refinedet网络结构
refinedet只预测4个层,并且只有conv6_1、conv6_2,没有ssd中的conv7、8、9
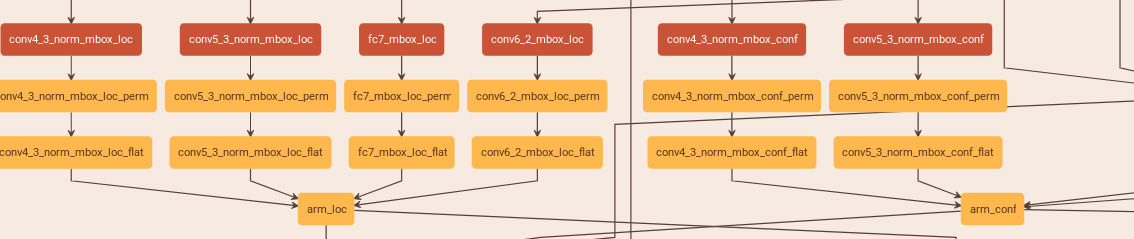
refinedet的4个层都只有1个aspect ratio和1个min_size,所以每层每个点只有3个anchor,arm中做location的conv4_3_norm_mbox_loc等层都是3*4个channel,做confidence的conv4_3_norm_mbox_conf都是6个channel,因为这里变成了2分类,每个anchor必须要有negative和positive的概率
refinedet是两步都要回归bounding box的框,refinedet中的odm_loss就相当于ssd中的mbox_loss,mbox_loss获得了anchor的坐标后会加上回归再进行训练,odm_loss获得anchor的坐标后先要加上arm_loc的回归,再加odm_loc的回归,这样再去进行loss计算.
name: "vgg_1/8"
layer {
name: "data"
type: "AnnotatedData"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
mirror: true
mean_value: 104.0
mean_value: 117.0
mean_value: 123.0
resize_param {
prob: 1.0
resize_mode: WARP
height:
width:
interp_mode: LINEAR
interp_mode: AREA
interp_mode: NEAREST
interp_mode: CUBIC
interp_mode: LANCZOS4
}
emit_constraint {
emit_type: CENTER
}
distort_param {
brightness_prob: 0.5
brightness_delta: 32.0
contrast_prob: 0.5
contrast_lower: 0.5
contrast_upper: 1.5
hue_prob: 0.5
hue_delta: 18.0
saturation_prob: 0.5
saturation_lower: 0.5
saturation_upper: 1.5
random_order_prob: 0.0
}
expand_param {
prob: 0.5
max_expand_ratio: 4.0
}
}
data_param {
source:"examples/cityscapes/cityscapes_train_lmdb"
batch_size:
backend: LMDB
}
annotated_data_param {
batch_sampler {
max_sample:
max_trials:
}
batch_sampler {
sampler {
min_scale: 0.300000011921
max_scale: 1.0
min_aspect_ratio: 0.5
max_aspect_ratio: 2.0
}
sample_constraint {
min_jaccard_overlap: 0.10000000149
}
max_sample:
max_trials:
}
batch_sampler {
sampler {
min_scale: 0.300000011921
max_scale: 1.0
min_aspect_ratio: 0.5
max_aspect_ratio: 2.0
}
sample_constraint {
min_jaccard_overlap: 0.300000011921
}
max_sample:
max_trials:
}
batch_sampler {
sampler {
min_scale: 0.300000011921
max_scale: 1.0
min_aspect_ratio: 0.5
max_aspect_ratio: 2.0
}
sample_constraint {
min_jaccard_overlap: 0.5
}
max_sample:
max_trials:
}
batch_sampler {
sampler {
min_scale: 0.300000011921
max_scale: 1.0
min_aspect_ratio: 0.5
max_aspect_ratio: 2.0
}
sample_constraint {
min_jaccard_overlap: 0.699999988079
}
max_sample:
max_trials:
}
batch_sampler {
sampler {
min_scale: 0.300000011921
max_scale: 1.0
min_aspect_ratio: 0.5
max_aspect_ratio: 2.0
}
sample_constraint {
min_jaccard_overlap: 0.899999976158
}
max_sample:
max_trials:
}
batch_sampler {
sampler {
min_scale: 0.300000011921
max_scale: 1.0
min_aspect_ratio: 0.5
max_aspect_ratio: 2.0
}
sample_constraint {
max_jaccard_overlap: 1.0
}
max_sample:
max_trials:
}
label_map_file: "data/cityscapes/labelmap_cityscapes.prototxt"
}
}
layer {
name: "conv1_1"
type: "Convolution"
bottom: "data"
top: "conv1_1"
param {
lr_mult: 1.0
decay_mult: 1.0
}
param {
lr_mult: 2.0
decay_mult: 0.0
}
convolution_param {
num_output:
pad:
kernel_size:
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "relu1_1"
type: "ReLU"
bottom: "conv1_1"
top: "conv1_1"
}
layer {
name: "conv1_2"
type: "Convolution"
bottom: "conv1_1"
top: "conv1_2"
param {
lr_mult: 1.0
decay_mult: 1.0
}
param {
lr_mult: 2.0
decay_mult: 0.0
}
convolution_param {
num_output:
pad:
kernel_size:
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "relu1_2"
type: "ReLU"
bottom: "conv1_2"
top: "conv1_2"
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1_2"
top: "pool1"
pooling_param {
pool: MAX
kernel_size:
stride:
}
}
layer {
name: "conv2_1"
type: "Convolution"
bottom: "pool1"
top: "conv2_1"
param {
lr_mult: 1.0
decay_mult: 1.0
}
param {
lr_mult: 2.0
decay_mult: 0.0
}
convolution_param {
num_output:
pad:
kernel_size:
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "relu2_1"
type: "ReLU"
bottom: "conv2_1"
top: "conv2_1"
}
layer {
name: "conv2_2"
type: "Convolution"
bottom: "conv2_1"
top: "conv2_2"
param {
lr_mult: 1.0
decay_mult: 1.0
}
param {
lr_mult: 2.0
decay_mult: 0.0
}
convolution_param {
num_output:
pad:
kernel_size:
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "relu2_2"
type: "ReLU"
bottom: "conv2_2"
top: "conv2_2"
