vue+rest-framework前后端分离整合
一、为什么要做前后端分离项目
1、满足多端适配
随着移动端的兴起,现在公司产品不只限于pc端的,包括Android,IOS。
按照以前的方式,我们后端其实就要有多套,pc一套,APP端两套。开发成本以及开发效率会很低,如果前后端分离,我们后端只需要有一套就可以了~
后端只提供接口,前端不管是pc还是APP都可以去调用数据。
2、前后端职责划分
以前的编程方式,前后端职责不清晰,模板语言前端后端都可以写。
3、开发效率
前后端互相等待。
4、解放前端能力
前端配合后端,只写模板语言,能力受限。
5、后端语言和模板语言解耦
后端开发语言与模板语言耦合度较高,依赖开发语言,更换后端语言的成本很高。
二、django路由配置
(1)项目urls.py修改如下:
from django.conf.urls import url, include urlpatterns = [
# path('admin/', admin.site.urls),
url(r'^api/', include('api.urls')),
]
(2)应用目录下创建urls.py文件,配置如下:
from django.conf.urls import url, include
from api.views import course urlpatterns = [
url(r'^(?P<version>[v1|v2]+)/course/$', course.CourseView.as_view()),
]
(3)修改/api/views/course.py类视图文件如下所示:
from rest_framework.views import APIView
from rest_framework.response import Response
from rest_framework.versioning import QueryParameterVersioning, URLPathVersioning class CourseView(APIView):
versioning_class = URLPathVersioning def get(self, request, *args, **kwargs):
print(request.version)
return Response('...')
(4)访问显示效果
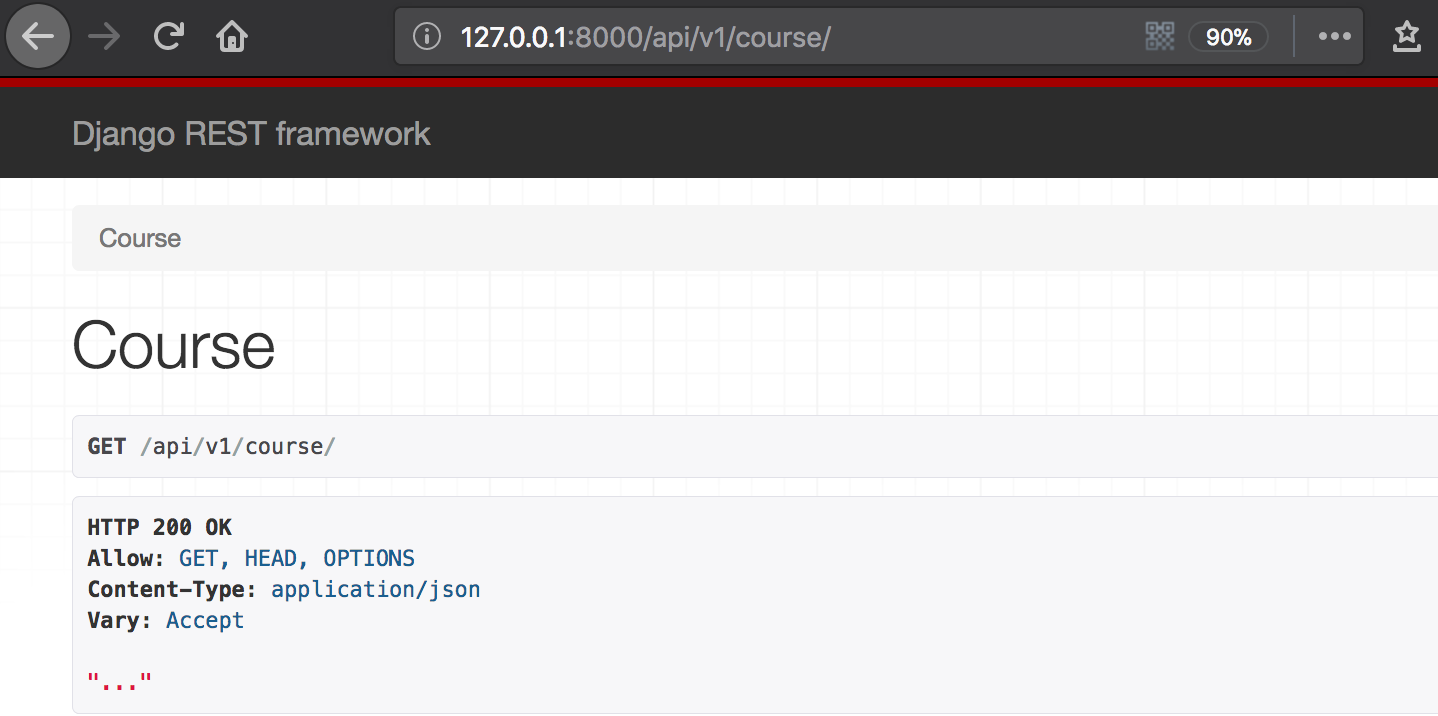
三、django部分构建中间件解决跨域问题
创建/api/cors.py,代码如下所示:
from django.middleware.common import CommonMiddleware # 通过它找到要引入的模块
from django.utils.deprecation import MiddlewareMixin class CORSMiddleware(MiddlewareMixin):
"""自定义中间件"""
def process_response(self, request, response):
# 添加响应头 # 允许你的域名来获取我的数据
response['Access-Control-Allow-Origin'] = "*"
# 允许你携带Content-Type请求头,这里不能写*
response['Access-Control-Allow-Headers'] = "Content-Type"
# 允许你发送GET/POST/DELETE/PUT
response['Access-Control-Allow-Methods'] = "GET, POST"
return response
修改settings.py,添加中间件:
MIDDLEWARE = [
'django.middleware.security.SecurityMiddleware',
'django.contrib.sessions.middleware.SessionMiddleware',
'django.middleware.common.CommonMiddleware',
'django.middleware.csrf.CsrfViewMiddleware',
'django.contrib.auth.middleware.AuthenticationMiddleware',
'django.contrib.messages.middleware.MessageMiddleware',
