[转载]基于Redis的Bloomfilter去重(附Python代码)
前言:
“去重”是日常工作中会经常用到的一项技能,在爬虫领域更是常用,并且规模一般都比较大。去重需要考虑两个点:去重的数据量、去重速度。为了保持较快的去重速度,一般选择在内存中进行去重。
- 数据量不大时,可以直接放在内存里面进行去重,例如python可以使用set()进行去重。
- 当去重数据需要持久化时可以使用redis的set数据结构。
- 当数据量再大一点时,可以用不同的加密算法先将长字符串压缩成 16/32/40 个字符,再使用上面两种方法去重;
- 当数据量达到亿(甚至十亿、百亿)数量级时,内存有限,必须用“位”来去重,才能够满足需求。Bloomfilter就是将去重对象映射到几个内存“位”,通过几个位的 0/1值来判断一个对象是否已经存在。
- 然而Bloomfilter运行在一台机器的内存上,不方便持久化(机器down掉就什么都没啦),也不方便分布式爬虫的统一去重。如果可以在Redis上申请内存进行Bloomfilter,以上两个问题就都能解决了。
本文即是用Python,基于Redis实现Bloomfilter去重。下面先放代码,最后附上说明。
代码:
# encoding=utf-8
import redis
from hashlib import md5
class SimpleHash(object):
def __init__(self, cap, seed):
self.cap = cap
self.seed = seed
def hash(self, value):
ret = 0
for i in range(len(value)):
ret += self.seed * ret + ord(value[i])
return (self.cap - 1) & ret
class BloomFilter(object):
def __init__(self, host='localhost', port=6379, db=0, blockNum=1, key='bloomfilter'):
"""
:param host: the host of Redis
:param port: the port of Redis
:param db: witch db in Redis
:param blockNum: one blockNum for about 90,000,000; if you have more strings for filtering, increase it.
:param key: the key's name in Redis
"""
self.server = redis.Redis(host=host, port=port, db=db)
self.bit_size = 1 << 31 # Redis的String类型最大容量为512M,现使用256M
self.seeds = [5, 7, 11, 13, 31, 37, 61]
self.key = key
self.blockNum = blockNum
self.hashfunc = []
for seed in self.seeds:
self.hashfunc.append(SimpleHash(self.bit_size, seed))
def isContains(self, str_input):
if not str_input:
return False
m5 = md5()
m5.update(str_input)
str_input = m5.hexdigest()
ret = True
name = self.key + str(int(str_input[0:2], 16) % self.blockNum)
for f in self.hashfunc:
loc = f.hash(str_input)
ret = ret & self.server.getbit(name, loc)
return ret
def insert(self, str_input):
m5 = md5()
m5.update(str_input)
str_input = m5.hexdigest()
name = self.key + str(int(str_input[0:2], 16) % self.blockNum)
for f in self.hashfunc:
loc = f.hash(str_input)
self.server.setbit(name, loc, 1)
if __name__ == '__main__':
""" 第一次运行时会显示 not exists!,之后再运行会显示 exists! """
bf = BloomFilter()
if bf.isContains('http://www.baidu.com'): # 判断字符串是否存在
print 'exists!'
else:
print 'not exists!'
