HDFS文件系统
Hadoop 附带了一个名为 HDFS(Hadoop分布式文件系统)的分布式文件系统,专门存储超大数据文件,为整个Hadoop生态圈提供了基础的存储服务。
本章内容:
1) HDFS文件系统的特点,以及不适用的场景
2) HDFS文件系统重点知识点:体系架构和数据读写流程
3) 关于操作HDFS文件系统的一些基本用户命令
1. HDFS特点:
HDFS专为解决大数据存储问题而产生的,其具备了以下特点:
1) HDFS文件系统可存储超大文件
每个磁盘都有默认的数据块大小,这是磁盘在对数据进行读和写时要求的最小单位,文件系统是要构建于磁盘上的,文件系统的也有块的逻辑概念,通常是磁盘块的整数倍,通常文件系统为几千个字节,而磁盘块一般为512个字节。
HDFS是一种文件系统,自身也有块(block)的概念,其文件块要比普通单一磁盘上文件系统大的多,默认是64MB。
HDFS上的块之所以设计的如此之大,其目的是为了最小化寻址开销。
HDFS文件的大小可以大于网络中任意一个磁盘的容量,文件的所有块并不需要存储在一个磁盘上,因此可以利用集群上任意一个磁盘进行存储,由于具备这种分布式存储的逻辑,所以可以存储超大的文件,通常G、T、P级别。
2) 一次写入,多次读取
一个文件经过创建、写入和关闭之后就不需要改变,这个假设简化了数据一致性的问题,同时提高数据访问的吞吐量。
3) 运行在普通廉价的机器上
Hadoop的设计对硬件要求低,无需昂贵的高可用性机器上,因为在HDFS设计中充分考虑到了数据的可靠性、安全性和高可用性。
2. 不适用于HDFS的场景:
1) 低延迟
HDFS不适用于实时查询这种对延迟要求高的场景,例如:股票实盘。往往应对低延迟数据访问场景需要通过数据库访问索引的方案来解决,Hadoop生态圈中的Hbase具有这种随机读、低延迟等特点。
2) 大量小文件
对于Hadoop系统,小文件通常定义为远小于HDFS的block size(默认64MB)的文件,由于每个文件都会产生各自的MetaData元数据,Hadoop通过Namenode来存储这些信息,若小文件过多,容易导致Namenode存储出现瓶颈。
3) 多用户更新
为了保证并发性,HDFS需要一次写入多次读取,目前不支持多用户写入,若要修改,也是通过追加的方式添加到文件的末尾处,出现太多文件需要更新的情况,Hadoop是不支持的。
针对有多人写入数据的场景,可以考虑采用Hbase的方案。
4) 结构化数据
HDFS适合存储半结构化和非结构化数据,若有严格的结构化数据存储场景,也可以考虑采用Hbase的方案。
5) 数据量并不大
通常Hadoop适用于TB、PB数据,若待处理的数据只有几十GB的话,不建议使用Hadoop,因为没有任何好处。
3. HDFS体系架构
HDFS是一个主/从(Master/Slave)体系架构,由于分布式存储的性质,集群拥有两类节点NameNode和DataNode。
NameNode(名字节点):系统中通常只有一个,中心服务器的角色,管理存储和检索多个DataNode的实际数据所需的所有元数据。
DataNode(数据节点):系统中通常有多个,是文件系统中真正存储数据的地方,在NameNode统一调度下进行数据块的创建、删除和复制。
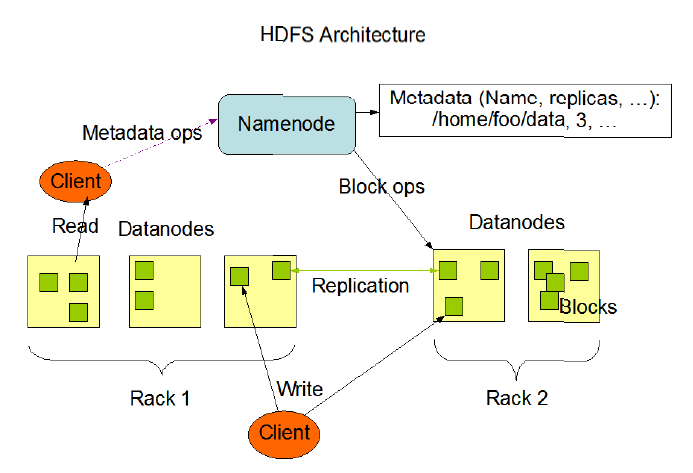
图中的Client是HDFS的客户端,是应用程序可通过该模块与NameNode和DataNode进行交互,进行文件的读写操作。
4. HDFS数据块复制
为了系统容错,文件系统会对所有数据块进行副本复制多份,Hadoop是默认3副本管理。
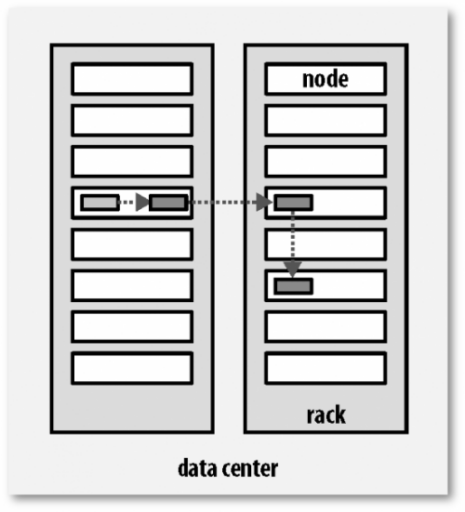
