Python之路第二天,基础(2)-基本数据类型
一、Python数据类型
数
在Python中有4种类型的数,整数,长整数,浮点数和复数。
- 2是一个整数的例子
- 长整数不过是大一点的整数
- 3.23和52.3E是浮点数的例子。E标记表示10的幂。52.3E-4表示52.3 * 10-4
- (-5+4j)和(2.3-4.6j)是复数的例子
C语言:
C语言数据类型分为基本类型,构造类型,指针类型,和空类型。
- 基本类型又分为整型:短整型(short int),基本整型(int)和长整型(long int);字符型(char);实型(浮点型):单精度型(float)和双精度型(double);枚举类型
- 构造类型:数组类型,结构体类型,共用体类型
- 指针类型(C语言的精华)
- 空类型(void)
int类型
在32位机器上,整数的位数为32位,取值范围为-231~231-1,即-2147483648~2147483647
在64位系统上,整数的位数为64位,取值范围为-263~263-1,即-9223372036854775808~9223372036854775807
long int长整型
跟C语言不同,Python的长整数没有指定位宽,即:Python没有限制长整数数值的大小,但实际上由于机器内存有限,我们使用的长整数数值不可能无限大。
自从Python2.2起,如果整数发生溢出,Python会自动将整数数据转换为长整数,所以如今在长整数数据后面不加字母L也不会导致严重后果了。
float浮点数
浮点数用来处理实数,即带有小数的数字。类似于C语言中的double类型,占8个字节(64位),其中52位表示底,11位表示指数,剩下的一位表示符号。
complex复数
复数由实数部分和虚数部分组成,一般形式为x+yj,其中的x是复数的实数部分,y是复数的虚数部分,这里的x和y都是实数。
注:Python中存在小数字池:-5 ~ 257
字符串
字符串是字符的序列,字符串基本上就是一组单词。
下面是如何在Python中使用字符串:
使用单引号(')
你可以使用单引号指示字符串,例如'hello, world!'所有的空白,即空格和制表符都原样保留
使用双引号(")
在双引号的字符串和在单引号的字符串使用完全相同,例如:"What's your name?"
使用三引号('''或""")
利用三引号你可以格式化一个多行字符串,你可以在三引号中自由的使用单引号或双引号。例如
'''hello,what's your name?
Is "apple" a fruit or a cell phone?
'''转义符
假如你要在一个字符串中包含一个'单引号,你该怎么表示?例如What's your name? 是这样吗'What's your name?',肯定不是这样,因为Python字符串从何时开始,何时结束。可以通过转义符来完成这个任务 :'What's your name?'另外还有一个方法是用双引号,即 "What's your name?",当然双引号的字符串里还有双引号的话,这时就需要转义\"
万恶的字符串拼接:
python中的字符串在C语言中体现为是一个字符数组,每次创建字符串时候需要在内存中开辟一块连续的空,并且一旦需要修改字符串的话,就需要再次开辟空间,万恶的+号每出现一次就会在内从中重新开辟一块空间。
操作字符串的一些方法:
- 去掉字符串前后的字符
.strip([chars])把str中前后chars中有的字符全部去掉,可以理解为把S前后chars替换为None
str = ' hello,world! '
str.strip() #把字符串前后的空格都去掉
'hello,world'str.lstrip() #把字符串左边的空格去掉
'hello,world 'str.rstrip() #把字符串右边的空格去掉
' hello,world'
```
- 字符串分隔
split([sep, [maxsplit]]) 以sep为分隔符,把str分成一个list。maxsplit表示分割的次数。默认的分割符为空白字符.
str = 'Tom,Jerry,Jack,Rose'
str.split(',') #以逗号为分隔符
['Tom','Jerry','Jack','Rose']
```
字符串中字符大小写的变换
str = 'Alex,how are you?'
str.lower() #将所有大写字符转换为小写
'alex,how are you?'str.upper() #将所有小写字符转换为大写
'ALEX,HOW ARE YOU?'str.swapcase() #大小写字符互换
'aLEX,HOW ARE YOU?'str.capitalize() #首字母大写
'Alex,how are you?'
