( 转 ) 优秀REST风格 API的设计原则
设计优秀的REST风格API非常困难!API是服务提供方和使用方之间的契约,打破该契约将会给服务端开发人员招来非常大的麻烦,这些麻烦来自于使用API的开发人员,因为对API的改动会导致他们的移动app无法工作。一个好的文档对于解决这些事情能起到事半功倍的作用,但是绝对多数程序员都不喜欢写文档。
如果想让服务端的价值更好的体现出来,就要好好设计API。通过这些API,你的服务/核心程序将有可能成为其他项目所依赖的平台;目前的大公司:Facebook、Twitter、Google、Github、Amazon、Netflix等等无不依赖API,如果没有精心设计的API对外开发它们的数据,这些公司也就不会像今天这么强大。事实上,整个产业存在的目的就是消费上述平台提供的数据。
你提供的API越易用,就会有越多人愿意使用它。
如果在设计API时能遵循本文档提出的原则,那么你设计出的API就能让调用方更容易理解和使用,也能大幅减少调用方对你的抱怨;我已将文档内容按主题分别进行详细描述,读者可选择自己感兴趣的主题,而无需顺序阅读。
本文档中所使用的术语及其含义如下:
- Resource(资源):单个实例对象,例如animal(一只动物);[逍遥子笔记:Roy ThomasFielding(REST风格的提出者)如此解释资源的含义:一个资源可以是一份文档、一张图片、一个与时间相关的服务(例如:洛杉矶今天的天气)等等,资源是实体的概念性映射,而不是实体本身;个人理解:一张图片是一个资源,但是在我本机中有一个的名字叫做“jason.txt”的、实实在在的文件实体,就不能称作资源,它是资源实体,简单而言:“资源”与“资源实体”之间犹如类和对象的关系。]
- Collection(集合):集合是一组同类的实例对象,例如animals(一群动物)。
- HTTP:一种在网络上传输的通信协议;
- Consumer(使用方、用户):能够发送http请求的客户端程序;[逍遥子笔记:这里Consumer实际是指API的调用方,如果直译成消费者更让人困惑]
- Third Party Developer(第三方开发人员):不是你项目项目团队的成员,但希望使用你的服务的那些开发人员;
- Server(服务器):能够被Consumer通过网络访问的HTTP服务器/程序;
- Endpoint(端点):服务器提供的一个URL,它标识了一个资源(Resource)或者集合(Collection);[逍遥子笔记:这里理解为URL最后面的那个字段更合适,例如URL: https://api.example.com/vi/zoos的端点就是:/zoos;]
- Idempotent(幂等):多次重复操作得到的结果一样;
- URL Segment(URL片段):从某个URL中取出的一小部分片段;
数据设计和抽象
规划API的展示形式可能比你想象的要简单,首先要确定你的数据是如何设计以及核心程序是如何工作的?在新开发项目中进行API设计会比较容易,如果要对一个已经存在的项目进行修改使之符合REST风格,那么你就需要在抽象方面多下功夫了。[逍遥子笔记:按照RoyThomas Fielding对REST的设计,REST风格更适用于以数据为中心的架构,而非以计算为中心的架构]
有时,集合(Collection)可以表示数据库里的一张表,资源(Resource)表示表中的一行。[逍遥子笔记:这里的比喻感觉有些不恰当,数据库的一行对应的是一个资源实体,而非资源!]但是多数情况不是这样简单。事实上,你的API应该是对数据和业务逻辑的“尽可能的”抽象。非常重要的一点是:复杂的应用数据将会让第三方开发人员理解和使用起来非常困难,如果你这么做了,他们就不想使用你的API了。[逍遥子笔记:设计API时,参数和返回值的数据不应太复杂,否则开发人员发起调用和处理返回结果时都要处理半天,非常麻烦!]
有些情况下,服务的数据不能通过API暴露出来。一个常见的例子就是许多API都不允许第三方开发人员创建用户。[逍遥子笔记:设计API时,需要提供什么功能时就提供什么API出来,不要过早、过多暴露不必要的API接口,我们开发过程中通常会遇到这种情况:无论能否用到,先把自己服务的所有功能暴露出来再说,说不定就用上了,到时候就省得再修改了!]
