【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 2_Linear regression with one variable 单变量线性回归
Lecture2 Linear regression with one variable 单变量线性回归
2.1 模型表示 Model Representation
2.1.1 线性回归 Linear regression
2.1.2 单变量线性回归 Linear regression with one variable
2.2 代价函数 Cost Function
2.2.1 如何选择模型的参数 θ
2.2.2 建模误差 modeling error
2.2.3 平方误差代价函数 Squared error cost function
2.3 代价函数的直观理解 I
2.4 代价函数的直观理解 II
2.5 梯度下降 Gradient descent
2.5.1 局部最优解 local optimum
2.5.2 梯度下降算法 Gradient descent algorithm
2.6 梯度下降的直观理解
2.6.1 梯度下降算法的更新规则
2.6.2 学习速率 α 的选择
2.6.3 不调整学习速率 α 也能收敛
2.7 梯度下降的线性回归
2.7.1 梯度下降和线性回归相结合
2.7.2 批处理梯度下降 batch gradient descent
2.8 接下来的内容
2.1 模型表示 Model Representation
参考视频: 2 - 1 - Model Representation (8 min).mkv
本节引入第一个监督学习算法:线性回归 Linear regression。其中只有一个参数的线性回归算法叫做 单变量线性回归 Linear regression with one variable。
2.1.1 线性回归 Linear regression
还是房价预测的例子, 训练集如下:
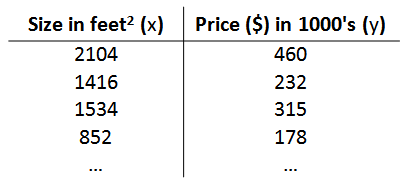
定义各个变量的含义如下:
m 代表训练集中实例的数量
x 代表特征/输入变量
y 代表目标变量/输出变量
(x,y) 代表训练集中的实例
(x(i),y(i)) 代表第 i 个观察实例:其中x(i) 代表第i个输入变量, y(i)代表第i个目标变量
h 代表学习算法的解决方案或函数,也称为假设(hypothesis)
2.1.2 单变量线性回归 Linear regression with one variable
h 根据输入的 x 值来得出 y 值, y 值对应房子的价。因此, h 是一个从x 到 y 的函数映射。

h 的一种可能的表达方式如下。因为只含有一个特征/输入变量,这样的问题叫作单变量线性回归问题。
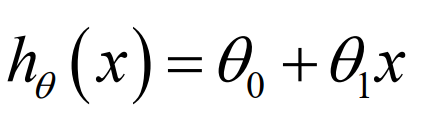
2.2 代价函数 Cost Function
参考视频: 2 - 2 - Cost Function (8 min).mkv
线性回归算法优化的目标是:选取最有可能与数据相拟合的直线。数据与直线的误差,称为建模误差 modeling error。为了使建模误差最小,我们需要调整参数θ0 和 θ1,使得代价函数Cost function J(θ0, θ1)的值最小。
在各种代价函数中,最常用的是平方误差代价函数 Squared error cost function。
2.2.1 如何选择模型的参数 θ
因为 h 是一次方程,它对应两个模型参数(parameters) θ0 和 θ1:

选取不同的参数 θ0 和 θ1,产生的 h 不同,最终的直线也不同:

2.2.2 建模误差 modeling error
参数决定了直线相对于训练集的准确程度,模型所预测值 与 训练集实际值 之间的差距(下图中蓝线所指)就是 建模误差(modeling error)。

调整参数 θ0 和 θ1,目标:使建模误差的平方和最小
2.2.3 平方误差代价函数 Squared error cost function
为了使建模误差最小,需要 使代价函数 J(θ0, θ1) 最小,公式如下。其中 h(x) - y 是预测值和实际值的差,取其平方和。m 指的是数据集的大小,乘以1/2m 是为了便于计算。这个J(θ0 ,θ1) 通常称为 平方误差函数(Squared error function),有时也被称为 平方误差代价函数(Squared error cost function)。
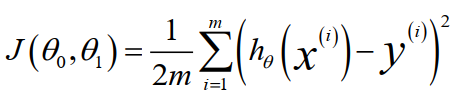
下面公式的意思是:寻找θ0 和 θ1,使得 J 值最小。
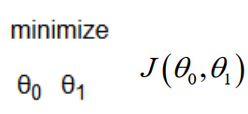
我们绘制一个等高线图, 三个坐标分别为 θ0 和 θ1 和 J(θ0 和 θ1),则可以看出在三维空间中存在一个点,使得 J(θ0 和 θ1)最小:

2.3 代价函数的直观理解 I
参考视频: 2 - 3 - Cost Function - Intuition I (11 min).mkv
线性回归模型的假设、参数、代价函数、目标如下:

取将 θ0 固定为 0时,代价函数简化为只关于 θ1 的函数:
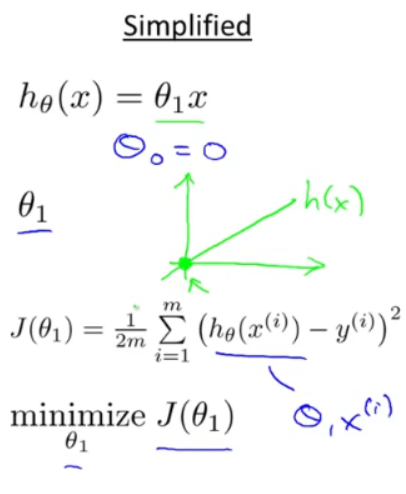
下面的例子里,三个数据点的坐标是(1,1)(2,2)(3,3)。当将 θ0固定为0,只变化 θ1时, 代价函数是一条二次曲线。
当 θ1 分别取值1,0.5,0的时候,对应左边从上到下三条曲线。
当 θ1 取1时,J(θ1) = 0 , 此时 J(θ1) 最小,处于曲线最低点,是我们想要的结果。
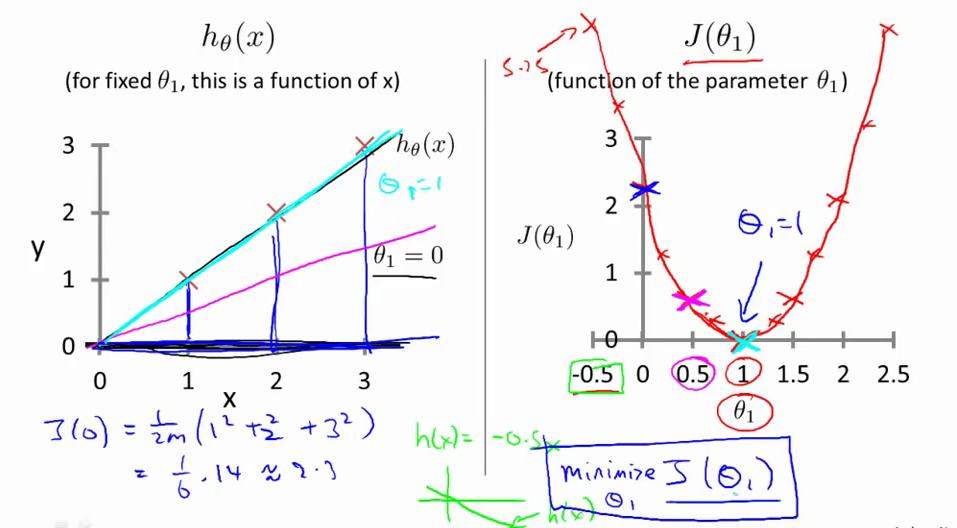
2.4 代价函数的直观理解 II
参考视频: 2 - 4 - Cost Function - Intuition II (9 min).mkv
当 θ0 和 θ1 都发生变化时,代价函数 J(θ0 , θ1) 在三维空间中图形如下:
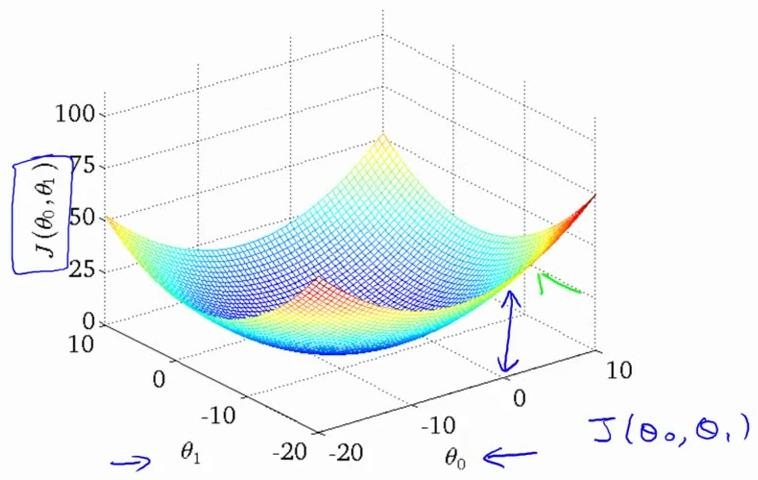
因为三维图像看起来太复杂, 将它投射到二维平面。引入等高线contour plot 的概念,也叫contour figure。等高线上的点,对应的代价函数 J(θ0 , θ1) 取值相同。
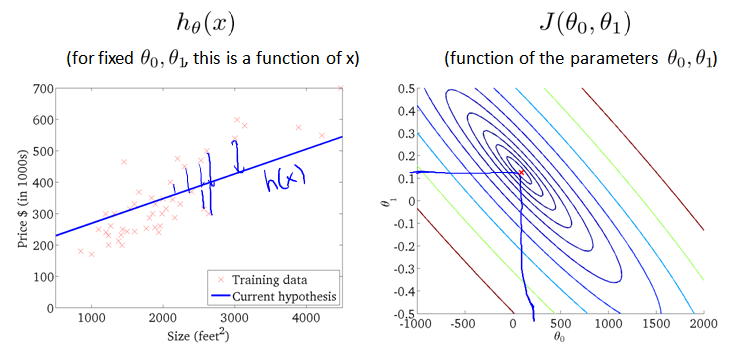
下面两个图,右边红点对应的直线如左图,可以看出拟合的都不好。

