Java8函数之旅 (七) - 函数式备忘录模式优化递归
前言
在上一篇开始Java8之旅(六) -- 使用lambda实现Java的尾递归中,我们利用了函数的懒加载机制实现了栈帧的复用,成功的实现了Java版本的尾递归,然而尾递归的使用有一个重要的条件就是递归表达式必须是在函数的尾部,但是在很多实际问题中,例如分治,动态规划等问题的解决思路虽然是使用递归来解决,但往往那些解决方式要转换成尾递归花费很多精力,这也违背了递归是用来简洁地解决问题这个初衷了,本篇介绍的是使用备忘录模式来优化这些递归,并且使用lambda进行封装,以备复用。
回顾
为了回顾上一章节,同时用本章的例子作对比,我们这里使用经典的斐波那契数列求解问题作为例子来讲解。
斐波那契数列表示这样的一组数 1,1,2,3,5,8,13.... 其表现形式为数列的第一个和第二个数为1,其余的数都是它前两位数的和,用公式表示为
\begin{aligned}
1, n <= 1\\
a_{n-1} + a_{n-2} , n > 1
\end{aligned}
,n\in N
\right.\]
递归求解
这里我们依据上面的数列公式直接使用递归解法求解该问题
/**
* 递归求解斐波那契数列
*
* @param n 第n个斐波那数列契数
* @return 斐波那契数列的第n个数
*/
public static long fibonacciRecursion(long n) {
if (n <= 1) return 1;
return fibonacciRecursion(n - 1) + fibonacciRecursion(n - 2);
}
/**
* 递归测试斐波那契数列
*/
@Test
public void testFibonacciRec() {
long start = System.nanoTime();
System.out.println(fibonacciRecursion(47));
System.out.printf("cost %.2f ms %n", (System.nanoTime() - start) / Math.pow(10, 6));
}
这里我们测试当n等于47的时候,所要花费的时间
4807526976
cost 13739.30 ms
Process finished with exit code 0
可以看出,递归的写法虽然简洁,但是消耗的时间是成指数级的。
尾递归求解
这里回顾上一章内容,使用尾递归求解,具体这里的尾递归接口的实现这里就不贴出来了(点击这里查看),下面是尾递归的具体调用代码,增加两个变量分别保存\(a_{n-2}\)与\(a_{n-1}\) 在下面的形参对应的分别是accPrev与accNext,尾递归是自底向上的,你可以理解成迭代的方式,每次调用递归将\(a_{n-1}\)赋值给\(a_{n-2}\),将\(a_{n-1} + a_{n-2}\) 赋值给 \(a_{n-1}\)
/**
* 尾递归求解斐波那契数列
* @param accPrev 第n-1个斐波那契数
* @param accNext 第n个斐波那契数
* @param n 第n个斐波那契数
* @return 包含了一系列斐波那契的完整计算过程,调用invoke方法启动计算
*/
public static TailRecursion<Long> fibonacciRecursionTail(final long accPrev,final long accNext, final long n) {
if (n <= 1) return TailInvoke.done(accNext);
return TailInvoke.call(() -> fibonacciRecursionTail(accNext, accPrev + accNext, n - 1));
}
/**
* 尾递归测试斐波那契数列
*/
@Test
public void testFibonacciTailRec() {
long start = System.nanoTime();
System.out.println(fibonacciRecursionTail(1,1,47).invoke());
System.out.printf("cost %.2f ms %n", (System.nanoTime() - start) / Math.pow(10, 6));
}
同样测试当n等于47的时候,所要花费的时间
4660046610375530309
cost 97.67 ms
Process finished with exit code 0
可以看出花费的时间是线性级别的,但是因为这里的尾递归是手动封装的,所以接口类的建立以及lambda表达式的调用等一些基本开销占用了大部分的时间,但是这是常数级别的时间,计算过程本身几乎不花费什么时间,所以性能也是十分好的。
迭代求解
尾递归在优化之后在计算过程上就变成了自底向上,因此也就是转变成了迭代的过程,这里大家配合迭代求解来理解尾递归求解应该会容易许多。
/**
* 斐波那契的迭代解法,自底向上求解
* @param n 第n个斐波那契数
* @return 第n个斐波那契数
*/
public static long fibonacciIter(int n) {
