强化学习 车杆游戏 DQN 深度强化学习 Demo
网上搜寻到的代码,亲测比较好用,分享如下。
- import gym
- import time
- env = gym.make('CartPole-v0') # 获得游戏环境
- observation = env.reset() # 复位游戏环境,新一局游戏开始
- print ('新一局游戏 初始观测 = {}'.format(observation))
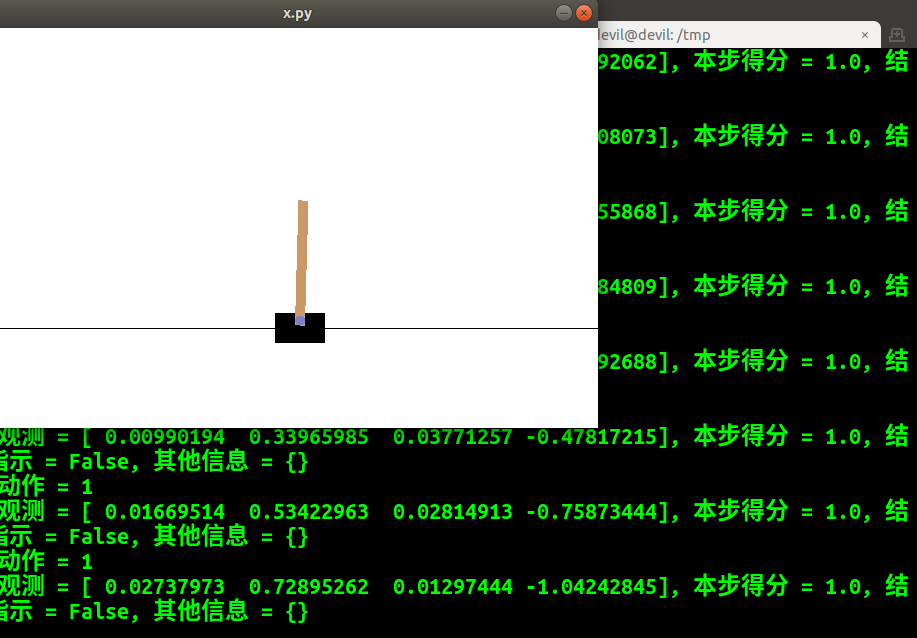
- for t in range(200):
- env.render()
- action = env.action_space.sample() # 随机选择动作
- print ('{}: 动作 = {}'.format(t, action))
- observation, reward, done, info = env.step(action) # 执行行为
- print ('{}: 观测 = {}, 本步得分 = {}, 结束指示 = {}, 其他信息 = {}'.format(
- t, observation, reward, done, info))
- if done:
- break
- time.sleep(1)#可加可不加,有的话就可以看到图
- env.close()
以下给出多个回合的代码:
- import gym
- env = gym.make('CartPole-v0')
- n_episode = 20
- for i_episode in range(n_episode):
- observation = env.reset()
- episode_reward = 0
- while True:
- # env.render()
- action = env.action_space.sample() # 随机选
- observation, reward, done, _ = env.step(action)
- episode_reward += reward
- state = observation
- if done:
- break
- print ('第{}局得分 = {}'.format(i_episode, episode_reward))
- env.close()
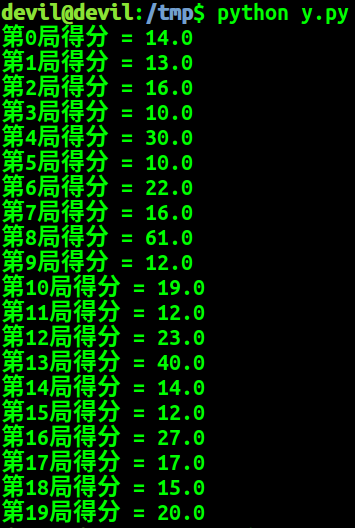
这次的多回合游戏并没有加入绘图,需要绘图的话可以将 env.render() 加入。
构建一个完整的 DQN 网络, 代码如下:
- #encoding:UTF-8
- #Cart Pole Environment
- import gym
- env = gym.make('CartPole-v0')
- #搭建 DQN
- import torch.nn as nn
- model = nn.Sequential(
- nn.Linear(env.observation_space.shape[0], 128),
- nn.ReLU(),
- nn.Linear(128, 128),
- nn.ReLU(),
- nn.Linear(128, env.action_space.n)
- )
- import random
- def act(model, state, epsilon):
- if random.random() > epsilon: # 选最大的
- state = torch.FloatTensor(state).unsqueeze(0)
- q_value = model.forward(state)
- action = q_value.max(1)[1].item()
- else: # 随便选
- action = random.randrange(env.action_space.n)
- return action
- #训练
- # epsilon值不断下降
- import math
- def calc_epsilon(t, epsilon_start=1.0,
- epsilon_final=0.01, epsilon_decay=500):
- epsilon = epsilon_final + (epsilon_start - epsilon_final) \
- * math.exp(-1. * t / epsilon_decay)
- return epsilon
- # 最近历史缓存
- import numpy as np
- from collections import deque
- batch_size = 32
- class ReplayBuffer(object):
- def __init__(self, capacity):
- self.buffer = deque(maxlen=capacity)
- def push(self, state, action, reward, next_state, done):
- state = np.expand_dims(state, 0)
- next_state = np.expand_dims(next_state, 0)
- self.buffer.append((state, action, reward, next_state, done))
- def sample(self, batch_size):
- state, action, reward, next_state, done = zip( \
- *random.sample(self.buffer, batch_size))
- concat_state = np.concatenate(state)