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2_2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size:
stride:
}
}
layer {
name: "conv3_1"
type: "Convolution"
bottom: "pool2"
top: "conv3_1"
param {
lr_mult: 1.0
decay_mult: 1.0
}
param {
lr_mult: 2.0
decay_mult: 0.0
}
convolution_param {
num_output:
pad:
kernel_size:
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "relu3_1"
type: "ReLU"
bottom: "conv3_1"
top: "conv3_1"
}
layer {
name: "conv3_2"
type: "Convolution"
bottom: "conv3_1"
top: "conv3_2"
param {
lr_mult: 1.0
decay_mult: 1.0
}
param {
lr_mult: 2.0
decay_mult: 0.0
}
convolution_param {
num_output:
pad:
kernel_size:
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "relu3_2"
type: "ReLU"
bottom: "conv3_2"
top: "conv3_2"
}
layer {
name: "conv3_3"
type: "Convolution"
bottom: "conv3_2"
top: "conv3_3"
param {
lr_mult: 1.0
decay_mult: 1.0
}
param {
lr_mult: 2.0
decay_mult: 0.0
}
convolution_param {
num_output:
pad:
kernel_size:
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "relu3_3"
type: "ReLU"
bottom: "conv3_3"
top: "conv3_3"
}
layer {
name: "pool3"
type: "Pooling"
bottom: "conv3_3"
top: "pool3"
pooling_param {
pool: MAX
kernel_size:
stride:
}
}
layer {
name: "conv4_1"
type: "Convolution"
bottom: "pool3"
top: "conv4_1"
param {
lr_mult: 1.0
decay_mult: 1.0
}
param {
lr_mult: 2.0
decay_mult: 0.0
}
convolution_param {
num_output:
pad:
kernel_size:
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "relu4_1"
type: "ReLU"
bottom: "conv4_1"
top: "conv4_1"
}
layer {
name: "conv4_2"
type: "Convolution"
bottom: "conv4_1"
top: "conv4_2"
param {
lr_mult: 1.0
decay_mult: 1.0
}
param {
lr_mult: 2.0
decay_mult: 0.0
}
convolution_param {
num_output:
pad:
kernel_size:
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "relu4_2"
type: "ReLU"
bottom: "conv4_2"
top: "conv4_2"
}
layer {
name: "conv4_3"
type: "Convolution"
bottom: "conv4_2"
top: "conv4_3"
param {
lr_mult: 1.0
decay_mult: 1.0
}
param {
lr_mult: 2.0
decay_mult: 0.0
}
convolution_param {
num_output:
pad:
kernel_size:
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "relu4_3"
type: "ReLU"
bottom: "conv4_3"
top: "conv4_3"
}
layer {
name: "pool4"
type: "Pooling"
bottom: "conv4_3"
top: "pool4"
pooling_param {
pool: MAX
kernel_size:
stride:
}
}
layer {
name: "conv5_1"
type: "Convolution"
bottom: "pool4"
top: "conv5_1"
param {
lr_mult: 1.0
decay_mult: 1.0
}
param {
lr_mult: 2.0
decay_mult: 0.0
}
convolution_param {
num_output:
pad:
kernel_size:
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "relu5_1"
type: "ReLU"
bottom: "conv5_1"
top: "conv5_1"
}
layer {
name: "conv5_2"
type: "Convolution"
bottom: "conv5_1"
top: "conv5_2"
param {
lr_mult: 1.0
decay_mult: 1.0
}
param {
lr_mult: 2.0
decay_mult: 0.0
}
convolution_param {
num_output:
pad:
kernel_size:
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "relu5_2"
type: "ReLU"
bottom: "conv5_2"
top: "conv5_2"
}
layer {
name: "conv5_3"
type: "Convolution"
bottom: "conv5_2"
top: "conv5_3"
param {
lr_mult: 1.0
decay_mult: 1.0
}
param {
lr_mult: 2.0
decay_mult: 0.0
}
convolution_param {
num_output:
pad:
kernel_size:
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "relu5_3"
type: "ReLU"
bottom: "conv5_3"
top: "conv5_3"
}
layer {
name: "pool5"
type: "Pooling"
bottom: "conv5_3"
top: "pool5"
pooling_param {
pool: MAX
kernel_size:
stride:
}
}
layer {
name: "fc6"
type: "Convolution"
bottom: "pool5"
top: "fc6"
param {
lr_mult: 1.0
decay_mult: 1.0
}
param {
lr_mult: 2.0
decay_mult: 0.0
}
convolution_param {
num_output:
pad:
kernel_size:
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "relu6"
type: "ReLU"
bottom: "fc6"
top: "fc6"
}
layer {
name: "fc7"
type: "Convolution"
bottom: "fc6"
top: "fc7"
param {
lr_mult: 1.0
decay_mult: 1.0
}
param {
lr_mult: 2.0
decay_mult: 0.0
}
convolution_param {
num_output:
kernel_size:
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "relu7"
type: "ReLU"
