Hadoop(13)-MapReduce框架原理--Job提交源码和切片源码解析
1.MapReduce的数据流

1) Input -> Mapper阶段
这一阶段的主要分工就是将文件切片和把文件转成K,V对
输入源是一个文件,经过InputFormat之后,到了Mapper就成了K,V对,以上一章的流量案例来说,经过InputFormat之后,变成了手机号为key,这一行数据为value的K,V对,所以这里我们可以自定义InputFormat,按照具体的业务来实现将文件切片并且转为K,V对的方式
2) Mapper -> Reducer阶段
这一阶段叫做shuffle(洗牌)阶段,从Mapper出来的数据是无序的K,V对,那到了Reducer阶段,就变成了有序了.所以我们可以自定义排序规则
3) Reducer -> Output阶段
文件数据经过之前的种种处理,已经变成了有序的数据,这一阶段就是将数据写入文件
2.数据切片与MapTask并行度决定机制
问题引出
MapTask的并行度决定Map阶段的任务处理并发度,进而影响到整个Job的处理速度。
思考:1G的数据,启动8个MapTask,可以提高集群的并发处理能力。那么1K的数据,也启动8个MapTask,会提高集群性能吗?MapTask并行任务是否越多越好呢?哪些因素影响了MapTask并行度?
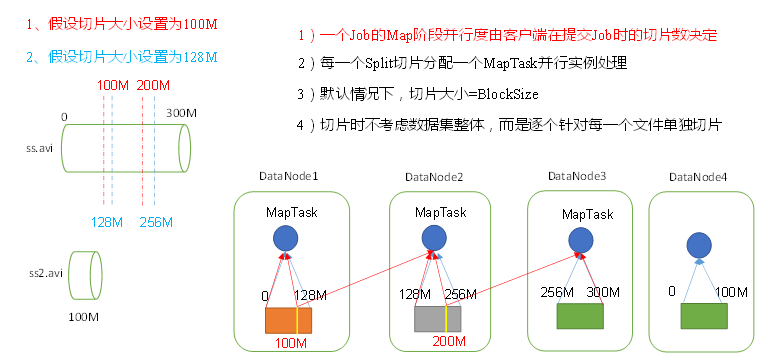
一个300M的数据,按照blocksize=128M进行存储,在datanode上分别是0-128m,128m-256m,256m-300m
1) 红线切片,将数据按照100M进行切片,每个MapTask处理同样大小的100M数据,看似很公平,datanode1的MapTask处理100M数据,剩下的28m传输给datanode2的MapTask,datanode2的MapTask处理28m+本地的72m数据,剩下的56m再传输给datanode3的MapTask.这样就增加了84m的网络传输数据.为了减少网络传输,yarn有一个本地原则,即block保存在哪个节点上,就在哪个节点上启动MapTask
2) 蓝线切片,切片大小128m=blocksize,每一个datanode启动的MapTask处理的数据都是128m,虽然看似处理速度比1)的100m慢一些,但是却节省了紧张的网络传输资源
所以约定俗成的,切片大小=blocksize
3.Job提交流程源码


