机器学习之Adaboost算法原理
转自:http://www.cnblogs.com/pinard/p/6133937.html
在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类,第一个是个体学习器之间存在强依赖关系,另一类是个体学习器之间不存在强依赖关系。前者的代表算法就是是boosting系列算法。在boosting系列算法中, Adaboost是最著名的算法之一。Adaboost既可以用作分类,也可以用作回归。本文就对Adaboost算法做一个总结。
1. 回顾boosting算法的基本原理
在集成学习原理小结中,我们已经讲到了boosting算法系列的基本思想,如下图:

从图中可以看出,Boosting算法的工作机制是首先从训练集用初始权重训练出一个弱学习器1,根据弱学习的学习误差率表现来更新训练样本的权重,使得之前弱学习器1学习误差率高的训练样本点的权重变高,使得这些误差率高的点在后面的弱学习器2中得到更多的重视。然后基于调整权重后的训练集来训练弱学习器2.,如此重复进行,直到弱学习器数达到事先指定的数目T,最终将这T个弱学习器通过集合策略进行整合,得到最终的强学习器。
不过有几个具体的问题Boosting算法没有详细说明。
1)如何计算学习误差率e?
2) 如何得到弱学习器权重系数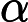 α?
α?
3)如何更新样本权重D?
4) 使用何种结合策略?
只要是boosting大家族的算法,都要解决这4个问题。那么Adaboost是怎么解决的呢?
2. Adaboost算法的基本思路
我们这里讲解Adaboost是如何解决上一节这4个问题的。
假设我们的训练集样本是
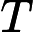

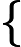

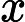
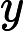

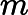
 T={(x,y1),(x2,y2),...(xm,ym)}
T={(x,y1),(x2,y2),...(xm,ym)}训练集的在第k个弱学习器的输出权重为
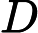
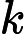
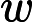
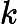
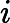
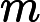
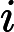
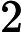 D(k)=(wk1,wk2,...wkm);w1i=1m;i=1,2...m
D(k)=(wk1,wk2,...wkm);w1i=1m;i=1,2...m首先我们看看Adaboost的分类问题。
分类问题的误差率很好理解和计算。由于多元分类是二元分类的推广,这里假设我们是二元分类问题,输出为{-1,1},则第k个弱分类器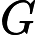 Gk(x)在训练集上的加权误差率为
Gk(x)在训练集上的加权误差率为

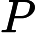
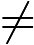


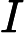 ek=P(Gk(xi)≠yi)=∑i=1mwkiI(Gk(xi)≠yi)
ek=P(Gk(xi)≠yi)=∑i=1mwkiI(Gk(xi)≠yi) 接着我们看弱学习器权重系数,对于二元分类问题,第k个弱分类器Gk(x)的权重系数为


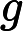
 αk=12log1−ekek
αk=12log1−ekek 为什么这样计算弱学习器权重系数?从上式可以看出,如果分类误差率ek越大,则对应的弱分类器权重系数αk越小。也就是说,误差率小的弱分类器权重系数越大。具体为什么采用这个权重系数公式,我们在讲Adaboost的损失函数优化时再讲。
第三个问题,更新更新样本权重D。假设第k个弱分类器的样本集权重系数为D(k)=(wk1,wk2,...wkm),则对应的第k+1个弱分类器的样本集权重系数为
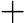
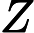
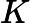
 wk+1,i=wkiZKexp(−αkyiGk(xi))
wk+1,i=wkiZKexp(−αkyiGk(xi)) 这里Zk是规范化因子
Zk=∑i=1mwkiexp(−αkyiGk(xi)) 从wk+1,i计算公式可以看出,如果第i个样本分类错误,则
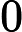 yiGk(xi)<0,导致样本的权重在第k+1个弱分类器中增大,如果分类正确,则权重在第k+1个弱分类器中减少.具体为什么采用样本权重更新公式,我们在讲Adaboost的损失函数优化时再讲。
yiGk(xi)<0,导致样本的权重在第k+1个弱分类器中增大,如果分类正确,则权重在第k+1个弱分类器中减少.具体为什么采用样本权重更新公式,我们在讲Adaboost的损失函数优化时再讲。
最后一个问题是集合策略。Adaboost分类采用的是加权平均法,最终的强分类器为
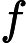
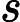
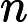 f(x)=sign(∑k=1KαkGk(x))
f(x)=sign(∑k=1KαkGk(x))
接着我们看看Adaboost的回归问题。由于Adaboost的回归问题有很多变种,这里我们以Adaboost R2算法为准。
我们先看看回归问题的误差率的问题,对于第k个弱学习器,计算他在训练集上的最大误差
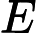

