分布式服务框架 Zookeeper(四)官方编程指南
握草,是不是加了官方两个字就可以唬人了。
使用ZooKeeper开发分布式应用
简介
这篇文档是为了那些想利用ZooKeeper的协调服务来构建分布式应用的开发人员而写滴,不相干的走一边去哈。在这儿有概念的介绍也有编程实例。
本指南的前四个部分从较高层次讨论了ZooKeeper几个不同的概念。熟悉这个几个概念对于理解ZooKeeper是如何工作的以及如何用好ZooKeeper是十分必要的。这里并没有包含源代码,而是假设读者熟悉分布式计算的问题。第一组包含了如下的几个部分:
ZooKeeper数据模型
ZooKeeper会话
ZooKeeper监视
一致性保证
下面的四个部分则提供了实际的编程信息。它们分别是:
构建块:ZooKeeper操作指南
绑定
简单例子的编程框架
Gotchas:共同问题以及定位问题
本指南的末尾附有包括其他有用的和ZooKeeper相关信息的链接。
这篇文档大部分的信息可以在单机版的参考资料中找到。然而,在开始你的第一个ZooKeeper应用之前,你至少应该要读一下ZooKeeper数据模型以及ZooKeeper基本操作这两章。同样的简单编程实例对于理解ZooKeeper客户端应用也是十分有帮助的。
ZooKeeper数据模型
ZooKeeper有一个层级的命名空间,很像一个分布式的文件系统。唯一的不同之处在于在在命名空间中的每个节点都可以有和它相关的数据以及子节点。就像让文件系统中的文件也可以是目录一样。每个节点的路径总是表示为canonical,absolute,以斜线分隔的路径;这里没有相对参考。任何unicode编码的字符都可以用在路径中,但是要满足一下的约束:
null字符(\u0000)不能出现在路径名中。(这会导致和C绑定时出问题。)
以下的字符也不能使用因为它们不能很好地显示,或者为在路径中造成误解:\u0001 – \u0019以及\u007F – \u009F。
以下的字符也不允许:\ud800 – uF8FFF,\uFFF0 - uFFFF。
"."字符可以用于另一个名字中的一部分,但是"."和".."不能单独用于一个路径上的节点,因为ZooKeeper并不使用相对路径。以下的路径都是有效的:"/a/b/./c"或者"/a/b/../c"。
"zookeeper"这个是保留的,谁用我跟谁急。
Znodes
在ZooKeeper树中的每个节点我们用znode来表示。znode为了一个stat structure,其中包含了数据改变以及acl改变的版本号。stat structure同时也有时间戳。版本号以及时间戳允许ZooKeeper验证缓存以及协调更新。每次znode的数据改变时,版本号就会增加。例如,不论什么时候客户端接受数据,它也会接收数据的版本号。当一个客户端执行更新或者删除操作时,它必须提供正在修改的znode的版本号。如果它提供的版本号和数据的实际版本号不匹配,那么更新就会失败。(这种行为可以被重写。更多个信息请见......)
