javascript实现数据结构: 树和二叉树的应用--最优二叉树(赫夫曼树),回溯法与树的遍历--求集合幂集及八皇后问题
赫夫曼树及其应用
赫夫曼(Huffman)树又称最优树,是一类带权路径长度最短的树,有着广泛的应用。
最优二叉树(Huffman树)
1 基本概念
① 结点路径:从树中一个结点到另一个结点的之间的分支构成这两个结点之间的路径。
② 路径长度:结点路径上的分支数目称为路径长度。
③ 树的路径长度:从树根到每一个结点的路径长度之和。
以下图为例:
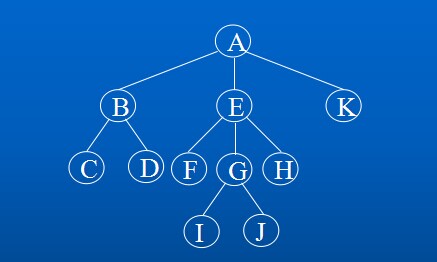
A到F :结点路径 AEF ;
路径长度(即边的数目) 2 ;
树的路径长度:3*1+5*2+2*3=19;
④ 结点的带权路径长度:从该结点的到树的根结点之间的路径长度与结点的权(值)的乘积。
权(值):各种开销、代价、频度等的抽象称呼。
⑤ 树的带权路径长度:树中所有叶子结点的带权路径长度之和,记做:
WPL=w1*l1+w2*l2+⋯+wn*ln=∑wi*li (i=1,2,⋯,n)
其中:n为叶子结点的个数;wi为第i个结点的权值; li为第i个结点的路径长度。
⑥ Huffman树:具有n个叶子结点(每个结点的权值为wi) 的二叉树不止一棵,但在所有的这些二叉树中,必定存在一棵WPL值最小的树,称这棵树为Huffman树(或称最优树) 。
在许多判定问题时,利用Huffman树可以得到最佳判断算法。
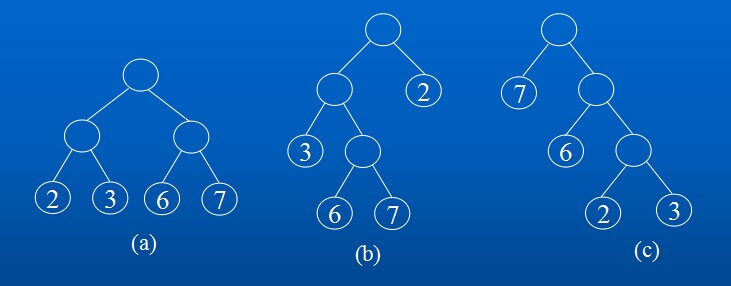
下图是权值分别为2、3、6、7,具有4个叶子结点的二叉树,它们的带权路径长度分别为:
(a) WPL=2*2+3*2+6*2+7*2=36 ;
(b) WPL=2*1+3*2+6*3+7*3=47 ;
(c) WPL=7*1+6*2+2*3+3*3=34 。
其中(c)的 WPL值最小,可以证明是Huffman树。
2 Huffman树的构造
① 根据n个权值{w1, w2, ⋯,wn},构造成n棵二叉树的集合F={T1, T2, ⋯,Tn},其中每棵二叉树只有一个权值为wi的根结点,没有左、右子树;
② 在F中选取两棵根结点权值最小的树作为左、右子树构造一棵新的二叉树,且新的二叉树根结点权值为其左、右子树根结点的权值之和;
③ 在F中删除这两棵树,同时将新得到的树加入F中;
④ 重复②、③,直到F只含一棵树为止。
构造Huffman树时,为了规范,规定F={T1,T2, ⋯,Tn}中权值小的二叉树作为新构造的二叉树的左子树,权值大的二叉树作为新构造的二叉树的右子树;在取值相等时,深度小的二叉树作为新构造的二叉树的左子树,深度大的二叉树作为新构造的二叉树的右子树。
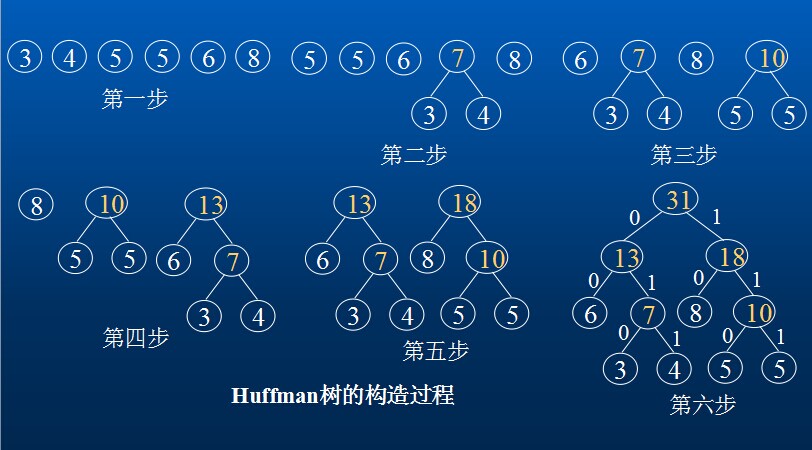
下图是权值集合W={8, 3, 4, 6, 5, 5}构造Huffman树的过程。所构造的Huffman树的WPL是: WPL=6*2+3*3+4*3+8*2+5*3+5*3 =79
赫夫曼编码及其算法
1 Huffman编码
在电报收发等数据通讯中,常需要将传送的文字转换成由二进制字符0、1组成的字符串来传输。为了使收发的速度提高,就要求电文编码要尽可能地短。此外,要设计长短不等的编码,还必须保证任意字符的编码都不是另一个字符编码的前缀,这种编码称为前缀编码。
Huffman树可以用来构造编码长度不等且译码不产生二义性的编码。
设电文中的字符集C={c1,c2, ⋯,ci, ⋯,cn},各个字符出现的次数或频度集W={w1,w2, ⋯,wi, ⋯,wn}。
Huffman编码方法
以字符集C作为叶子结点,次数或频度集W作为结点的权值来构造 Huffman树。规定Huffman树中左分支代表“0”,右分支代表“1” 。
从根结点到每个叶子结点所经历的路径分支上的“0”或“1”所组成的字符串,为该结点所对应的编码,称之为Huffman编码。
由于每个字符都是叶子结点,不可能出现在根结点到其它字符结点的路径上,所以一个字符的Huffman编码不可能是另一个字符的Huffman编码的前缀。
若字符集C={a, b, c, d, e, f}所对应的权值集合为W={8, 3, 4, 6, 5, 5},如上图所示,则字符a,b, c,d, e,f所对应的Huffman编码分别是:10,010,011,00 ,110,111。
2 Huffman编码算法实现
(1) 数据结构设计
Huffman树中没有度为1的结点棵有n个叶子结点的Huffman树共有2n-1个结点,则可存储在大小为2n-1的一维数组中。
原因:
◆ 求编码需从叶子结点出发走一条从叶子到根的路径;
◆ 译码需从根结点出发走一条到叶子结点的路径。
// 赫夫曼树和赫夫曼编码的存储结构