'django.middleware.clickjacking.XFrameOptionsMiddleware',
'api.cors.CORSMiddleware'
]
四、API示例数据录入
1、构建模型表并数据迁移
from django.db import models
# Create your models here. class Course(models.Model):
"""课程表"""
title = models.CharField(verbose_name='课程名称', max_length=32)
course_img = models.CharField(verbose_name="课程图片", max_length=64)
level_choices = (
(1, "初级"),
(2, "中级"),
(3, "高级"),
)
level = models.IntegerField(verbose_name="课程难易程度", choices=level_choices, default=1) def __str__(self):
return self.title class CourseDetail(models.Model):
"""课程详细表"""
course = models.OneToOneField(to='Course', on_delete=models.CASCADE)
slogon = models.CharField(verbose_name="口号", max_length=255)
why = models.CharField(verbose_name="为什么要学习?", max_length=255)
recommend_courses = models.ManyToManyField(verbose_name="推荐课程", to="Course", related_name="rc") def __str__(self):
return "课程详细:" + self.course.title class Chapter(models.Model):
"""章节"""
num = models.IntegerField(verbose_name="章节")
name = models.CharField(verbose_name="章节名称", max_length=32)
course = models.ForeignKey(verbose_name="所属课程", to="Course", on_delete=models.CASCADE) def __str__(self):
return "课程章节" + self.name
执行数据迁移操作。
2、admin组件使用
from django.contrib import admin
from api import models # Register your models here. """ root/root!2345 """
admin.site.register(models.Course)
admin.site.register(models.CourseDetail)
admin.site.register(models.Chapter)
3、数据录入
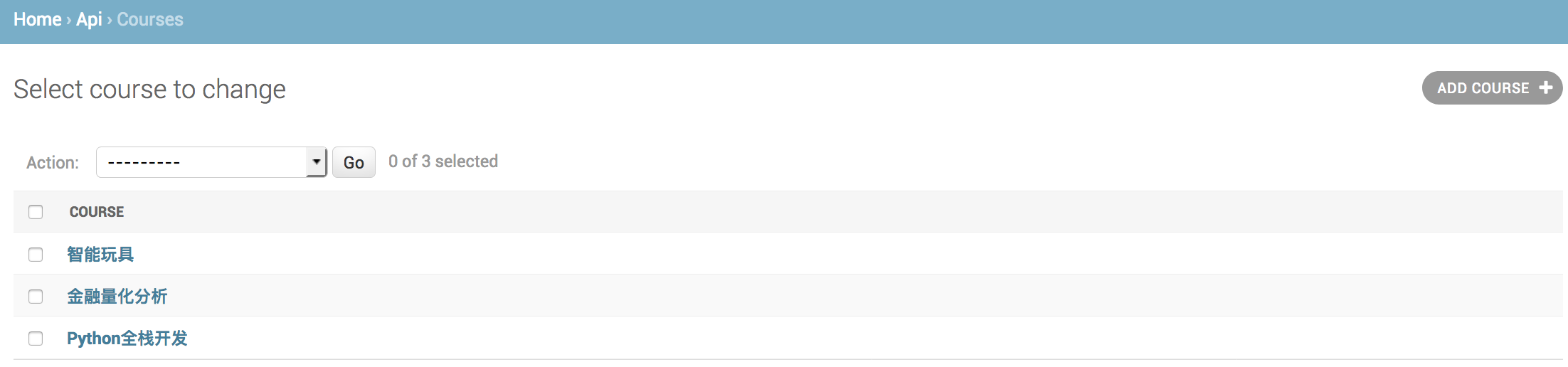
五、api课程查询接口
基于rest-framework实现查询课程查询接口。
1、方式一:根据带不带id交给同一视图不同代码去处理
api/urls.py:
from django.conf.urls import url, include
from api.views import course urlpatterns = [
# 方式一:
url(r'^(?P<version>[v1|v2]+)/course/$', course.CourseView.as_view()),
url(r'^(?P<version>[v1|v2]+)/course/(?P<pk>\d+)/$', course.CourseView.as_view()),
]
api/views/course.py:
from rest_framework.views import APIView
from rest_framework.response import Response
from api import models
from rest_framework import serializers class CourseSerializer(serializers.ModelSerializer):