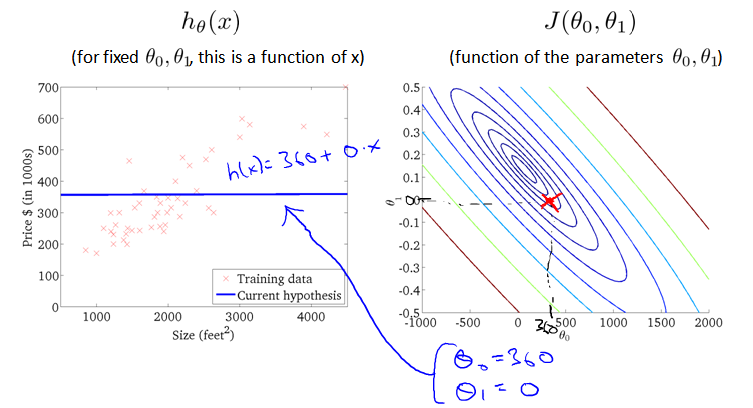
下图取值位于三维图形的最低点,在二维图形上位于等高线的中心。对应的假设函数 h(x) 直线如左图。虽然拟合数据有一些误差(蓝色竖线),但是已经很接近最小值了。
2.5 梯度下降 Gradient descent
参考视频: 2 - 5 - Gradient Descent (11 min).mkv
2.5.1 局部最优解 local optimum
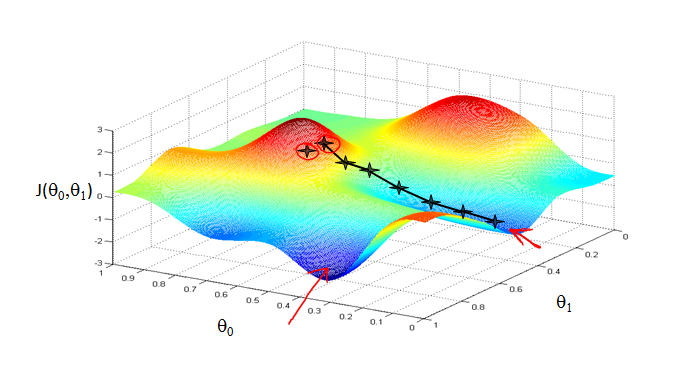
已有一个代价函数,我们的目的是使其最小化。通常情况下,始于θ0=0 , θ1=0,调整θ0 , θ1,止于J(θ0 , θ1) 的最小值。

下面这个例子,θ0 和θ1没有开始于0,0。当选取两个不同的起始点,并向着不同方向进行梯度下降时,到达两个不同的最优解,它们称为局部最优解local optimum。

2.5.2 梯度下降算法 Gradient descent algorithm
梯度下降算法对 θ赋值, 使得 J(θ)按梯度下降最快方向进行, 一直迭代下去, 最终得到局部最小值,即收敛 convergence。梯度下降算法不只用于线性回归, 可以用来最小化任何代价函数 J。公式如下,