function HuffmanNode(weight, parent, leftChild, rightChild) {
this.weight = weight || 0;
this.parent = parent || 0;
this.leftChild = leftChild || 0;
this.rightChild = rightChild || 0;
}
Weight:权值域;
Parent:双亲结点下标
leftChild, rightChild:分别标识左、右子树的下标
(2) Huffman树的生成
// 创建一棵叶子结点数为n的Huffman树
function buildHuffmanTree(weights, n) {
n = n || weights.length;
var m = 2 * n - 1;
var huffmanTree = []; // 初始化
for (var i = 0; i < n; i++)
huffmanTree[i] = new HuffmanNode(weights[i], 0, 0, 0);
for (; i < m; i++)
huffmanTree[i] = new HuffmanNode(0, 0, 0, 0); for (i = n; i < m; i++) {
// 在HT[1..i-1]选择parent为0且weight最小的两个结点,返回其序号为[s1, s2]
var ret = select(huffmanTree, i);
var s1 = ret[0];
var s2 = ret[1];
huffmanTree[s1].parent = i;
huffmanTree[s2].parent = i;
huffmanTree[i].leftChild = s1;
huffmanTree[i].rightChild = s2;
huffmanTree[i].weight = huffmanTree[s1].weight + huffmanTree[s2].weight;
} return huffmanTree;
} function select(huffmanTree, len) {
var ret = [];
for (var i = 0; i < len; i++) {
var node = huffmanTree[i];
if (node.parent !== 0) continue; if (ret.length < 2) {
ret.push(i);
} else {
var index = huffmanTree[ret[0]].weight > huffmanTree[ret[1]].weight
? 0 : 1; if (node.weight < huffmanTree[ret[index]].weight)
ret[index] = i;
}
} if (ret[0] > ret[1]) {
var temp = ret[0];
ret[0] = ret[1];
ret[1] = temp;
} return ret;
}
说明:生成Huffman树后,树的根结点的下标是2n-1 ,即m-1 。
(3) Huffman编码算法
根据出现频度(权值)Weight,对叶子结点的Huffman编码有两种方式:
① 从叶子结点到根逆向处理,求得每个叶子结点对应字符的Huffman编码。
② 从根结点开始遍历整棵二叉树,求得每个叶子结点对应字符的Huffman编码。
由Huffman树的生成知,n个叶子结点的树共有2n-1个结点,叶子结点存储在数组HT中的下标值为1∽n。
① 编码是叶子结点的编码,只需对数组HT[1…n]的n个权值进行编码;
② 每个字符的编码不同,但编码的最大长度是n。
算法实现:
function huffManCoding(weights) {
var n = weights.length;
if (n < 1) return;
var huffmanTree = buildHuffmanTree(weights, n);
// 从叶子到根逆向求每个字符的赫夫曼编码
var hc = calcHuffmanCode(huffmanTree, n);
return [huffmanTree, hc];
}
function calcHuffmanCode(huffmanTree, n) {
// 从叶子到根逆向求每个字符的赫夫曼编码
var hc = [];
var cd = [];
for (var i = 0; i < n; i++) {
var start = n - 1;
for (var c = i, f = huffmanTree[i].parent; f != 0; c = f, f = huffmanTree[f].parent) {