"""对django model 的实例进行序列化"""
class Meta:
# 帮忙转换没有自己写的字段
model = models.Course
fields = "__all__" class CourseView(APIView): def get(self, request, *args, **kwargs):
"""
查看所有的课程:http://127.0.0.1:8000/api/v1/course/
查看某一课程:http://127.0.0.1:8000/api/v1/course/1
"""
ret = {'code': 1000, 'data': None}
try:
pk = kwargs.get('pk')
if pk: # 如果pk有值
obj = models.Course.objects.filter(id=pk).first()
ser = CourseSerializer(instance=obj, many=False)
else:
queryset = models.Course.objects.all() # QuerySet里面是一个个对象
ser = CourseSerializer(instance=queryset, many=True) # 序列化结果
ret['data'] = ser.data
except Exception as e:
ret['code'] = 1001
ret['error'] = "获取课程失败" return Response(ret)
显示效果:
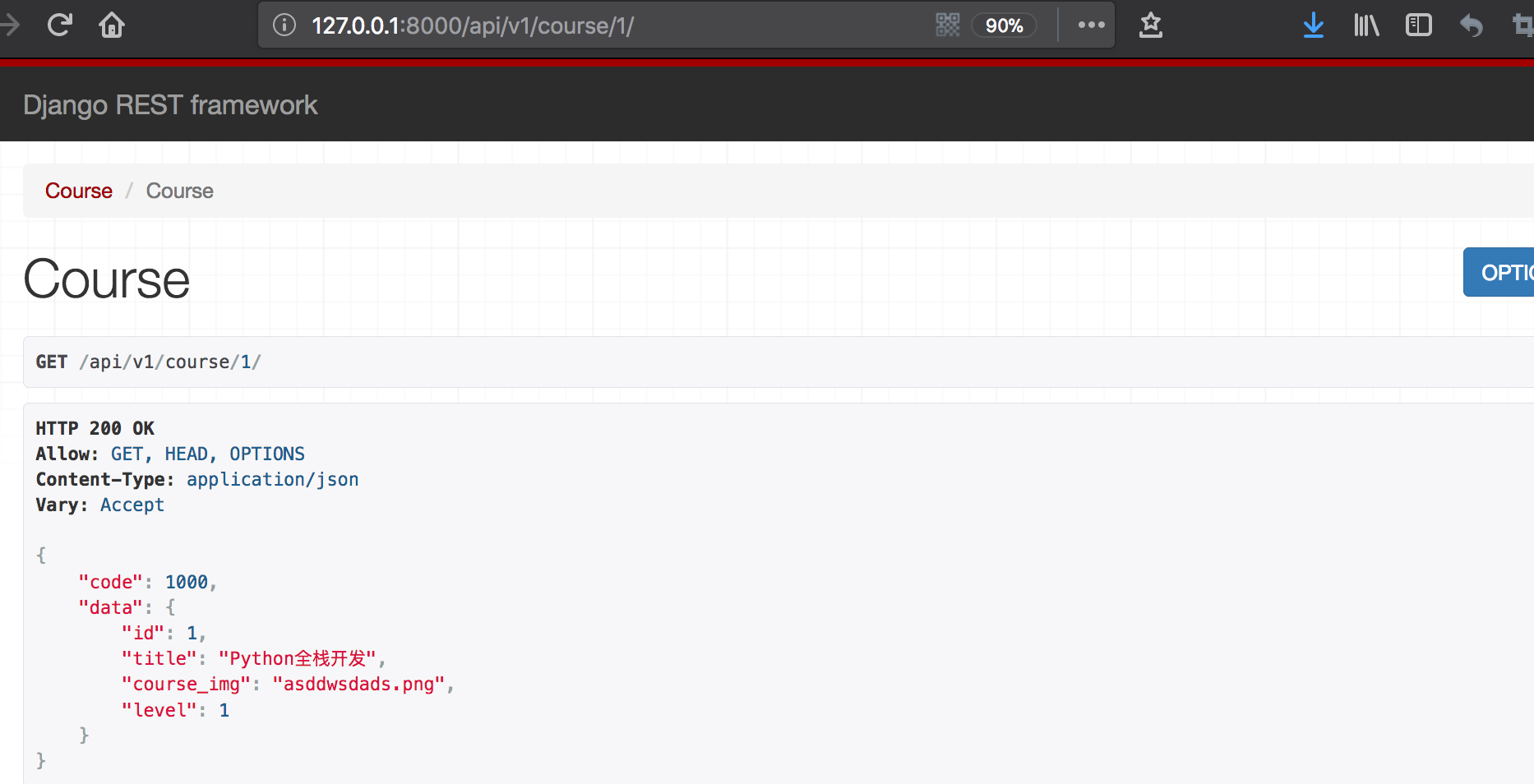
这种方法虽然可以实现但是如果代码很多时,就看起来很不简洁了。如果能交给不同的方法来执行就比较好了。
2、方式二:由视图类中不同的方法来处理不同的查询操作
api/urls.py:
from django.conf.urls import url, include
from api.views import course urlpatterns = [
# 方式二:前提是要重写as_view
url(r'^(?P<version>[v1|v2]+)/course/$', course.CourseView.as_view({'get': 'list'})),
url(r'^(?P<version>[v1|v2]+)/course/(?P<pk>\d+)/$', course.CourseView.as_view({'get': 'retrieve'})),
]
api/views/course.py改写如下:
from rest_framework.viewsets import ViewSetMixin
class CourseView(ViewSetMixin, APIView):
def list(self, request, *args, **kwargs):
"""
课程列表接口
:param request:
:param args:
:param kwargs:
:return:
"""
ret = {'code': 1000, 'data': None}
try:
queryset = models.Course.objects.all() # QuerySet里面是一个个对象
ser = CourseSerializer(instance=queryset, many=True) # 序列化结果 True:queryset
ret['data'] = ser.data
except Exception as e:
ret['code'] = 1001
ret['error'] = "获取课程失败"
return Response(ret)
def retrieve(self, request, *args, **kwargs):
"""
课程详细接口
:param request:
:param args:
:param kwargs:
:return:
"""
ret = {'code': 1000, 'data': None}
try:
pk = kwargs.get('pk')
obj = models.Course.objects.filter(id=pk).first()
ser = CourseSerializer(instance=obj, many=False) # many描述是model对象还是QuerySet False:对象