```
- 字符串在输出时的对齐
ljust(width,[fillchar]) 输出width个字符,str左对齐,不足部分用fillchar填充,默认的为空格。
str = 'Welcome'
str.ljust(50,'-') #左对齐
'Welcome-------------------------------------------'str.rjust(50,'-') #右对齐
'-------------------------------------------Welcome'str.center(50,'-') #居中
'---------------------Welcome----------------------'
```
- 字符串查找
find(substr, [start, [end]]) 返回str中出现substr的第一个字母的标号,如果str中没有substr则返回-1。start和end作用就相当于在S[start:end]中搜索.
index(substr, [start, [end]]) 和find一样,只是在str中没有substr时,会返回一个运行时错误.
rfind(substr, [start, [end]]) 返回str中最后出现的substr的第一个字母的标号,如果str中没有substr则返回-1,也就是说从右边算起的第一次出现的substr的首字母标号.
rindex((substr, [start, [end]]) 同理
str = 'hello,world,hello,world'
str.find('hello')
0str.find('world')
6str.find('haha')
-1str.index('hello')
0str.index('world')
6str.index('haha')
Traceback (most recent call last):
File "", line 1, in
str.index('haha')
ValueError: substring not foundstr.rfind('hello')
12str.rindex('hello')
12str.rfind('haha')
-1str.rindex('haha')
Traceback (most recent call last):
File "", line 1, in
str.rindex('haha')
ValueError: substring not found
```
- 字符串判断
startswith(prefix[,start[,end]]) 是否以prefix开头。
endswith(suffix[,start[,end]]) 是否以suffix结尾。
str = 'hello,world,hello,world'
str.startswith('hello')
Truestr.endswith('world')
True
```
```
isalnum() #是否全是字母和数字,并至少有一个字符
isalpha() #是否全是字母,并至少有一个字符
isdigit() #是否全是数字,并至少有一个字符
isspace() #是否全是空白字符,并至少有一个字符
islower() #S中的字母是否全是小写
isupper() #S中的字母是否便是大写
istitle() #S是否是首字母大写的
这个就不举例子了。
```
- 字符串切片
str = 'hello,world'
str[0]
'h'str[0:4]
'hell'str[:4]
'hell'str[4:6]
'o,'str[4:]
'o,world'str[-1]
'd'str[::2]
'hlowrd'
```
列表
列表的创建
name_list = ['alex', 'seven', 'eric']
或:
name_list = list(['alex', 'seven', 'eric'])
列表的操作:
- 列表的取值
列表的取值是通过下标来取值的,下标默认从0开始
name_list = ['alex','seven','eric']
name_list[0]
'alex'
```
列表的切片
列表的切片和字符串的切片方法完全相同,请参照字符串切片列表的插入
L.insert(index, object) 在index之前插入一个元素
name_list = ['alex','seven','eric']
name_list.insert(2,'tom')
name_list
['alex', 'seven', 'tom', 'eric']
```
- 列表的删除
L.remove(value) 去除这个列表第一个出现的 value.如果value不存在会报ValueError错误
name_list.remove('tom')
name_list
['alex', 'seven', 'eric']
```
L.pop([index]) 去除下标为index的元素并返回这个元素(默认为最后一个元素).如果列表为空或者下标超出范围将会报IndexError错误.
```
name_list
['alex', 'seven', 'eric']name_list.pop()
'eric'name_list
['alex', 'seven']name_list.pop(0)
'alex'name_list
['seven']
```
- 列表的追加
L.append(object) 追加一个元素到列表末尾
name_list
['seven']name_list.append('jerry')
name_list
['seven', 'jerry']
```
- 列表元素的统计
L.count(value) -> 返回value元素的数量
name_list
['alex', 'seven', 'eric', 'jerry', 'alex']name_list.count('alex')
2
```
- 获取元素的下标
L.index(value, [start, [stop]]) 返回找到的第一个元素的下标,如果这个value元素不存在则会报ValueError错误.