bf.insert('http://www.baidu.com')
说明:
- Bloomfilter算法如何使用位去重,这个百度上有很多解释。简单点说就是有几个seeds,现在申请一段内存空间,一个seed可以和字符串哈希映射到这段内存上的一个位,几个位都为1即表示该字符串已经存在。插入的时候也是,将映射出的几个位都置为1。
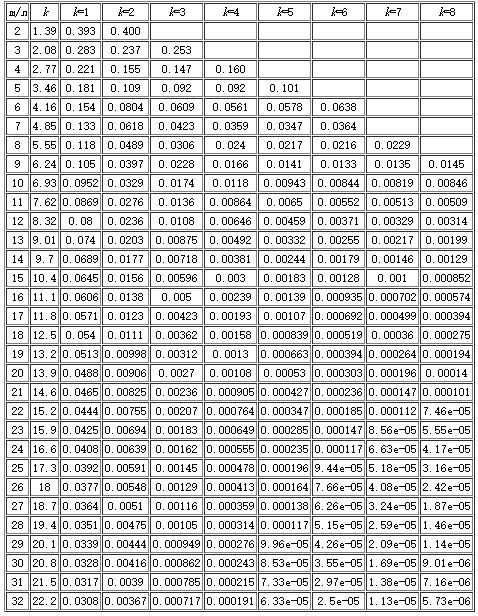
- 需要提醒一下的是Bloomfilter算法会有漏失概率,即不存在的字符串有一定概率被误判为已经存在。这个概率的大小与seeds的数量、申请的内存大小、去重对象的数量有关。下面有一张表,m表示内存大小(多少个位),n表示去重对象的数量,k表示seed的个数。例如我代码中申请了256M,即1<<31(m=2^31,约21.5亿),seed设置了7个。看k=7那一列,当漏失率为8.56e-05时,m/n值为23。所以n = 21.5/23 = 0.93(亿),表示漏失概率为8.56e-05时,256M内存可满足0.93亿条字符串的去重。同理当漏失率为0.000112时,256M内存可满足0.98亿条字符串的去重。
- 基于Redis的Bloomfilter去重,其实就是利用了Redis的String数据结构,但Redis一个String最大只能512M,所以如果去重的数据量大,需要申请多个去重块(代码中blockNum即表示去重块的数量)。
- 代码中使用了MD5加密压缩,将字符串压缩到了32个字符(也可用hashlib.sha1()压缩成40个字符)。它有两个作用,一是Bloomfilter对一个很长的字符串哈希映射的时候会出错,经常误判为已存在,压缩后就不再有这个问题;二是压缩后的字符为 0~f 共16中可能,我截取了前两个字符,再根据blockNum将字符串指定到不同的去重块进行去重。
总结:
基于Redis的Bloomfilter去重,既用上了Bloomfilter的海量去重能力,又用上了Redis的可持久化能力,基于Redis也方便分布式机器的去重。在使用的过程中,要预算好待去重的数据量,则根据上面的表,适当地调整seed的数量和blockNum数量(seed越少肯定去重速度越快,但漏失率越大)。
另外针对基于Scrapy+Redis框架的爬虫,我使用Bloomfilter作了一些优化,只需替换scrapy_redis模块即可使用Bloomfilter去重,并且去重队列和种子队列可以拆分到不同的机器上,详情见:《scrapy_redis去重优化(已有7亿条数据),附Demo福利》,代码见:Scrapy_Redis_Bloomfilter。
原文链接:http://blog.csdn.net/bone_ace/article/details/53107018)
关于setbit:https://blog.csdn.net/hgd613/article/details/54095729
[转载]基于Redis的Bloomfilter去重(附Python代码)的更多相关文章
- 基于Redis的Bloomfilter去重(转载)
转载:http://blog.csdn.net/bone_ace/article/details/53107018 前言 “去重”是日常工作中会经常用到的一项技能,在爬虫领域更是常用,并且规模一般都比 ...
- XGBoost参数调优完全指南(附Python代码)
XGBoost参数调优完全指南(附Python代码):http://www.2cto.com/kf/201607/528771.html https://www.zhihu.com/question/ ...
- 基于Redis的BloomFilter算法去重
BloomFilter算法及其适用场景 BloomFilter是利用类似位图或者位集合数据结构来存储数据,利用位数组来简洁的表示一个集合,并且能够快速的判断一个元素是不是已经存在于这个集合.因为基于H ...
- [转载] 基于Redis实现分布式消息队列
转载自http://www.linuxidc.com/Linux/2015-05/117661.htm 1.为什么需要消息队列?当系统中出现“生产“和“消费“的速度或稳定性等因素不一致的时候,就需要消 ...