动作(Verbs)
你肯定知道HTTP的GET和POST请求,这是两个通过浏览器访问各种网页时最常用的请求。术语POST甚至变成一个人们的常用语,即使不知道互联网如何工作的用户也知道能POST信息到朋友的Facebook留言板里。
你需要了解这里列出的4.5个非常重要的HTTP动作,这里的0.5个是指PATCH,因为它在功能上与PUT非常类似,剩下4个通常被API开发人员两两结合使用[逍遥子笔记:例如GET和POST,PUT和DELETE]。这里是这些动作以及它们对应的数据库调用(我认为大多开发人员更熟悉数据库操作而不是设计API)。[逍遥子笔记:正式基于作者的这个理解,所以本文的很多地方都是用数据库来解释API,其实这个也非常恰当,因为REST架构风格是基于资源的,而数据库也是资源的一种形式。下面这些解释中,括号里的内容就是与该HTTP动词类似的数据库操作]
- GET(SELECT):从服务器获取一个指定资源或一个资源集合;
- POST(CREATE):在服务器上创建一个资源;
- PUT(UPDATE):更新服务器上的一个资源,需要提供整个资源;
- PATCH(UPDATE):更新服务器上的一个资源,只提供资源中改变的那部分属性;
- DELETE(DELETE):移除服务器上的一个资源;
还有两个不常见的HTTP动作:
- HEAD – 获取一个资源的元数据,例如一组hash数据或者资源的最近一次更新时间;
- OPTIONS – 获取当前用户(Consumer)对资源的访问权限;
一个优秀的API将会充分利用这4.5个HTTP动作让第三方开发人员与自己的数据交互,并且URL中决不包含动作/动词。[逍遥子笔记:URL是对资源描述的抽象,资源的描述一定是名词,如果引入了动词,那这个URL就表示了一个动作,而非一个资源,这样就偏离了REST的设计思想]
通常,GET请求能够被浏览器缓存(而且通常都会这么做),例如,当用户发起第二次POST请求时,缓存的GET请求(依赖于缓存首部)能够加快用户的访问速度。一个HEAD请求基本上就是一个没有返回体的GET请求,因此也能被缓存。
版本控制
无论你在设计什么系统,也不管你事先做了多么详尽的计划,随着时间的推移和业务的发展,你的程序总会发生变化,数据关系也会发生变化,资源可能会被添加或者删除一些属性。只要软件还在生存期内并且还有人在用它,开发人员就得面对这些问题,对于API设计来说,尤其如此。[逍遥子笔记:根据RoyThomas Fielding对资源的解释:资源描述和资源实体是分开的,而设计REST API是基于资源描述,当资源实体发生变更时,只要修改资源描述和资源实体的映射,就能保证资源描述不变,进而保证所设计的API不变,所有使用API的第三方程序也不需要做任何修改,因此,REST风格就是用于解耦这种服务端和客户端的关系]
API是一份调用方(Consumer)和服务器之间已达成的契约,更改服务器的API必然会影响其向后兼容性,对契约的破坏将会招致使用方(Consumer)的抱怨,如果你改动很大,他们可能会放弃使用你的服务。为了确保服务器程序能够进化升级,同时能够让使用方感到满意,你需要在引入新版本API的同时继续让旧版本的API正常工作。
注意,如果你只是简单地为API增加一些新特性,例如为资源增加新属性(这些新属性并非必须的,没有它们资源也能工作),或者新增了端点,那就不需要升级API的版本号,因为这些变化并不会破坏向后的兼容性。当然,你还是需要更新API设计文档(你和调用方的契约)。[逍遥子笔记:文档对于API来说太重要了,没有好的文档必然没有好的API,因此API和它的文档一定同步修改,甚至要先修改文档]
过一段时间之后,你可以告诉调用方不建议(deprecate)使用旧版本[逍遥子笔记:就像java里面的depredated注释一样,用于告诉使用方,我不建议你使用它了,过一段时间之后我可能就不支持它了]。不建议使用一个API并不意味着马上就要关闭它或者降低它的服务质量,而是告诉你的API使用人员他们需要版本升级,旧的版本将在未来一段时间之后被停止服务。[逍遥子笔记:通过过渡期来提醒用户升级API,明确告诉调用方什么API处在过渡期,过渡期内新老版本同时都能工作,但老版本在过渡期之后就会被去掉]