name_list
['alex', 'seven', 'eric', 'jerry', 'alex']name_list.index('alex')
0
```
- 列表排序
在2.x的Python,如果列表里有数字和字符串,是可以排序的,按照ASCII码的顺序排,在Python3.X 会报错。
name_list
['alex', 'seven', 'eric', 'jerry', 'alex']name_list.sort()
name_list
['alex', 'alex', 'eric', 'jerry', 'seven']
```
列表反转
name_list
['alex', 'alex', 'eric', 'jerry', 'seven']name_list.reverse()
name_list
['seven', 'jerry', 'eric', 'alex', 'alex']
```
列表的扩展
>>> name_list
['seven', 'jerry', 'eric', 'alex', 'alex']
names = ['tom','jack','rose']
name_list.extend(names)
name_list
['seven', 'jerry', 'eric', 'alex', 'alex', 'tom', 'jack', 'rose']
```
元组(不可变列表)
元组的创建:
numbers = (11, 22, 33, 44, 55)
或:
numbers = tuple((11, 22, 33, 44, 55))
元组的操作:
- 统计元素数量
T.count(value) 返回元素vaule的数量
numbers = (10,22,32,43,88,10)
numbers.count(10)
2
```
- 找出元素的下标
T.index(value, [start, [stop]]) -> integer -- 返回找到的第一个元素的下标. 如果这个元素不存在会报ValueError错误.
numbers = (10,22,32,43,88,10)
numbers.index(10)
0
```
字典(无序)
创建字典:
person = {"name": "tom", 'age': 18}
或:
person = dict({"name": "tom", 'age': 18})
字典的操作:
- 获取key的值
D.get(k[,d]) -> D[k] if k in D, else d. d defaults to None.
person = {'name':'tom','age':18} #创建一个字典
person.get('name') #获取字典key为name的值
'tom'person.get('sex') #获取字典key为sex的值,如果 key不存在,不报错,什么也不返回
person.get('sex',None) #可以设置一个默认的值,如果key不存在,返回默认的值
Noneperson['name'] #也可以通过[]的方式获取key的值
'tom'person['sex'] #如果key不存在会报错
Traceback (most recent call last):
File "", line 1, in
person['sex']
KeyError: 'sex'
```
获取字典中的所有key
person.keys()
dict_keys(['name', 'age'])
```
获取字典中的所有value
person.values()
dict_values(['tom', 18])
```
将字典转换为[(key,value),(key,value)...]
person.items()
dict_items([('name', 'tom'), ('age', 18)])
```
删除字典内所有元素
person.clear()
person
{}
```
- 删除字典内某一个元素
person = {'name':'tom','age':18}
person.pop('age')
18
```
把字典dict2的键/值对更新到dict里
person = {'name':'tom','age':18}
single = {'sex':'f','phone':'13231012345'}
person.update(single)
person
{'phone': '13231012345', 'name': 'tom', 'sex': 'f', 'age': 18}
```
- 创建一个新字典