long prev = 1;
long next = 1;
long accumulate = 0;
for (int i = 2; i <= n; i++) {
accumulate = prev + next;
prev = next;
next = accumulate;
}
return accumulate;
}
/**
* 迭代测试斐波那契数列
*/
@Test
public void testFibonacciIter() {
long start = System.nanoTime();
System.out.println(fibonacciIter(47));
System.out.printf("cost %.2f ms %n", (System.nanoTime() - start) / Math.pow(10, 6));
}
同样测试当n等于47的时候,所要花费的时间
4660046610375530309
cost 0.09 ms
Process finished with exit code 0
这里只花费了0.09ms,其实迭代计算的时间和尾递归理论上应该是差不多的,但是上文也说到了,尾递归由于是自己的封装接口并且本身使用lambda也会有一定的开销,所以会造成一些性能上的差异。
分析递归效率低下的原因
可以看到上面的三种解决方案,尾递归与迭代的效率是可以接受的,而递归虽然写起来最短,但是时间复杂度是指数级别的,完全不能够接受,那么这里就分析为什么第一种的递归如此之慢,而第二种与第三种就要快上很多。
第一种的解决思路是最直接的,假设我们要求解f(5)这个数,我们会将问题转化成f(3) + f(4),接着再转化
成f(1)+f(2)+f(2)+f(3)...依次类推,如图所示
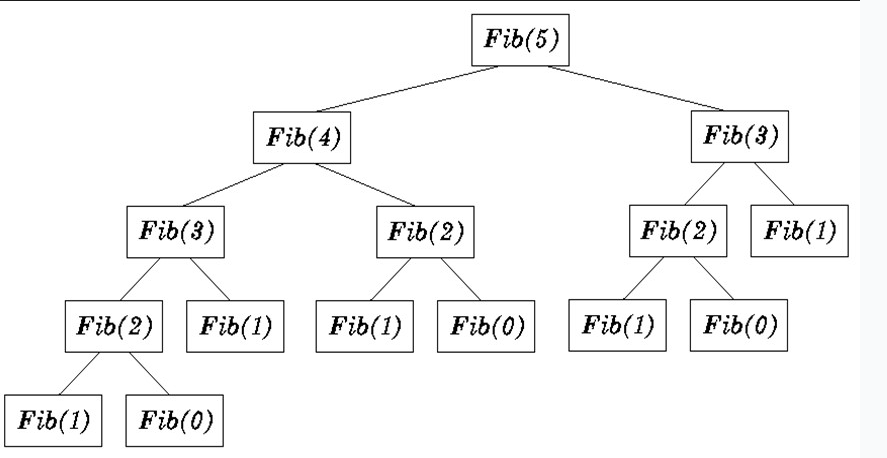
通过简单的观察可以发现,这里的f(0),f(1),f(2)等被重复计算了很多次,随着树的高度的提升,这样的重复计算会以指数级别的程度增长,这就是为什么第一种递归解法的效率为什么这么低下的原因。
那么我们来看看为什么尾递归与迭代的效率会这么高,前面也说到了,经过优化之后的尾递归与迭代的计算方式是自底向上的,同样以计算f(5)为例子,他们不是从f(5)开始往下计算,而是从前往后,先计算出f(2)然后根据f(2)计算出(3)再根据f(2)与f(3)计算出(f4)最终计算出f(5),也就是说,自底向上的每一次计算都运用到了前面计算的结果,因此中间过程并没有重复的计算,所以效率很高。
经过上面的总结,我们得出了如果想要递归高效的进行,那么要解决的就是如何避免重复的计算,也就是要利用之前已经计算过的结果。
使用备忘录模式存储结果
经过上面的分析,我们得到了要想解决效率问题,就必要存储并且重复利用之前的计算结果,因此显而易见的我们这里使用散列表这个数据结构来存储这些信息。
我们将已经计算过的结果存储在散列表里,下一次遇到需要计算这个问题的时候直接取出来,如果散列表里没有这样的数据,我们才进行计算并且存储计算结果,把他想象成计算结果的缓存来理解。
Before Java8
为了保证线程安全我们使用synchronized关键字与double-check来保证,代码如下
private static final Map<Integer, Long> cache = new HashMap<>();
/**
* 使用备忘录模式来利用重复计算结果
* @param n 第n个斐波那契数
* @return 第n个斐波那契数
*/
public static long fibonacciMemo(int n) {
if (n == 0 || n == 1) return n;
Long exceptedNum = cache.get(n);
if (exceptedNum == null) {
synchronized (cache) {
exceptedNum = cache.get(n);
if (exceptedNum == null) {
exceptedNum = fibRecurOpt(n - 1) + fibRecurOpt(n - 2);
cache.put(n, exceptedNum);
}
}
}
return exceptedNum;
}
In Java8
这样的代码虽然可以达到效率的优化,但是不管是复用性还是可读性基本上为0,因此这里我们使用java8 Map结构新增的computeIfAbsent,该方法接受两个参数,一个key值,一个是function计算策略,从字面意思也可以明白,作用就是如果key值为空,那么就执行后面的function策略,因此使用computeIfAbsent后的优化代码如下
private static final Map<Integer, Long> cache = new HashMap<>();
/**
* 使用computeIfAbsent来优化备忘录模式
* @param n
* @return
*/
public static long fibonacciMemoOpt(int n) {
if (n == 0 || n == 1) return n;