ret['data'] = ser.data
except Exception as e:
ret['code'] = 1001
ret['error'] = "获取课程失败"
return Response(ret)
注意:many描述是model对象还是QuerySet,当many=True时,描述是QuerySet;当many=False时,描述是model对象。
六、api示例之课程详细接口
1、简单实现详细信息的序列化(depth)
course.py调整如下:
from rest_framework.views import APIView
from rest_framework.response import Response
from api import models
from rest_framework import serializers class CourseSerializer(serializers.ModelSerializer):
"""对django model 的实例进行序列化"""
class Meta:
# 帮忙转换没有自己写的字段
model = models.Course
fields = "__all__" class CourseDetailSerializer(serializers.ModelSerializer):
"""课程详细序列化"""
class Meta:
model = models.CourseDetail
fields = "__all__"
depth = 1 # 0-10之间,0是帮忙找一层(当前表关联的表)的数据,1是找两层(再往下找一层关联表)的数据 from rest_framework.viewsets import ViewSetMixin class CourseView(ViewSetMixin, APIView):
def list(self, request, *args, **kwargs):
"""
课程列表接口
:param request:
:param args:
:param kwargs:
:return:
"""
ret = {'code': 1000, 'data': None}
try:
queryset = models.Course.objects.all() # QuerySet里面是一个个对象
ser = CourseSerializer(instance=queryset, many=True) # 序列化结果 True:queryset
ret['data'] = ser.data
except Exception as e:
ret['code'] = 1001
ret['error'] = "获取课程失败" return Response(ret) def retrieve(self, request, *args, **kwargs):
"""
课程详细接口
:param request:
:param args:
:param kwargs:
:return:
"""
ret = {'code': 1000, 'data': None}
try:
pk = kwargs.get('pk') # 课程id
# 课程详细对象
obj = models.CourseDetail.objects.filter(course_id=pk).first()
ser = CourseDetailSerializer(instance=obj, many=False)
ret['data'] = ser.data except Exception as e:
ret['code'] = 1001
ret['error'] = "获取课程失败" return Response(ret)
主要是调整了retrieve方法,增加了CourseDetailSerializer来处理详细信息序列化。
注意:这里配置depth = 1 官方推荐是:配置0-10之间,0是帮忙找一层(当前表关联的表)的数据,1是找两层(再往下找一层关联表)的数据。
显示效果:
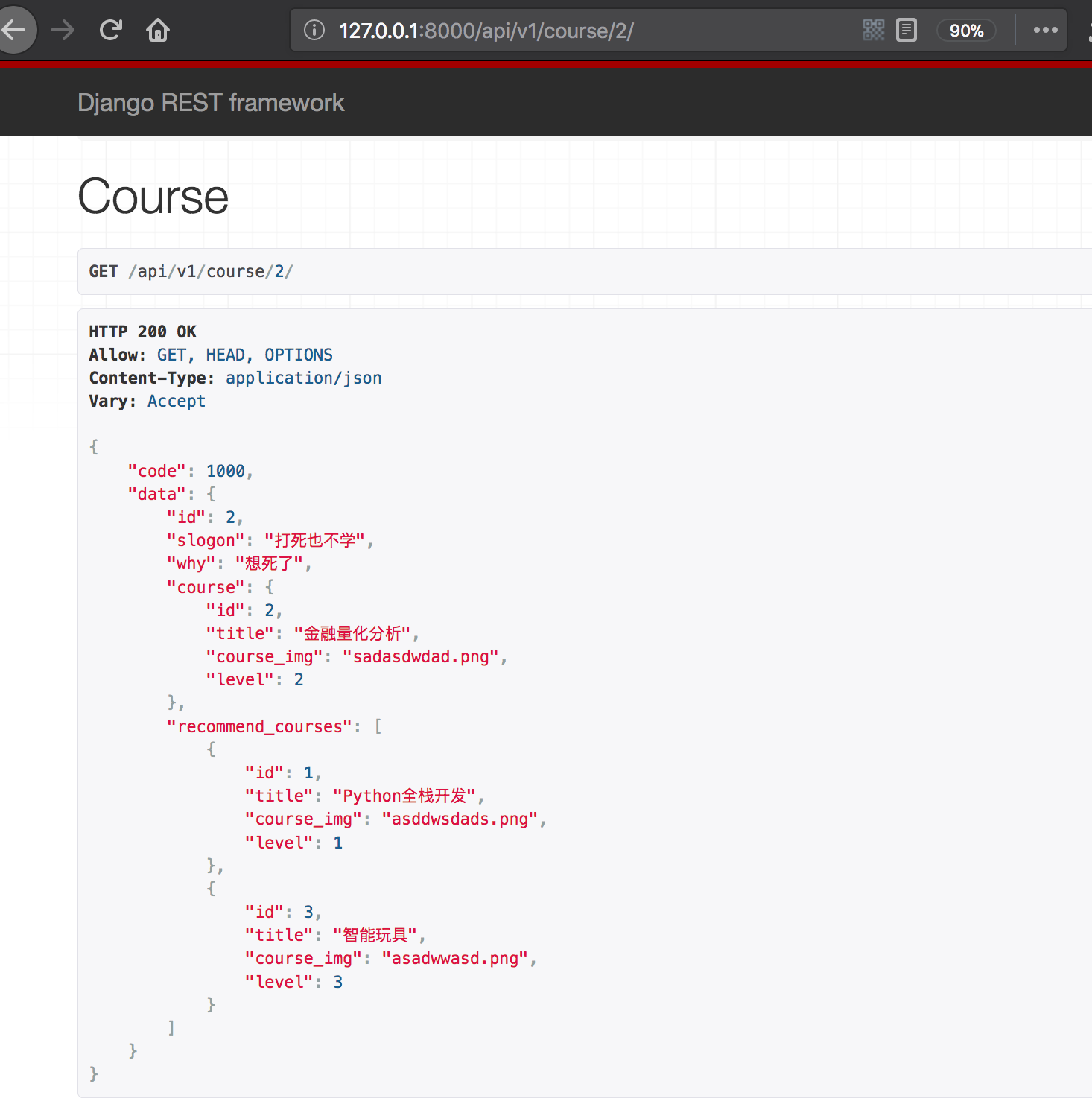
虽然这种方法可以实现效果,但是它往往给的数据过多了。
2、指定数据库字段在页面显示
对CourseDetailSerializer做了如下修改:
class CourseDetailSerializer(serializers.ModelSerializer):