dict.fromkeys(S[,v]) 创建一个新字典,这个字典的所有的keys都来自己于S,所有的值都是v
fields = ['id','name','age']
person = {}
person.fromkeys(fields,None)
{'age': None, 'id': None, 'name': None}
```
- **获取key的值,如果这个字典中key不存在,则会增加一个元素D[k] = d **
D.setdefault(k[,d]) -> D.get(k,d), also set D[k]=d if k not in D
person = {'name':'tom','age':18}
person.setdefault('country','China')
'China'person
{'age': 18, 'name': 'tom', 'country': 'China'}
```
- 浅复制字典
D.copy() D字典的浅复制 ,只会复制第一层,第二层不会(我觉得应该是第一层字典存的是第二层字典的地址,copy的时候只是把这个地址copy过去,但还是指向相同的地方,所以当第一个字典改变第二层的值的时候,第二个字典也跟着变了)
person = {'name':'tom','age':18,'addr':{'country':'China','province':'Hebei'}}
single = person.copy()
person
{'addr': {'country': 'China', 'province': 'Hebei'}, 'name': 'tom', 'age': 18}single
{'addr': {'country': 'China', 'province': 'Hebei'}, 'name': 'tom', 'age': 18}person['name'] = 'jerry'
person
{'addr': {'country': 'China', 'province': 'Hebei'}, 'name': 'jerry', 'age': 18}single
{'addr': {'country': 'China', 'province': 'Hebei'}, 'name': 'tom', 'age': 18}person['addr']['country'] = 'America'