确定job的输出路径是否有问题



创建jobid和临时文件夹

生成job的配置信息

经过这一步写入后,文件夹里就有了文件


最后提交job

整理一下
waitForCompletion() submit(); // 1建立连接
connect();
// 1)创建提交Job的代理
new Cluster(getConfiguration());
// (1)判断是本地yarn还是远程
initialize(jobTrackAddr, conf); // 2 提交job
submitter.submitJobInternal(Job.this, cluster)
// 1)创建给集群提交数据的Stag路径
Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf); // 2)获取jobid ,并创建Job路径
JobID jobId = submitClient.getNewJobID(); // 3)拷贝jar包到集群
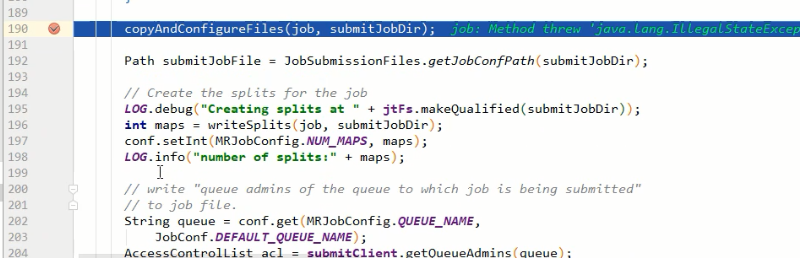
copyAndConfigureFiles(job, submitJobDir);
rUploader.uploadFiles(job, jobSubmitDir); // 4)计算切片,生成切片规划文件
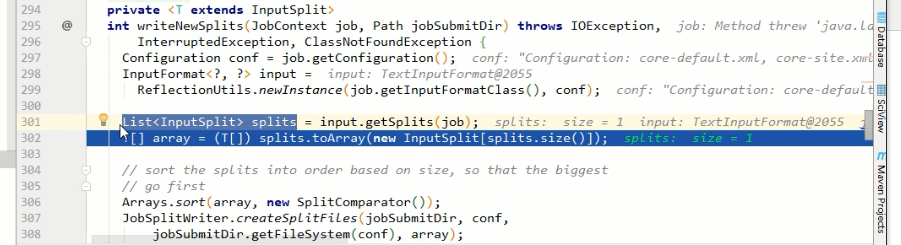
writeSplits(job, submitJobDir);
maps = writeNewSplits(job, jobSubmitDir);
input.getSplits(job); // 5)向Stag路径写XML配置文件
writeConf(conf, submitJobFile);
conf.writeXml(out); // 6)提交Job,返回提交状态
status = submitClient.submitJob(jobId, submitJobDir.toString(), job.getCredentials());
4.FileInputFormat切片机制
上一小章的job提交流程里,生成的临时文件夹里面,有一个job.split文件,说明切片是在job提交之前就切好了,是本地的Driver类做的
那么就再追一下切片源码


最小值minsize=1,最大值maxsize是long的最大值

遍历input源的文件夹,对每一个文件进行切片,先判断文件是否可切
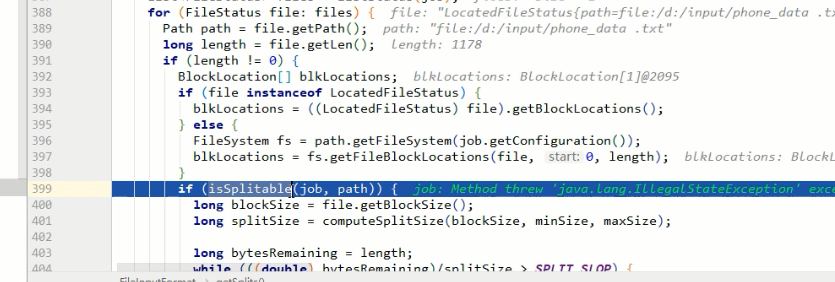
计算切片大小

如,minsize=1,blocksize=32G(33554432),maxsize=9223372036854775807
通过计算,返回的是blocksize.也就是返回的中间值
如果想增加切片大小,那么就增加minsize的大小到>blocksize,如果想减小切片大小,那么就减小maxsize大小到<blocksize

bytesRemaining是文件的大小,根据上面计算到的splitSize来进行切片
404行的SPLIT_SLOP的值是1.1,比的时候是按1.1倍来比,而409行切的时候是按1倍来切
假如blocksize=32M,现在要切一个32.001M的文件,为了多出来的1k启动一个MapTask,很浪费不值当~,所以这样做是为了保证,切出来的片,至少是blocksize大小的10%以上,如果不够10%,那就交给最后的MapTask哥们来处理好了
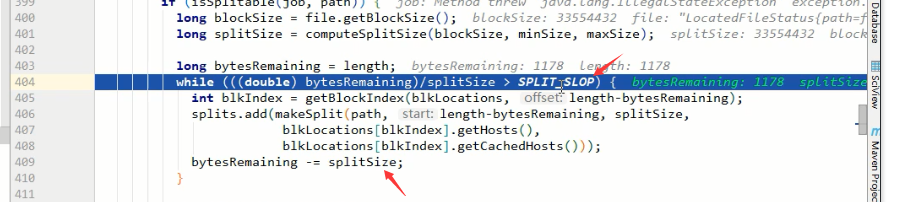
最后将切片放到切片list里