return cache.computeIfAbsent(n, key -> fibRecurLambdaOpt(n - 1) + fibRecurLambdaOpt(n - 2));
}
这样代码的可读性就高了不少,每次调用递归方法的时候直接返回cache里的计算结果,如果没有该计算结果,那么就执行后面一段计算过程来得到计算结果,下面进行时间的测试。
/**
* 测试备忘录模式递归求解
*/
@Test
public void testFibonacciMemoOpt(){
long start = System.nanoTime();
System.out.println(fibonacciMemoOpt(47));
System.out.printf("cost %.2f ms %n", (System.nanoTime() - start) / Math.pow(10, 6));
}
输出结果为
2971215073
cost 80.36 ms
Process finished with exit code 0
发现运行的时间已经大大的减少了,并且消耗时间和之前的尾递归几乎差不多。
到这一步,大部分工作已经完成了,递归代码也十分的简短高效,剩下的就是复用了,接下来我们对上述的分析过程进行抽象,将备忘录模式完全封装,这样以后需要使用类似的情况可以直接使用。
使用lambda封装上述备忘录模式优化递归
签名设计
其实看一看标题,感觉似乎一直到现在才讲到重点,其实我也考虑过直接跳过上面所有的介绍写这里,但是我觉得如果这么写的话,给人的感觉会太直接,上一篇尾递归的封装我就有这样的感觉,感觉似乎太直接了,没有具体的分析过程就直接封装,感觉可读性不是很高,所以这一篇花了比较长的篇幅来一步一步讲解整个的过程,希望能让大家更容易的去理解。
首先我们要考虑设计的封装需要几个参数,这里应该是两个,分别是 斐波那契的算法策略 与输入值,也就是说我们向这个备忘录方法传入一个斐波那契的算法策略function,以及一个输入值n,这个备忘录方法就应该返回正确的结果给我们,因此这个方法的签名初步构想应该是这样的
public static <T, R> R callMemo(final Function<T,R> function, final T input)
- T为输入值类型
- R为返回值类型
- function 为具体的计算策略,这这里的例子中,就是斐波那契的计算策略
但这仅仅是初步构想,这里会碰到的一个问题就是,因为我们的策略是递归策略,因此必须要有一个方法名,而众所周知,lambda函数全部是匿名的,也就是说,直接单纯的使用lambda根本无法递归调用,因为lambda方法没有名字,怎么调用自己呢? 那该怎么办呢?其实很简单,我们只需要再封装一层,也就是说将策略本身作为参数来传递,然后使用this调用即可,这里的思想其实就是利用了尾递归的思想,将每一次递归调用需要的策略本身作为参数来传递。
因此我们上面参数的function 要稍作修改,增加一个策略本身作为参数,因此function的类型应该是BiFunction<Function<T,R>,T,R> 仔细观察一下泛型里的类型,只是由原来的<T,R>在前面多了一个策略本身参数Function<T,R>,这样2个参数的组合我们使用BiFunction,因此最终的方法签名如下
public static <T, R> R callMemo(final BiFunction<Function<T,R>,T,R> function, final T input)
知晓了方法签名与每一个参数的意思之后,完成最终的实现就十分容易了
具体实现
/**
* 备忘录模式 函数封装
* @param function 递归策略算法
* @param input 输入值
* @param <T> 输出值类型
* @param <R> 返回值类型
* @return 将输入值输入递归策略算法,计算出的最终结果
*/
public static <T, R> R callMemo(final BiFunction<Function<T, R>, T, R> function, final T input) {
Function<T, R> memo = new Function<T, R>() {
private final Map<T, R> cache = new HashMap<>(64);
@Override
public R apply(final T input) {
return cache.computeIfAbsent(input, key -> function.apply(this, key));
}
};
return memo.apply(input);
}
这里为了保证这个散列表Map每次只为一个递归策略服务,我们在方法内部实例化一个实现function的类,并将Map存入其中,这样就能够保证Map服务的唯一性,在apply方法中 cache.computeIfAbsent(input, key -> function.apply(this, key))这一句就是为什么方法的签名要多一个function的参数原因,因为策略是递归策略,lambda函数没有名字,所以必须显示的将他存入参数中,这样才能完成递归调用,这里使用this将自己本身作为策略传递下去。
此时我们要调用的话,只需要将完成这个策略即可,调用代码如下
