Hive 7、Hive 的内表、外表、分区(22)
Hive 7、Hive 的内表、外表、分区
1、Hive的内表
Hive 的内表,就是正常创建的表,在 http://www.cnblogs.com/raphael5200/p/5208437.html 中已经提到;
2、Hive的外表
创建Hive 的外表,需要使用关键字 External:

CREATE EXTERNAL TABLE [IF NOT EXISTS] [db_name.]table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[SKEWED BY (col_name, col_name, ...)
ON ((col_value, col_value, ...), (col_value, col_value, ...), ...)
[STORED AS DIRECTORIES]
[
[ROW FORMAT row_format]
下面看一个例子:
create External table food_ex
(
id int,
name string,
category string,
price double
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
lines terminated by '\n';
-- 加载数据
load data local inpath '/opt/food.txt' overwrite into table food_ex;
select * from food_ex;


这两个,左边是外表,右边是内表从大体上看似乎没什么区别,但是他的主要区别在于删除操作上:
内表删除表或者分区元数据和数据都删了
外表删除表元数据删除,数据保留
下面分别执行两条语句:
drop table food;
drop table food_ex;
执行这两条语句以后,两个表都删除了,但是结果却不一样,访问NameNode的50070端口:

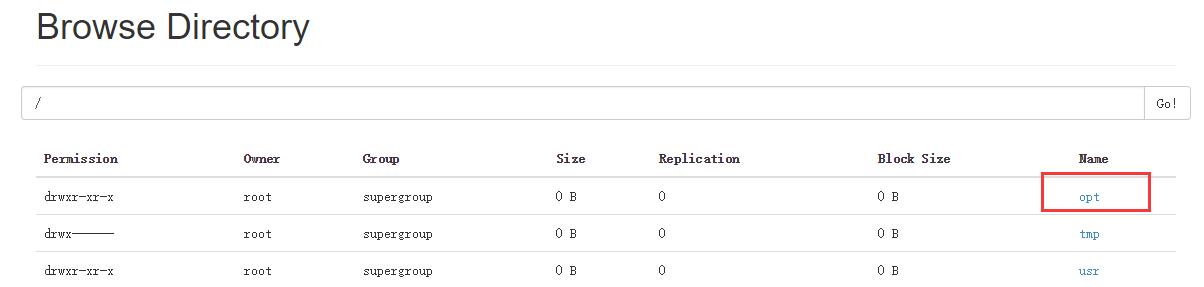


可以看到,虽然都执行了表删除语句,内表删除后是把元数据和数据都删除了,而外表却只删除了元数据(表的信息)但真实数据却保留了下来;
3、Hive的分区partition
必须在表定义时创建partition
a、单分区建表语句:
create table day_table (id int, content string)
partitioned by (dt string);
单分区表,按天分区,在表结构中存在id,content,dt三列。 以dt为文件夹区分
例:
create table log_info
(
ip string
)
PARTITIONED BY(times string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
lines terminated by '\n';
# 下面是log_info 的表结构信息,分区已经创建
hive> desc log_info;
OK
ip string
times string # Partition Information
# col_name data_type comment times string
Time taken: 0.077 seconds, Fetched: 7 row(s)
b、 双分区建表语句:
create table day_hour_table (id int, content string)
partitioned by (dt string, hour string);
双分区表,按天和小时分区,在表结构中新增加了dt和hour两列。 先以dt为文件夹,再以hour子文件夹区分
create table log_info2
(
ip string
)
PARTITIONED BY(days string,hours string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
lines terminated by '\n';
# 下面是log_info2 的表结构信息,分区已经创建
hive> desc log_info2;
OK
ip string
days string
hours string # Partition Information
# col_name data_type comment days string
hours string
Time taken: 0.08 seconds, Fetched: 9 row(s)
c、Hive添加分区表语法 (表已创建,在此基础上添加分区):
ALTER TABLE table_name ADDpartition_spec
[ LOCATION 'location1' ]
partition_spec [ LOCATION 'location2' ] ...
ALTER TABLE day_table
ADDPARTITION (dt='2008-08-08', hour='08')
location '/path/pv1.txt'
d、Hive删除分区语法:
ALTER TABLE table_name DROP PARTITION partition_spec, partition_spec,...
用户可以用 ALTER TABLE DROP PARTITION 来删除分区。分区的元数据和数据将被一并删除。例:
ALTER TABLE day_hour_table DROP PARTITION (dt='2008-08-08', hour='09');
alter table log_info drop partition (times='20160222');
e、Hive数据加载进分区表中语法:
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
例:
单分区数据加载
load data local inpath '/opt/log' overwrite into table log_info partition(times='20160223');
load data local inpath '/opt/log2' overwrite into table log_info partition(times='20160222');
hive> select * from log_info;
OK
23.45.66.77 20160222
45.66.11.8
20160222
2.3.4.5 20160223
4.56.77.31 20160223
34.55.6.77
20160223
34.66.11.6 20160223
Time taken: 0.125 seconds, Fetched: 6
row(s)
在Hive中会根据分区的名称新建两个分区目录
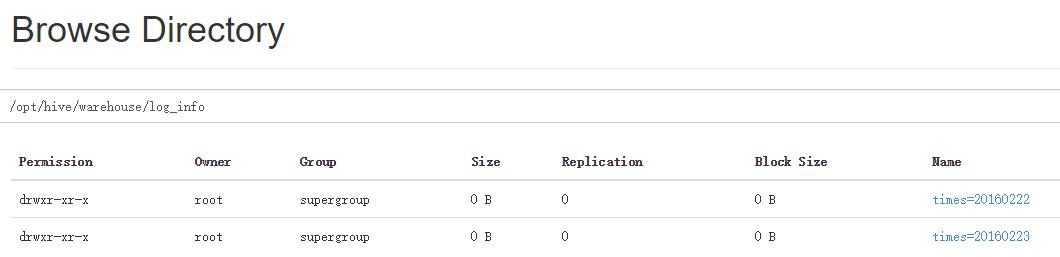
双分区数据加载
load data local inpath '/opt/log3' overwrite into table log_info2 partition(days='23',hours='12');
hive> select * from log_info2;
OK
12.3.33.66 23 12
23.44.56.6 23 12
12.22.33.4 23 12
8.78.99.4 23 12
233.23.211.2 23 12
Time taken: 0.069 seconds, Fetched: 5 row(s)