注意
在分布式应用中,node这个词通常指一般的主机,服务器,某个组中的一个成员或者一个客户端的进程等等。在ZooKeeper文档中,znodes指的是数据节点。服务器指的是组成ZooKeeper服务的机器;quorum peers指的是组成一个组的服务器;客户端指的是任何使用ZooKeeper服务的主机或者进程。
znode是程序员需要清楚的一个主要抽象。在这里znode有几个特性需要注意一下。
监视(Watches)
客户端可以对znode设置监视。对znode的修改将会触发监视,然后清除监视。当监视触发的时候,ZooKeeper会对客户端发送一个通知。更多关于监视(watches)的信息可以在ZooKeeper Watches中找到。
数据访问(Data Access)
命名空间中每个znode数据的读和写都是原子性的。读操作会获取和一个znode相关的所有的数据,而写操作则会用新的数据替换掉所有的旧数据。每个节点都有一个访问控制列表(ACL)来限制用户可以做什么。
ZooKeeper并不是设计用作一般的数据库或者存储大型的对象。而只是用于管理协调数据。这种数据以配置文件,状态信息,冗余等形式存在。这些不同形式的协调数据有一个共同的属性就是它们都相当小:以kb来计算。ZooKeeper的客户端和服务器的实现都会有sanity检查来确保znode的数据小于1M,但是每个文件平均下来要小得多。在相对较大的数据上进行操作花的时间将会比其他操作花的时间要长得多,因为需要花更多的时间进行网络传输以及存储到媒介上而使得延迟更多。如果需要存储更大的数据的话,通常采用的模式是将这些数据存储在块存储系统中,比如NFS或者HDFS,然后只是把指向这些存储位置的指针存放到ZooKeeper中。
临时节点(Ephemeral Nodes)
ZooKeeper也有所谓的临时节点。这些znodes只要在创建这些节点的会话存在,那么这些节点也会存在。当会话结束的时候,这些临时节点也会被删除。由于临时节点的这种特性使得临时节点不允许有子节点。
序列节点 -- 唯一命名
创建了一个节点之后,你可以请求ZooKeeper追加一个单调递增的计数器到路径的结尾。这个计数器对父辈的znode是唯一的。这个计数器的形式是 %01d - 也就是10位,前面的用0来填充(这个计数器这样的格式是为了简化排序),"<path>0000000001"。可以参考Queue Recipe来看这个特性的例子。注意:这个计数器可以用来存储父节点维护的有符号整数的一下个序列号,当计数器增长超过了21474833647(然后生成一个名字为"<path>-2147483647")。
ZooKeeper中的时间
ZooKeeper中有很多种方式来记录时间:
zxid
每次对ZooKeeper的状态进行修改都会收到一个zxid(ZooKeeper事物ID)的戳。这里可以看到所有对ZooKeeper进行修改的顺序。每次修改都会有一个唯一的zxid,如果zxid1比zxid2小的话,那么zxid1发生的时间要早于zxid2。
版本号(Version numbers)
每次对一个节点的修改都会导致该节点的版本号增加。这里有三个不同的版本号,分别是,znode数据的版本号,对znode子节点修改的版本号,以及一个znode的ACL修改的版本号。
嘀嗒(Ticks)
当使用多个ZooKeeper服务器的时候,服务器之间使用ticks来定义时间的计时,比如状态的上传,会话的超时,以及peers之间的连接超时等。tick时间仅仅通过最小会话超时间接表现的(tick时间的2倍);如果一个客户端请求的会话超时要小于最小的会话超时时间,那么服务器将会告诉客户端会话超时时间实际上是最小的会话超时时间。
真实时间(Real Time)
ZooKeeper并不使用真实的时间,或者时钟时间,除了给znode创建或者znode修改时对状态结构加时间戳。
ZooKeeper的状态结构
在ZooKeeper中每个节点的状态结构由以下几个字段组成:
czxid
使得znode被创建的改变的zxid。
mzxid
对znode最后修改的zxid。
pzxid
对znode的子节点最后修改的zxid。
ctime
当znode被创建时从epoch返回的以millisecond计的时间。
mtime
当znode最后修改的时候从epoch返回的以millisecond计的时间。