/**
* 使用同一封装的备忘录模式 执行斐波那契策略
* @param n 第n个斐波那契数
* @return 第n个斐波那契数
*/
public static long fibonacciMemo(int n) {
return callMemo((fib, number) -> {
if (number == 0 || number == 1) return 1L;
return fib.apply(number -1 ) + fib.apply(number-2);
}, n);
}
最终代码
这样调用的可读性可能有点差,因此我们将第一个参数抽离出来,使用方法引用来调用,最终代码如下
public class Factorial {
/**
* 使用统一封装的备忘录模式 对外开放的方法,在内部执行具体的斐波那契策略 {@link #fibonacciCallMemo(Function, Integer)}
* @param n 第n个斐波那契数
* @return 第n个斐波那契数
*/
public static long fibonacciMemo(int n) {
return callMemo(Factorial::fibonacciCallMemo, n);
}
/**
* 私有方法,服务于{@link #fibonacciMemo(int)} ,内部实现为斐波那契算法策略
* @param fib 斐波那契算法策略自身,用于递归调用, 在{@link #callMemo(BiFunction, Object)} 中通过传入this来实例这个策略
* @param n 第n个斐波那契数
* @return 第n个斐波那契数
*/
private static long fibonacciCallMemo(Function<Integer,Long> fib,Integer n){
if (n == 0 || n == 1) return 1;
return fib.apply(n -1 ) + fib.apply(n-2);
}
/**
* 备忘录模式 函数封装
* @param function 递归策略算法
* @param input 输入值
* @param <T> 输出值类型
* @param <R> 返回值类型
* @return 将输入值输入递归策略算法,计算出的最终结果
*/
public static <T, R> R callMemo(final BiFunction<Function<T, R>, T, R> function, final T input) {
Function<T, R> memo = new Function<T, R>() {
private final Map<T, R> cache = new HashMap<>(64);
@Override
public R apply(final T input) {
return cache.computeIfAbsent(input, key -> function.apply(this, key));
}
};
return memo.apply(input);
}
}
通过调用fibonacciMemo(47)方法来计算时间,输出结果为
4807526976
cost 69.19 ms
Process finished with exit code 0
运转良好,并且复用性强,每次使用这个模式的时候并不需要编写额外的代码,也不需要考虑内部的Map的线程安全或者是策略独立。
运用
这里我们是用来解决斐波那契数列递归问题,下面我们分别用于经典的分治算法-汉诺塔递归问题与动态规划-分割杆问题,篇幅有限,这两个问题我不作具体说明了,直接给出初始的递归解法代码,(具体的问题点击上面两个问题的蓝色链接即可)来看看该如何使用我们封装好的备忘录模式方法。
汉诺塔递归问题
汉诺塔递归问题一般有2个,一个问最少要移动多少次,另一个一般是要给出具体的每一步的过程
- 先看最少要移动多少次这个问题
递归代码如下
public int countMovePlate(int n) {
if (n <= 1) return 1;
return countMovePlate(n - 1) + 1 +countMovePlate(n - 1);
}
使用我们的备忘录模式来优化解决如下(同样可以使用上文的方法引用抽离第一个参数,使得代码可读性更高)
public long countMovePlateMemo(int n) {
return callMemo((count, num) ->{
if (n <=1 ) return 1L;
return count.apply(num) + 1 + count.apply(num);
},n );
}
- 再看具体的每一步的移动过程
递归代码如下
public void movePlate(int n, String from, String mid, String to) {
if (n <= 1) {
System.out.println(from + " -> " + to);
return;
}
movePlate(n - 1, from, to, mid);
System.out.println(from + " -> " + to);