复本管理策略是运行客户端的节点上放一个复本(若客户端运行在集群之外,会随机选择一个节点),第二个复本会放在与第一个不同且随机另外选择的机架中节点上,第三个复本与第二个复本放在相同机架,切随机选择另一个节点。所存在其他复本,则放在集群中随机选择的节点上,不过系统会尽量避免在相同机架上放太多复本。
所有有关块复制的决策统一由NameNode负责,NameNode会周期性地接受集群中数据节点DataNode的心跳和块报告。一个心跳的到达表示这个数据节点是正常的。一个块报告包括该数据节点上所有块的列表。
5. HDFS读取和写入流程
1) 读文件的过程:
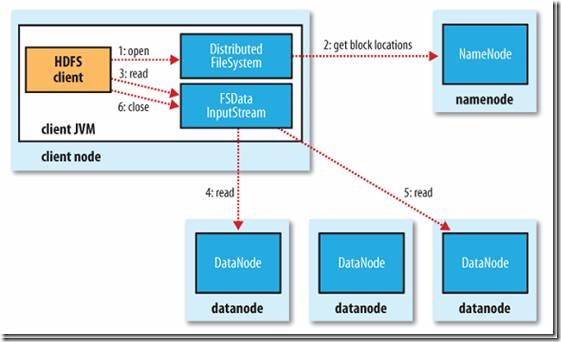
首先Client通过File System的Open函数打开文件,Distributed File System用RPC调用NameNode节点,得到文件的数据块信息。对于每一个数据块,NameNode节点返回保存数据块的数据节点的地址。Distributed File System返回FSDataInputStream给客户端,用来读取数据。客户端调用stream的read()函数开始读取数据。DFSInputStream连接保存此文件第一个数据块的最近的数据节点。DataNode从数据节点读到客户端(client),当此数据块读取完毕时,DFSInputStream关闭和此数据节点的连接,然后连接此文件下一个数据块的最近的数据节点。当客户端读取完毕数据的时候,调用FSDataInputStream的close函数。
在读取数据的过程中,如果客户端在与数据节点通信出现错误,则尝试连接包含此数据块的下一个数据节点。失败的数据节点将被记录,以后不再连接。
2) 写文件的过程:
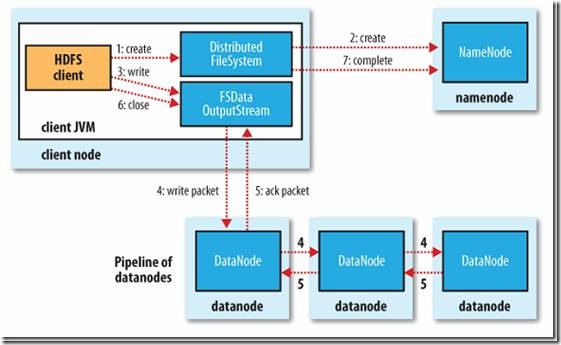
客户端调用create()来创建文件,Distributed File System用RPC调用NameNode节点,在文件系统的命名空间中创建一个新的文件。NameNode节点首先确定文件原来不存在,并且客户端有创建文件的权限,然后创建新文件。
Distributed File System返回DFSOutputStream,客户端用于写数据。客户端开始写入数据,DFSOutputStream将数据分成块,写入Data Queue。Data Queue由Data Streamer读取,并通知NameNode节点分配数据节点,用来存储数据块(每块默认复制3块)。分配的数据节点放在一个Pipeline里。Data Streamer将数据块写入Pipeline中的第一个数据节点。第一个数据节点将数据块发送给第二个数据节点。第二个数据节点将数据发送给第三个数据节点。
DFSOutputStream为发出去的数据块保存了Ack Queue,等待Pipeline中的数据节点告知数据已经写入成功。
6. 操作HDFS的基本命令
1) 打印文件列表(ls)
|
标准写法: hadoop fs -ls hdfs:/#hdfs: 明确说明是HDFS系统路径 简写: hadoop fs -ls /#默认是HDFS系统下的根目录 打印指定子目录: hadoop fs -ls /package/test/#HDFS系统下某个目录 |
2) 上传文件、目录(put、copyFromLocal)
put用法:
|
上传新文件: hdfs fs -put file:/root/test.txt hdfs:/ #上传本地test.txt文件到HDFS根目录,HDFS根目录须无同名文件,否则“File exists” hdfs fs -put test.txt /test2.txt #上传并重命名文件。 hdfs fs -put test1.txt test2.txt hdfs:/ #一次上传多个文件到HDFS路径。 上传文件夹: hdfs fs -put mypkg /newpkg #上传并重命名了文件夹。 覆盖上传: hdfs fs -put -f /root/test.txt / #如果HDFS目录中有同名文件会被覆盖 |