if (huffmanTree[f].leftChild == c) cd[--start] = '0';
else cd[--start] = '1';
}
hc[i] = strCopy(cd, start);
}
return hc;
}
function strCopy(str, start) {
var s = '';
for (; str[start]; start++) {
s += str[start];
}
return s;
}
全部代码实现:
// 赫夫曼树和赫夫曼编码的存储结构
function HuffmanNode(weight, parent, leftChild, rightChild) {
this.weight = weight || 0;
this.parent = parent || 0;
this.leftChild = leftChild || 0;
this.rightChild = rightChild || 0;
}
function huffManCoding(weights) {
var n = weights.length;
if (n < 1) return; var huffmanTree = buildHuffmanTree(weights, n); // 从叶子到根逆向求每个字符的赫夫曼编码
var hc = calcHuffmanCode(huffmanTree, n); return [huffmanTree, hc];
} function calcHuffmanCode(huffmanTree, n) {
// 从叶子到根逆向求每个字符的赫夫曼编码
var hc = [];
var cd = [];
for (var i = 0; i < n; i++) {
var start = n - 1;
for (var c = i, f = huffmanTree[i].parent; f != 0; c = f, f = huffmanTree[f].parent) {
if (huffmanTree[f].leftChild == c) cd[--start] = '0';
else cd[--start] = '1';
} hc[i] = strCopy(cd, start);
} return hc;
} // 创建一棵叶子结点数为n的Huffman树
function buildHuffmanTree(weights, n) {
n = n || weights.length;
var m = 2 * n - 1;
var huffmanTree = []; // 初始化
for (var i = 0; i < n; i++)
huffmanTree[i] = new HuffmanNode(weights[i], 0, 0, 0);
for (; i < m; i++)
huffmanTree[i] = new HuffmanNode(0, 0, 0, 0); for (i = n; i < m; i++) {
// 在HT[1..i-1]选择parent为0且weight最小的两个结点,返回其序号为[s1, s2]
var ret = select(huffmanTree, i);
var s1 = ret[0];
var s2 = ret[1];
huffmanTree[s1].parent = i;
huffmanTree[s2].parent = i;
huffmanTree[i].leftChild = s1;
huffmanTree[i].rightChild = s2;
huffmanTree[i].weight = huffmanTree[s1].weight + huffmanTree[s2].weight;
} return huffmanTree;
} function strCopy(str, start) {
var s = '';
for (; str[start]; start++) {
s += str[start];
}
return s;
} function select(huffmanTree, len) {
var ret = [];
for (var i = 0; i < len; i++) {
var node = huffmanTree[i];
if (node.parent !== 0) continue; if (ret.length < 2) {
ret.push(i);
} else {
var index = huffmanTree[ret[0]].weight > huffmanTree[ret[1]].weight