总结一下

Hadoop(13)-MapReduce框架原理--Job提交源码和切片源码解析的更多相关文章
- MapReduce之Job提交流程源码和切片源码分析
hadoop2.7.2 MapReduce Job提交源码及切片源码分析 首先从waitForCompletion函数进入 boolean result = job.waitForCompletion ...
- 大数据入门第七天——MapReduce详解(二)切片源码浅析与自定义patition
一.mapTask并行度的决定机制 1.概述 一个job的map阶段并行度由客户端在提交job时决定 而客户端对map阶段并行度的规划的基本逻辑为: 将待处理数据执行逻辑切片(即按照一个特定切片大小, ...
- Hadoop(12)-MapReduce框架原理-Hadoop序列化和源码追踪
1.什么是序列化 2.为什么要序列化 3.为什么不用Java的序列化 4.自定义bean对象实现序列化接口(Writable) 在企业开发中往往常用的基本序列化类型不能满足所有需求,比如在Hadoop ...
- Hadoop(17)-MapReduce框架原理-MapReduce流程,Shuffle机制,Partition分区
MapReduce工作流程 1.准备待处理文件 2.job提交前生成一个处理规划 3.将切片信息job.split,配置信息job.xml和我们自己写的jar包交给yarn 4.yarn根据切片规划计 ...
- Hadoop(18)-MapReduce框架原理-WritableComparable排序和GroupingComparator分组
1.排序概述 2.排序分类 3.WritableComparable案例 这个文件,是大数据-Hadoop生态(12)-Hadoop序列化和源码追踪的输出文件,可以看到,文件根据key,也就是手机号进 ...
- Hadoop(16)-MapReduce框架原理-自定义FileInputFormat
1. 需求 将多个小文件合并成一个SequenceFile文件(SequenceFile文件是Hadoop用来存储二进制形式的key-value对的文件格式),SequenceFile里面存储着多个文 ...
- Hadoop(20)-MapReduce框架原理-OutputFormat
1.outputFormat接口实现类 2.自定义outputFormat 步骤: 1). 定义一个类继承FileOutputFormat 2). 定义一个类继承RecordWrite,重写write ...
- Hadoop(14)-MapReduce框架原理-切片机制
1.FileInputFormat切片机制 切片机制 比如一个文件夹下有5个小文件,切片时会切5个片,而不是一个片 案例分析 2.FileInputFormat切片大小的参数配置 源码中计算切片大小的 ...
- Hadoop(19)-MapReduce框架原理-Combiner合并
1. Combiner概述 2. 自定义Combiner实现步骤 1). 定义一个Combiner继承Reducer,重写reduce方法 public class WordcountCombiner ...
随机推荐
- 让CPU的占用率听你的指挥
此题目具有很大的想象空间,尤其是多核环境下. 详见:http://hi.baidu.com/jeschou/item/53da6df6a8d25209d99e722d
- MongoDB数据库 备份 还原
MongoDB数据库 1.备份用 mongodump 2.还原用 mongorestore 1.备份 @echo offecho 正在备份MongoDB数据库SET mon ...
- monkeyrunner之安卓开发环境搭建(二)
在上一篇文章-安卓开发环境搭建中,我们创建并启动了eclipse自带的安卓模拟器,该模拟器不仅启动慢,而且在使用过程中的反应速度也是出奇的差,经常出现卡机现象.为了解决这种现象,因此,我们又寻找到了更 ...
- 配置karma支持Chrome浏览器
准备:项目中已搭建好了karma. 前言:利用vue-cli初始化创建vue项目时,已经搭建好了测试框架 karma+mocha,但是此时karma默认启动的浏览器是 phantomjs,而我想用 C ...
- mysql 统计连续天数
以下为例子数据 图1 图1 首先根据要求取出BeforeMeal要在7.0以下 并且 bingAfterMeal要在11.1以下 select AccountId,CreateTime from Di ...
- mysql 省市数据
CREATE TABLE `province` ( `id` ) DEFAULT NULL, `name` ) DEFAULT NULL ) ENGINE=INNODB DEFAULT CHARSET ...
- makefile 编译指定目录
makefile 编译指定目录 sub1=test1 sub2=test2 subs = sub1 sub2 SUBDIRS =$(foreach i, $(subs), $($(i))) .PHON ...
- sql 2008 远程过程调用失败 0x800706be
啊哦,SQL Server挂了!sql 2008 远程过程调用失败 0x800706be,找了一下解决方案,如下: 1.打开控制面板->添加删除程序 2.卸载一个叫Microsoft SQL S ...
- 每天一个linux命令(22):tar命令
通过SSH访问服务器,难免会要用到压缩,解压缩,打包,解包等,这时候tar命令就是是必不可少的一个功能强大的工具.linux中最流行的tar是麻雀虽小,五脏俱全,功能强大. tar命令可以为linux ...
- c++11之100行实现简单线程池
代码从github上拷的,写了一些理解,如有错误请指正 Threadpool.h #ifndef THREAD_POOL_H #define THREAD_POOL_H #include <ve ...