copyFromLocal用法:
|
上传文件并重命名: hadoop fs -copyFromLocal file:/test.txt hdfs:/test2.txt 覆盖上传: hadoop fs -copyFromLocal -f test.txt /test.txt |
3) 下载文件、目录(get、copyToLocal)
get用法:
|
拷贝文件到本地目录: hadoop fs -get hdfs:/test.txt file:/root/ 拷贝文件并重命名,可以简写: hadoop fs -get /test.txt /root/test.txt |
copyToLocal用法
|
拷贝文件到本地目录: hadoop fs -copyToLocal hdfs:/test.txt file:/root/ 拷贝文件并重命名,可以简写: hadoop fs -copyToLocal /test.txt /root/test.txt |
4) 拷贝文件、目录(cp)
|
从本地到HDFS,同put hadoop fs -cp file:/test.txt hdfs:/test2.txt 从HDFS到HDFS hadoop fs -cp hdfs:/test.txt hdfs:/test2.txt hadoop fs -cp /test.txt /test2.txt |
5) 移动文件(mv)
|
hadoop fs -mv hdfs:/test.txt hdfs:/dir/test.txt hadoop fs -mv /test.txt /dir/test.txt |
6) 删除文件、目录(rm)
|
删除指定文件 hadoop fs -rm /a.txt 删除全部txt文件 hadoop fs -rm /*.txt 递归删除全部文件和目录 hadoop fs -rm -R /dir/ |
7) 读取文件(cat、tail)
|
hadoop fs -cat /test.txt #以字节码的形式读取 hadoop fs -tail /test.txt |
8) 创建空文件(touchz)
|
hadoop fs - touchz /newfile.txt |
9) 创建文件夹(mkdir)
|
hadoop fs -mkdir /newdir /newdir2#可以同时创建多个 hadoop fs -mkdir -p /newpkg/newpkg2/newpkg3 #同时创建父级目录 |
10) 获取逻辑空间文件、目录大小(du)
|
hadoop fs - du / #显示HDFS根目录中各文件和文件夹大小 hadoop fs -du -h / #以最大单位显示HDFS根目录中各文件和文件夹大小 hadoop fs -du -s / #仅显示HDFS根目录大小。即各文件和文件夹大小之和 |
这时,你已经了解了HDFS和HDFS的操作命令,接下来我会继续介绍Mapreduce计算框架,Mapreduce在hadoop中又起到什么作用呢?
HDFS文件系统的更多相关文章
- 搭建maven开发环境测试Hadoop组件HDFS文件系统的一些命令
1.PC已经安装Eclipse Software,测试平台windows10及Centos6.8虚拟机 2.新建maven project 3.打开pom.xml,maven工程项目的pom文件加载以 ...
- HDFS文件系统基本文件命令、编程读写HDFS
基本文件命令: 格式为:hadoop fs -cmd <args> cmd的命名通常与unix对应的命令名相同.例如,文件列表命令: hadoop fs -ls 1.添加目录和文件 HDF ...