在URL中加入版本号是一个优秀的API设计,当然还有另一个常用的解决办法就是把版本号放在请求首部中[逍遥子笔记:HTTP请求的accept字段],根据多年与第三方开发人员打交道的经验,我可以告诉你把版本号放在URL里要比放在请求的首部中更容易实现和使用。[逍遥子笔记:对这种方法还有一些疑问,个人理解,版本应该标识资源,也就是版本是针对URL尾部的端点,例如https://api.example.com/vi/zoos中的/zoos,按照这种思路,当一个项目包含很多类型的资源,这些资源需要要分级进行展示,此时版本号放在URL里可能遇到很多问题,例如:有个即时通信项目IM,它包含user_info(用户信息),user_rel(用户关系),message三个资源大类,其中user_info又分为公开信息public和私有信息private两个类型,public类型包括个人简介的二维码信息self_info,private类型包括个人的应用锁信息lock, user_rel(用户关系)类型包括好友关系friends和群组groups两个类型,groups包含群成员member和群信息info两个子类型资源,messge包含新聊天消息new和历史聊天消息history,这些资源组织成树状结构后如下图所示:
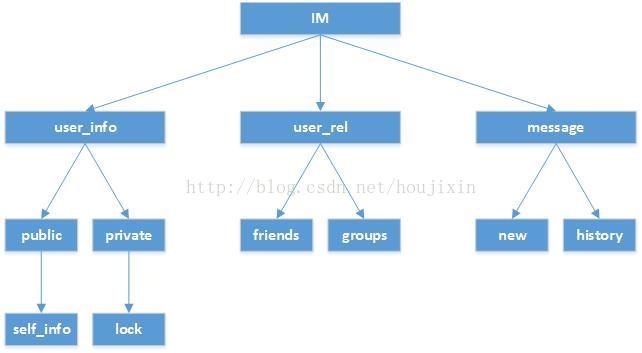
假设我的URL根(在本文后面将会介绍URL的根)为:https://test.jason.com/im/*,那么上述资源对应的URL为:
(1)https://test.jason.com/im/user_info/public/self_info
该URL表示资源:用户个人简介的二维码信息;
(2)https://test.jason.com/im/user_info/private/lock
该URL表示资源:用户的应用锁信息;
(3)https://test.jason.com/im/user_rel/friends
该URL表示资源:用户的好友信息
(4)https://test.jason.com/im/user_rel/groups/member
该URL表示资源:群组的群成员
(5)https://test.jason.com/im/user_rel/groups/info
该URL表示资源:群组的信息
(6)https://test.jason.com/im/message/new
该URL表示资源:用户新聊天消息
(7)https://test.jason.com/im/message/history
该URL表示资源:用户的历史聊天消息
问题是:在这种情况下版本号应该放在URL的那个地方?
如果版本号是针对IM整个项目,例如这里的IM项目整体分为v1和v2两个大版本,此时的URL首部就能改成:https://test.jason.com/im/v1/*,https://test.jason.com/im/v2/*,实际的URL资源将变成:https://test.jason.com/im/v1/message/new。
如果版本号是针对IM项目中的某个子类,例如这里的message类型分为v1和v2两个版本,那么消息类的URL根就会变成:https://test.jason.com/im/message/v1/*,https://test.jason.com/im/message/v2/*,实际的URL资源将会变成:https://test.jason.com/im/message/v1/new。
如果版本号针对的资源类型更详细,那么版本号就会更靠后。在一些负责类型的项目中,资源的类型也会非常复杂,层级也更深,按照本文作者建议的方法就很难确定v1的位置]
分析
跟踪各版本/端点的API被调用的情况[逍遥子笔记:由此可见版本号对应URL末尾的“端点”]。可以通过在数据库中为每个API增加一个计数器来实现,来一个请求就将对应的使用计数加1。统计各API的调用情况会带来很多好处,例如,优化调用频度最高的API。
为了构建第三方开发人员喜欢的API,最重要事情是确定何时不建议(deprecate)用户使用旧版本API,你可以使用这些不建议的(deprecated)API来告知第三方开发人员,这是在你废掉旧版本之前提醒他们的一个好途径。
通知第三方开发人员的过程可以自动化完成,例如,每调用10,000次deprecated API就给相应开发人员发一个邮件提醒。
API的根URL
无论你是否相信,API的根设计非常重要。当开发人员接手一个使用你的API所开发的旧项目,并且需要为它增加新特性的时候,他可能完全不了解你的服务,或许他们知道的就是所调用的一系列URL。重要的是你API的URL根应该尽可能简单,一个又长又复杂的URL看起来就吓人,它很可能就把这些第三方开发人员吓跑了。
这里有两个普通的URL根:
- https//example.org/api/vi/*
- https//example.com/vi/*
如果你的应用程序很庞大,或者未来它可能变得很庞大,你可以把API放在各自的子域内,这么做可以让你的程序在以后的发展中更灵活、更容易扩展。[逍遥子笔记:这里作者想表达的意思好像是把URL所表示的资源进行分类、分层级,不同的资源放在不同的类中]
如果你的程序不会变得这么大,或者你想简化程序的使用(例如,你想通过一个框架同时提供网站和API服务),就把你的API放在URL的根域(例如:/api/)之后。