? 0 : 1; if (node.weight < huffmanTree[ret[index]].weight)
ret[index] = i;
}
} if (ret[0] > ret[1]) {
var temp = ret[0];
ret[0] = ret[1];
ret[1] = temp;
} return ret;
} console.log('-------huffman coding :------');
console.log(huffManCoding([5, 29, 7, 8, 14, 23, 3, 11]));
回溯法与树的遍历
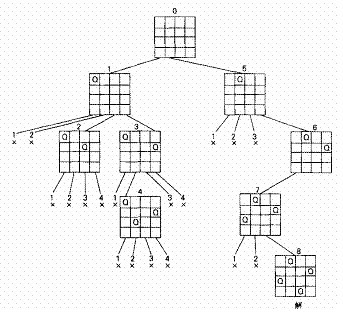
在程序设计中,有相当一类求一组解,或求全部解或求最优解的问题,例如八皇后问题等,不是根据某种确定的计算法则,而是利用试探和回溯(backtracking)的搜索技术求解。回溯法也是设计递归过程的一种重要方法,它的求解过程实质上是一个选序遍历一棵“状态树”的过程,只是这棵树不是遍历前预先建立的,而是隐含在遍历过程中。
求含n个元素的集合的幂集:
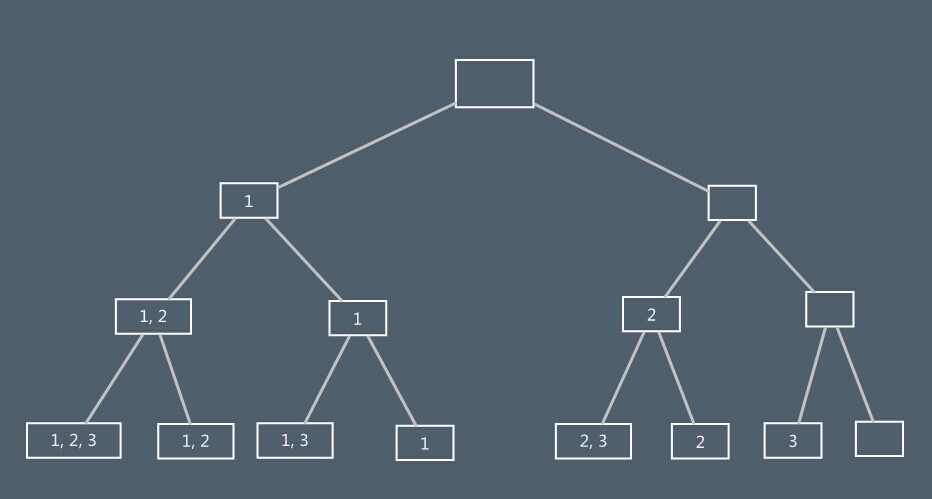
集合A的幂集是由集合A的所有子集所组成的集合。如:A = {1,2,3},则A的幂集p(A) = {{1,2,3}, {1,2}, {1,3}, {1}, {2,3}, {2}, {2}, 空集}
求幂集p(A)的元素的过程可看成是依次对集合A中元素进行“取”或“舍”的过程,并且可用一棵二叉树来表示过程中幂集元素的状态变化状况。
树中根结点表示幂集元素的初始状态(为空集);
叶子结点表示它的终结状态;
而第i(i=2,3,...,n-1)层的分支结点,则表示已对集合A中前i-1个元素进行了取/舍处理的当前状态(左分支表示“取”,右分支表示“舍”)。
如下图所示:
// 求含集合aList的幂集
// 进入函数时已对A中前i-1个元素做了取舍处理
function getPowerSet(i, aList) {
var bList = []; void function recurse(i, aList) {
if (i > aList.length - 1) console.log('set: ' + bList);
else {
var x = aList[i];
bList.push(x);
recurse(i + 1, aList);
bList.pop();
recurse(i + 1, aList);
}
}(i, aList); return bList;
} console.log('getPowerSet:');
var list = [1, 2, 3];
console.log('list: ' + getPowerSet(0, list));
求八皇后问题的所有合法布局:
同理,我们可以用回溯法解决八皇后问题。
首先,我们把问题简化为四皇后问题。
在求解过程,棋盘的状态变化就像一棵四叉树,树上每个结点表示一个局部布局或一个完整布局。根结点表示棋盘的初始状态:棋盘上无任何棋子。每个(皇后)棋子都有4个可选择的位置,但在任何时刻,棋盘的合法布局都必须满足任何两个棋子都不占据棋盘上同一行,或者同一列,或者同一对角线。
求所有合法布局的过程即为上述约束条件下先根遍历状态树的过程。
遍历中访问结点的操作为,判别棋盘上是否已得到一个完整的布局(即棋盘上是否已有4个棋子)。
若是,则输出该布局;
否则依次先根遍历满足约束条件的各棵子树,即首先判断该子树根的布局是否合法;
若合法,则先根遍历该子树;
否则剪去该子树分支。
为了通用性,我将代码实现成n皇后问题:
// 求n皇后问题的所有合法布局
function Queen(n) {
var board = [];
var count = 0; this.init = function(){
for(var i = 0; i < n; i++){
board[i] = [];
for(var j = 0; j < n; j++){
board[i][j] = 0;
}
}
}; this.init(); this.getSolutionsCount = function(){
return count;
}; this.printCurrentLayout = function () {
++count;
console.log(board);
}; this.addPoint = function (i, j) {
if(board[i][j] === 0){
board[i][j] = 1;
return true;
} else {