movePlate(n - 1, mid, from, to);
}
这里我们使用方法引用,由于哈诺塔具体移动的初始代码有4个参数,因此我们将参数存入数组中来处理,可以看到和原先的代码相比,只是增加了一个参数处理,就使用了备忘录模式,完全隐去了细节
public class movePlate{
public static boolean movePlateMemo(int n, String from, String mid, String to){
Object[] params = {n, from, mid, to};
return callMemo(movePlate::movePlateCallMemo,params);
}
private static boolean movePlateCallMemo(Function<Object[],Boolean> function,Object[] params) {
// 将数组里的参数初始化,这样不影响之前的代码
int n = (int) params[0];
String from = (String) params[1];
String mid = (String) params[2];
String to = (String) params[3];
//原先的递归代码,没有差别,将递归调用转换成为function.apply()
if (n <= 1) {
System.out.println(from + " -> " + to);
return true;
}
function.apply(new Object[]{n - 1, from, to, mid});
System.out.println(from + " -> " + to);
function.apply(new Object[]{n - 1, mid, from, to});
return false;
}
}
测试是否可行,输入参数3,A,B,C,发现运转良好
A -> c
A -> B
c -> B
A -> c
B -> A
B -> c
A -> c
Process finished with exit code 0
杆切割问题
初始递归代码
public int maxProfit(final int length) {
int profit = (length <= prices.size()) ? prices.get(length - 1) : 0;
for(int i = 1; i < length; i++) {
int priceWhenCut = maxProfit(i) + maxProfit(length - i);
if(profit < priceWhenCut) profit = priceWhenCut;
}
return profit;
}
同样的简单更改一下递归处的调用就可以更改为备忘录的优化,这里为了节省代码不使用方法引用,直接实现
public int maxProfit(final int rodLenth) {
return callMemo(
(func,length) -> {
int profit = (length <= prices.size()) ? prices.get(length - 1) : 0;
for(int i = 1; i < length; i++) {
int priceWhenCut = func.apply(i) + func.apply(length - i);
if(profit < priceWhenCut) profit = priceWhenCut;
}
return profit;
}, rodLenth);
}
总结
不得不承认,这一章的内容是比较难的,尤其是在对递归方法的签名设计上,要理解这一切需要有一定的函数编程设计的理解,所以我用了很长的篇幅来一步步讲述为什么要这么封装,前面的设计为什么要这么设计,以及最后选了斐波那契,汉诺塔,杆切割的原始递归代码来优化成备忘录模式,习惯了面向对象的设计在碰到函数式的方式设计的时候确实容易一头包,不过没有人生下来就会这一切,因此我在这里想说的是,practise makes perfect,熟能生巧,希望每个人都能成为自己心目中的大师
Java8函数之旅 (七) - 函数式备忘录模式优化递归的更多相关文章
- Java8之旅(七) - 函数式备忘录模式优化递归
前言 在上一篇开始Java8之旅(六) -- 使用lambda实现Java的尾递归中,我们利用了函数的懒加载机制实现了栈帧的复用,成功的实现了Java版本的尾递归,然而尾递归的使用有一个重要的条件就是 ...
- Java8函数之旅 (八) - 组合式异步编程
前言 随着多核处理器的出现,如何轻松高效的进行异步编程变得愈发重要,我们看看在java8之前,使用java语言完成异步编程有哪些方案. JAVA8之前的异步编程 继承Thead类,重写run方法 实现 ...
- 七、备忘录模式Memento(行为型模式)
其目的是,在不违反封装原则的前提下.採集和备份一个对象的内部状态以便这个对象能够在以后恢复到之前的某个状态. 在Memento模式中,有例如以下角色: 1.Memento (备忘录) * 存储Orig ...