最好让你API的根也包含内容。例如,访问githubAPI的根就会得到一个端点(端点代表资源)列表。我更偏好使用根URL获取那些对“正在迷茫中的”开发人员来说有用的信息,例如:怎么获取API的开发者文档。
注意使用HTTPS前缀,一个好的RESTfulAPI必须使用HTTPS作为前缀。[逍遥子笔记:例如:https://api.example.com/v1/zoos]
端点
端点是URL中用于标识一个特定资源或资源集合的那部分URL片段。[逍遥子笔记:例如:https://api.example.com/v1/zoos中的/zoos]
假如你想构建用于表示多个动物园资源的API,其中,每个动物园都包含很多动物(每个动物只能属于一个动物园),顾员(他们可以在多个动物园工作),并且需要跟踪每个动物的详细信息,那么这些API的端点可能如下所示:[逍遥子笔记:下列URL中红色加粗的后缀就是端点]
- https://api.example.com/v1/zoos
- https://api.example.com/v1/animals
- https://api.example.com/v1/animal_types
- https://api.example.com/v1/employees
在介绍这些端点的作用时,你需要给出这些端点以及操作它们的HTTP动作。例如下面给出的是刚才所构建动物园API列表的功能,注意,我在每个端点前面都加上了HTTP动作,就像HTTP请求中所使用的那样。
- GET /zoos:列出所有的动物园(包括动物园的ID、名称以及简介);
- POST /zoos: 创建一个新的动物园;
- GET /zoos/ZID:获取一个完整的动物园对象;[逍遥子笔记:这里的动物园对象仅仅指“动物园”,例如“动物园”的ID、名称、介绍等信息,而不包含该动物园中的动物、雇员等下辖类型的信息]
- PUT /zoos/ZID:更新一个动物对象(包含全部信息);
- PATCH /zoos/ZID:更新一个动物对象(包含部分信息);
- DELETE /zoos/ZID: 删除一个动物园对象;
- GET /zoos/ZID/animals:获取指定动物园的全部动物信息(包括动物的ID和名称);
- GET /animals:是指列出所有动物信息;
- POST /animals: 创建一个新的动物;
- GET /animals/AID: 获取某个动物的对象信息;
- PUT /animals/AID:更新一个动物的对象信息(提供对象的全部内容);
- PATCH /animals/AID:更新一个动物的对象信息(提供对象的部分内容);
- GET /animal_types: 获取所有的动物类型信息;
- GET /animal_types/ATID: 获取指定动物类型的类型描述信息;
- GET /employees:获取所有的雇员列表;
- GET /employees/EID:获取一个指定雇员的信息;
- GET /zoos/ZID/employees:获取指定动物园的全部雇员列表;
- POST /employees:创建一个新雇员;
- POST /zoos/ZID/employees:为指定动物园增加一个雇员;
- DELETE /zoos/ZID/employees/EID:解雇指定动物园的某个雇员;
上述列表中,ZID表示动物园的ID,AID表示动物ID,EID表示雇员ID,ATID表示动物类型ID,在文档中给出关键词及含义是一个非常好的习惯。
在上面的例子中我已简要列出常见API的URL前缀,这种简化方式(省略URL前缀)非常有利于沟通,但是在你的API文档当中,还是要使用全部的URL(例如:GET https://api.example.com/vi/animal_type/ATID)。[逍遥子笔记:在非正式文档中介绍一个API时可以采用端点代替完成URL这种方法:HTTP动作+端点+该端点的功能说明,端点要比完整URL短的多,这样更容易表述,也不影响理解,但是在正式文档中还是要把URL写全]
这里需要注意数据之间关系的展示,尤其是雇员和动物园之间的多对多的关系。你可以通过增加URL的方式来表示更多的数据关系[逍遥子笔记:根据RoyThomas Fielding对资源的解释,关系也是一种资源,因此,在遇到多对多的数据关系时,可以将数据关系进行拆分,并为每个关系都增加一个URL]。当然,这里并没有一个HTTP操作能表示解除雇员,但是我们可以通过删除指定动物园的雇员的方式来达到同样的效果。[逍遥子笔记:这是对上面“DELETE/zoos/ZID/employees/EID:解雇指定动物园的某个雇员”这个条目的解释]
过滤器