"""课程详细序列化"""
# 自定义字段 serializers默认对model对象做序列化
title = serializers.CharField(source="course.title") # source与数据库的某个字段绑定,这样写完成了跨表查询
img = serializers.CharField(source="course.course_img")
# level = serializers.CharField(source="course.level") # 这个只是拿到了数字
level = serializers.CharField(source="course.get_level_display") class Meta:
model = models.CourseDetail
fields = ["course", "title", "img", "level", "slogon", "why"]
注意source的用法,且get_字段名_display()可以用来获取对应字段的值
显示效果:
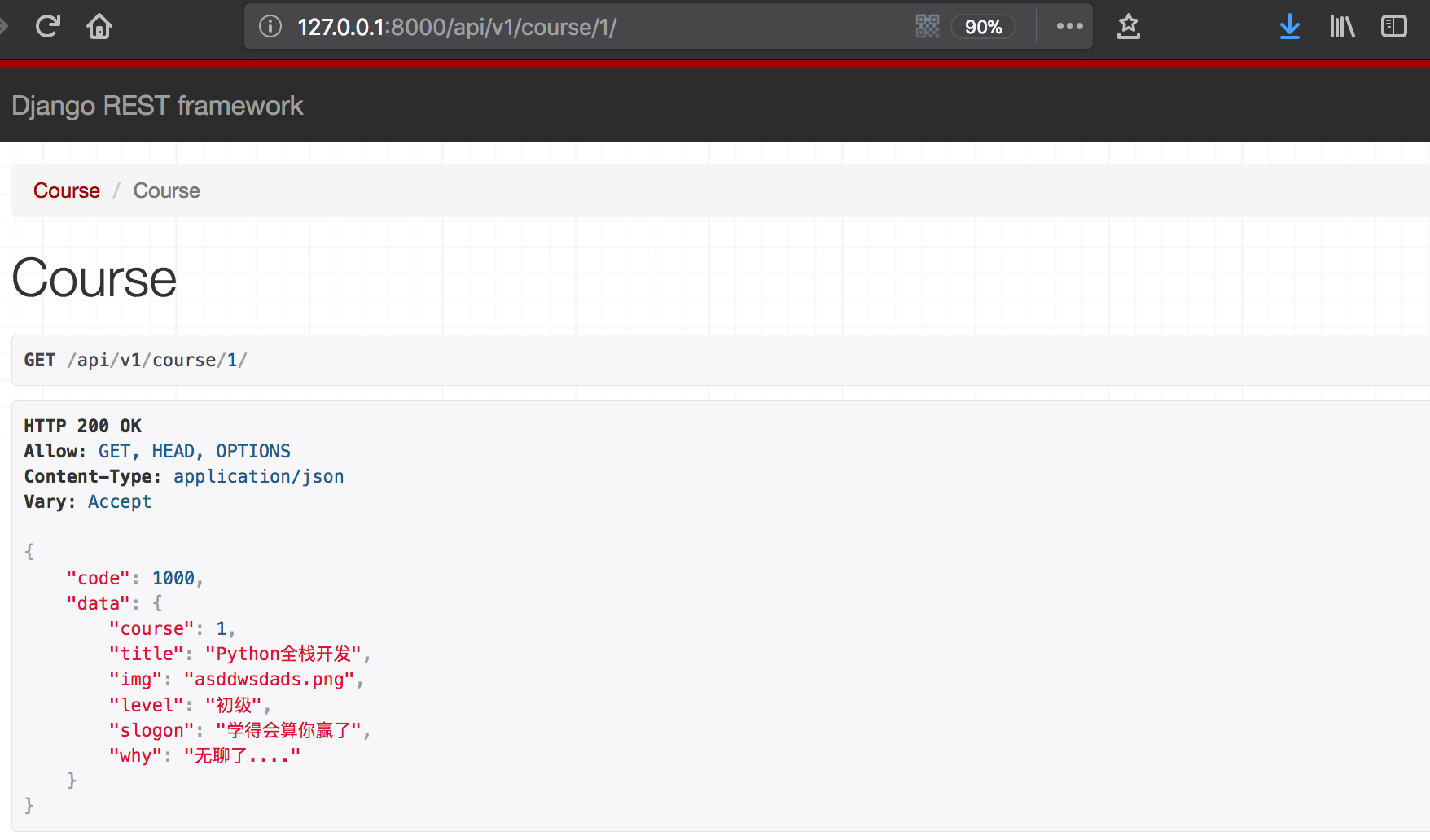
3、进一步拿到推荐课程信息
source用来解决一对一、外键、choice的跨表查询。但是遇到多对多就不好用了。
class CourseDetailSerializer(serializers.ModelSerializer):
"""课程详细序列化"""
# 自定义字段 serializers默认对model对象做序列化
title = serializers.CharField(source="course.title") # source与数据库的某个字段绑定,这样写完成了跨表查询
img = serializers.CharField(source="course.course_img")
# level = serializers.CharField(source="course.level") # 这个只是拿到了数字
level = serializers.CharField(source="course.get_level_display") # 针对多对多字段使用SerializerMethodField
recommends = serializers.SerializerMethodField() # 取get_recommends(obj)的返回值 class Meta:
model = models.CourseDetail
fields = ["course", "title", "img", "level", "slogon", "why", "recommends"] def get_recommends(self, obj): # 注意这个方法必须是“get_"拼接配置了SerializerMethodField的字段。
# 获取推荐的所有课程
queryset = obj.recommend_courses.all()
return [{'id': row.id, 'title': row.title} for row in queryset]
注意多对多的字段使用SerializerMethodField,recommends取的是get_recommends函数的返回值。
注意这个方法必须是“get_"拼接配置了SerializerMethodField的字段。显示效果如下:
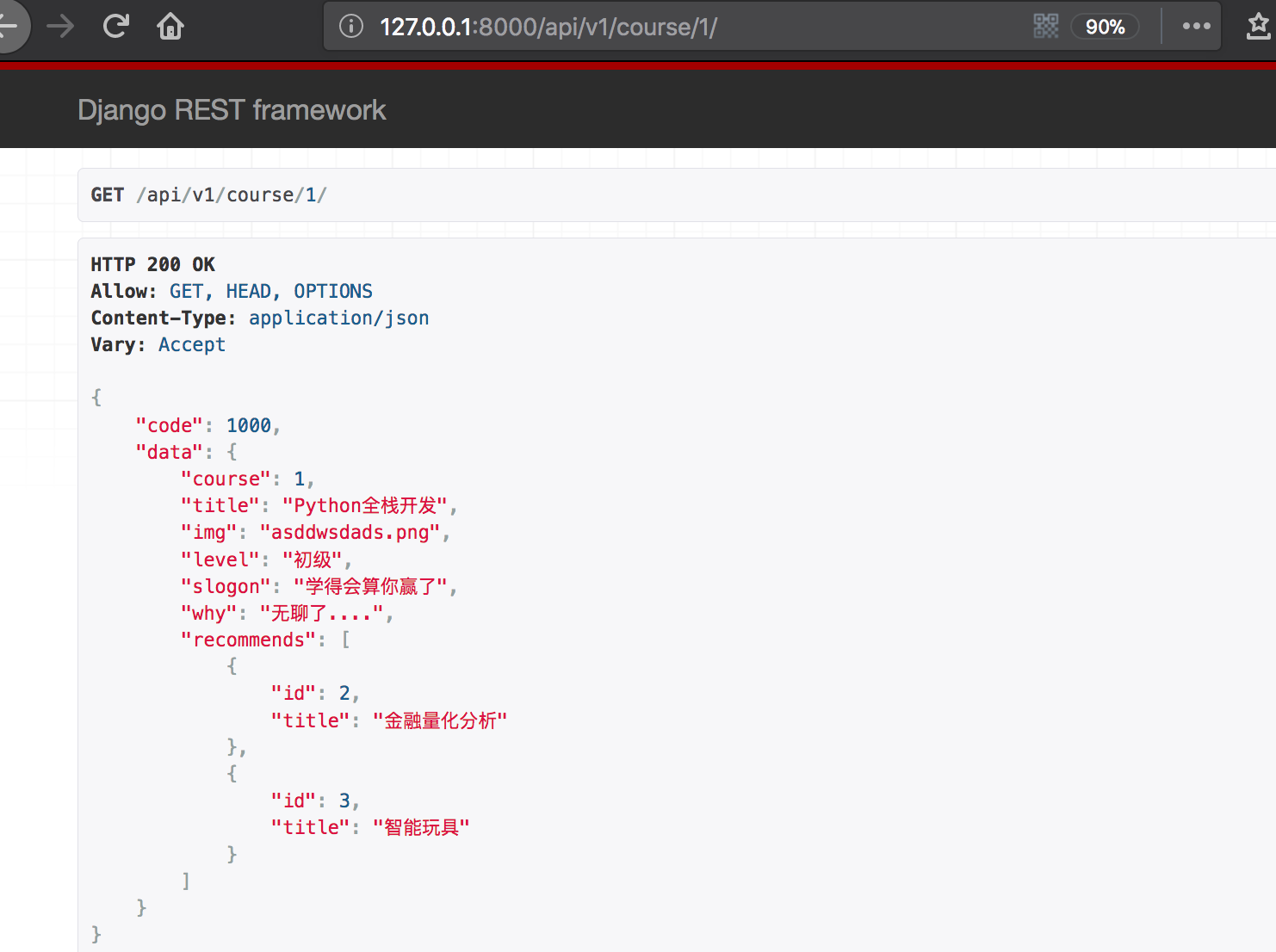
七、api示例之课程优化(练习题 )
1、查询所有课程level字段修改为中文
修改CourseSerializer实现对课程列表序列化修改:
class CourseSerializer(serializers.ModelSerializer):
"""对django model 的实例进行序列化"""
# 自定义字段
level = serializers.CharField(source="get_level_display") class Meta:
# 帮忙转换没有自己写的字段
model = models.Course
fields = ["id", "title", "course_img", "level"]
显示效果:
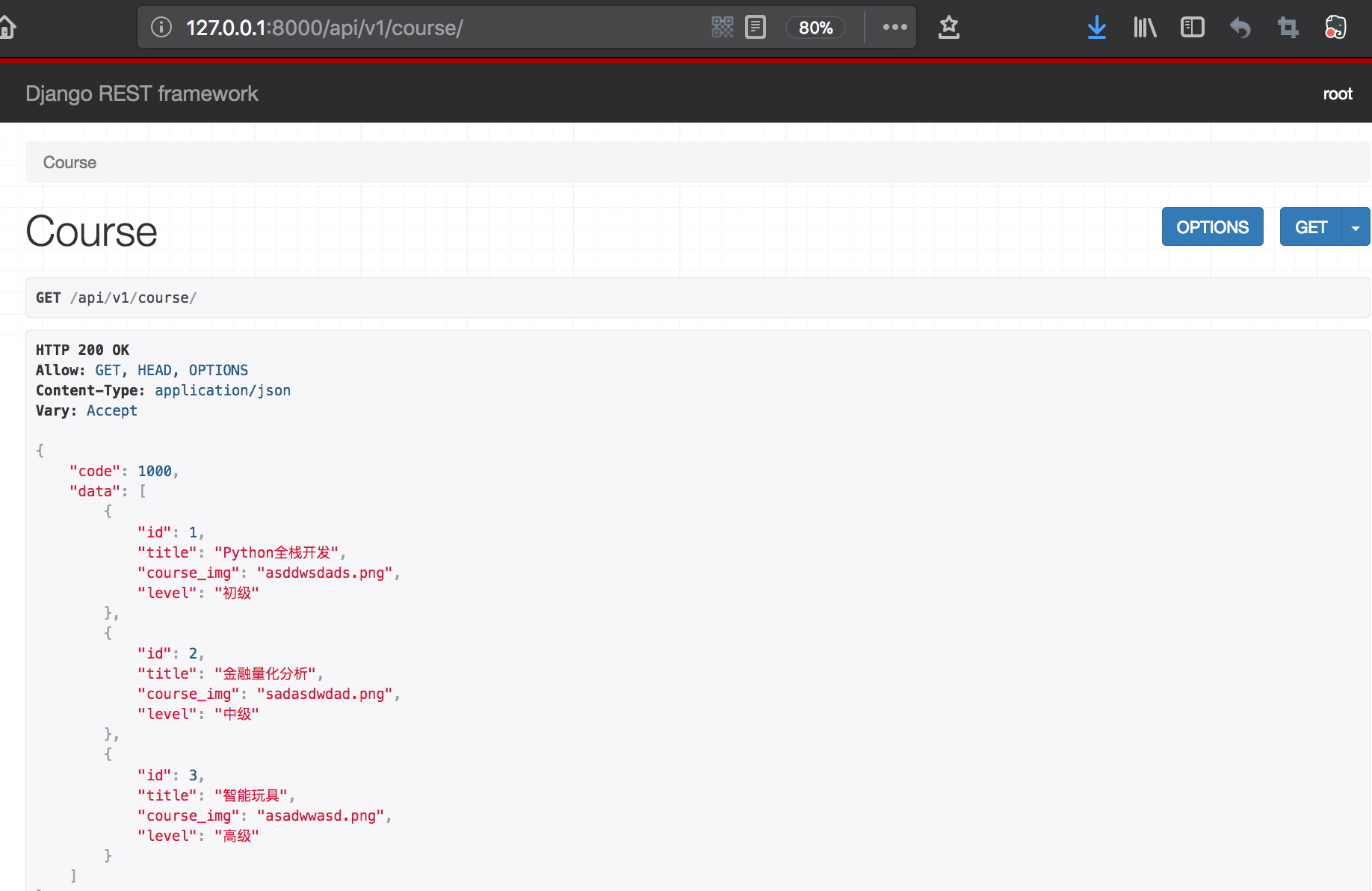
2、查询课程详细——显示该课程相关的所有章节
修改CourseDetailSerializer如下所示:
class CourseDetailSerializer(serializers.ModelSerializer):
"""课程详细序列化"""
# 自定义字段 serializers默认对model对象做序列化
title = serializers.CharField(source="course.title") # source与数据库的某个字段绑定,这样写完成了跨表查询
img = serializers.CharField(source="course.course_img")
# level = serializers.CharField(source="course.level") # 这个只是拿到了数字
level = serializers.CharField(source="course.get_level_display") # 针对多对多字段使用SerializerMethodField
recommends = serializers.SerializerMethodField() # 取get_recommends(obj)的返回值
chapter = serializers.SerializerMethodField() class Meta:
model = models.CourseDetail
fields = ["course", "title", "img", "level", "slogon", "why", "recommends", "chapter"] def get_recommends(self, obj): # 注意这个方法必须是“get_"拼接配置了SerializerMethodField的字段。
# 获取推荐的所有课程
queryset = obj.recommend_courses.all()
return [{'id': row.id, 'title': row.title} for row in queryset] def get_chapter(self, obj): # obj是课程详细的对象
queryset = obj.course.chapter_set.all() # course.chapter_set反向查找,取到所有的章节
return [{'id': row.id, 'name': row.name} for row in queryset]
Django 中的一对多关系用 ForeignKey 来实现,一对多的反向查询是通过:按表名小写_set.all() 来实现的。
显示效果如下所示:
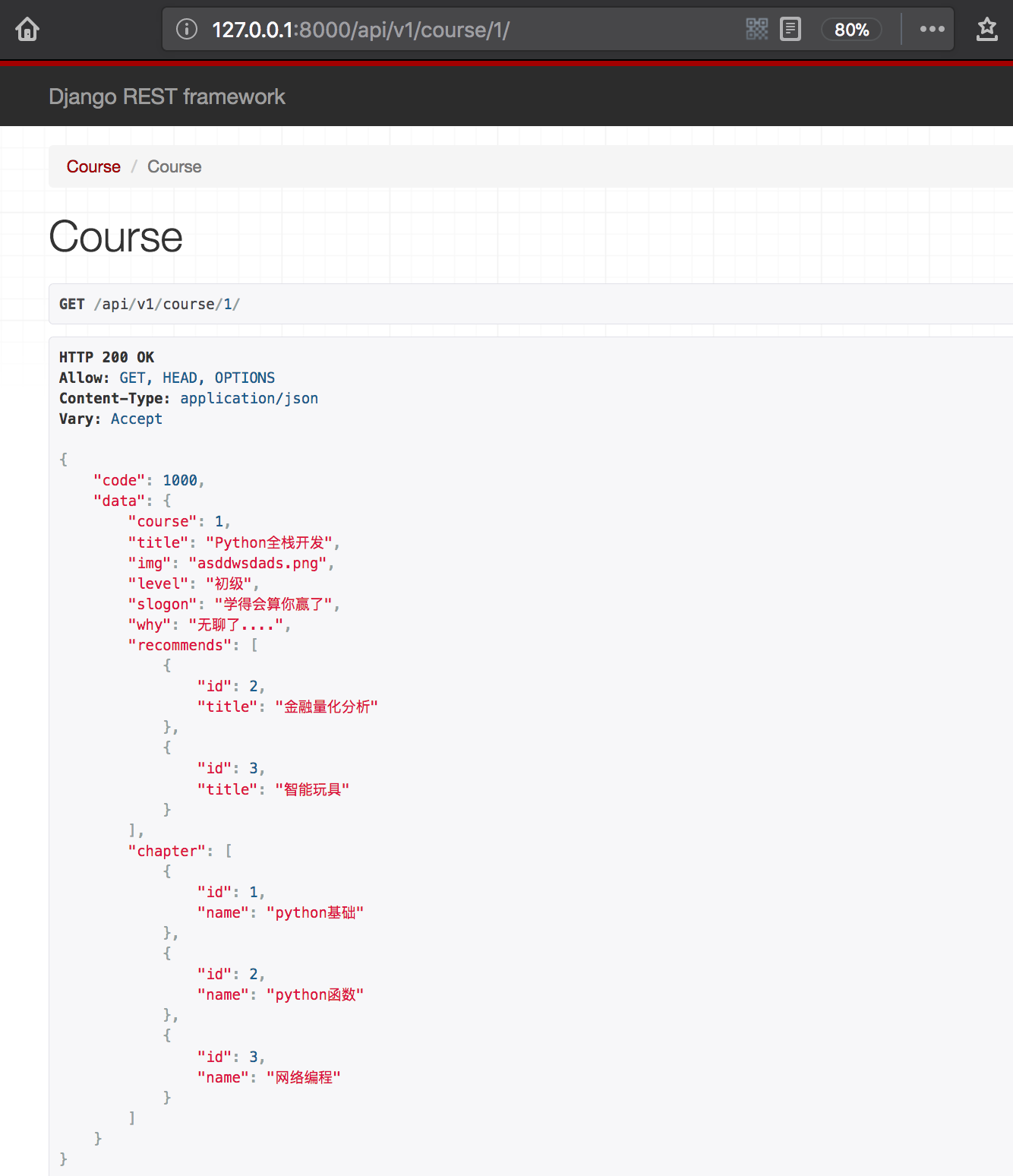
3、序列化和视图解耦
创建/api/serializers/course.py文件夹和文件,将序列化相关内容迁移过来,如下所示:
from api import models
from rest_framework import serializers class CourseSerializer(serializers.ModelSerializer):
"""课程序列化"""
# 自定义字段
level = serializers.CharField(source="get_level_display") class Meta:
# 帮忙转换没有自己写的字段
model = models.Course
fields = ["id", "title", "course_img", "level"] class CourseDetailSerializer(serializers.ModelSerializer):
"""课程详细序列化"""
# 自定义字段 serializers默认对model对象做序列化
title = serializers.CharField(source="course.title") # source与数据库的某个字段绑定,这样写完成了跨表查询
img = serializers.CharField(source="course.course_img")
# level = serializers.CharField(source="course.level") # 这个只是拿到了数字
level = serializers.CharField(source="course.get_level_display") # 针对多对多字段使用SerializerMethodField
recommends = serializers.SerializerMethodField() # 取get_recommends(obj)的返回值