bottom: "fc7"
top: "fc7"
}
layer {
name: "conv6_1"
type: "Convolution"
bottom: "fc7"
top: "conv6_1"
param {
lr_mult: 1.0
decay_mult: 1.0
}
param {
lr_mult: 2.0
decay_mult: 0.0
}
convolution_param {
num_output:
pad:
kernel_size:
stride:
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "conv6_1_relu"
type: "ReLU"
bottom: "conv6_1"
top: "conv6_1"
}
layer {
name: "conv6_2"
type: "Convolution"
bottom: "conv6_1"
top: "conv6_2"
param {
lr_mult: 1.0
decay_mult: 1.0
}
param {
lr_mult: 2.0
decay_mult: 0.0
}
convolution_param {
num_output:
pad:
kernel_size:
stride:
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "conv6_2_relu"
type: "ReLU"
bottom: "conv6_2"
top: "conv6_2"
}
layer {
name: "conv4_3_norm_mbox_loc"
type: "Convolution"
bottom: "conv4_3"
top: "conv4_3_norm_mbox_loc"
param {
lr_mult: 1.0
decay_mult: 1.0
}
param {
lr_mult: 2.0
decay_mult: 0.0
}
convolution_param {
num_output:
pad:
kernel_size:
stride:
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "conv4_3_norm_mbox_loc_perm"
type: "Permute"
bottom: "conv4_3_norm_mbox_loc"
top: "conv4_3_norm_mbox_loc_perm"
permute_param {
order:
order:
order:
order:
}
}
layer {
name: "conv4_3_norm_mbox_loc_flat"
type: "Flatten"
bottom: "conv4_3_norm_mbox_loc_perm"
top: "conv4_3_norm_mbox_loc_flat"
flatten_param {
axis:
}
}
layer {
name: "conv4_3_norm_mbox_conf"
type: "Convolution"
bottom: "conv4_3"
top: "conv4_3_norm_mbox_conf"
param {
lr_mult: 1.0
decay_mult: 1.0
}
param {
lr_mult: 2.0
decay_mult: 0.0
}
convolution_param {
num_output:
pad:
kernel_size:
stride:
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "conv4_3_norm_mbox_conf_perm"
type: "Permute"
bottom: "conv4_3_norm_mbox_conf"
top: "conv4_3_norm_mbox_conf_perm"
permute_param {
order:
order:
order:
order:
}
}
layer {
name: "conv4_3_norm_mbox_conf_flat"
type: "Flatten"
bottom: "conv4_3_norm_mbox_conf_perm"
top: "conv4_3_norm_mbox_conf_flat"
flatten_param {
axis:
}
}
layer {
name: "conv4_3_norm_mbox_priorbox"
type: "PriorBox"
bottom: "conv4_3"
bottom: "data"
top: "conv4_3_norm_mbox_priorbox"
prior_box_param {
min_size: 16.0
aspect_ratio: 2.0
flip: true
clip: false
variance: 0.10000000149
variance: 0.10000000149
variance: 0.20000000298
variance: 0.20000000298
step: 8.0
offset: 0.5
}
}
layer {
name: "conv5_3_norm_mbox_loc"
type: "Convolution"
bottom: "conv5_3"
top: "conv5_3_norm_mbox_loc"
param {
lr_mult: 1.0
decay_mult: 1.0
}
param {
lr_mult: 2.0
decay_mult: 0.0
}
convolution_param {
num_output:
pad:
kernel_size:
stride:
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "conv5_3_norm_mbox_loc_perm"
type: "Permute"
bottom: "conv5_3_norm_mbox_loc"
top: "conv5_3_norm_mbox_loc_perm"
permute_param {
order:
order:
order:
order:
}
}
layer {
name: "conv5_3_norm_mbox_loc_flat"
type: "Flatten"
bottom: "conv5_3_norm_mbox_loc_perm"
top: "conv5_3_norm_mbox_loc_flat"
flatten_param {
axis:
}
}
layer {
name: "conv5_3_norm_mbox_conf"
type: "Convolution"
bottom: "conv5_3"
top: "conv5_3_norm_mbox_conf"
param {
lr_mult: 1.0
decay_mult: 1.0
}
param {
lr_mult: 2.0
decay_mult: 0.0
}
convolution_param {
num_output:
pad:
kernel_size:
stride:
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "conv5_3_norm_mbox_conf_perm"
type: "Permute"
bottom: "conv5_3_norm_mbox_conf"
top: "conv5_3_norm_mbox_conf_perm"
permute_param {
order:
order:
order:
order:
}
}
layer {
name: "conv5_3_norm_mbox_conf_flat"
type: "Flatten"
bottom: "conv5_3_norm_mbox_conf_perm"
top: "conv5_3_norm_mbox_conf_flat"
flatten_param {
axis:
}
}
layer {
name: "conv5_3_norm_mbox_priorbox"
type: "PriorBox"
bottom: "conv5_3"
bottom: "data"
top: "conv5_3_norm_mbox_priorbox"
prior_box_param {
min_size: 32.0
aspect_ratio: 2.0
flip: true
clip: false
variance: 0.10000000149
variance: 0.10000000149
variance: 0.20000000298
variance: 0.20000000298
step: 16.0
offset: 0.5
}
}
layer {
name: "fc7_mbox_loc"
type: "Convolution"
bottom: "fc7"
top: "fc7_mbox_loc"
param {
lr_mult: 1.0
decay_mult: 1.0
