在zookeeper集群的基础上,搭建solrCloud
1 将在window中部署的单机版solr上传到node-01中
cd /export/software/
rz
选择资料中的solr.zip进行上传(此zip就是 solr的简单部署:在tomcat中启动slor 的内容, 包含solr-home和tomcat)
2 将zip进行解压到指定目录中
由于是zip文件,在linux上解压需要unzip
yum -y install unzip
unzip solr.zip
mv solr /export/servers/
3 修改tomcat的Catalina.sh的配置文件
cd /export/servers/solr/apache-tomcat-7.0./bin
vi catalina.sh //注意此时修改的.sh的文件 为非.bat //添加如下内容:(此处后面还会进行修改, 目前只是为了测试单机版本能否在linux中运行)
export "JAVA_OPTS=-Dsolr.solr.home=/export/servers/solr/solr-home"
4 启动tomcat测试单机版本能否在linux中运行
//注意: 由于是解压的是zip文件, tomcat中的.sh文件都没有任何的执行缺陷, 需要进行赋权限:
chmod /export/servers/solr/apache-tomcat-7.0./bin/* //启动tomcat:
cd /export/servers/solr/apache-tomcat-7.0.77/bin/
./startup.sh
访问 192.168.44.28:8080/solr 看是否成功 192.168.44.28是你当前虚拟机的ip
5 成功后: 将tomcat务必先关闭
./shutdown.sh
6 将solr的配置文件交给zookeeper进行管理
//1. 需要先上传solr的安装包
cd /export/software/
rz
//2. 解压solr的安装包
unzip solr-4.10..zip
//3. 将solr安装包复制到/export/servers下
mv solr-4.10. /export/servers/
//4. 开始执行上传
cd /export/servers/solr-4.10./example/scripts/cloud-scripts/
//注意: 以下命令是一行 而且要确保三台机器的zookeeper是开启的 zookeeper集群的搭建
./zkcli.sh -zkhost node-:,node-:,node-: -cmd upconfig -confdir /export/servers/solr/solr-home/collection1/conf/ -confname solrconf
//参数解释: -zkhost指定zookeeper地址列表, -cmd指定命令, upconfig上传配置的命令, -confdir配置文件所在目录, -confname配置名称

7 修改solr.xml配置文件
solr.xml是solr集群管理文件
cd /export/servers/solr/solr-home/
vi solr.xml
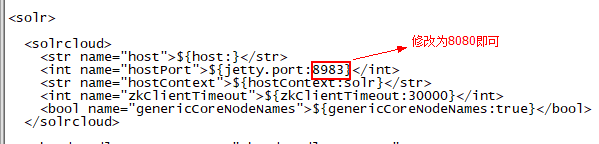
8 修改tomcat的Catalina.sh配置文件
其实可以单独修改每个solr的solrhome地址(修改每个solr的 web.xml 文件, 关联它自己的solrhome),然后在这里直接配置-DzHost就可以了,这里就先不做介绍了。
cd /export/servers/solr/apache-tomcat-7.0./bin/
vi catalina.sh
// 修改如下内容
export "JAVA_OPTS=-Dsolr.solr.home=/export/servers/solr/solr-home //原来的内容 //以下为替换后的内容 注意: 这是一行内容, 复制时一起复制即可
export "JAVA_OPTS=-Dsolr.solr.home=/export/servers/solr/solr-home -DzkHost=node-01:2181,node-02:2181,node-03:2181
