Lucene学习总结之六:Lucene打分公式的数学推导
在进行Lucene的搜索过程解析之前,有必要单独的一张把Lucene score公式的推导,各部分的意义阐述一下。因为Lucene的搜索过程,很重要的一个步骤就是逐步的计算各部分的分数。
Lucene的打分公式非常复杂,如下:
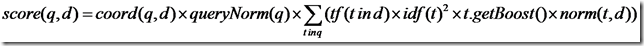
在推导之前,先逐个介绍每部分的意义:
- t:Term,这里的Term是指包含域信息的Term,也即title:hello和content:hello是不同的Term
- coord(q,d):一次搜索可能包含多个搜索词,而一篇文档中也可能包含多个搜索词,此项表示,当一篇文档中包含的搜索词越多,则此文档则打分越高。
- queryNorm(q):计算每个查询条目的方差和,此值并不影响排序,而仅仅使得不同的query之间的分数可以比较。其公式如下:
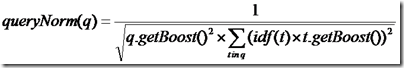
- tf(t in d):Term t在文档d中出现的词频
- idf(t):Term t在几篇文档中出现过
- norm(t, d):标准化因子,它包括三个参数:
- Document boost:此值越大,说明此文档越重要。
- Field boost:此域越大,说明此域越重要。
- lengthNorm(field) = (1.0 / Math.sqrt(numTerms)):一个域中包含的Term总数越多,也即文档越长,此值越小,文档越短,此值越大。

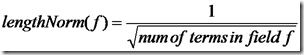
- 各类Boost值
- t.getBoost():查询语句中每个词的权重,可以在查询中设定某个词更加重要,common^4 hello
- d.getBoost():文档权重,在索引阶段写入nrm文件,表明某些文档比其他文档更重要。
- f.getBoost():域的权重,在索引阶段写入nrm文件,表明某些域比其他的域更重要。
以上在Lucene的文档中已经详细提到,并在很多文章中也被阐述过,如何调整上面的各部分,以影响文档的打分,请参考有关Lucene的问题(4):影响Lucene对文档打分的四种方式一文。
然而上面各部分为什么要这样计算在一起呢?这么复杂的公式是怎么得出来的呢?下面我们来推导。
首先,将以上各部分代入score(q, d)公式,将得到一个非常复杂的公式,让我们忽略所有的boost,因为这些属于人为的调整,也省略coord,这和公式所要表达的原理无关。得到下面的公式:

然后,有Lucene学习总结之一:全文检索的基本原理中的描述我们知道,Lucene的打分机制是采用向量空间模型的:
我们把文档看作一系列词(Term),每一个词(Term)都有一个权重(Term weight),不同的词(Term)根据自己在文档中的权重来影响文档相关性的打分计算。
于是我们把所有此文档中词(term)的权重(term weight) 看作一个向量。
Document = {term1, term2, …… ,term N}
Document Vector = {weight1, weight2, …… ,weight N}
同样我们把查询语句看作一个简单的文档,也用向量来表示。
Query = {term1, term 2, …… , term N}
Query Vector = {weight1, weight2, …… , weight N}
我们把所有搜索出的文档向量及查询向量放到一个N维空间中,每个词(term)是一维。

我们认为两个向量之间的夹角越小,相关性越大。
所以我们计算夹角的余弦值作为相关性的打分,夹角越小,余弦值越大,打分越高,相关性越大。
余弦公式如下:
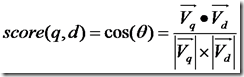
下面我们假设:
查询向量为Vq = <w(t1, q), w(t2, q), ……, w(tn, q)>
文档向量为Vd = <w(t1, d), w(t2, d), ……, w(tn, d)>
向量空间维数为n,是查询语句和文档的并集的长度,当某个Term不在查询语句中出现的时候,w(t, q)为零,当某个Term不在文档中出现的时候,w(t, d)为零。
w代表weight,计算公式一般为tf*idf。