梯度下降算法中,两个参数 同步更新 simultaneous update(左下)。如果是非同步更新 non-simultaneous update (右下),则不是梯度下降。

a := b 是赋值操作 assignment ,将 b 的值赋值给 a。
a = b 是真值断言Truth assertion,判断 a 和 b 是否相等。
α 是 学习速率 learning rate,决定了沿着能让代价函数下降程度最大的方向向下迈出的步子有多大。
2.6 梯度下降的直观理解
参考视频: 2 - 6 - Gradient Descent Intuition (12 min).mkv
2.6.1 梯度下降法的更新规则
梯度下降算法如下图:
求导的目的,基本上可以说取这个红点的切线,即这条红色直线。由于曲线右侧斜率为正,导数为正。 因此,θ1 减去一个正数乘以 α,值变小。
曲线左侧斜率为负,导数为负。 因此,θ1 减去一个负数乘以 α,值变大。

2.6.2 学习速率 α 的选择
如果 α 太小,只能小碎步下降,需要很多步才能到达全局最低点,很慢。
如果 α 太大,那么算法可能会越过最低点。一次次越过最低点,离它越来越远。会导致无法收敛, 甚至发散。

2.6.3 不调整学习速率 α 也能收敛
假设将 θ1初始化在局部最低点。导数为0,会使得 θ1不再改变,不会改变参数的值。也解释了为什么即使学习速率 α 保持不变时, 梯度下降也可以收敛到局部最低点。

为什么不用调整α也能到达局部最优点?因为梯度下降一步后, 新的导数会变小,移动的幅度会自动变小。直到最终移动幅度非常小时,已经收敛到局部极小值。

2.7 梯度下降的线性回归 Gradient Descent For Linear Regression
参考视频: 2 - 7 - GradientDescentForLinearRegression (6 min).mkv
2.7.1 梯度下降和线性回归相结合
将平方误差函数 h(x), 结合梯度下降法, 以及平方代价函数J(Θ),得出第一个机器学习算法, 即线性回归Linear Regression。
梯度下降算法和线性回归模型的比较:

对之前的线性回归问题运用梯度下降法,关键在于求出代价函数的导数,即:
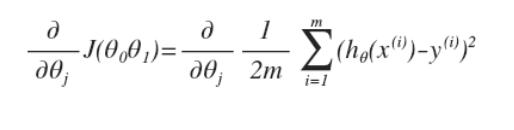
j 分别取 0 和 1 时,其导数如下:
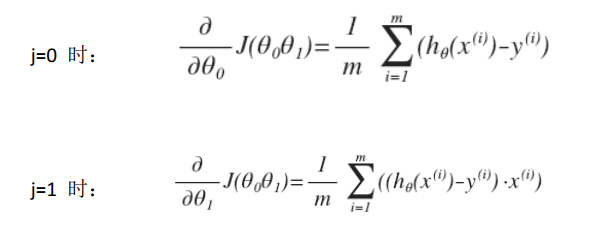
将上面两个导数带入梯度下降算法中,替代原来的 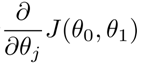 。梯度下降算法变为:
。梯度下降算法变为:

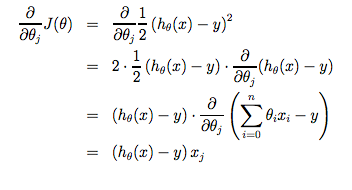
虽然梯度下降一般易受局部最小值影响 susceptible to local minima,但我们在线性回归中提出的优化问题只有一个全局最优解,而没有其他局部最优解,代价函数是凸二次函数。因此,梯度下降总是收敛到全局最小值(假设学习率α不是太大)。
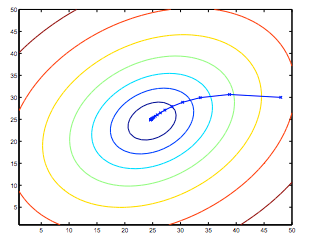
2.7.2 批处理梯度下降 batch gradient descent
上面使用的算法也叫批处理梯度下降 batch gradient descent,指的是梯度下降的每一步都涉及到所有的训练实例。也有其他类型的非批处理梯度下降法,每次只关注训练集中一些小子集。
高等线性代数中有一种计算代价函数 J 最小值的数值解法,不需要梯度下降这种迭代算法,也能解出代价函数 J 的最小值,这是另一种称为正规方程(normal equations)的方法。实际上在数据量较大的情况下,梯度下降法比正规方程要更适用一些。
2.8 接下来的内容
参考视频: 2 - 8 - What_'s Next (6 min).mkv
介绍了一点线性代数 Linear algebra
相关术语
线性回归 Linear regression
单变量线性回归 Linear regression with one variable
代价函数 Cost Function
平方误差代价函数 Squared error cost function
建模误差 Modeling error
等高线 contour plot 、contour figure
梯度下降 Gradient descent
批处理梯度下降 Batch gradient descent
学习效率 Learning rate
同步更新 simultaneous update
非同步更新 non-simultaneous update
局部最优 local optimum
全局最优 global optimum
全局最小值 global minimum
局部最小值 local minimum
微分项 derivative term
微积分 calculus
导数 derivatives
偏导数 partial derivatives
负导数 nagative derivative
负斜率 nagative slope
收敛 converge
发散 diverge
陡峭 steep
碗型 bow-shaped function
凸函数 convex function
线性代数 linear algebra
迭代算法 iterative algorithm
正规方程组 normal equations methods
梯度下降的泛化 a generalization of the gradient descent algorithm
越过最低点 overshoot the minimum
【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 2_Linear regression with one variable 单变量线性回归的更多相关文章
- 【原】Coursera—Andrew Ng机器学习—Week 1 习题—Linear Regression with One Variable 单变量线性回归
Question 1 Consider the problem of predicting how well a student does in her second year of college/ ...
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 4_Linear Regression with Multiple Variables 多变量线性回归
Lecture 4 Linear Regression with Multiple Variables 多变量线性回归 4.1 多维特征 Multiple Features4.2 多变量梯度下降 Gr ...
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 6_Logistic Regression 逻辑回归
Lecture6 Logistic Regression 逻辑回归 6.1 分类问题 Classification6.2 假设表示 Hypothesis Representation6.3 决策边界 ...
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 15—Anomaly Detection异常检测
Lecture 15 Anomaly Detection 异常检测 15.1 异常检测问题的动机 Problem Motivation 异常检测(Anomaly detection)问题是机器学习算法 ...
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 16—Recommender Systems 推荐系统
Lecture 16 Recommender Systems 推荐系统 16.1 问题形式化 Problem Formulation 在机器学习领域,对于一些问题存在一些算法, 能试图自动地替你学习到 ...
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 14—Dimensionality Reduction 降维
Lecture 14 Dimensionality Reduction 降维 14.1 降维的动机一:数据压缩 Data Compression 现在讨论第二种无监督学习问题:降维. 降维的一个作用是 ...
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 13—Clustering 聚类
Lecture 13 聚类 Clustering 13.1 无监督学习简介 Unsupervised Learning Introduction 现在开始学习第一个无监督学习算法:聚类.我们的数据没 ...
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 12—Support Vector Machines 支持向量机
Lecture 12 支持向量机 Support Vector Machines 12.1 优化目标 Optimization Objective 支持向量机(Support Vector Machi ...
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 11—Machine Learning System Design 机器学习系统设计
Lecture 11—Machine Learning System Design 11.1 垃圾邮件分类 本章中用一个实际例子: 垃圾邮件Spam的分类 来描述机器学习系统设计方法.首先来看两封邮件 ...
随机推荐
- OC-SEL 和 Class
[认识选择器]============================================ SEL 1.选择器(SEL)是一个变量类型. 2.选择器用来装成员消息(成员方法) people ...
- CSS:Tutorial two
1.CSS Text text color, text align... Text Decoration The text-decoration property is used to set or ...
- canvas 绘制文本
<!DOCTYPE html> <html> <head lang="en"> <meta charset="UTF-8&quo ...
- 前端之JavaScript再次补充(干死!!)
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 通过设置debug_options调试squid
debug_options用于设置输出到access.log中的调试信息的模块和级别,默认为ALL,1. ALL指所有模块,每个源文件被赋予一个唯一的模块号 1指级别,完全调试的级别为9.很显然,设置 ...
- Java得到当前系统时间,精确到毫秒的几种方法
import java.text.SimpleDateFormat; import java.util.Date; import java.util.Calendar; public class Ma ...
- PS更换证件照颜色
PS是我们经常使用的设计软件,在生活中使用的范围也很广,但是对于普通的用户来说,也就是平时给自己的照片美化一下,还有就是做一些证件照.今天和大家分享的是更改证件照的颜色,网上可能有很多,但是个人感觉都 ...
- JAVA如何以追加的方式向文件中写入信息?
以FileWriter类为例: FileWriter的构造方法中有一个方法是:FileWriter(String fileName, boolean append) ,其中第二个参数决定了写文件的方 ...
- 四种线性相位FIR滤波器振幅谱统一形式
- 双色球基础分析--SQL
代码是心血来潮编写得,就象买彩票一样,为国家做贡献:首先建立一个表,表得数据可以从福利彩票网站上获得,自己一个一个得录入进去先: 表结构为: ) NOT NULL , --期数 [F1] [i ...