version
对znode的数据进行修改的版本号。
cversion
对znode的子节点进行修改的版本。
aversion
对znode的ACL进行修改的版本号。
ephemeralOwner
如果znode是一个临时节点的话,则表示的是该节点拥有者的会话id。如果它不是临时节点的话,那么它就是0了。
dataLength
znode的数据域的长度。
numChildren
znode的子节点个数。
ZooKeeper的会话
一个ZooKeeper客户端通过使用语言绑定的方法创建一个到服务的句柄,来建立与ZooKeeper服务器的会话。一旦会话被创建,句柄开始是一个CONNECTING状态,然后客户端的库开始尝试连接到组成ZooKeeper服务器的一台主机上,然后就变为了CONNECTED的状态。在正常操作的时候会是这两个状态中的一个。如果发生了一个不可恢复的错误,比如会话过期或者认证失败,或者是应用显式地关闭了句柄将会转移到CLOSED状态。下图描述了一个ZooKeeper可能的状态转移图。
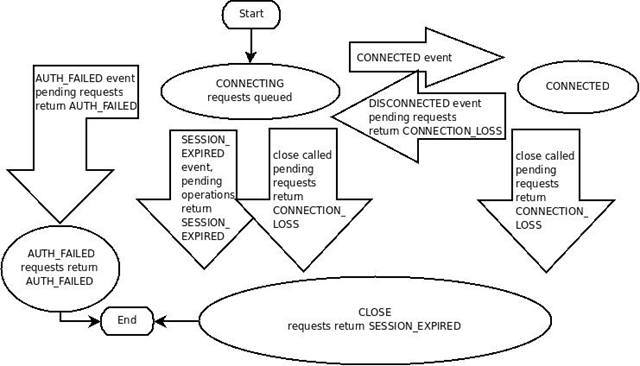
想吐槽一下,这是我见过的最丑的官方图片。
为了创建一个客户端会话,应用代码中必须提供一个连接字符串,这个字符串包括了一个用逗号分隔的主机:端口对,每个都对应了一个ZooKeeper服务器(例如,"127.0.0.1:4545"或者"127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002")。ZooKeeper客户端库将会挑选一个任意的主机并且尝试连接它。如果连接失败了,或者如果客户端因为任何原因导致客户端的连接断开了,客户端将会自动尝试列表中的下一个主机,直到连接重新建立为止。
在3.2.0中加入的:一个可选的"chroot"后缀也可以被加入到连接字符串中。这将运行客户端的命令同时解释所有和这个root的所有的相对路径(类似于unix的chroot命令)。如果用例子说明的话可能就想这样的:"127.0.0.1:4545/app/a"或者"127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002/app/a",其中客户端将会 以"/app/a"为根节点,并且所有的路径都会相对于这个根节点 —— 也就是说获得/setting/src..."/foo/bar"将会使操作运行在"/app/a/foo/bar"上(从服务器的视角来看)。这种特性在多个tenant环境下特别有用,其中每个ZooKeeper服务器的根节点都不一样。这样可用达到更简单的重用因为每个用户可以都可以编码它的应用就像它们的根节点都是"/"一样,但实际上的位置(比如/app/a)可以在部署的时候决定。
当一个客户端获得了一个ZooKeeper服务器的句柄之后,ZooKeeper会创建一个ZooKeeper会话,用一个64位的数字来表示,并将它分配给这个客户端。如果这个客户端连接到了一个不同的服务器,将会把这个session id连同连接握手信息一起发送。作为一个安全措施,服务器会为这个seesion id创建一个密码,任意一个ZooKeeper服务器都可以来验证。这个密码会在客户端建立会话的时候连同会话id一起发送给客户端。客户端无论在什么时候和一个新的服务器建立连接都会把密码和会话ID一起发过去。
ZooKeeper客户端库调用创建一个ZooKeeper会话需要传递的参数是以millisecond为单位的会话超时时间。客户端发送一个请求的端超时时间,服务器会响应一个超时时间给客户端。当前的实现要求超时时间最少是tick时间的2倍(就像在服务器配置中的那样),最大是20个tick时间。ZooKeeper客户端API允许访问协商的超时时间。
当一个客户端(会话)在ZK服务集群中被分区之后,它开始搜索在会话创建时指定的服务器列表。最终,当客户端最少和其中一个服务器建立连接之后,会话将要么重新变成"connected"状态(如果在会话超时时间内重新连接上)或者它会变成"expired"状态(如果在会话超时之后重新连接)。不建议创建一个新的会话对象(一个新的ZooKeeper.class或者C语言的ZooKeeper句柄)来断开连接。ZK客户端将会为你处理重连。我们还特别地在客户端代码中设计了启发式规则来处理诸如"herd effect"之类的情况等。当你在被告知会话过期(mandatory)之后再来创建一个新的会话。