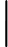 Ek=max|yi−Gk(xi)|i=1,2...m
Ek=max|yi−Gk(xi)|i=1,2...m然后计算每个样本的相对误差
eki=|yi−Gk(xi)|Ek 这里是误差损失为线性时的情况,如果我们用平方误差,则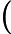
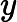
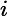

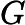
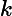
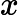
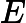 eki=(yi−Gk(xi))2Ek2,如果我们用的是指数误差,则()eki=1−exp(−yi+Gk(xi))Ek)
eki=(yi−Gk(xi))2Ek2,如果我们用的是指数误差,则()eki=1−exp(−yi+Gk(xi))Ek)
最终得到第k个弱学习器的 误差率
ek=∑i=1mwkieki 我们再来看看如何得到弱学习器权重系数α。这里有:
αk=ek1−ek对于更新更新样本权重D,第k+1个弱学习器的样本集权重系数为
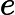 wk+1,i=wkiZkαk1−eki
wk+1,i=wkiZkαk1−eki 这里Zk是规范化因子
Zk=∑i=1mwkiαk1−eki最后是结合策略,和分类问题一样,采用的也是加权平均法,最终的强回归器为
f(x)=∑k=1K(ln1αk)Gk(x)3. AdaBoost分类问题的损失函数优化
刚才上一节我们讲到了分类Adaboost的弱学习器权重系数公式和样本权重更新公式。但是没有解释选择这个公式的原因,让人觉得是魔法公式一样。其实它可以从Adaboost的损失函数推导出来。
从另一个角度讲, Adaboost是模型为加法模型,学习算法为前向分步学习算法,损失函数为指数函数的分类问题。
模型为加法模型好理解,我们的最终的强分类器是若干个弱分类器加权平均而得到的。
前向分步学习算法也好理解,我们的算法是通过一轮轮的弱学习器学习,利用前一个弱学习器的结果来更新后一个弱学习器的训练集权重。也就是说,第k-1轮的强学习器为
fk−1(x)=∑i=1k−1αiGi(x)而第k轮的强学习器为
fk(x)=∑i=1kαiGi(x)上两式一比较可以得到
 fk(x)=fk−1(x)+αkGk(x)
fk(x)=fk−1(x)+αkGk(x)可见强学习器的确是通过前向分步学习算法一步步而得到的。
Adaboost损失函数为指数函数,即定义损失函数为
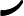
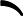
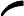