- concat_next_state = np.concatenate(next_state)
- return concat_state, action, reward, concat_next_state, done
- def __len__(self):
- return len(self.buffer)
- replay_buffer = ReplayBuffer(1000)
- import torch.optim
- optimizer = torch.optim.Adam(model.parameters())
- gamma = 0.99
- episode_rewards = [] # 各局得分,用来判断训练是否完成
- t = 0 # 训练步数,用于计算epsilon
- while True:
- # 开始新的一局
- state = env.reset()
- episode_reward = 0
- while True:
- epsilon = calc_epsilon(t)
- action = act(model, state, epsilon)
- next_state, reward, done, _ = env.step(action)
- replay_buffer.push(state, action, reward, next_state, done)
- state = next_state
- episode_reward += reward
- if len(replay_buffer) > batch_size:
- # 计算时间差分误差
- sample_state, sample_action, sample_reward, sample_next_state, \
- sample_done = replay_buffer.sample(batch_size)
- sample_state = torch.tensor(sample_state, dtype=torch.float32)
- sample_action = torch.tensor(sample_action, dtype=torch.int64)
- sample_reward = torch.tensor(sample_reward, dtype=torch.float32)
- sample_next_state = torch.tensor(sample_next_state,
- dtype=torch.float32)
- sample_done = torch.tensor(sample_done, dtype=torch.float32)
- next_qs = model(sample_next_state)
- next_q, _ = next_qs.max(1)
- expected_q = sample_reward + gamma * next_q * (1 - sample_done)
- qs = model(sample_state)
- q = qs.gather(1, sample_action.unsqueeze(1)).squeeze(1)
- td_error = expected_q - q
- # 计算 MSE 损失
- loss = td_error.pow(2).mean()
- # 根据损失改进网络
- optimizer.zero_grad()
- loss.backward()
- optimizer.step()
- t += 1
- if done: # 本局结束
- i_episode = len(episode_rewards)
- print ('第{}局收益 = {}'.format(i_episode, episode_reward))
- episode_rewards.append(episode_reward)
- break
- if len(episode_rewards) > 20 and np.mean(episode_rewards[-20:]) > 195:
- break # 训练结束
- #使用 (固定 ϵ 的值为0)
- n_episode = 20
- for i_episode in range(n_episode):
- observation = env.reset()
- episode_reward = 0
- while True:
- # env.render()
- action = act(model, observation, 0)
- observation, reward, done, _ = env.step(action)
- episode_reward += reward
- state = observation
- if done:
- break
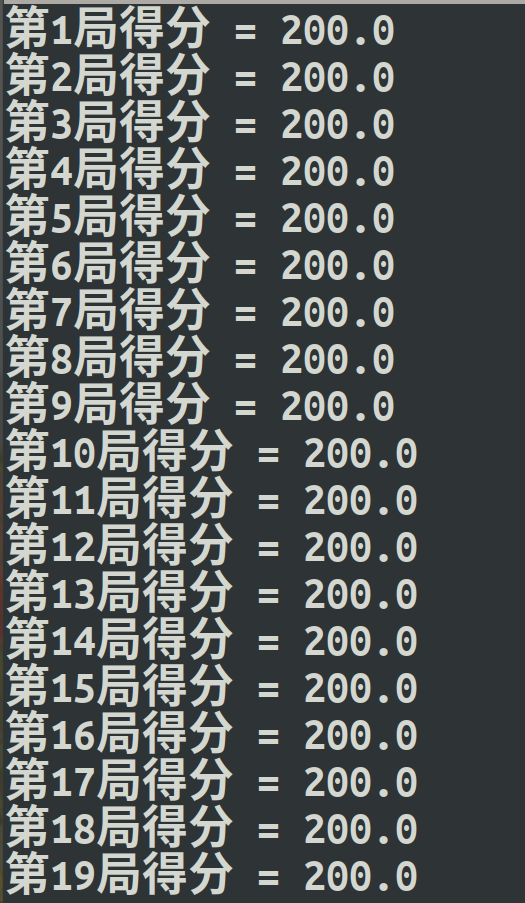
- print ('第{}局得分 = {}'.format(i_episode, episode_reward))
训练过程:

测试过程:
以上代码来自:
该书阅读后个人感觉非常好,照比市面上的同类pytorch书籍相比该书虽然略显深奥,但是各方面的讲解脉络十分的清晰,在同类书籍中首推,而且全书所有代码都可以跑通,十分的难得。
强化学习 车杆游戏 DQN 深度强化学习 Demo的更多相关文章
- 基于Keras的OpenAI-gym强化学习的车杆/FlappyBird游戏
强化学习 课程:Q-Learning强化学习(李宏毅).深度强化学习 强化学习是一种允许你创造能从环境中交互学习的AI Agent的机器学习算法,其通过试错来学习.如上图所示,大脑代表AI Agent ...