- 转载 基于JAVA每月运势api调用代码实例
代码描述:基于JAVA每月运势api调用代码实例 接口地址:http://www.juhe.cn/docs/api/id/58 原文链接:http://outofmemory.cn/code-snip ...
- 机器学习/逻辑回归(logistic regression)/--附python代码
个人分类: 机器学习 本文为吴恩达<机器学习>课程的读书笔记,并用python实现. 前一篇讲了线性回归,这一篇讲逻辑回归,有了上一篇的基础,这一篇的内容会显得比较简单. 逻辑回归(log ...
- 【路径规划】 Optimal Trajectory Generation for Dynamic Street Scenarios in a Frenet Frame (附python代码实例)
参考与前言 2010年,论文 Optimal Trajectory Generation for Dynamic Street Scenarios in a Frenet Frame 地址:https ...
- 光照问题之常见算法比较(附Python代码)
一.灰度世界算法 ① 算法原理 灰度世界算法以灰度世界假设为基础,该假设认为:对于一幅有着大量色彩变化的图像,R,G,B三个分量的平均值趋于同一灰度值Gray.从物理意义上讲,灰色世界法假设自然界景物 ...
- 【转】XGBoost参数调优完全指南(附Python代码)
xgboost入门非常经典的材料,虽然读起来比较吃力,但是会有很大的帮助: 英文原文链接:https://www.analyticsvidhya.com/blog/2016/03/complete-g ...
随机推荐
- vs code 代码格式化整理
vs code格式化代码的快捷键如下:(来源于这里) On Windows Shift + Alt + F On Mac Shift + Option + F On Ubuntu Ctrl + Shi ...
- Activiti工作流(一)——Activiti Diagram
工作流解决在多个参与者之间按照某种预定义的规则传递文档.信息或任务的过程自动进行,从而实现某个预期的业务目标,或者促使此目标的实现. 使用Eclipse开发,需要安排工作流插件,详情见下面. Name ...
- linux系统基础文件属性
记录用户登录前显示的信息 cat /etc/issue vim /etc/motd 设置登录提醒 隐藏执行命令的历史记录用history –d 加上历史记录行号 如history -d 38 ...
- capacilitys docker中的权限设置 privileged
capacilities是docker 中对docker权限设置的重要方面: http://blog.csdn.net/wangpengqi/article/details/9821227 上面这篇文 ...
- 一张图彻底搞懂JavaScript的==运算
一张图彻底搞懂JavaScript的==运算 来源 https://zhuanlan.zhihu.com/p/21650547 PS:最后,把图改了一下,仅供娱乐 : ) 大家知道,==是JavaSc ...
- [bzoj3886] [USACO15JAN]电影移动Moovie Mooving
题目链接 状压\(dp\). 注意到\(n\leq 20\)且每个只能用一次,所以很显然可以压缩每部电影看过没,记\(f[sta]\)为状态为\(sta\)时最多可以看多久. 转移时先枚举状态,然后枚 ...
- [Leetcode] subsets 求数组所有的子集
Given a set of distinct integers, S, return all possible subsets. Note: Elements in a subset must be ...
- 洛谷 P2218 [HAOI2007]覆盖问题 解题报告
P2218 [HAOI2007]覆盖问题 题目描述 某人在山上种了\(N\)棵小树苗.冬天来了,温度急速下降,小树苗脆弱得不堪一击,于是树主人想用一些塑料薄膜把这些小树遮盖起来,经过一番长久的思考,他 ...
- bootstrap和bootstrap-select去除蓝色边框outline
/*bootstrap outline设置*/ .btn:focus, .btn:active:focus, .btn.active:focus, .btn.focus, .btn:active.fo ...
- sqlplus 几个命令:
sqlplus 几个命令: 在sys,system,sysman,scott四个用户权限中,scott用户最低. 其权限依次从高到低. cmd进入sqlplus sqlplus 登录命令: 登录sys ...