- hadoop系列二:HDFS文件系统的命令及JAVA客户端API
转载请在页首明显处注明作者与出处 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据的一些内容,如hadoop,spark,storm,机器学习等. 当前使用的hadoop版本为2.6 ...
- hdfs文件系统架构详解
hdfs文件系统架构详解 官方hdfs分布式介绍 NameNode *Namenode负责文件系统的namespace以及客户端文件访问 *NameNode负责文件元数据操作,DataNode负责文件 ...
- hue上配置HA的hdfs文件(注意,HA集群必须这样来配置才能访问hdfs文件系统)
按照正常方式配置,发现无论如何也访问不了hdfs文件系统,因为我们是HA的集群,所以不能按照如下配置 将其改为 除此之外,还需要配置hdfs文件的 接着要去hadoop的目录下启动httpfs.sh ...
- Ubuntu本地文件上传至HDFS文件系统出现的乱码问题及解决方案
1.问题来源及原因 用shell命令上传到HDFS中之后出现中文乱码,在shell命令窗口查看如图: 在eclipse中的文件HDFS查看工具查看如图: 原因:上传至HDFS文件系统的文本文件(这里是 ...
- 使用Java API操作HDFS文件系统
使用Junit封装HFDS import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; import org ...
- Hadoop Shell命令(基于linux操作系统上传下载文件到hdfs文件系统基本命令学习)
Apache-->hadoop的官网文档命令学习:http://hadoop.apache.org/docs/r1.0.4/cn/hdfs_shell.html FS Shell 调用文件系统( ...
- HDFS文件系统的JAVA-API操作(一)
使用java.net.URL访问HDFS文件系统 HDFS的API使用说明: 1.如果要访问HDFS,HDFS客户端必须有一份HDFS的配置文件 也就是hdfs-site.xml,从而读取Nameno ...
随机推荐
- js的数组与对象关系
有的时候总犯糊涂,不理解对象和数组的关系,转载一篇文章,深刻记忆一下 http://hi.baidu.com/samdan/item/05179313d1ee4b9e99ce3371 比如有一个数组a ...
- hive row_number等窗口分析函数
一.排序&去重分析 row_number() over(partititon by col1 order by col2) as rn 结果:1,2,3,4 rank() over(parti ...
- rspec-rails中的一些匹配器只有在特定的类型才能使用。
请求测试 ) expect(response).not_to have_http_status(:created) Model Specs描述模型的行为,一般基于数据库. Request Spec 主 ...
- css强制html不换行 css强制英文单词断行 重拾丢失的
css强制html不换行 css强制英文单词断行 强制不换行 div{ white-space:nowrap; } 自动换行 div{ word-wrap: break-word; word-brea ...
- (C#基础)深浅拷贝理解
一方面感觉实在无趣,不知道做什么了,纯粹来个打字练习,于是有了这个. 二方面深感自己C#基础之薄弱,于是对着园友的文章一边看,一边练习,因为很多次看了,没有多久就忘了,还有练习过程中会出现一些问题,这 ...
- C++设计模式之享元模式
概述 想想我们编辑文档用的wps,文档里文字很多都是重复的,我们不可能为每一个出现的汉字都创建独立的空间,这样代价太大,最好的办法就是共享其中相同的部分,使得需要创建的对象降到最小,这个就是享元模式的 ...
- Beta阶段第2周/共2周 Scrum立会报告+燃尽图 08
作业要求[https://edu.cnblogs.com/campus/nenu/2018fall/homework/2389] 版本控制:https://git.coding.net/liuyy08 ...
- addpath
这个命令见得很多了,一直懒得理他,自己直接加绝对路径.但是,这个破命令出现太多,我改得都掉脾气,写写. 1. 添加路径:addpath('当前路径中的文件夹名1','当前路径下的文件夹名2','当前 ...
- Ubuntu下的计算器
今天计算乘法时居然给算错了,好囧. 于是开始使用ubuntu自带的计算器:gcalctool 使用方法: 在终端直接输入命令gcalctool即可.
- .net 微信支付(公众号支付)遇到的问题
啥也不说了搬砖的都知道老板说是什么就是什么 最近我老板让饿哦做一个微信支付的功能 还带微信上面京东众筹活动的那种,我买东西别人出钱的那种 然后用微信支付 我是新手之前也没有做过这个 所以估计着过程中 ...