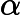 argmin⏟α,G∑i=1mexp(−yifk(x))
argmin⏟α,G∑i=1mexp(−yifk(x))利用前向分步学习算法的关系可以得到损失函数为
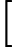
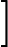 (αk,Gk(x))=argmin⏟α,G∑i=1mexp[(−yi)(fk−1(x)+αG(x))]
(αk,Gk(x))=argmin⏟α,G∑i=1mexp[(−yi)(fk−1(x)+αG(x))] 令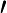 wki′=exp(−yifk−1(x)), 它的值不依赖于α,G,因此与最小化无关,仅仅依赖于fk−1(x),随着每一轮迭代而改变。
wki′=exp(−yifk−1(x)), 它的值不依赖于α,G,因此与最小化无关,仅仅依赖于fk−1(x),随着每一轮迭代而改变。
将这个式子带入损失函数,损失函数转化为
(αk,Gk(x))=argmin⏟α,G∑i=1mwki′exp[−yiαG(x)]
首先,我们求Gk(x).,可以得到
Gk(x)=argmin⏟G∑i=1mwki′I(yi≠G(xi)) 将Gk(x)带入损失函数,并对α求导,使其等于0,则就得到了
αk=12log1−ekek 其中,ek即为我们前面的分类误差率。
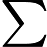 ek=∑i=1mwki′I(yi≠G(xi))∑i=1mwki′=∑i=1mwkiI(yi≠G(xi))
ek=∑i=1mwki′I(yi≠G(xi))∑i=1mwki′=∑i=1mwkiI(yi≠G(xi)) 最后看样本权重的更新。利用fk(x)=fk−1(x)+αkGk(x)和wki′=exp(−yifk−1(x)),即可得:
wk+1,i′=wki′exp[−yiαkGk(x)]这样就得到了我们第二节的样本权重更新公式。
4. AdaBoost二元分类问题算法流程
这里我们对AdaBoost二元分类问题算法流程做一个总结。
输入为样本集T={(x,y1),(x2,y2),...(xm,ym)},输出为{-1, +1},弱分类器算法, 弱分类器迭代次数K。
输出为最终的强分类器f(x)
1) 初始化样本集权重为
D(1)=(w11,w12,...w1m);w1i=1m;i=1,2...m2) 对于k=1,2,...K:
a) 使用具有权重Dk的样本集来训练数据,得到弱分类器Gk(x)
b)计算Gk(x)的分类误差率
ek=P(Gk(xi)≠yi)=∑i=1mwkiI(Gk(xi)≠yi)c) 计算弱分类器的系数
αk=12log1−ekekd) 更新样本集的权重分布
wk+1,i=wkiZKexp(−αkyiGk(xi))i=1,2,...m 这里Zk是规范化因子
Zk=∑i=1mwkiexp(−αkyiGk(xi))3) 构建最终分类器为:
f(x)=sign(∑k=1KαkGk(x))
对于Adaboost多元分类算法,其实原理和二元分类类似,最主要区别在弱分类器的系数上。比如Adaboost SAMME算法,它的弱分类器的系数
 αk=12log1−ekek+log(R−1)
αk=12log1−ekek+log(R−1)其中R为类别数。从上式可以看出,如果是二元分类,R=2,则上式和我们的二元分类算法中的弱分类器的系数一致。
5. Adaboost回归问题的算法流程
这里我们对AdaBoost回归问题算法流程做一个总结。AdaBoost回归算法变种很多,下面的算法为Adaboost R2回归算法过程。
输入为样本集T={(x,y1),(x2,y2),...(xm,ym)},,弱学习器算法, 弱学习器迭代次数K。
输出为最终的强学习器f(x)
1) 初始化样本集权重为
D(1)=(w11,w12,...w1m);w1i=1m;i=1,2...m2) 对于k=1,2,...K:
a) 使用具有权重Dk的样本集来训练数据,得到弱学习器Gk(x)
b) 计算训练集上的最大误差
Ek=max|yi−Gk(xi)|i=1,2...mc) 计算每个样本的相对误差:
如果是线性误差,则 eki=|yi−Gk(xi)|Ek;
eki=|yi−Gk(xi)|Ek;
如果是平方误差,则eki=(yi−Gk(xi))2Ek2
如果是指数误差,则()eki=1−exp(−yi+Gk(xi))Ek)
d) 计算回归误差率
ek=∑i=1mwkiekic) 计算弱学习器的系数
αk=ek1−ekd) 更新样本集的权重分布为
wk+1,i=wkiZkαk1−eki 这里Zk是规范化因子
Zk=∑i=1mwkiαk1−eki3) 构建最终强学习器为:
f(x)=∑k=1K(ln1αk)Gk(x)
6. Adaboost算法的正则化
为了防止Adaboost过拟合,我们通常也会加入正则化项,这个正则化项我们通常称为步长(learning rate)。定义为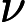 ν,对于前面的弱学习器的迭代
ν,对于前面的弱学习器的迭代
fk(x)=fk−1(x)+αkGk(x)如果我们加上了正则化项,则有
fk(x)=fk−1(x)+ναkGk(x) ν的取值范围为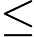 0<ν≤1。对于同样的训练集学习效果,较小的ν意味着我们需要更多的弱学习器的迭代次数。通常我们用步长和迭代最大次数一起来决定算法的拟合效果。
0<ν≤1。对于同样的训练集学习效果,较小的ν意味着我们需要更多的弱学习器的迭代次数。通常我们用步长和迭代最大次数一起来决定算法的拟合效果。
7. Adaboost小结
到这里Adaboost就写完了,前面有一个没有提到,就是弱学习器的类型。理论上任何学习器都可以用于Adaboost.但一般来说,使用最广泛的Adaboost弱学习器是决策树和神经网络。对于决策树,Adaboost分类用了CART分类树,而Adaboost回归用了CART回归树。