9 将solr目录发送到其他两台linux上(node2,node3)
cd /export/servers/
scp -r solr root@node-:$PWD
scp -r solr root@node-:$PWD
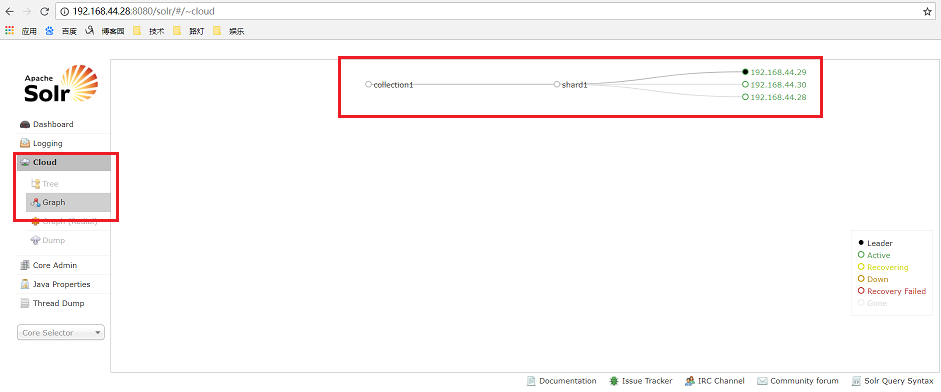
10 依次启动三台solr即可
cd /export/servers/solr/apache-tomcat-7.0./bin/
./startup.sh
------------------------------以上 基本搭建就完成了 下面介绍solrCloud相关的管理命令-------------------------------
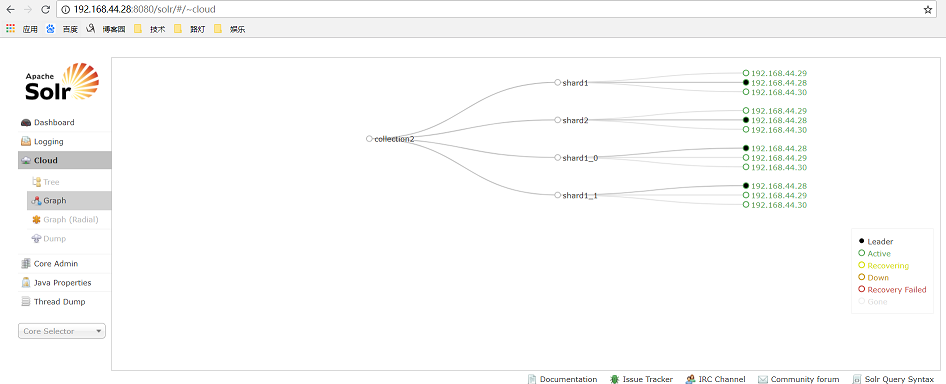
1 创建新集群(创建一个索引库)
http://192.168.44.28:8080/solr/admin/collections?action=CREATE&name=collection2&numShards=2&replicationFactor=3&maxShardsPerNode=8&property.schema=schema.xml&property.config=solrconfig.xml //接口参数说明: action: 表示执行的操作 CREATE 创建
name: 新集群的名称
numShards: 分片数
replicationFactor: 每个分片的节点数
maxShardsPerNode: 设置每个分片的最大节点数, 默认为1
property.schema: 指定使用的schema文件 (注意, 此文件必须在zookeeper上存在)
property.config: 指定使用的solrConfig文件 (注意, 此文件必须在zookeeper上存在)
2 删除core命令
http://192.168.44.28:8080/solr/admin/collections?action=DELETE&name=collection1
3 查询所有的Core
http://192.168.44.28:8080/solr/admin/collections?action=LIST
4 分裂shard(扩展容量)
分裂: 就是将某个分片分成两个分片
注意: 一旦分裂后, 虽然原来的分片还可以提供服务, 但是已经不再保存数据, 会将数据保存到新的分裂后的分片
http://192.168.44.28:8080/solr/admin/collections?action=SPLITSHARD&collection=collection2&shard=shard1 参数说明:
shard: 指定要分裂的分片
5 删除某个分片
注意: 删除的分片必须是已经被分裂的, 或者是已经无法提供服务的
http://192.168.44.28:8080/solr/admin/collections?action=DELETESHARD&shard=shard1&collection=collection2
使用java代码对zookeeper集群中的solrCloud数据进行CURD
在zookeeper集群的基础上,搭建solrCloud的更多相关文章
- 沉淀,再出发——在Hadoop集群的基础上搭建Spark
在Hadoop集群的基础上搭建Spark 一.环境准备 在搭建Spark环境之前必须搭建Hadoop平台,尽管以前的一些博客上说在单机的环境下使用本地FS不用搭建Hadoop集群,可是在新版spark ...
- 在zookeeper集群的基础上,搭建伪solrCloud集群
伪集群的搭建:将solrCloud搭建到同一台机器上. 准备工作 1 将在window中部署的单机版solr上传到服务器(虚拟机)中 solr的简单部署:在tomcat中启动slor 的内容 这一次放 ...
- [k8s]zookeeper集群在k8s的搭建(statefulset模式)-pod的调度
之前一直docker-compose跑zk集群,现在把它挪到k8s集群里. docker-compose跑zk集群 zk集群in k8s部署 参考: https://github.com/kubern ...