console.log('already occupated!');
return false;
}
}; this.isCurrentLayoutLegal = function (i, j) {
return checkHorizontal(i, j) && checkVertical(i, j) && checkLeftTop2RightBottom(i, j) && checkRightTop2LeftBottom(i, j);
}; function checkHorizontal(x, y){
for(var i = 0; i < y; i++){
if(board[x][i] === 1) return false;
}
for(i = y + 1; i < n; i++){
if(board[x][i] === 1) return false;
}
return true;
} function checkVertical(x, y){
for(var i = 0; i < x; i++){
if(board[i][y] === 1) return false;
}
for(i = x + 1; i < n; i++){
if(board[i][y] === 1) return false;
}
return true;
} function checkLeftTop2RightBottom(x, y){
for(var i = 1; x - i >= 0 && y - i >= 0; i++){
if(board[x - i][y - i] === 1) return false;
}
for(i = 1; x + i < n && y + i < n; i++){
if(board[x + i][y + i] === 1) return false;
}
return true;
} function checkRightTop2LeftBottom(x, y){
for(var i = 1; x - i >= 0 && y + i < n; i++){
if(board[x - i][y + i] === 1) return false;
}
for(i = 1; x + i < n && y - i >= 0; i++){
if(board[x + i][y - i] === 1) return false;
}
return true;
} this.removePoint = function (i, j) {
if(board[i][j] === 1){
board[i][j] = 0;
}
}; var me = this;
this.trial = function trial(i) {
i = i || 0;
if (i > n - 1) {
me.printCurrentLayout();
} else {
for (var j = 0; j < n; j++) {
if(me.addPoint(i, j)){
if (me.isCurrentLayoutLegal(i, j)) trial(i + 1);
me.removePoint(i, j);
}
}
}
};
} var test = new Queen(8);
test.trial();
console.log('getSolutionsCount: ' + test.getSolutionsCount());
javascript实现数据结构: 树和二叉树的应用--最优二叉树(赫夫曼树),回溯法与树的遍历--求集合幂集及八皇后问题的更多相关文章
- 【数据结构】赫夫曼树的实现和模拟压缩(C++)
赫夫曼(Huffman)树,由发明它的人物命名,又称最优树,是一类带权路径最短的二叉树,主要用于数据压缩传输. 赫夫曼树的构造过程相对比较简单,要理解赫夫曼数,要先了解赫夫曼编码. 对一组出现频率不同 ...
- Android版数据结构与算法(七):赫夫曼树
版权声明:本文出自汪磊的博客,未经作者允许禁止转载. 近期忙着新版本的开发,此外正在回顾C语言,大部分时间没放在数据结构与算法的整理上,所以更新有点慢了,不过既然写了就肯定尽力将这部分完全整理好分享出 ...
- 【算法】赫夫曼树(Huffman)的构建和应用(编码、译码)
参考资料 <算法(java)> — — Robert Sedgewick, Kevin Wayne <数据结构> ...
- python 回溯法 子集树模板 系列 —— 15、总结
作者:hhh5460 时间:2017年6月3日 用回溯法子集树模板解决了这么多问题,这里总结一下使用回溯法子集树模板的步骤: 1.确定元素及其状态空间(精髓) 对每一个元素,遍历它的状态空间,其它的事 ...