这里对Adaboost算法的优缺点做一个总结。
Adaboost的主要优点有:
1)Adaboost作为分类器时,分类精度很高
2)在Adaboost的框架下,可以使用各种回归分类模型来构建弱学习器,非常灵活。
3)作为简单的二元分类器时,构造简单,结果可理解。
4)不容易发生过拟合
Adaboost的主要缺点有:
1)对异常样本敏感,异常样本在迭代中可能会获得较高的权重,影响最终的强学习器的预测准确性。
机器学习之Adaboost算法原理的更多相关文章
- 集成学习值Adaboost算法原理和代码小结(转载)
在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类: 第一个是个体学习器之间存在强依赖关系: 另一类是个体学习器之间不存在强依赖关系. 前者的代表算法就是提升(bo ...
- AdaBoost算法原理简介
AdaBoost算法原理 AdaBoost算法针对不同的训练集训练同一个基本分类器(弱分类器),然后把这些在不同训练集上得到的分类器集合起来,构成一个更强的最终的分类器(强分类器).理论证明,只要每个 ...
- 集成学习之Adaboost算法原理
在boosting系列算法中,Adaboost是最著名的算法之一.Adaboost既可以用作分类,也可以用作回归. 1. boosting算法基本原理 集成学习原理中,boosting系列算法的思想:
- 集成学习之Adaboost算法原理小结
在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类,第一个是个体学习器之间存在强依赖关系,另一类是个体学习器之间不存在强依赖关系.前者的代表算法就是是boostin ...
- AdaBoost算法原理及OpenCV实例
备注:OpenCV版本 2.4.10 在数据的挖掘和分析中,最基本和首要的任务是对数据进行分类,解决这个问题的常用方法是机器学习技术.通过使用已知实例集合中所有样本的属性值作为机器学习算法的训练集,导 ...
- 基于单层决策树的AdaBoost算法原理+python实现
这里整理一下实验课实现的基于单层决策树的弱分类器的AdaBoost算法. 由于是初学,实验课在找资料的时候看到别人的代码中有太多英文的缩写,不容易看懂,而且还要同时看代码实现的细节.算法的原理什么的, ...
- AdaBoost 算法原理及推导
AdaBoost(Adaptive Boosting):自适应提升方法. 1.AdaBoost算法介绍 AdaBoost是Boosting方法中最优代表性的提升算法.该方法通过在每轮降低分对样例的权重 ...
- 【机器学习】Apriori算法——原理及代码实现(Python版)
Apriopri算法 Apriori算法在数据挖掘中应用较为广泛,常用来挖掘属性与结果之间的相关程度.对于这种寻找数据内部关联关系的做法,我们称之为:关联分析或者关联规则学习.而Apriori算法就是 ...
- 机器学习之Adaboost (自适应增强)算法
注:本篇博文是根据其他优秀博文编写的,我只是对其改变了知识的排序,另外代码是<机器学习实战>中的.转载请标明出处及参考资料. 1 Adaboost 算法实现过程 1.1 什么是 Adabo ...
随机推荐
- 「loj#6261」一个人的高三楼
题目 显然存在一个这样的柿子 \[S^{(k)}_i=\sum_{j=1}^iS^{(k-1)}_j\] 我们可以视为\(S^{(k)}\)就是由\(S^{(k-1)}\)卷上一个长度为\(n\)全是 ...
- ssm项目 maven 项目pon.xml 配置
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/20 ...
- Ionic 新闻类别菜单
1.效果图 2.controller .js .controller("ProductCtrl", function ($scope,$ionicModal,$ionicScr ...
- c语言学习笔记 - 顺序查找和哨兵查找比较
今天学习C时用到了顺序查找和哨兵查找,做了一个比较,主要是学习下哨兵查找法 例如在一个数组里查找一个元素,没找到返回-1,找到了则返回这个数组的下标也就是键值. 用循序查找法: void arr_se ...
- 写js过程中遇到的一个bug
<div class="func_Div" id="xxcx"><span>信息查询</span> ...
- STL中的unique()和lower_bound ,upper_bound
unique(): 作用:unique()的作用是去掉容器中相邻元素的重复元素(数组可以是无序的,比如数组可以不是按从小到大或者从大到小的排列方式) 使用方法:unique(初始地址,末地址): 这里 ...
- PL/SQl连接数据库ORA-12154错误
先说说我遇到的问题: 1.在sql/plus下可以正确连接到数据库(oracle10g): 2.检查我机器(64)位环境变量的配置,没问题.path环境变量没问题(C:\oraclexe\app\or ...
- day1(老男孩-Python3.5-S14期全栈开发)
作者:赵俊 发布日期:2019/10/18 一.第一个python程序 1.在解释器下写hello world程序运行,与运行外部文件方法 运行外部文件,必须在相应位置创建一个p ...
- Django项目: 5.新闻主页
一.功能需求分析 1.功能 轮播图 推荐文章列表 文章标签导航 文章列表 分页 二.模型设计 根据功能分析,我们需要如下表 1.表和字段分析 文章分类表 文章表 文章评论表 推荐文章表 轮播图表 2. ...
- Redis基本类型与常用命令
Redis基本类型一共有五类: 字符串类型(string): 散列类型(hash): 列表类型(list): 集合类型(sort): 有序集合类型(zset): 在redis中,所有的类型都是被以键值 ...