- 深度强化学习(DRL)专栏开篇
2015年,DeepMind团队在Nature杂志上发表了一篇文章名为"Human-level control through deep reinforcement learning&quo ...
- 5G网络的深度强化学习:联合波束成形,功率控制和干扰协调
摘要:第五代无线通信(5G)支持大幅增加流量和数据速率,并提高语音呼叫的可靠性.在5G无线网络中共同优化波束成形,功率控制和干扰协调以增强最终用户的通信性能是一项重大挑战.在本文中,我们制定波束形成, ...
- 深度强化学习(Deep Reinforcement Learning)入门:RL base & DQN-DDPG-A3C introduction
转自https://zhuanlan.zhihu.com/p/25239682 过去的一段时间在深度强化学习领域投入了不少精力,工作中也在应用DRL解决业务问题.子曰:温故而知新,在进一步深入研究和应 ...
- 强化学习(十二) Dueling DQN
在强化学习(十一) Prioritized Replay DQN中,我们讨论了对DQN的经验回放池按权重采样来优化DQN算法的方法,本文讨论另一种优化方法,Dueling DQN.本章内容主要参考了I ...
- (转) 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文)
本文转自:http://mp.weixin.qq.com/s/aAHbybdbs_GtY8OyU6h5WA 专题 | 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文) 原创 201 ...
- 深度强化学习——连续动作控制DDPG、NAF
一.存在的问题 DQN是一个面向离散控制的算法,即输出的动作是离散的.对应到Atari 游戏中,只需要几个离散的键盘或手柄按键进行控制. 然而在实际中,控制问题则是连续的,高维的,比如一个具有6个关节 ...
- 强化学习(3)-----DQN
看这篇https://blog.csdn.net/qq_16234613/article/details/80268564 1.DQN 原因:在普通的Q-learning中,当状态和动作空间是离散且维 ...
- 深度强化学习(DQN-Deep Q Network)之应用-Flappy Bird
深度强化学习(DQN-Deep Q Network)之应用-Flappy Bird 本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-fu ...
随机推荐
- (转)Springboot+shiro配置笔记+错误小结
springboot不像springmvc,它没有xml配置文件,那该如何配置shiro呢,其实也不难,用java代码+注解来解决这个问题.仅以此篇记录我对shiro的学习,如有对过客造成不便,实在抱 ...
- cocos代码研究(21)Widget子类TextField学习笔记
基础理论 一个接受用户输入的widget. 输入文本的渲染基于TextFieldTTF. 如果你想用系统控制行为,请使用EditBox来替代.继承自 Widget. 代码实践 //与占位符有关void ...
- uva11732 Trie转化
有40001 个单词每个单词长度不超过1000,每个两个单词之间都要比较求要比较次数 int strcmp(char *s,char *t){ int i; for(i = 0; s[i]==t[i] ...
- OpenCV图像的轮廓的匹配
http://blog.sina.com.cn/s/blog_67a7426a0101cxl0.html 一个跟轮廓相关的最常用到的功能是匹配两个轮廓.如果有两个轮廓,如何比较它们;或者如何比较一个轮 ...
- c++第二十天
p111~p114: 与旧代码的接口 1.C++程序中的C风格字符串:任何出现字符串字面值的地方都可以以空字符结束的字符数组来替代. const char str[] = {"Hello, ...
- 20145221 《Java程序设计》实验报告一:Java开发环境的熟悉(Windows+IDEA)
20145221 <Java程序设计>实验报告一:Java开发环境的熟悉(Windows+IDEA) 实验要求 使用JDK编译.运行简单的Java程序: 使用IDEA 编辑.编译.运行.调 ...
- AOP AspectJ注解
概念: 切面(aspect):用来切插业务方法的类.连接点(joinpoint):是切面类和业务类的连接点,其实就是封装了业务方法的一些基本属性,作为通知的参数来解析.通知(advice):在切面类中 ...
- 框架-springmvc源码分析(一)
框架-springmvc源码分析(一) 参考: http://www.cnblogs.com/heavenyes/p/3905844.html#a1 https://www.cnblogs.com/B ...
- Python学习札记(二十二) 函数式编程3 filter & SyntaxError: unexpected EOF while parsing
参考: filter Problem SyntaxError: unexpected EOF while parsing 遇到该语法错误,一般是由于 括号不匹配 问题. Note 1.filter 用 ...
- HDU 3435 A new Graph Game(最小费用流:有向环权值最小覆盖)
http://acm.hdu.edu.cn/showproblem.php?pid=3435 题意:有n个点和m条边,你可以删去任意条边,使得所有点在一个哈密顿路径上,路径的权值得最小. 思路: 费用 ...