chapter = serializers.SerializerMethodField() class Meta:
model = models.CourseDetail
fields = ["course", "title", "img", "level", "slogon", "why", "recommends", "chapter"] def get_recommends(self, obj): # 注意这个方法必须是“get_"拼接配置了SerializerMethodField的字段。
# 获取推荐的所有课程
queryset = obj.recommend_courses.all()
return [{'id': row.id, 'title': row.title} for row in queryset] def get_chapter(self, obj): # obj是课程详细的对象
queryset = obj.course.chapter_set.all() # course.chapter_set反向查找,取到所有的章节
return [{'id': row.id, 'name': row.name} for row in queryset]
在view/course.py中引入序列化组件:
from rest_framework.views import APIView
from rest_framework.response import Response
from api import models
from api.serializers.course import CourseDetailSerializer, CourseSerializer
from rest_framework.viewsets import ViewSetMixin class CourseView(ViewSetMixin, APIView): def list(self, request, *args, **kwargs):
"""
课程列表接口
:param request:
:param args:
:param kwargs:
:return:
"""
ret = {'code': 1000, 'data': None}
try:
queryset = models.Course.objects.all() # QuerySet里面是一个个对象
ser = CourseSerializer(instance=queryset, many=True) # 序列化结果 True:queryset
ret['data'] = ser.data
except Exception as e:
ret['code'] = 1001
ret['error'] = "获取课程失败" return Response(ret) def retrieve(self, request, *args, **kwargs):
"""
课程详细接口
:param request:
:param args:
:param kwargs:
:return:
"""
ret = {'code': 1000, 'data': None}
try:
pk = kwargs.get('pk') # 课程id
# 课程详细对象
obj = models.CourseDetail.objects.filter(course_id=pk).first() ser = CourseDetailSerializer(instance=obj, many=False)
ret['data'] = ser.data except Exception as e:
ret['code'] = 1001
ret['error'] = "获取课程失败" return Response(ret)
vue+rest-framework前后端分离整合的更多相关文章
- List多个字段标识过滤 IIS发布.net core mvc web站点 ASP.NET Core 实战:构建带有版本控制的 API 接口 ASP.NET Core 实战:使用 ASP.NET Core Web API 和 Vue.js 搭建前后端分离项目 Using AutoFac
List多个字段标识过滤 class Program{ public static void Main(string[] args) { List<T> list = new List& ...