- Java数据结构和算法(四)赫夫曼树
Java数据结构和算法(四)赫夫曼树 数据结构与算法目录(https://www.cnblogs.com/binarylei/p/10115867.html) 赫夫曼树又称为最优二叉树,赫夫曼树的一个 ...
- C#数据结构-赫夫曼树
什么是赫夫曼树? 赫夫曼树(Huffman Tree)是指给定N个权值作为N个叶子结点,构造一棵二叉树,若该树的带权路径长度达到最小.哈夫曼树(也称为最优二叉树)是带权路径长度最短的树,权值较大的结点 ...
- 赫夫曼树JAVA实现及分析
一,介绍 1)构造赫夫曼树的算法是一个贪心算法,贪心的地方在于:总是选取当前频率(权值)最低的两个结点来进行合并,构造新结点. 2)使用最小堆来选取频率最小的节点,有助于提高算法效率,因为要选频率最低 ...
- python 回溯法 子集树模板 系列 —— 18、马踏棋盘
问题 将马放到国际象棋的8*8棋盘board上的某个方格中,马按走棋规则进行移动,走遍棋盘上的64个方格,要求每个方格进入且只进入一次,找出一种可行的方案. 分析 说明:这个图是5*5的棋盘. 图片来 ...
- python 回溯法 子集树模板 系列 —— 17、找零问题
问题 有面额10元.5元.2元.1元的硬币,数量分别为3个.5个.7个.12个.现在需要给顾客找零16元,要求硬币的个数最少,应该如何找零?或者指出该问题无解. 分析 元素--状态空间分析大法:四种面 ...
随机推荐
- jquery循环语句if-else if-else
jquery循环语句if-else if-elsecallbackFun()函数,开始是写的if-if-else.结果是不管第一个if有没有匹配到,会再次判断, 如果匹配到第二个if,则第二个if中的 ...
- gym 102082G BZOJ4240 贪心+树状数组
4240: 有趣的家庭菜园 Time Limit: 10 Sec Memory Limit: 256 MBSubmit: 756 Solved: 349[Submit][Status][Discu ...
- springboot整合activemq加入会签,自动重发机制,持久化
消费者客户端成功接收一条消息的标志是:这条消息被签收. 消费者客户端成功接收一条消息一般包括三个阶段: 1.消费者接收消息,也即从MessageConsumer的receive方法返 ...
- P4449 于神之怒加强版 (莫比乌斯反演)
[题目链接] https://www.luogu.org/problemnew/show/P4449 给定n,m,k,计算 \(\sum_{i=1}^n \sum_{j=1}^m \mathrm{gc ...
- 江西理工大学南昌校区排名赛 C: 单身狗的地图游戏
题目描述 萌樱花是一只单身狗. 萌樱花今天决定去喜欢的学妹家玩,但他不记得路,于是他拿出有n个点的完全图,选取了k条不同的路. 完全图:n 个点的图中任意两个点之间都有一条边相连,所以有 n*(n-1 ...
- HDU - 4686 函数积的前缀和
题意:求\(\sum_{i=0}^{n-1}a_ib_i\) 其中,\(a_i=A_xa_{i-1}+A_y,b_i=B_xb_{i-1}+B_y\) 构造矩阵分别维护\(a_ib_i,a_i,b_i ...
- [原创]c# 类中 Collection 字段初始化的特殊之处
1.今天看一下StackExchange.Redis的源代码,里面有这样一段代码 public sealed class ConfigurationOptions : ICloneable { ... ...
- JS判断包括IE11在内的IE浏览器
function isIE() { //ie? if (!!window.ActiveXObject || "ActiveXObject" in window) return tr ...
- PIE SDK专题制图下地图的的操作
1. 功能简介 制图模式和地图模式下用的地图是同一份地图,那么在制图模式下如果需要对地图进行操作(例如地图的拉框放大,缩小),那么该如何操作呢,地图范围视图变化在制图模式下该如何监听呢,下面主要 ...
- 详细讲解Android的网络通信(HttpUrlConnection和HttpClient)
前言,Android的网络通信的方式有两种:使用Socket或者HTTP,今天这一篇我们详细讲解使用HTTP实现的网络通信,HTTP又包括两种方式编程方式: (1)HttpUrlConnection: ...