当用户请求获取一组对象列表时,你就需要对结果进行过滤并返回一组严格符合用户要求的对象。有时返回结果的数量可能非常大,但是你也不能随意对此进行约束,因为这种服务端的随意约束会造成第三方开发人员的困惑。如果用户请求了一个集合,并对返回结果进行遍历,然后只要前100个对象,那么这里就需要由用户来指明这个限制量。这样用户就不会有这样的疑惑:是他们程序的bug还是接口限制了100条?还是网络只允许传这么大的包?[逍遥子笔记:在IM项目中有个接口让用户拉取自己的历史消息,我们就需要在接口中增加一个参数让用户来确定本次要拉取多少条历史消息,服务器端根据用户传入的限制量来确定返回消息的条数,而不是由服务器来在实现时就确定该接口一次调用只能返回几条]
尽量减少对第三方开发人员的随意约束。[逍遥子笔记:不要在接口中添加默认的约束条件]
非常重要的一点:让第三方开发人员自己指定排序过滤器/返回结果集的约束条件。这么做的最重要原因是:用户能用尽量少的网络消耗尽快获取到结果;第二个重要原因是:用户可能很懒,想让服务端帮他们做好分页和过滤;还有一个对客户端不那么重要,但是对服务端很重要的原因:这么做会降低请求的资源负载。
过滤器通常用于过滤GET请求返回的资源集合,在GET请求中,可以通过URL传递过滤器信息。你可以放心把下面例子中列出的过滤器类型应用到自己的API中:
- ?limit=10:限制返回给用户的结果集的数量(通常用于分页);
- ?offset=10:给用户返回一个结果集(通常用于分页);[逍遥子笔记:指定偏移量,从指定位置开始返回结果集,与limit结合使用就可以达到分页效果,第一次从开始获取指定数量的结果,后续都要从上次结果之后开始返回]
- ?animal_type_id=1:返回符合条件的结果集(类似于数据库的WHERE查询条件:WHERE animal_type_id=1);
- ?sortby=name&order=asc:将结果集按照指定属性和指定排序方式进行排序(类似于数据的ORDER BY name ASC);
上述部分过滤器与前面介绍的某些URL端点功能重复,例如前面提到的URL:GET /zoo/ZID/animals在功能上就与使用过滤器的GET /animals?zoo_id=ZID重复。功能单一的端点对于第三方开发人员来说更容易使用,尤其是他们使用你提供的请求做一些复杂的开发时,更是如此。在API文档中明确写出这些功能重复的请求方式,将会消除第三方开发人员对这些重复功能的困惑,否则他们就会怀疑这些重复功能之间是否有差异!
还有一点,当需要对数据进行过滤或者排序时,你要给第三方开发人员(Consumer)列出哪些属性能用于过滤或排序,我们不希望把任何数据库操作的错误返回给用户。[逍遥子笔记:不要把服务内部的错误或者问题暴露给第三方开发人员]
状态码
充分利用适当的状态码对于设计REST 风格的API来说非常重要,因为HTTP状态码已有标准定义,并且各种网络设备都能读取并识别这些它们。例如,通过配置负载均衡器的参数来避免将请求发往出现50X错误的服务程序[逍遥子笔记:50X表示服务程序内部出错]。这里将列出一些可供你选择使用的HTTP状态码,它们可以成为你设计良好返回码的出发点:
- 200 OK – [GET]
客户端向服务器请求数据时,服务器找到这些数据并将之返回给客户端(此行为幂等);[逍遥子笔记:GET操作只能获取数据(即只读),不应该对服务器的数据进行任何形式的修改]
- 201 CREATED – [POST/PUT/PATCH]
客户端向服务器发送数据,服务器为这些数据创建一个资源;
- 204 NO CONTENT – [DELETE]
客户端请求服务器删除一个资源时,服务器将该资源删除;[逍遥子笔记:返回码204表示执行成功了,但是没有数据。HTTP 的RFC2616中对于204返回码的描述为:如果客户端是个代理(例如浏览器),它不应该改变“触发该请求的”页面展示,该返回值主要用于输入行为发生时,虽然新的或更新过的元数据信息被应用于当前页面,但代理(浏览器)不能改变当前的页面展示,原文为:
If the client is a user agent, itSHOULD NOT change its document view from that which caused the request to besent. This response is primarily intended to allow input for actions to takeplace without causing a change to the user agent’s active document view,although any new or updated metainformation SHOULD be applied to the documentcurrently in the user agent’s active view.]