我们首先计算余弦公式的分子部分,也即两个向量的点积:
Vq*Vd = w(t1, q)*w(t1, d) + w(t2, q)*w(t2, d) + …… + w(tn ,q)*w(tn, d)
把w的公式代入,则为
Vq*Vd = tf(t1, q)*idf(t1, q)*tf(t1, d)*idf(t1, d) + tf(t2, q)*idf(t2, q)*tf(t2, d)*idf(t2, d) + …… + tf(tn ,q)*idf(tn, q)*tf(tn, d)*idf(tn, d)
在这里有三点需要指出:
- 由于是点积,则此处的t1, t2, ……, tn只有查询语句和文档的并集有非零值,只在查询语句出现的或只在文档中出现的Term的项的值为零。
- 在查询的时候,很少有人会在查询语句中输入同样的词,因而可以假设tf(t, q)都为1
- idf是指Term在多少篇文档中出现过,其中也包括查询语句这篇小文档,因而idf(t, q)和idf(t, d)其实是一样的,是索引中的文档总数加一,当索引中的文档总数足够大的时候,查询语句这篇小文档可以忽略,因而可以假设idf(t, q) = idf(t, d) = idf(t)
基于上述三点,点积公式为:
Vq*Vd = tf(t1, d) * idf(t1) * idf(t1) + tf(t2, d) * idf(t2) * idf(t2) + …… + tf(tn, d) * idf(tn) * idf(tn)
所以余弦公式变为:
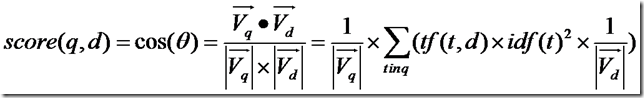
下面要推导的就是查询语句的长度了。
由上面的讨论,查询语句中tf都为1,idf都忽略查询语句这篇小文档,得到如下公式
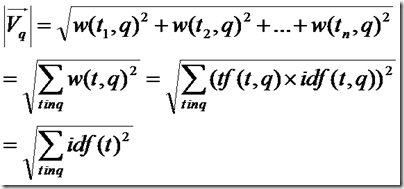
所以余弦公式变为:

下面推导的就是文档的长度了,本来文档长度的公式应该如下:
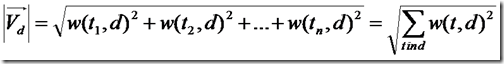
这里需要讨论的是,为什么在打分过程中,需要除以文档的长度呢?
因为在索引中,不同的文档长度不一样,很显然,对于任意一个term,在长的文档中的tf要大的多,因而分数也越高,这样对小的文档不公平,举一个极端的例子,在一篇1000万个词的鸿篇巨著中,"lucene"这个词出现了11次,而在一篇12个词的短小文档中,"lucene"这个词出现了10次,如果不考虑长度在内,当然鸿篇巨著应该分数更高,然而显然这篇小文档才是真正关注"lucene"的。
然而如果按照标准的余弦计算公式,完全消除文档长度的影响,则又对长文档不公平(毕竟它是包含了更多的信息),偏向于首先返回短小的文档的,这样在实际应用中使得搜索结果很难看。
所以在Lucene中,Similarity的lengthNorm接口是开放出来,用户可以根据自己应用的需要,改写lengthNorm的计算公式。比如我想做一个经济学论文的搜索系统,经过一定时间的调研,发现大多数的经济学论文的长度在8000到10000词,因而lengthNorm的公式应该是一个倒抛物线型的,8000到 10000词的论文分数最高,更短或更长的分数都应该偏低,方能够返回给用户最好的数据。
在默认状况下,Lucene采用DefaultSimilarity,认为在计算文档的向量长度的时候,每个Term的权重就不再考虑在内了,而是全部为一。
而从Term的定义我们可以知道,Term是包含域信息的,也即title:hello和content:hello是不同的Term,也即一个Term只可能在文档中的一个域中出现。
所以文档长度的公式为:
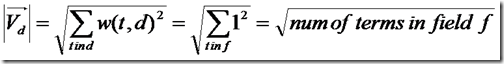
代入余弦公式:
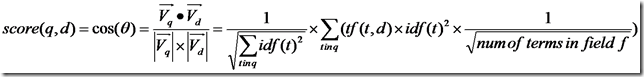
再加上各种boost和coord,则可得出Lucene的打分计算公式。
Lucene学习总结之六:Lucene打分公式的数学推导的更多相关文章
- Lucene学习总结之六:Lucene打分公式的数学推导 2014-06-25 14:20 384人阅读 评论(0) 收藏
在进行Lucene的搜索过程解析之前,有必要单独的一张把Lucene score公式的推导,各部分的意义阐述一下.因为Lucene的搜索过程,很重要的一个步骤就是逐步的计算各部分的分数. Lucene ...