}
param {
lr_mult: 2.0
decay_mult: 0.0
}
convolution_param {
num_output:
pad:
kernel_size:
stride:
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "fc7_mbox_loc_perm"
type: "Permute"
bottom: "fc7_mbox_loc"
top: "fc7_mbox_loc_perm"
permute_param {
order:
order:
order:
order:
}
}
layer {
name: "fc7_mbox_loc_flat"
type: "Flatten"
bottom: "fc7_mbox_loc_perm"
top: "fc7_mbox_loc_flat"
flatten_param {
axis:
}
}
layer {
name: "fc7_mbox_conf"
type: "Convolution"
bottom: "fc7"
top: "fc7_mbox_conf"
param {
lr_mult: 1.0
decay_mult: 1.0
}
param {
lr_mult: 2.0
decay_mult: 0.0
}
convolution_param {
num_output:
pad:
kernel_size:
stride:
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "fc7_mbox_conf_perm"
type: "Permute"
bottom: "fc7_mbox_conf"
top: "fc7_mbox_conf_perm"
permute_param {
order:
order:
order:
order:
}
}
layer {
name: "fc7_mbox_conf_flat"
type: "Flatten"
bottom: "fc7_mbox_conf_perm"
top: "fc7_mbox_conf_flat"
flatten_param {
axis:
}
}
layer {
name: "fc7_mbox_priorbox"
type: "PriorBox"
bottom: "fc7"
bottom: "data"
top: "fc7_mbox_priorbox"
prior_box_param {
min_size: 64.0
aspect_ratio: 2.0
flip: true
clip: false
variance: 0.10000000149
variance: 0.10000000149
variance: 0.20000000298
variance: 0.20000000298
step: 32.0
offset: 0.5
}
}
layer {
name: "conv6_2_mbox_loc"
type: "Convolution"
bottom: "conv6_2"
top: "conv6_2_mbox_loc"
param {
lr_mult: 1.0
decay_mult: 1.0
}
param {
lr_mult: 2.0
decay_mult: 0.0
}
convolution_param {
num_output:
pad:
kernel_size:
stride:
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "conv6_2_mbox_loc_perm"
type: "Permute"
bottom: "conv6_2_mbox_loc"
top: "conv6_2_mbox_loc_perm"
permute_param {
order:
order:
order:
order:
}
}
layer {
name: "conv6_2_mbox_loc_flat"
type: "Flatten"
bottom: "conv6_2_mbox_loc_perm"
top: "conv6_2_mbox_loc_flat"
flatten_param {
axis:
}
}
layer {
name: "conv6_2_mbox_conf"
type: "Convolution"
bottom: "conv6_2"
top: "conv6_2_mbox_conf"
param {
lr_mult: 1.0
decay_mult: 1.0
}
param {
lr_mult: 2.0
decay_mult: 0.0
}
convolution_param {
num_output:
pad:
kernel_size:
stride:
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "conv6_2_mbox_conf_perm"
type: "Permute"
bottom: "conv6_2_mbox_conf"
top: "conv6_2_mbox_conf_perm"
permute_param {
order:
order:
order:
order:
}
}
layer {
name: "conv6_2_mbox_conf_flat"
type: "Flatten"
bottom: "conv6_2_mbox_conf_perm"
top: "conv6_2_mbox_conf_flat"
flatten_param {
axis:
}
}
layer {
name: "conv6_2_mbox_priorbox"
type: "PriorBox"
bottom: "conv6_2"
bottom: "data"
top: "conv6_2_mbox_priorbox"
prior_box_param {
min_size: 128.0
aspect_ratio: 2.0
flip: true
clip: false
variance: 0.10000000149
variance: 0.10000000149
variance: 0.20000000298
variance: 0.20000000298
step: 64.0
offset: 0.5
}
}
layer {
name: "arm_loc"
type: "Concat"
bottom: "conv4_3_norm_mbox_loc_flat"
bottom: "conv5_3_norm_mbox_loc_flat"
bottom: "fc7_mbox_loc_flat"
bottom: "conv6_2_mbox_loc_flat"
top: "arm_loc"
concat_param {
axis:
}
}
layer {
name: "arm_conf"
type: "Concat"
bottom: "conv4_3_norm_mbox_conf_flat"
bottom: "conv5_3_norm_mbox_conf_flat"
bottom: "fc7_mbox_conf_flat"
bottom: "conv6_2_mbox_conf_flat"
top: "arm_conf"
concat_param {
axis:
}
}
layer {
name: "arm_priorbox"
type: "Concat"
bottom: "conv4_3_norm_mbox_priorbox"
bottom: "conv5_3_norm_mbox_priorbox"
bottom: "fc7_mbox_priorbox"
bottom: "conv6_2_mbox_priorbox"
top: "arm_priorbox"
concat_param {
axis:
}
}
layer {
name: "P3_mbox_loc_p"
type: "Convolution"
bottom: "conv4_3"
top: "P3_mbox_loc"
param {
lr_mult: 1.0
decay_mult: 1.0
}
param {
lr_mult: 2.0
decay_mult: 0.0
}
convolution_param {
num_output:
pad:
kernel_size:
stride:
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "P3_mbox_loc_perm"
type: "Permute"
bottom: "P3_mbox_loc"
top: "P3_mbox_loc_perm"
permute_param {
order:
order:
order:
order:
}
}
layer {
name: "P3_mbox_loc_flat"
type: "Flatten"
bottom: "P3_mbox_loc_perm"
top: "P3_mbox_loc_flat"
flatten_param {