- 400 INVALID REQUEST – [POST/PUT/PATCH]
客户端给服务器发送了一个无效的请求,服务器对此不作任何动作(此行为幂等)。
- 404 NOT FOUND – [*]
客户端请求了一个不存在的资源或资源集合,服务端对此不作任何动作(此行为幂等)。
- 500 INTERNAL SERVER ERROR – [*]
服务器内部发生了错误,客户端无法知道请求是否被执行成功了。
状态码范围
1XX的返回码预留给HTTP的底层使用,在你的整个职业生涯中都不会主动发送这种返回码;
2XX的返回码表示请求按照预期执行并成功返回了信息。服务端要尽可能给用户返回这种结果。
3XX的返回码表示请求重定向,大多数API都不会经常使用这种请求(),但是最新的超媒体API会充分使用这些功能。
4XX的返回码主要表示由客户端引起的错误,例如请求参数错误或者访问一个不存在的资源,这些必须为幂等操作,并且不能改变服务器的状态[逍遥子笔记:其实服务器的状态发生了改变就意味着操作不是幂等了]。
5XX的返回码主要表示由服务器引起的错误,通常情况下,这些错误都是开发人员([逍遥子笔记:这里应该是服务器程序的开发人员])接触不到的底层函数抛出来,然后传递给用户([逍遥子笔记:这里应该是第三方开发人员])的。用户在收到5XX的返回码时,他们不知道服务器当前的工作状态是否正常,因此,要尽量避免这种情况发生。
返回值文档
当第三方开发人员在发送HTTP请求时,他们需要事先了解这些请求的返回值信息,下述列表就是一些REST风格API以及它们对应的返回值信息:[逍遥子笔记:与前面的介绍URL的功能类似,只是这里将最后面的URL描述换成返回值描述,这里依然采用三段式描述法:HTTP请求动作+端点+端点对应的返回值描述信息]
- GET /collection:返回一个资源对象的列表;
- GET /collection/resource: 返回一个资源对象;
- POST /collection:返回新创建的资源对象
- PUT /collection/resource:返回一个完整的资源对象;
- PATCH /collection/resource:返回一个完整的资源对象;[逍遥子笔记:虽然请求中只带了部分资源对象的内容,但是返回的内容却是整个资源对象]
- DELETE /collection/resource:返回一个空文档;
需要注意的是:当用户创建一个资源时,他们通常并不想知道新创建资源的ID(也不想知道其他属性,例如修改或创建的时间戳)[逍遥子笔记:这一点略有疑惑,这种设计思路应该也是区分场合的,如果资源很复杂,本文介绍的这种思路或许可行,如果资源原本就很简单,例如我们以前设计的发送消息接口,就直接给用户返回所发送消息的ID]。这些新增的属性信息可通过后续请求获得,当然也可以通过初始化POST请求来返回。
授权
多数情况下,服务器想确切知道每个请求的发起方是谁?当然,部分API接口能放开被用匿名访问,但通常接口只能被授权的用户访问。
OAuth2.0为此提供了一个很好的实现途径。你能知道每个请求是由哪个客户端发起?这些请求背后分别代表了哪些用户?以及提供一种标准化的用户访问或撤销访问方式,所有这些都无需第三方用户的登录授信。
还有OAuth1.0和xAuth也能完成类似功能。无论采用那种方法,一定要确保通用性以和良好的文档设计,在文档中对用户常用语言/平台的各种不同封装库进行详细说明。[逍遥子笔记:这些服务以库的方式供客户端调用,例如SDK,因此在文档中要对各种形式的封装库进行详细说明]
我可以如实地告诉你,尽管OAuth1.0a虽然是最安全的选项,但是它非常难以部署。我遇到很多第三方开发人员抱怨他们不得不实现自己的库,因为OAuth1.0a没有他们所使用语言对应的库。我花费了大量的时间用于解决那些难以理解的“invalid signature”错误。因此,我建议你使用其他的替代方案。
内容类型
目前,大多数REST风格API接口都提供JSON格式的数据,你所能想起来的Facebook、Twitter、GitHub都是如此。XML方式已经逐渐退出人们的视野(除了一些大公司内部还在使用之外),幸亏SOAP方式已经消失,我们已经看不到返回HTML格式数据的API接口了。
开发者常用的开发语言或框架都能轻易解析你返回的各种有效数据。如果你正在使用不同的序列化器构建一个通用的返回对象,你可以使用前面提到的任意数据格式(SOAP除外),不过在返回数据时需要注意处理请求首部的Accept字段。[逍遥子笔记:HTTP请求头部的Accept可用于指定返回数据的格式]