person
{'addr': {'country': 'America', 'province': 'Hebei'}, 'name': 'jerry', 'age': 18}single
{'addr': {'country': 'America', 'province': 'Hebei'}, 'name': 'tom', 'age': 18}
```
数据运算
算数运算
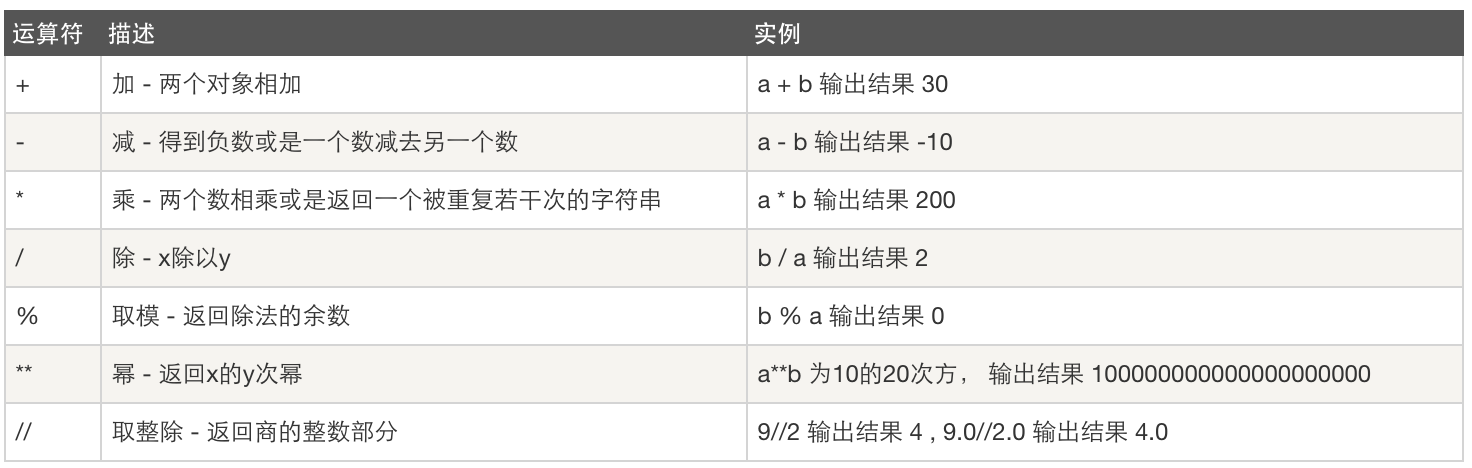
比较运算

赋值运算
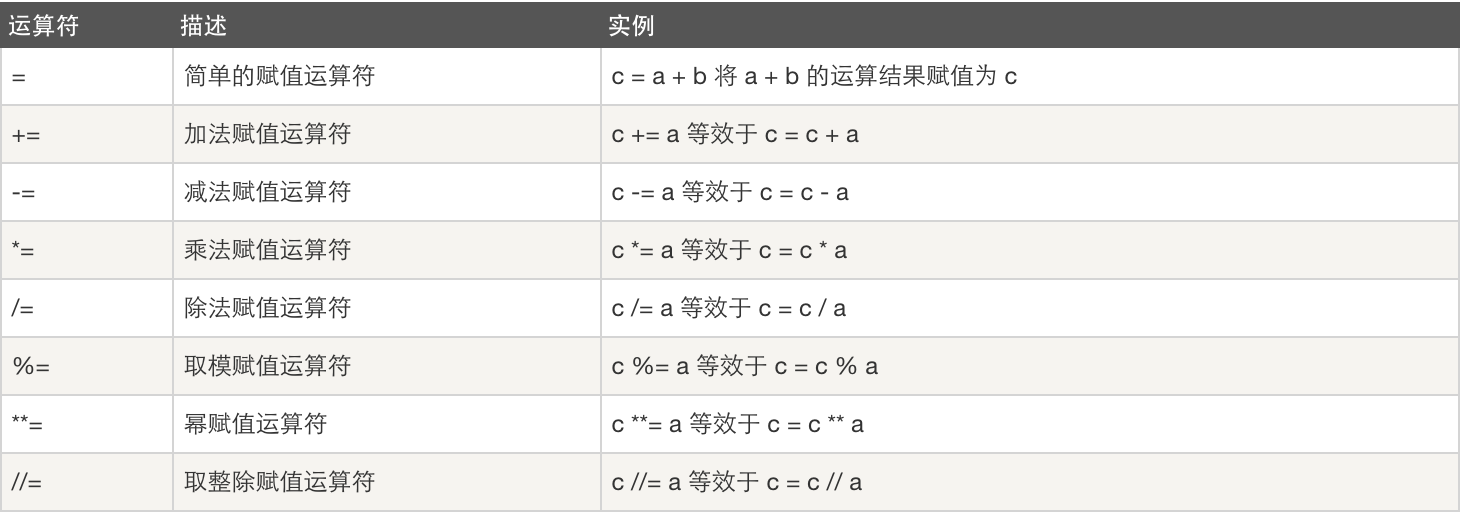
逻辑运算

成员运算

身份运算

位运算
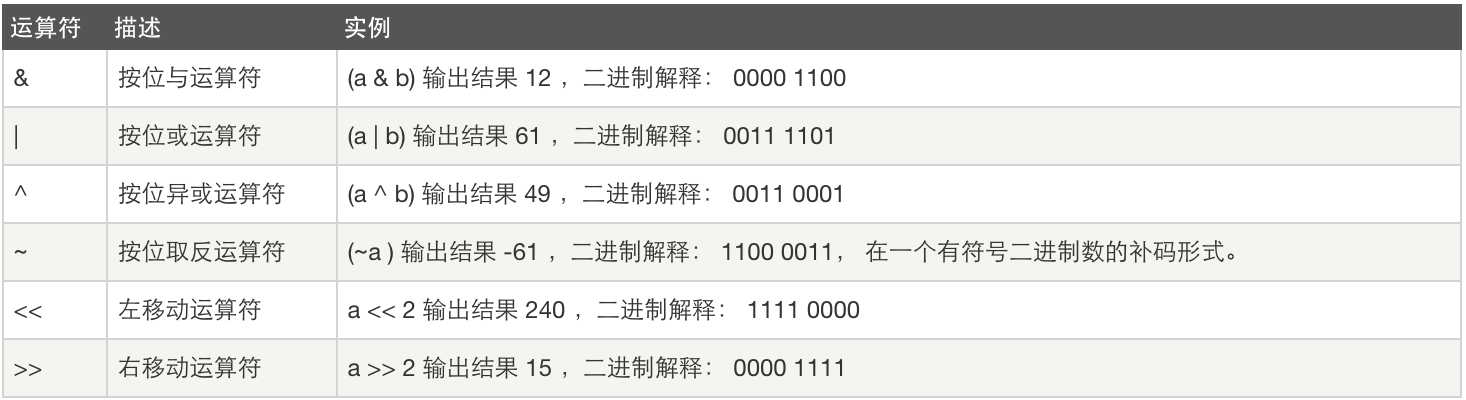
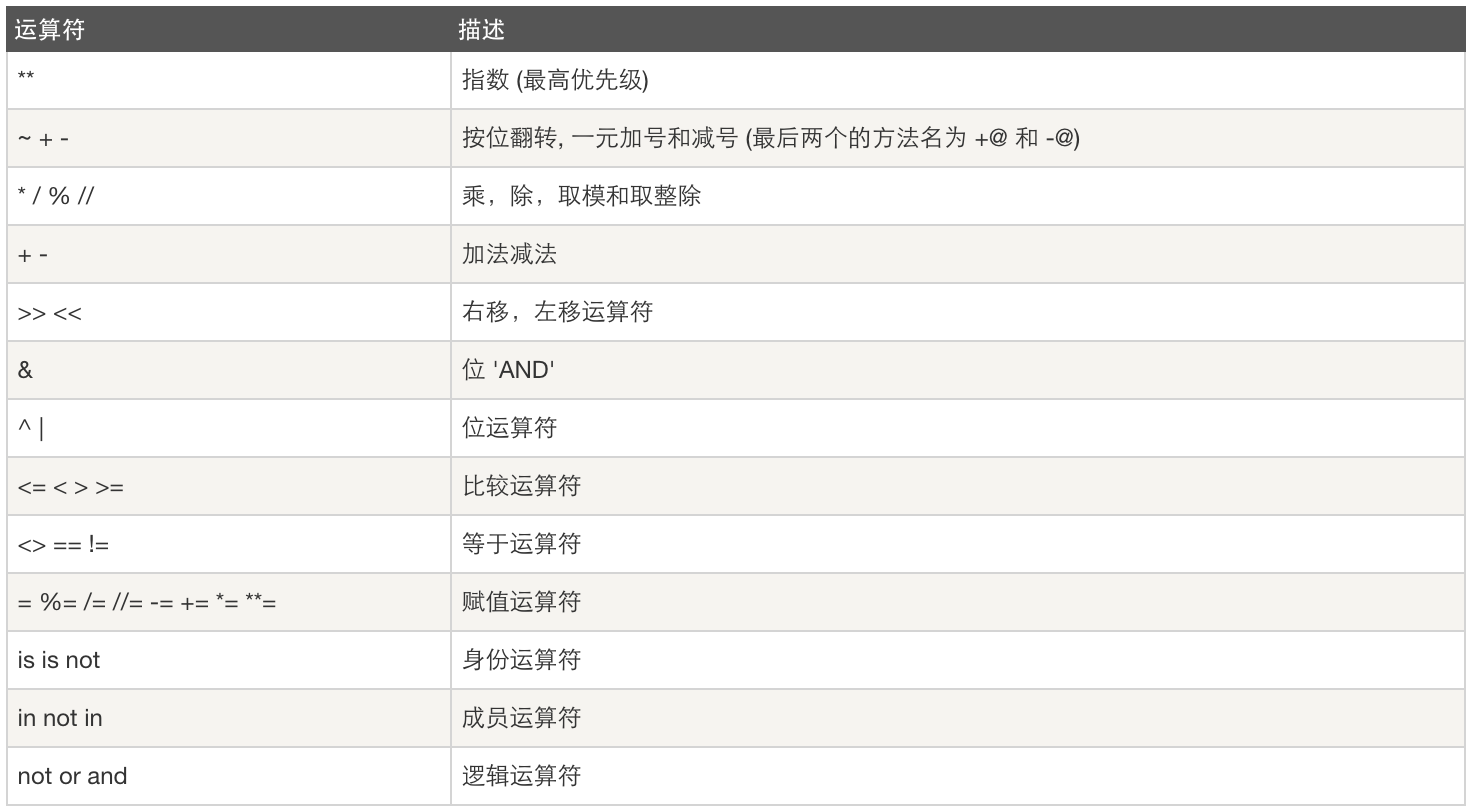
运算优先级
Python之路第二天,基础(2)-基本数据类型的更多相关文章
- python之路第二篇(基础篇)
入门知识: 一.关于作用域: 对于变量的作用域,执行声明并在内存中存在,该变量就可以在下面的代码中使用. if 10 == 10: name = 'allen' print name 以下结论对吗? ...
- Python之路(第二篇):Python基本数据类型字符串(一)
一.基础 1.编码 UTF-8:中文占3个字节 GBK:中文占2个字节 Unicode.UTF-8.GBK三者关系 ascii码是只能表示英文字符,用8个字节表示英文,unicode是统一码,世界通用 ...
- Python之路,day3-Python基础
三级菜单 menu = { '北京':{ '海淀':{ '五道口':{ 'soho':{}, '网易':{}, 'google':{} }, '中关村':{ '爱奇艺':{}, '汽车之家':{}, ...
- python自动化开发-[第二天]-基础数据类型与编码(续)
今日简介: - 编码 - 进制转换 - 初识对象 - 基本的数据类型 - 整数 - 布尔值 - 字符串 - 列表 - 元祖 - 字典 - 集合 - range/enumcate 一.编码 encode ...