axis:
}
}
layer {
name: "P3_mbox_conf_p"
type: "Convolution"
bottom: "conv4_3"
top: "P3_mbox_conf"
param {
lr_mult: 1.0
decay_mult: 1.0
}
param {
lr_mult: 2.0
decay_mult: 0.0
}
convolution_param {
num_output:
pad:
kernel_size:
stride:
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "P3_mbox_conf_perm"
type: "Permute"
bottom: "P3_mbox_conf"
top: "P3_mbox_conf_perm"
permute_param {
order:
order:
order:
order:
}
}
layer {
name: "P3_mbox_conf_flat"
type: "Flatten"
bottom: "P3_mbox_conf_perm"
top: "P3_mbox_conf_flat"
flatten_param {
axis:
}
}
layer {
name: "P4_mbox_loc_p"
type: "Convolution"
bottom: "conv5_3"
top: "P4_mbox_loc"
param {
lr_mult: 1.0
decay_mult: 1.0
}
param {
lr_mult: 2.0
decay_mult: 0.0
}
convolution_param {
num_output:
pad:
kernel_size:
stride:
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "P4_mbox_loc_perm"
type: "Permute"
bottom: "P4_mbox_loc"
top: "P4_mbox_loc_perm"
permute_param {
order:
order:
order:
order:
}
}
layer {
name: "P4_mbox_loc_flat"
type: "Flatten"
bottom: "P4_mbox_loc_perm"
top: "P4_mbox_loc_flat"
flatten_param {
axis:
}
}
layer {
name: "P4_mbox_conf_p"
type: "Convolution"
bottom: "conv5_3"
top: "P4_mbox_conf"
param {
lr_mult: 1.0
decay_mult: 1.0
}
param {
lr_mult: 2.0
decay_mult: 0.0
}
convolution_param {
num_output:
pad:
kernel_size:
stride:
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "P4_mbox_conf_perm"
type: "Permute"
bottom: "P4_mbox_conf"
top: "P4_mbox_conf_perm"
permute_param {
order:
order:
order:
order:
}
}
layer {
name: "P4_mbox_conf_flat"
type: "Flatten"
bottom: "P4_mbox_conf_perm"
top: "P4_mbox_conf_flat"
flatten_param {
axis:
}
}
layer {
name: "P5_mbox_loc_p"
type: "Convolution"
bottom: "fc7"
top: "P5_mbox_loc"
param {
lr_mult: 1.0
decay_mult: 1.0
}
param {
lr_mult: 2.0
decay_mult: 0.0
}
convolution_param {
num_output:
pad:
kernel_size:
stride:
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "P5_mbox_loc_perm"
type: "Permute"
bottom: "P5_mbox_loc"
top: "P5_mbox_loc_perm"
permute_param {
order:
order:
order:
order:
}
}
layer {
name: "P5_mbox_loc_flat"
type: "Flatten"
bottom: "P5_mbox_loc_perm"
top: "P5_mbox_loc_flat"
flatten_param {
axis:
}
}
layer {
name: "P5_mbox_conf_p"
type: "Convolution"
bottom: "fc7"
top: "P5_mbox_conf"
param {
lr_mult: 1.0
decay_mult: 1.0
}
param {
lr_mult: 2.0
decay_mult: 0.0
}
convolution_param {
num_output:
pad:
kernel_size:
stride:
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "P5_mbox_conf_perm"
type: "Permute"
bottom: "P5_mbox_conf"
top: "P5_mbox_conf_perm"
permute_param {
order:
order:
order:
order:
}
}
layer {
name: "P5_mbox_conf_flat"
type: "Flatten"
bottom: "P5_mbox_conf_perm"
top: "P5_mbox_conf_flat"
flatten_param {
axis:
}
}
layer {
name: "P6_mbox_loc_p"
type: "Convolution"
bottom: "conv6_2"
top: "P6_mbox_loc"
param {
lr_mult: 1.0
decay_mult: 1.0
}
param {
lr_mult: 2.0
decay_mult: 0.0
}
convolution_param {
num_output:
pad:
kernel_size:
stride:
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "P6_mbox_loc_perm"
type: "Permute"
bottom: "P6_mbox_loc"
top: "P6_mbox_loc_perm"
permute_param {
order:
order:
order:
order:
}
}
layer {
name: "P6_mbox_loc_flat"
type: "Flatten"
bottom: "P6_mbox_loc_perm"
top: "P6_mbox_loc_flat"
flatten_param {
axis:
}
}
layer {
name: "P6_mbox_conf_p"
type: "Convolution"
bottom: "conv6_2"
top: "P6_mbox_conf"
param {
lr_mult: 1.0
decay_mult: 1.0
}
param {
lr_mult: 2.0
decay_mult: 0.0
}
convolution_param {
num_output:
pad:
kernel_size:
stride:
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "P6_mbox_conf_perm"
type: "Permute"
bottom: "P6_mbox_conf"
top: "P6_mbox_conf_perm"
permute_param {
order:
order:
order:
order:
}
}
layer {
name: "P6_mbox_conf_flat"
type: "Flatten"
bottom: "P6_mbox_conf_perm"
top: "P6_mbox_conf_flat"
flatten_param {
axis:
}
}
layer {
name: "odm_loc"
type: "Concat"
bottom: "P3_mbox_loc_flat"
bottom: "P4_mbox_loc_flat"
bottom: "P5_mbox_loc_flat"
bottom: "P6_mbox_loc_flat"