当数据被加载至表中时,不会对数据进行任何转换。Load操作只是将数据复制至Hive表对应的位置。数据加载时在表下自动创建一个目录 基于分区的查询的语句:
SELECT day_table.* FROM day_table WHERE day_table.dt>= '2008-08-08';
f、Hive查看分区语句:
hive> show partitions day_hour_table;
OK
dt=2008-08-08/hour=08
dt=2008-08-08/hour=09
dt=2008-08-09/hour=09
hive> show partitions log_info;
OK
times=20160222
times=20160223
Time taken: 0.06 seconds, Fetched: 2 row(s)
Hive 7、Hive 的内表、外表、分区(22)的更多相关文章
- 分析Hive表和分区的统计信息(Statistics)
类似于Oracle的分析表,Hive中也提供了分析表和分区的功能,通过自动和手动分析Hive表,将Hive表的一些统计信息存储到元数据中. 表和分区的统计信息主要包括:行数.文件数.原始数据大小.所占 ...
- Hive 官方手册翻译 -- Hive Transactions (Hive 事务)
由 Alan Gates创建, 最终由 Andrew Sherman修改于2018年8月7日 原文链接:https://cwiki.apache.org/confluence/display/Hive ...
- Hive 7、Hive 的内表、外表、分区
1.Hive的内表 Hive 的内表,就是正常创建的表,在 http://www.cnblogs.com/raphael5200/p/5208437.html 中已经提到: 2.Hive的外表 创建H ...
- Hive内表和外表的区别
本文以例子的形式介绍一下Hive内表和外表的区别.例子共有4个:不带分区的内表.带分区的内表.不带分区的外表.带分区的外表. 1 不带分区的内表 #创建表 create table innerTabl ...
- hive内表和外表的创建、载入数据、区别
创建表 创建内表 create table customer( customerId int, firstName string, lastName STRING, birstDay timestam ...
- Hive的内表和外表以及分区表
1. 内表和外表的区别 内表和外表之间是通过关键字EXTERNAL来区分.删除表时: 内表:在删除时,既删除内表的元数据,也删除内表的数据 外表:删除时,仅仅删除外表的元数据. CREATE [EXT ...
- Hive 文件格式 & Hive操作(外部表、内部表、区、桶、视图、索引、join用法、内置操作符与函数、复合类型、用户自定义函数UDF、查询优化和权限控制)
本博文的主要内容如下: Hive文件存储格式 Hive 操作之表操作:创建外.内部表 Hive操作之表操作:表查询 Hive操作之表操作:数据加载 Hive操作之表操作:插入单表.插入多表 Hive语 ...
- Hive 表操作(HIVE的数据存储、数据库、表、分区、分桶)
1.Hive的数据存储 Hive的数据存储基于Hadoop HDFS Hive没有专门的数据存储格式 存储结构主要包括:数据库.文件.表.试图 Hive默认可以直接加载文本文件(TextFile),还 ...
- Hive Experiment 2(表动态分区和IDE)
1.使用oracle sql developer 4.0.3作为hive query的IDE. 下载hive-jdbc driver http://www.cloudera.com/content/c ...
随机推荐
- uploadify上传大文件时出现404错误
出现这个错误的话一般是IIs限制了文件大小.IIS7下的默认设置限制了上传大小.这个时候Web.Config中的大小设置也就失效了.具体步骤:1.打开IIS管理器,找到Default Web Site ...
- MM32Flash读写操作(兼容STM32)
MM32Flash读写操作(兼容STM32) Flash基础描述 思维导图 编程实现读写操作 主函数结构 #include "delay.h" #include "sys ...
- web02--jsp数据传递
1.创建一个login.jsp登陆界面 <%@ page language="java" import="java.util.*" pageEncodin ...
- 深入理解 CSS变形 transform(3d)
坐标轴 在了解透视之前,首先要先了解坐标轴.3D变形与2D变形最大的不同就在于其参考的坐标轴不同.2D变形的坐标轴是平面的,只存在x轴和y轴,而3D变形的坐标轴则是x.y.z三条轴组成的立体空间,x轴 ...
- python代码合并
http://www.baidu.com/s?wd=python%E4%BB%A3%E7%A0%81%E5%90%88%E5%B9%B6&rsv_bp=0&ch=&tn=mon ...
- 执行CMD命令
可以执行多条命令,用“\r\n”分割 using System; using System.Diagnostics; namespace Tool { public class CMDHelper { ...
- TFS统计编码行数语句
****** Script for SelectTopNRows command from SSMS ******/ SELECT TeamProjectProjectNodeName 项目名称 ,c ...
- Lesson 5: Typography in Product Design
Lesson 5: Typography in Product Design Article 1: Interactive Guide to Blog Typography 布局(Layout) 用空 ...
- linux(vi)多行注释和取消注释.
//comment1,'ctrl+v' to VISUAL BLOCK mode.2,'j' or 'k' to select/deselect lines.3,'I' to INSERT mode. ...
- 常用语句1【weber出品】
1.查看控制文件位置: select * from v$controlfile show parameter control; 2.查询日志文件位置 select group#,status,mem ...