的值,则称他们具有逻辑等同性.另一种是引用等同性:如果两个引用指向同一个对 ...