top: "odm_loc"
concat_param {
axis:
}
}
layer {
name: "odm_conf"
type: "Concat"
bottom: "P3_mbox_conf_flat"
bottom: "P4_mbox_conf_flat"
bottom: "P5_mbox_conf_flat"
bottom: "P6_mbox_conf_flat"
top: "odm_conf"
concat_param {
axis:
}
}
layer {
name: "arm_loss"
type: "MultiBoxLoss"
bottom: "arm_loc"
bottom: "arm_conf"
bottom: "arm_priorbox"
bottom: "label"
top: "arm_loss"
include {
phase: TRAIN
}
propagate_down: true
propagate_down: true
propagate_down: false
propagate_down: false
loss_param {
normalization: VALID
}
multibox_loss_param {
loc_loss_type: SMOOTH_L1
conf_loss_type: SOFTMAX
loc_weight: 1.0
num_classes:
share_location: true
match_type: PER_PREDICTION
overlap_threshold: 0.5
use_prior_for_matching: true
background_label_id:
use_difficult_gt: true
neg_pos_ratio: 3.0
neg_overlap: 0.5
code_type: CENTER_SIZE
ignore_cross_boundary_bbox: false
mining_type: MAX_NEGATIVE
objectness_score: 0.00999999977648
}
}
layer {
name: "arm_conf_reshape"
type: "Reshape"
bottom: "arm_conf"
top: "arm_conf_reshape"
reshape_param {
shape {
dim:
dim: -
dim:
}
}
}
layer {
name: "arm_conf_softmax"
type: "Softmax"
bottom: "arm_conf_reshape"
top: "arm_conf_softmax"
softmax_param {
axis:
}
}
layer {
name: "arm_conf_flatten"
type: "Flatten"
bottom: "arm_conf_softmax"
top: "arm_conf_flatten"
flatten_param {
axis:
}
}
layer {
name: "odm_loss"
type: "MultiBoxLoss"
bottom: "odm_loc"
bottom: "odm_conf"
bottom: "arm_priorbox"
bottom: "label"
bottom: "arm_conf_flatten"
bottom: "arm_loc"
top: "odm_loss"
include {
phase: TRAIN
}
propagate_down: true
propagate_down: true
propagate_down: false
propagate_down: false
propagate_down: false
propagate_down: false
loss_param {
normalization: VALID
}
multibox_loss_param {
loc_loss_type: SMOOTH_L1
conf_loss_type: SOFTMAX
loc_weight: 1.0
num_classes:
share_location: true
match_type: PER_PREDICTION
overlap_threshold: 0.5
use_prior_for_matching: true
background_label_id:
use_difficult_gt: true
neg_pos_ratio: 3.0
neg_overlap: 0.5
code_type: CENTER_SIZE
ignore_cross_boundary_bbox: false
mining_type: MAX_NEGATIVE
objectness_score: 0.00999999977648
}
} layer {
name: "conv1_1_t"
type: "Convolution"
bottom: "data"
top: "conv1_1_t"
param {
lr_mult:
decay_mult:
}
param {
lr_mult:
decay_mult:
}
convolution_param {
num_output:
pad:
kernel_size:
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "relu1_1_t"
type: "ReLU"
bottom: "conv1_1_t"
top: "conv1_1_t"
}
layer {
name: "conv1_2_t"
type: "Convolution"
bottom: "conv1_1_t"
top: "conv1_2_t"
param {
lr_mult:
decay_mult:
}
param {
lr_mult:
decay_mult:
}
convolution_param {
num_output:
pad:
kernel_size:
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "relu1_2_t"
type: "ReLU"
bottom: "conv1_2_t"
top: "conv1_2_t"
}
layer {
name: "pool1_t"
type: "Pooling"
bottom: "conv1_2_t"
top: "pool1_t"
pooling_param {
pool: MAX
kernel_size:
stride:
}
}
layer {
name: "conv2_1_t"
type: "Convolution"
bottom: "pool1_t"
top: "conv2_1_t"
param {
lr_mult:
decay_mult:
}
param {
lr_mult:
decay_mult:
}
convolution_param {
num_output:
pad:
kernel_size:
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "relu2_1_t"
type: "ReLU"
bottom: "conv2_1_t"
top: "conv2_1_t"
}
layer {
name: "conv2_2_t"
type: "Convolution"
bottom: "conv2_1_t"
top: "conv2_2_t"
param {
lr_mult:
decay_mult:
}
param {
lr_mult:
decay_mult:
}
convolution_param {
num_output:
pad:
kernel_size:
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "relu2_2_t"
type: "ReLU"
bottom: "conv2_2_t"
top: "conv2_2_t"
}
layer {
name: "pool2_t"
type: "Pooling"
bottom: "conv2_2_t"
top: "pool2_t"
pooling_param {
pool: MAX
kernel_size:
stride:
}
}
layer {
name: "conv3_1_t"
type: "Convolution"
bottom: "pool2_t"
top: "conv3_1_t"
param {
lr_mult:
decay_mult:
}
param {
lr_mult:
decay_mult:
}
convolution_param {
num_output:
pad:
kernel_size:
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "relu3_1_t"
type: "ReLU"
bottom: "conv3_1_t"
top: "conv3_1_t"