一些API开发人员建议针对不同返回内容的类型,为URL(在端点之后)添加扩展字段,例如:.json,.xml,或者.html,但我不建议这么做,我建议使用HTTP请求首部的Accept字段(HTTP的RFC文档中有对Accept的解释),并且觉得这才是合适的方法。
超媒体API
超媒体API可能代表REST风格API的未来发展,它们在思想上更符合HTTP和HTML的设计初衷。[逍遥子笔记:根据REST作者Roy Thomas Fielding的描述,REST核心是面向资源的设计,超媒体服务所提供了各种多媒体资源的访问,它在本质上符合了以资源为中心的设计]
在使用非超媒体的REST风格API时,URL端点也是客户端和服务器之间契约的一部分,这些端点必须事先告知客户端,一旦改变它们,客户端就无法按预期与服务器进行交互,这其实也是一种约束。
现在,API的用户不仅仅是能发起HTTP请求的用户代理,人们更常用浏览器发起HTTP请求。然而,用户不会被这些预先定义的、REST风格API的URL端点所约束。是什么让用户变得如此特殊呢?现在的网页能让用户先读主题,然后点击他们感兴趣的主题所对应的链接,访问他们想访问的网站或者想阅读的内容,此时URL发生变化的时候,用户不受影响(除非用户为某个网页打了标签,在他们访问这些打了标签的网页时会自动跳转到主页,用户需要再从主页中寻找他们所感兴趣数据的新路径)。[逍遥子笔记:我们的网站通常采用这种方式,尤其是各种门户网站,例如网易:www.163.com,新浪:www.sina.com,打开这些门户网站,我们看不到一个URL,我们所看到的都是一个个的主题,每个主题对应一个超链接(URL),当这些主题对应的URL发生变化时,只需要调整主题和超链接(URL)的映射关系即可,用户实际上看不到这些URL的变化]
超媒体API概念和一个普通人的行为类似。请求API的根目录将会获得一个URL列表,这些URL列表的每一项都可能对应了一个信息集,并且它以用户能够理解的方式来描述这些信息集合。无需为每个资源提供ID(除非特别邀请),因为一个URL就唯一标识了一个资源。
超媒体API用户在访问连接并且收集信息时,返回结果中将被放入最近更新的URL链接,因此URL无需事先与用户约定。如果URL被缓存了,后续请求又返回了404[逍遥子笔记:404表示请求了一个不存在的资源],用户只需简单地回到根目录重新寻找内容即可。
当从集合中检索一个资源列表时,要给用户返回这个资源列表的完整URL。当执行POST/PATCH/PUT请求时,可用返回码为3XX的响应来重定向到新的资源。
JSON即无法给我们提供需要的语义来指明哪些属性是URL,也不能说明URL怎样与当前的文档关联起来;可能正如你猜测的那样,HTML可以提供这样的信息。我们可以先通过API拿到数据,然后再进行HTML处理。想想CSS陪伴我们走过的这些路,我们可能有一天会看到:在获取同样URL和内容的时候,无论通过API请求还是网站访问,都采用同一种处理方式。[逍遥子笔记:JSON提供数据内容,并未提供数据展示功能]
文档
老实说,如果没有完全按照本文档的指导,你的API也不一定会太差,然而,如果你没有为API编写合适的文档,没有人会愿意用它,它将变为一个极难使用的API。
确保你的文档无需授权便可被开发人员访问。
不要使用自动文档生成器,如果用了,就一定要仔细检查和修改生成的文档,确保它们能够被用户理解和使用。
文档中所举例子中的请求和响应包体要写全,不要截断不重要的部分,而是用高亮方式展示重要的部分。
文档中要写明各URL端点的预期返回码和可能的出错信息,以及出现这些错误信息的可能原因是什么?
如果时间充足,你还可以构建一个第三方开发人员使用的API控制台,以便他们可以立即对你的API进行验证。这个事情做起来不会像你想象的那么难,但是开发人员(包括内部开发人员和第三方开发人员)却可能因为这个功能而喜欢上使用你的API。
确保文档能被打印,例如,CSS就是一种强大的文档展示方式;在文档打印的时候一定要隐藏文档的工具栏,即便没有人把你的文档用打印机打印出来,也会有很多开发人员喜欢把它们输出为PDF以便离线查看。
原贴 : https://blog.csdn.net/houjixin/article/details/54315835
( 转 ) 优秀REST风格 API的设计原则的更多相关文章
- 好RESTful API的设计原则
说在前面,这篇文章是无意中发现的,因为感觉写的很好,所以翻译了一下.由于英文水平有限,难免有出错的地方,请看官理解一下.翻译和校正文章花了我大约2周的业余时间,如有人愿意转载请注明出处,谢谢^_^ P ...