会话超时由ZooKeeper集群自己管理,而不是由客户端。当ZooKeeper的客户端和集群建立一个连接之后它会提供一个在之前已经详细说明的"超时时间"。集群会使用这个值来判断客户端什么时候过期。当集群在指定的会话超时时间之内没有再收到从客户端发送的信息(比如心跳)就会发生超时。在会话超时后集群将会删除所有由该超时会话所创建的临时节点并立即通知通知所有连接的客户端这种改变(任何对这些节点添加了监视的)。在这个时候,会话过期的客户端仍然是和集群断开连接的,它将不会收到会话过期的通知,除非它重新和服务器建立了连接。客户端将会一直处于离线状态直到重新和集群建立了TCP连接,在这个时候过期会话的watcher将会接收到"session expired"通知。
过期会话可以看到的状态转变为:
1. 'connected':会话被建立并且客户端和集群通信(客户端/服务器之间正常进行通信)
2. ....... 客户端在集群上进行分区
3. 'disconnected':客户端失去了和集群的连接
4. ......time elapses,在'timeout'后,集群会过期会话,这个时候客户端啥也不知道,因为它已经断开了和服务器的连接
5. ......time elapses,客户端重新获得和集群的网络连接
6. 'expired':最终客户端会对集群进行重连
建立ZooKeeper需要的另一个参数就是默认的watcher。当客户端有任何的状态改变的时候Watcher都会收到通知。例如,如何客户端失去了对服务器的连接,客户端将会被通知到,或者如果客户端的会话超时了等。这个watcher应该认为初始状态为disconnected(或者说在任何状态改变的事件发送到watcher之前它的状态应该是disconnected)。在新建一个连接的情况下,发送到watch第一个状态改变事件应该是connection。
客户端发送请求来维持会话状态。如果会话在一段时间内闲置会使得会话被超时,客户端将会发送一个PING请求来使得会话存活。这个PING请求仅仅是让服务器知道这个客户端仍然还活着,同时也可以让客户端来验证它是否仍然连接到服务器了。PING的时间维持足够长来确保检测死连接以及重新创建一个到新的服务器的连接。
一旦成功建立了到服务器的一个连接(connected),通常有两种情况客户端库造成连接丢失(这个结果在C binding中,而Java中没有)当一个通过或者异步的操作执行之后,并且下面情况存在:
1. 应用在会话中对一个不在存活的session进行操作。
2. ZooKeeper客户端从服务器断开连接,当这里对服务器有pending操作,或者说有一个pending的异步调用。
Added in 3.2.0 SessionMovedException(会话移除异常)。
ZooKeeper Watchers
Watches的语义(Semantics)
ZooKeeper对Watches的保证
对Watches要注意的地方
使用ACLs的ZooKeeper权限控制
ACL相关操作
可插拔的ZooKeeper认证
一致性保证
Bindings
Java Binding
C Binding
Building Block:ZooKeeper操作指南
我曹,要烂尾了
分布式服务框架 Zookeeper(四)官方编程指南的更多相关文章
- 分布式服务框架 Zookeeper(转)
分布式服务框架 Zookeeper -- 管理分布式环境中的数据 Zookeeper 分布式服务框架是 Apache Hadoop 的一个子项目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题 ...
- 大数据 --> 分布式服务框架Zookeeper
分布式服务框架 Zookeeper Zookeeper系列 分布式服务框架 Zookeeper -- 管理分布式环境中的数据
- 分布式服务框架 Zookeeper — 管理分布式环境中的数据
本节本来是要介绍ZooKeeper的实现原理,但是ZooKeeper的原理比较复杂,它涉及到了paxos算法.Zab协议.通信协议等相关知识,理解起来比较抽象所以还需要借助一些应用场景,来帮我们理解. ...