}
layer {
name: "conv3_2_t"
type: "Convolution"
bottom: "conv3_1_t"
top: "conv3_2_t"
param {
lr_mult:
decay_mult:
}
param {
lr_mult:
decay_mult:
}
convolution_param {
num_output:
pad:
kernel_size:
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "relu3_2_t"
type: "ReLU"
bottom: "conv3_2_t"
top: "conv3_2_t"
}
layer {
name: "conv3_3_t"
type: "Convolution"
bottom: "conv3_2_t"
top: "conv3_3_t"
param {
lr_mult:
decay_mult:
}
param {
lr_mult:
decay_mult:
}
convolution_param {
num_output:
pad:
kernel_size:
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "relu3_3_t"
type: "ReLU"
bottom: "conv3_3_t"
top: "conv3_3_t"
}
layer {
name: "pool3_t"
type: "Pooling"
bottom: "conv3_3_t"
top: "pool3_t"
pooling_param {
pool: MAX
kernel_size:
stride:
}
}
layer {
name: "conv4_1_t"
type: "Convolution"
bottom: "pool3_t"
top: "conv4_1_t"
param {
lr_mult:
decay_mult:
}
param {
lr_mult:
decay_mult:
}
convolution_param {
num_output:
pad:
kernel_size:
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "relu4_1_t"
type: "ReLU"
bottom: "conv4_1_t"
top: "conv4_1_t"
}
layer {
name: "conv4_2_t"
type: "Convolution"
bottom: "conv4_1_t"
top: "conv4_2_t"
param {
lr_mult:
decay_mult:
}
param {
lr_mult:
decay_mult:
}
convolution_param {
num_output:
pad:
kernel_size:
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "relu4_2_t"
type: "ReLU"
bottom: "conv4_2_t"
top: "conv4_2_t"
}
layer {
name: "conv4_3_t"
type: "Convolution"
bottom: "conv4_2_t"
top: "conv4_3_t"
param {
lr_mult:
decay_mult:
}
param {
lr_mult:
decay_mult:
}
convolution_param {
num_output:
pad:
kernel_size:
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "relu4_3_t"
type: "ReLU"
bottom: "conv4_3_t"
top: "conv4_3_t"
}
layer {
name: "pool4_t"
type: "Pooling"
bottom: "conv4_3_t"
top: "pool4_t"
pooling_param {
pool: MAX
kernel_size:
stride:
}
}
layer {
name: "conv5_1_t"
type: "Convolution"
bottom: "pool4_t"
top: "conv5_1_t"
param {
lr_mult:
decay_mult:
}
param {
lr_mult:
decay_mult:
}
convolution_param {
num_output:
pad:
kernel_size:
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.0
}
dilation:
}
}
layer {
name: "relu5_1_t"
type: "ReLU"
bottom: "conv5_1_t"
top: "conv5_1_t"
}
layer {
name: "conv5_2_t"
type: "Convolution"
bottom: "conv5_1_t"
top: "conv5_2_t"
param {
lr_mult:
decay_mult:
}
param {
lr_mult:
decay_mult:
}
convolution_param {
num_output:
pad:
kernel_size:
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.0
}
dilation:
}
}
layer {
name: "relu5_2_t"
type: "ReLU"
bottom: "conv5_2_t"
top: "conv5_2_t"
}
layer {
name: "conv5_3_t"
type: "Convolution"
bottom: "conv5_2_t"
top: "conv5_3_t"
param {
lr_mult:
decay_mult:
}
param {
lr_mult:
decay_mult:
}
convolution_param {
num_output:
pad:
kernel_size:
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.0
}
dilation:
}
}
layer {
name: "relu5_3_t"
type: "ReLU"
bottom: "conv5_3_t"
top: "conv5_3_t"
} layer {
name: "conv5_3_m"
type: "Convolution"
bottom: "conv5_3"
top: "conv5_3_m"
propagate_down: true
param {
lr_mult:
decay_mult:
}
param {
lr_mult:
decay_mult:
}
convolution_param {
num_output:
kernel_size:
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value:
}
}
} layer {
name: "relu5_3_m"
type: "ReLU"
bottom: "conv5_3_m"
top: "conv5_3_m"
} layer {
name: "roi_pool_t"
type: "ROIPooling"
bottom: "conv5_3_t"
bottom: "label"
top: "pool_t"
roi_pooling_param {
pooled_w:
pooled_h:
}
propagate_down: false
propagate_down: false
}
layer {
name: "roi_pool_s"
type: "ROIPooling"
bottom: "conv5_3_m"
bottom: "label"
top: "pool_s"
roi_pooling_param {
pooled_w:
pooled_h:
}
propagate_down: true
propagate_down: false
} layer {
name: "mimic_loss"
type: "EuclideanLoss"
bottom: "pool_t"
bottom: "pool_s"
top: "mimic_loss"
propagate_down: false
propagate_down: true
loss_weight:
include {
phase: TRAIN
}
}
refinedet网络结构的更多相关文章
- RefineDet算法笔记
---恢复内容开始--- 一.创新点 针对two-stage的速度慢以及one-stage精度不足提出的方法,refinedet 包括三个核心部分:使用TCB来转换ARM的特征,送入ODM中进行检测: ...