- Java8函数之旅 (二) --Java8中的流
流与集合 众所周知,日常开发与操作中涉及到集合的操作相当频繁,而java中对于集合的操作又是相当麻烦.这里你可能就有疑问了,我感觉平常开发的时候操作集合时不麻烦呀?那下面我们从一个例子说起. 计 ...
- Java8函数之旅(四) --四大函数接口
前言 Java8中函数接口有很多,大概有几十个吧,具体究竟是多少我也数不清,所以一开始看的时候感觉一脸懵逼,不过其实根本没那么复杂,毕竟不应该也没必要把一个东西设计的很复杂. 几个单词 在学习 ...
- Java8函数之旅 (一) 开始认识lambda
系列之前我想说的 最近有一段时间没写博客了,这几天回到学校,才闲下来,决定写一写最近学习到的知识,既是为了分享,也是为了巩固.之前看到过一篇调查,调查说的是学习新知识,光只是看的话,知识的获取率只 ...
- Java8函数之旅 (三) --几道关于流的练习题
为什么要有练习题? 所谓学而不思则罔,思而不学则殆,在系列第一篇就表明我认为写博客,既是分享,也是自己的巩固,我深信"纸上得来终觉浅,绝知此事要躬行"的道理,因此之后的几篇博 ...
- Java8函数之旅 (六) -- 使用lambda实现Java的尾递归
前言 本篇介绍的不是什么新知识,而是对前面讲解的一些知识的综合运用.众所周知,递归是解决复杂问题的一个很有效的方式,也是函数式语言的核心,在一些函数式语言中,是没有迭代与while这种概念的,因为此类 ...
- Java8函数之旅 (五) -- Java8中的排序
前言 对数据进行排序是平常经常会用到的操作之一,使用Jav8排序可以减少你在排序这方面的代码量,优化你的代码. 测试用例代码 定义个实体类User,拥有姓名name,年龄age,积分credit ...
随机推荐
- angular2 遇到的问题汇总
angular2 学习资源集锦:https://github.com/timjacobi/angular2-education 在学习angular开发项目过程遇到的问题: 1. 不同componen ...
- 【linux】dpkg 命令使用说明
dpkg是一个debian包管理工具.能够对包进行安装.卸载.获取信息等操作.用法: 安装(解包并配置): dpkg -i package_file dpkg --ins ...
- 统一latext在vsc的markdown+math和有道云笔记里的出发方式
起因 前段时间在有道云笔记上写笔记,里面使用latex来记录数学符号,有道云的latex行内触发模式为 `$ latex $`, 之后我在visual studio code里面使用markdown+ ...
- CSS气泡
气泡状文本框,是一种很生动的网页设计手段. 它可以用来表示用户的发言. 也可以用来作为特定信息的提示符. DVD租借网站Netflix,还用它显示碟片的详细信息. ================== ...
- c#-FrameWork02泛型
泛型 l 泛型(generic)编程是一种编程范式,它利用”参数化类型”将类型抽象化,从而可以实现更为灵活的复用.把数据类型参数化 sh泛型集合 泛型集合与集合的对比 泛型集合类 非泛型集合类 Li ...
- 项目搭建系列之四:SpringMVC框架下使用UrlRewrite实现地址重写
简单记录一下UrlRewrite实现地址重写功能. 1.pom.xml 在pom.xml增加配置UrlRewrite jar <!-- URL Rewrite --> <depend ...
- Redis的Publish/Subscribe
Publish/Subscribe 从字面上理解就是发布(Publish)与订阅(Subscribe),在Redis中,你可以设定对某一个key值进行消息发布及消息订阅,当一个key值上进行了消息发布 ...
- Bash 终端快捷键
在终端下输大量的命令,有些快捷键还是挺有帮助的. 跳跃 跳到最后 ctrl + e (end) 跳到最前 ctrl + a (abcde....) 向后跳一个单词 alt + 右方向键 向前跳一个单词 ...
- iOS instruments之ui automation的简单使用(高手绕道)
最近使用了几次instruments中的automation工具,现记录下automation的简单使用方法,希望对没接触过自动化测试又有需求的人有所帮助. UI 自动测试是iOS 中重要的附加功能 ...
- Java集合篇一:ArrayList
package com.test.collection; /** * 自定义ArrayList容器 * * 1.实现原理:底层封装数组 * * 2.查询 * LinkList 相较 ArrayList ...