- Lucene打分公式的数学推导
原文出自:http://www.cnblogs.com/forfuture1978/archive/2010/03/07/1680007.html 在进行Lucene的搜索过程解析之前,有必要单独的一 ...
- Lucene学习之四:Lucene的索引文件格式(3)
本文转载自:http://www.cnblogs.com/forfuture1978/archive/2010/02/02/1661436.html ,略有删改和备注. 四.具体格式 4.2. 反向信 ...
- Lucene学习之四:Lucene的索引文件格式(2)
本文转载自:http://www.cnblogs.com/forfuture1978/archive/2009/12/14/1623599.html 略有删减和补充 四.具体格式 上面曾经交代过,L ...
- Lucene学习之四:Lucene的索引文件格式(1)
本文转载自:http://www.cnblogs.com/forfuture1978/archive/2009/12/14/1623597.html Lucene的索引里面存了些什么,如何存放的,也即 ...
- Lucene学习总结之七:Lucene搜索过程解析
一.Lucene搜索过程总论 搜索的过程总的来说就是将词典及倒排表信息从索引中读出来,根据用户输入的查询语句合并倒排表,得到结果文档集并对文档进行打分的过程. 其可用如下图示: 总共包括以下几个过程: ...
- Lucene学习总结之七:Lucene搜索过程解析 2014-06-25 14:23 863人阅读 评论(1) 收藏
一.Lucene搜索过程总论 搜索的过程总的来说就是将词典及倒排表信息从索引中读出来,根据用户输入的查询语句合并倒排表,得到结果文档集并对文档进行打分的过程. 其可用如下图示: 总共包括以下几个过程: ...
- Lucene学习总结:全文检索的基本原理
一.总论 根据http://lucene.apache.org/java/docs/index.html定义: Lucene是一个高效的,基于Java的全文检索库. 所以在了解Lucene之前要费一番 ...
- Lucene学习笔记: 五,Lucene搜索过程解析
一.Lucene搜索过程总论 搜索的过程总的来说就是将词典及倒排表信息从索引中读出来,根据用户输入的查询语句合并倒排表,得到结果文档集并对文档进行打分的过程. 其可用如下图示: 总共包括以下几个过程: ...
随机推荐
- Android-1
@String 支持多语言 layout中的text文本中String都尽量定义在String.xml中,便于多语言管理. <resources> <string name=&quo ...
- requestAnimationFrame动画方法
一.动画方式 在HTML5/CSS3时代,实现动画的方式有许多种: 你可以用css3的animation和@keyframes: 可以用css3的transition: 还可以用原始的setTimeo ...
- str_翻转字符串
1. 给一个句子,翻转每个单词,单词内部不翻转 $str = "dog loves pig"; $ret = turnSentence($str); var_dump($ret); ...
- 转载收藏之用 - 微信公众平台开发教程(四):Hello World
这一篇文章其实可以写在很前面,不过我还是希望开发者们尽多地了解清楚原理之后再下手. 通过上一篇Senparc.Weixin.MP SDK 微信公众平台开发教程(三):微信公众平台开发验证,我们已经使微 ...
- bzoj 1912 巡逻(树直径)
Description Input 第一行包含两个整数 n, K(1 ≤ K ≤ 2).接下来 n – 1行,每行两个整数 a, b, 表示村庄a与b之间有一条道路(1 ≤ a, b ≤ n). Ou ...
- Android添加横线和竖线分割界面
竖线 <View android:layout_width="1dip" android:layout_height="match_parent ...
- Unix/Linux环境C编程入门教程(40) 初识文件操作
1.函数介绍 close(关闭文件) 相关函数 open,fcntl,shutdown,unlink,fclose 表头文件 #include<unistd.h> 定义函数 int ...
- 怎样合并排序数组(How to merge 2 sorted arrays?)
Question: We have 2 sorted arrays and we want to combine them into a single sorted array. Input: arr ...
- DBA 经典面试题(3)
这里的回答并不是十分全面,这些问题可以通过多个角度来进行解释,也许你不必在面试过程中给出完全详尽的答案,只需要通过你的解答使面试考官了解你对ORACLE概念的熟悉程度. 1.解释冷备份和热备份的不 ...
- web前端之 HTML标签详细介绍
html标签的分类 点我查看完整的html标签介绍 在html中,标签一般分为块级标签和行内标签 块级标签:块元素一般都从新行开始,它可以容纳内联元素和其他块元素,常见块元素是段落标签"p& ...