- 分布式服务框架Zookeeper
协议介绍 zookeeper协议分为两种模式 崩溃恢复模式和消息广播模式 崩溃恢复协议是在集群中所选举的leader 宕机或者关闭 等现象出现 follower重新进行选举出新的leader 同时集群 ...
- 分布式服务框架 Zookeeper -- 管理分布式环境中的数据
转自:http://www.ibm.com/developerworks/cn/opensource/os-cn-zookeeper/index.html Zookeeper 分布式服务框架是 Apa ...
- 分布式服务框架 Zookeeper -- 管理分布式环境中的数据(转载)
本文转载自:http://www.ibm.com/developerworks/cn/opensource/os-cn-zookeeper/ Zookeeper 分布式服务框架是 Apache Had ...
- 分布式服务框架 Zookeeper -- 管理分布式环境中的数据--转载
原文:http://www.ibm.com/developerworks/cn/opensource/os-cn-zookeeper/ Zookeeper 分布式服务框架是 Apache Hadoop ...
- 【Zookeeper】分布式服务框架 Zookeeper -- 管理分布式环境中的数据
Zookeeper 分布式服务框架是 Apache Hadoop 的一个子项目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务.状态同步服务.集群管理.分布式应用配置项的管理 ...
- 分布式服务框架 Zookeeper(一)介绍
一.概述 ZooKeeper(动物园管理员),顾名思义,是用来管理Hadoop(大象).Hive(蜜蜂).Pig(小猪)的管理员,同时Apache Hbase.Apache Solr.LinkedIn ...
- 【转】分布式服务框架 Zookeeper -- 管理分布式环境中的数据
Zookeeper 分布式服务框架是 Apache Hadoop 的一个子项目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务.状态同步服务.集群管理.分布式应用配置项的管理 ...
随机推荐
- Problem X: 零起点学算法22——华氏摄氏温度转换
#include<stdio.h> int main() { float f,c; while(scanf("%f",&f)!=EOF) c=*(f-); pr ...
- scrapy初探
一 创建scrapy项目 运行命令: scrapy startproject 项目名称 目录结构 二 定义Item容器 Item是保存爬取到数据的容器,其使用方法和python字典类似,并且提供了 ...
- Android中使用File文件进行数据存储
Android中使用File文件进行数据存储 上一篇学到使用SharedPerences进行数据存储,接下来学习一下使用File进行存储 我们有时候可以将数据直接以文件的形式保存在设备中, 例如:文本 ...
- JAVA 基本概念和编码规范
概括性描述:一个Java程序可以认为是一系列对象的集合,而这些对象通过调用彼此的方法来协同工作. 基本概念: 下面简要介绍下类.对象.方法和属性的概念. 对象:对象是类的一个实例,有状态和行为.例如, ...
- Saga的实现模式——进化(Saga implementation patterns – variations)
在之前的几个博客中,我主要讲了两个saga的实现模式: 基于command的控制者模式 基于事件的观察者模式 当然,这些都不是实现saga的唯一方式.我们甚至可以将这些结合起来. 发布者——收集者 回 ...
- P2P通信标准协议(四)之SIP
在前面几篇文章中我们介绍了建立p2p通信的一般协议(簇),以及一种完整的NAT传输解决方案ICE, 但是对于多用户的通信情况,还有一些通用协议来实现标准化的管理,如之前讲过的SDP和SIP等,SIP( ...
- vue-resource的使用中需要注意的坑
先看一段代码: export default { name: 'app', data() { return { articles: [] } }, created: function() { this ...
- JavaScript中的bind方法及其常见应用
一.bind()方法的实现 在JavaScript中,方法往往涉及到上下文,也就是this,因此往往不能直接引用.就拿最常见的console.log("info…")来说,避免书写 ...
- 详解Python中的生成器表达式(generator expression)
介绍 1.生成器表达式(generator expression)也叫生成器推导式或生成器解析式,用法与列表推导式非常相似,在形式上生成器推导式使用圆括号(parentheses)作为定界符,而不是列 ...
- represent states with objects
1. The behavior of objects in the real world is more complex than simply being in one state at a tim ...