- Vue+Spring Boot 前后端分离的商城项目开源啦!
新蜂商城 Vue 移动端版本开源啦! 去年开源新蜂商城项目后,就一直在计划这个项目 Vue 版本的改造,2020 年开始开发并且自己私下一直在测试,之前也有文章介绍过测试过程和存在的问题,修改完成后, ...
- ASP.NET Core 实战:使用 ASP.NET Core Web API 和 Vue.js 搭建前后端分离项目
一.前言 这几年前端的发展速度就像坐上了火箭,各种的框架一个接一个的出现,需要学习的东西越来越多,分工也越来越细,作为一个 .NET Web 程序猿,多了解了解行业的发展,让自己扩展出新的技能树,对自 ...
- VUE开发(二)nginx配合vue来实现前后端分离部署
一.引言 由于本地是采用vue+spring boot实现的前后端分离项目,本机启动的时候先启动后场服务,再单独启动vue工程,然后可以实现全流程贯穿,但是我们要部署到服务器上的时候,一般都是打一个j ...
- vue项目实践-前后端分离关于权限的思路
前后端分离后权限的思路 最近看到许多关于权限的思路,但好像都是使用动态加载路由的方式,现在也分享下我在项目中使用的解决方案. 前后端分离关于权限的处理每个人都不一样,根据项目选择制定合适的方案就好 我 ...
- vue+node+mongodb前后端分离博客系统
感悟 历时两个多月,终于利用工作之余完成了这个项目的1.0版本,为什么要写这个项目?其实基于vuejs+nodejs构建的开源博客系统有很多,但是大多数不支持服务端渲染,也不支持动态标题,只是做到了前 ...
- Springboot + Vue + shiro 实现前后端分离、权限控制
本文总结自实习中对项目对重构.原先项目采用Springboot+freemarker模版,开发过程中觉得前端逻辑写的实在恶心,后端Controller层还必须返回Freemarker模版的ModelA ...
- Vue+Express实现前后端分离
先说明一下缘由,因为自己前段时间在实习,实习期间为了参与项目开发,粗略学习了下Vue.Vuex.Vue-Router,大致会一些基础的.这里也快要做毕业设计了,趁着放假回来的这两天,学习下Node的相 ...
- vue+Ueditor集成 [前后端分离项目][图片、文件上传][富文本编辑]
后端DEMO:https://github.com/coderliguoqing/UeditorSpringboot 前端DEMO:https://github.com/coderliguoqing/ ...
随机推荐
- opencv学习笔记1
#对图像的像素处理#法1print("------------------------")image = cv.imread("D:/1.jpeg",cv.IM ...
- linux的发行版
Linux的不同版本以及应用领域 1.Linux内核及发行版介绍 <1>Linux内核版本 内核(kernel)是系统的心脏,是运行程序和管理像磁盘和打印机等硬件设备的核心程序,它提供了一 ...
- Hadoop文章
hadoop入门--简单的MapReduce案例:https://blog.csdn.net/zhangt85/article/details/42077281?utm_source=blogxgwz ...
- 关于Apache显示port 80 in use 无法解决的情况,这个世界对程序媛太不友好了
学到Ajax时下载了Apache,百度的安装教程,配置文件参数分别是: 1. httpd.conf里的80改为8000或者其他的,共三处(用记事本打开,按ctrl+F找方便) 2. httpd-ssl ...
- Jupyter 安装与应用
用pip安装Jupyter pip install jupyter 从命令行启动笔记本服务器 jupyter notebook 前提要先启动python,这里有一个 token值,如果不是使用默认浏览 ...
- 03-树3 Tree Traversals Again (25 分)
An inorder binary tree traversal can be implemented in a non-recursive way with a stack. For example ...
- 关于vue2非表单元素使用contenteditable="true"实现textarea高度自适应
<template> <div ref="sendContent" contenteditable="true" v-html="s ...
- [转] log4j-over-slf4j与slf4j-log4j12共存stack overflow异常分析
[From] http://www.tuicool.com/articles/INveIf 注:下文中的“桥接”.“转调”.“绑定”等词基本都是同一个概念. log4j-over-slf4j和slf4 ...
- 协程:gevent模块,遇到i/o自动切换任务 038
协程 : gevent模块,遇到io自动切换任务 from gevent import monkey;monkey.patch_all() # 写在最上面 这样后面的所有阻塞就全部能够识别了 impo ...
- 二维vector容器读取txt坐标
template <class vector> struct HeadLocation{ vector x; vector y; }; vector<HeadLocation< ...