- RESTful API的设计原则
好RESTful API的设计原则 说在前面,这篇文章是无意中发现的,因为感觉写的很好,所以翻译了一下.由于英文水平有限,难免有出错的地方,请看官理解一下.翻译和校正文章花了我大约2周的业余时间, ...
- 好的RESTful API的设计原则
转载自一位大佬 英文原版 Principles of good RESTful API Design Good API design is hard! An API represents a cont ...
- 优秀的API接口设计原则及方法(转)
一旦API发生变化,就可能对相关的调用者带来巨大的代价,用户需要排查所有调用的代码,需要调整所有与之相关的部分,这些工作对他们来说都是额外的.如果辛辛苦苦完成这些以后,还发现了相关的bug,那对用户的 ...
- RESTful Web Services中API的设计原则(转)
当下前后端分离的设计已经是web app开发的标配,但是如何设计一个强壮,扩展性好,又规范的API呢 参考以下link,可以得到需要有益的启示.同时个人推荐一本书<web API的设计和开发&g ...
- API通用设计原则
什么是好的API? · 完备(Be Complete) 对确定重点支持的用户场景具有完备的功能支持.就是说,用户通过对一组API的调用能够完成预期的功能. · 不冗余(Be ...
- [Medium翻译]RESTful API权威设计指南-设计更好的API
本文为授权译文.希望查看原文的同学请戳链接:https://hackernoon.com/restful-api-design-step-by-step-guide-2f2c9f9fcdbf 对于我们 ...
- 基于MVC的RESTFul风格API实战
基于MVC的RESTful风格的实现 1.RESTful风格阐述 REST服务是一种ROA(Resource-Oriented Architecture,面向资源的架构)应用.主要特点是方法信息存在于 ...
- javascript的api设计原则
前言 本篇博文来自一次公司内部的前端分享,从多个方面讨论了在设计接口时遵循的原则,总共包含了七个大块.系卤煮自己总结的一些经验和教训.本篇博文同时也参考了其他一些文章,相关地址会在后面贴出来.很难做到 ...
随机推荐
- [Leetcode] subsets ii 求数组所有的子集
Given a collection of integers that might contain duplicates, S, return all possible subsets. Note: ...
- How to reclaim space in InnoDB when innodb_file_per_table is ON
When innodb_file_per_table is OFF and all data is going to be stored in ibdata files. If you drop so ...
- Consumer [分组背包]
Consumer Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 32768/65536 K (Java/Others) Total Subm ...
- Codeforces Round #526 (Div. 2) A.B
A. The Fair Nut and Elevator 题目链接:https://codeforces.com/contest/1084/problem/A 题意: 一栋房子有n层楼,同时有个电梯( ...
- 如何快速的进行sql脚本升级
sql脚本升级即从一个老的脚本升级到一个新的全量的脚本.比如公司有某一个项目,有的客户已经用这个项目了,数据库里面去掉以前的初始化数据外,现在还有了客户自己的数据.但是这个版本中有严重的bug,所以为 ...
- Phantomjs设置浏览器useragent的方式
Selenium中使用PhantomJS,设置User-Agent的方法. 默认情况下,是没有自动设置User-Agent的:设置PhantomJS的user-agent def __init__(s ...
- 马上给Meltdown和Spectre漏洞打补丁
元旦之后的第一个工作日可谓是惊喜不断,4号就传来了 Google Project Zero 等团队和个人报告的 Meltdown 和 Spectre 内核漏洞的消息,首先简单介绍一下这两个内核漏洞. ...
- java属性为什么没多态,而是方法多态
定义 java多肽的特性:方法具有多态性,属性却没有. 准备 基类: 子类: 测试类: 结果: 分析如下 父类 a=new 子类,实际对象时子类.由于向上转型,我们可以用父类在编译期间代替子类,使得编 ...
- Linux : 从私钥中提取公钥
已知一个私钥, 如何从其中提取公钥出来? 提取公钥 ssh-keygen -y -f /path/to/private_key > /path/to/public_key
- 【洛谷 P2346】四子连棋(状态压缩,搜索)
其实这题可以直接二进制状压做,1表示黑棋,0表示白棋,另外记录下2个空点的位置就行了. 具体看代码(冗长): #include <iostream> #include <cstdio ...