- 第八章 搭建hadoop2.2.0集群,Zookeeper集群和hbase-0.98.0-hadoop2-bin.tar.gz集群
安装配置jdk,SSH 一.首先,先搭建三台小集群,虚拟机的话,创建三个 下面为这三台机器分别分配IP地址及相应的角色:集群有个特点,三台机子用户名最好一致,要不你就创建一个组,把这些用户放到组里面去 ...
- 关于Linux系统下zookeeper集群的搭建
1.集群概述 1.1什么是集群 1.1.1集群概念 集群是一种计算机系统, 它通过一组松散集成的计算机软件和/或硬件连接起来高度紧密地协作完成计算工作.在某种意义上,他们可以被看作是一台计算机.集群系 ...
- docker-compose搭建zookeeper集群环境 CodingCode
docker-compose搭建zookeeper集群环境 使用docker-compose搭建zookeeper集群环境 zookeeper是一个集群环境,用来管理微服务架构下面的配置管理功能. 这 ...
- Zookeeper集群介绍及其搭建
1 Zookeeper集群简介 1为什么搭建Zookeeper集群 大部分分布式应用需要一个主控.协调器或者控制器来管理物理分布的子进程.目前,大多数都要开发私有的协调程序,缺乏一个通用机制,协调程序 ...
- Zookeeper 集群 BindException: Cannot assign requested address 解决方案
前言 经历: 最近在搭建zookeeper集群,基础是3台机器(尝试过ubuntu 17 和 Centos 7). 一开始选择的是3台腾讯云服务器,每台机器在java环境配置正确的情况下,单机的情况都 ...
- 构建Zookeeper集群(zkcluster) ~一篇文章玩转zk集群^.^
概念 Zookeeper集群是由一个leader(负责人)主机和多个follower(追随者)或observer(观察者)主机组成. 构建一个Zookeeper集群需要有一个leader和一个foll ...
随机推荐
- [Hive]HiveServer2配置
HiveServer2(HS2)是一个服务器接口,能使远程客户端执行Hive查询,并且可以检索结果.HiveServer2是HiveServer1的改进版,HiveServer1已经被废弃.HiveS ...
- Win7系统64位环境下使用Apache——Apache2.4整合Tomcat与mod_jk
转载请注明出处:http://blog.csdn.net/dongdong9223/article/details/70398091 本文出自[我是干勾鱼的博客] 之前的几篇文章: Win7系统64位 ...
- 深入理解UE4宏定义—— GENERATED_BODY
本文章由cartzhang编写,转载请注明出处. 所有权利保留. 文章链接:http://blog.csdn.net/cartzhang/article/details/72834164 作者:car ...
- B. Clique Problem(贪心)
题目链接: B. Clique Problem time limit per test 2 seconds memory limit per test 256 megabytes input stan ...
- opencv 卡尔曼滤波器例子,自己修改过
一.卡尔曼滤波器的理论解释 http://blog.csdn.net/lindazhou2005/article/details/1534234(推荐) 二.代码中一些随机数设置函数,在opencv中 ...
- Chrome 的书签太多如何分类整理比较好
对于Chrome书签太多,如何进行分类整理,下面给出几种方法~ 工具/原料 电脑 Chrome浏览器 delicious.Diigo等 方法/步骤1 1.把书签中常用网站只保存LOGO,放在书签栏最前 ...
- 51nod 1011 最大公约数GCD
输入2个正整数A,B,求A与B的最大公约数. 收起 输入 2个数A,B,中间用空格隔开.(1<= A,B <= 10^9) 输出 输出A与B的最大公约数. 输入样例 30 105 输出 ...
- 关于ip层的作用网址链接
http://rabbit.xttc.edu.cn/rabbit/htm/artical/201091113054.shtml
- ACM学习历程—HDU5701 中位数计数(中位数 && 计数排序)
http://acm.hdu.edu.cn/showproblem.php?pid=5701 这是这次百度之星初赛2B的第六题.之前白山云做过类似的题,省赛完回来,我看了一下大概就有这样的思路:首先枚 ...
- UVA10674 Tangents
题意 PDF 分析 就是圆的切线的模板. 注意精度问题,排序的时候也不能直接写,被卡了好几次. 时间复杂度\(O(T)\) 代码 #include<iostream> #include&l ...