- 论文阅读 | RefineDet:Single-Shot Refinement Neural Network for Object Detection
论文链接:https://arxiv.org/abs/1711.06897 代码链接:https://github.com/sfzhang15/RefineDet 摘要 RefineDet是CVPR ...
- 目标检测之RefineDet
RefineDet 一.相关背景 中科院自动化所最新成果,CVPR 2018 <Single-Shot Refinement Neural Network for Object Detectio ...
- Sparse Filtering 学习笔记(一)网络结构与特征矩阵
Sparse Filtering 是一个用于提取特征的无监督学习算法,与通常特征学习算法试图建模训练数据的分布的做法不同,Sparse Filtering 直接对训练数据的特征分布进行分析,在所谓 ...
- 深度神经网络结构以及Pre-Training的理解
Logistic回归.传统多层神经网络 1.1 线性回归.线性神经网络.Logistic/Softmax回归 线性回归是用于数据拟合的常规手段,其任务是优化目标函数:$h(\theta )=\thet ...
- 受限玻尔兹曼机(RBM)学习笔记(二)网络结构
去年 6 月份写的博文<Yusuke Sugomori 的 C 语言 Deep Learning 程序解读>是囫囵吞枣地读完一个关于 DBN 算法的开源代码后的笔记,当时对其中涉及的算 ...
- OpenWrt网络结构
原文链接:http://www.freezhongzi.info/?p=104 OpenWrt网络结构 OpenWrt的网络配置很丰富,在我看来几乎可以完成任何网络结构.下图为一个支持OpenWrt的 ...
- CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)的内部网络结构有什么区别?
https://www.zhihu.com/question/34681168 CNN(卷积神经网络).RNN(循环神经网络).DNN(深度神经网络)的内部网络结构有什么区别?修改 CNN(卷积神经网 ...
- 神经网络结构在命名实体识别(NER)中的应用
神经网络结构在命名实体识别(NER)中的应用 近年来,基于神经网络的深度学习方法在自然语言处理领域已经取得了不少进展.作为NLP领域的基础任务-命名实体识别(Named Entity Recognit ...
随机推荐
- Reading a IMU Without Kalman: The Complementary Filter
目标是将惯性测量元件(IMU)之中陀螺仪.加速计的数据结合使用.Kalman filter太复杂,在微机上倾向用一种更简单的方法:Complementary filter 姿态估计(获得3个角度,俯仰 ...
- Jquery EasyUI Treegrid按需加载子集
项目说明,要一个有权限并且按需加载的树形列表. jeasyui网址 CSS <!--添加树状控件--> <link rel="stylesheet" type=& ...
- WEB 倒计时
<%@ Page Language="C#" %> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Trans ...
- Ace教你一步一步做Android新闻客户端(五) 优化Listview
今天写存货了 调试一些动画参数花了些时间 ,嘿嘿存货不多了就没法做教程了,今天来教大家优化listview,等下我把代码编辑下 这次代码有些多 所以我把条理给大家理清楚.思路就是把加载图片的权利交给O ...
- query的参数解析
SQLiteDatabase dbInstance;Cursor cursor = dbInstance.query(String table,String []Columns, String sel ...
- git换行符问题
from: http://www.cnblogs.com/flying_bat/archive/2013/09/16/3324769.html 一.AutoCRLF#提交时转换为LF,检出时转换为CR ...
- groovy与javah互相调用
暂时只找到这几种方法.groovy代码方便灵活.常用来写一些工具.一般都是java加入groovy代码 第一种 java中加入 groovy代码就是 Toy.groovy class Toy{ def ...
- Linux的应用层到底层驱动的调用过程
应用层如何内核.md 1.从应用层打通内核:驱动 首先来说是设备号的引入,我们通过 cat/proc/kallsyms |grep mydevice 可以查看设备号,当然我们也是可以自己创建设备号,这 ...
- jquery返回顶部和底部插件和解决ie6下fixed插件
(function($){ //返回顶部和底部插件 $.fn.extend({ goTopBootom:function (options){ //默认参数 var defaults = { &quo ...
- C# 获取字符串长度
int leng = System.Text.Encoding.Default.GetBytes(attachfileId2).Length;