- Python之路(第二十九篇) 面向对象进阶:内置方法补充、异常处理
一.__new__方法 __init__()是初始化方法,__new__()方法是构造方法,创建一个新的对象 实例化对象的时候,调用__init__()初始化之前,先调用了__new__()方法 __ ...
- Python之路(第二十八篇) 面向对象进阶:类的装饰器、元类
一.类的装饰器 类作为一个对象,也可以被装饰. 例子 def wrap(obj): print("装饰器-----") obj.x = 1 obj.y = 3 obj.z = 5 ...
- Python之路(第二十五篇) 面向对象初级:反射、内置方法
[TOC] 一.反射 反射的概念是由Smith在1982年首次提出的,主要是指程序可以访问.检测和修改它本身状态或行为的一种能力(自省).这一概念的提出很快引发了计算机科学领域关于应用反射性的研究.它 ...
- Python之路(第二十四篇) 面向对象初级:多态、封装
一.多态 多态 多态:一类事物有多种形态,同一种事物的多种形态,动物分为鸡类,猪类.狗类 例子 import abc class H2o(metaclass=abc.ABCMeta): def _ ...
- Python之路(第二十三篇) 面向对象初级:静态属性、静态方法、类方法
一.静态属性 静态属性相当于数据属性. 用@property语法糖装饰器将类的函数属性变成可以不用加括号直接的类似数据属性. 可以封装逻辑,让用户感觉是在调用一个普通的数据属性. 例子 class R ...
随机推荐
- C语言结构体(struct)常见使用方法
基本定义:结构体,通俗讲就像是打包封装,把一些变量有共同特征(比如同属于某一类事物的属性)的变量封装在内部,通过一定方法访问修改内部变量. 结构体定义: 第一种:只有结构体定义 struct stuf ...
- 兼容IE与firefox、chrome的css 线性渐变(linear-gradient)
现行渐变首先看下示例(1)垂直渐变 (2)垂直渐变 IE系列 filter: progid:DXImageTransform.Microsoft.Gradient(startColorStr='#FF ...
- Jasper_pass data_from main report to subReport (local CSV)
<dataSourceExpression><![CDATA[$P{REPORT_DATA_SOURCE}]]></dataSourceExpression>< ...
- MySQL 学习笔记 (范式)
范式基本就是不要有重复的数据,表和表之间都是用主键和外键来联系 表的关系通常分3中 1 对 1 1 对 多 多 对 多 多 对 多 是用另一个表来实现的,这个表记入了a 表和 b表之间多对多的联系主键
- Linux cat和EOF的使用
在某些场合,可能我们需要在脚本中生成一个临时文件,然后把该文件作为最终文件放入目录中.(可参考ntop.spec文件)这样有几个好处,其中之一就是临时文件不是唯一的,可以通过变量赋值,也可根据不同的判 ...
- testNg官方文档
官方文档:http://testng.org/doc/documentation-main.html
- Ubuntu 无线连接能上网,但是有线连接不能上
这两天装Ubuntu,遇到小问题.最头疼的还是上网,过去我装了Ubuntu时,都是插上网线就能直接上网,这次就不行了. 我刚点开一个网页,接下来点就不能上了,但是无线连接就可以正常上网. 我在一个论坛 ...
- java servlet+jquery+json学习小例子
引入JSON的jar包: 注意,如果包不全,页面请求servlet时,jquery ajax会返回error:function 弹出error occured!!! HTML Code: <%@ ...
- 由mysql数据库基础上的php程序实现单词的查询、删除、更改和查询
我做了一个php程序,将表单数据添加到数据库,借用mysql扩展库函数实现对mysql数据库的操作,能够实现添加单词.删除单词.更新和查询单词.运行环境是普通的mysql数据库和php.Apache服 ...
- 解决 Google 重定向,体验 Google 本味
想要体验原汁原味的 Google(google.com),下面的方案是我用过的较方便的方案. 欢迎更正及补充 Chrome 扩展 Chrone 商店有一款禁止重定向的扩展 NoCountryRedir ...