动手实现CapsNet系列——1 概述
Geoffrey Hinton是深度学习的开创者之一,反向传播等神经网络经典算法发明人,他在17年年底和他的团队发表了两篇论文,介绍了一种全新的神经网络,这种网络基于一种称为胶囊(Capsule)的结构,并且还发表了用来训练胶囊网络的囊间动态路由算法。这篇文章的意义目前还不明显,因为Hinton老师确实给大家挖了一个大坑来填,论文中还有一些想法目前很粗糙,有水论文的机会。
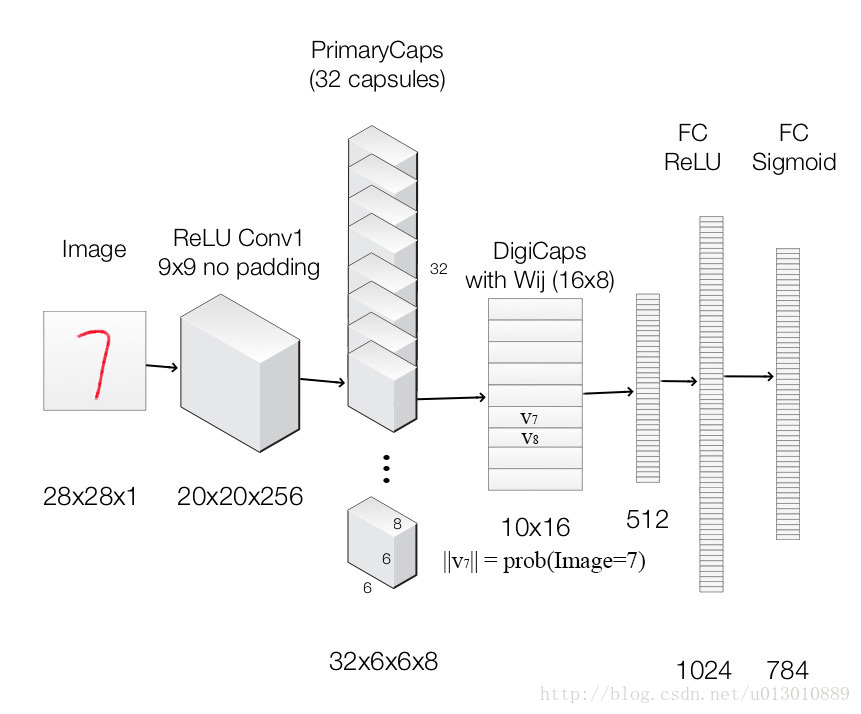
Capsule
Capsule 中的神经元的激活情况表示了图像中存在的特定实体的各种性质。这些性质可以包含很多种不同的参数,例如姿势(位置,大小,方向)、变形、速度、反射率,色彩、纹理等等。而输入输出向量的长度表示了某个实体出现的概率,所以它的值必须在 0 到 1 之间。
Capsule解决了CNN无法对特征之间相对位置等空间信息进行预测的问题,具有旋转不变性。
Capsule是一个向量,表征了两个部分:
- 其长度表征了某个实例(物体、视觉概念或者是他们的一部分)出现的概率
- 其方向(长度无关的部分)表征了物体的某些图像属性(位置、颜色、方向、形状等)
当胶囊工作正常时,视觉实体存在的概率具有局部不变性——当实体在胶囊覆盖的有限范围内的外观流形上移动时,概率不会改变。
用图形描述概念如下:

一个简单的CNN模型可以正确地提取鼻子,眼睛和嘴巴的特征,但是提取出来的特征会错误地激活神经元,得出脸部检测成功的结果,如下:
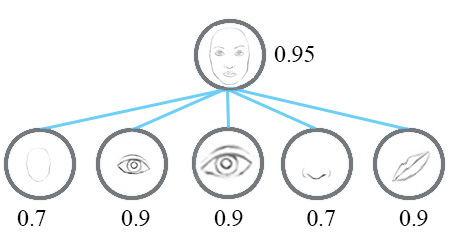
CapsNet将每个特征的概率的标量表示替换成很多信息的向量表示,输出的不再是标量x,而是一个包含[可能性,方向,大小]的向量,那么就可以检测鼻子,眼睛和耳朵特征之间的方向和大小的不一致, 得出最后的结论,如下图:
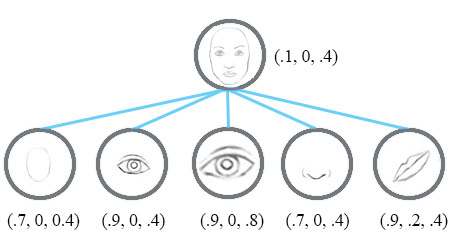
又比如,下面的第一行表示神经元检测数字“7”的概率;Capsule检测数字“7”时会输出一个2维向量,向量的长度表示检测特征的概率,向量的方向方向代表其参数(属性)。

第二行中,输出的2维向量为v=(0, 0.9)和 v=(0, 0.3),大小表示为:√(0^2+0.9^2 )=0.9 和 :√(0^2+0.3^2 )=0.3;第三行中,输出的2维向量为v=(0.2, 0.87)和 v=(0.2, 0.19),向量的大小仍为0.9和0.3。在这里,随意给的0.2代表其向右旋转20度。当然,可以再添加两个神经元来捕捉特征的大小和笔画的粗细程度,如下:
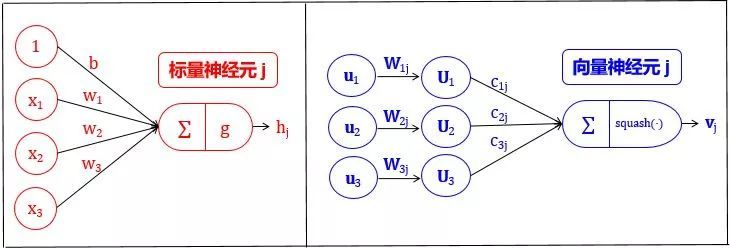
胶囊和人工神经元对比如下:

用图像表示如下:
Dynamic Routing
低层胶囊将其输出发送给对此表示“同意”的高层胶囊,这是动态路由算法的精髓,下面逐行看看原论文对这一算法的描述:

让我们先来看第一行和最后一行,也就是说,这个算法的输入和输出分别是什么。第一行指明了算法的输入:低层l中的所有胶囊及其输出û,以及路由迭代计数r。最后一行指明了算法的输出,一个高层胶囊vj。本质上,这段算法告诉我们如何计算网络的前向传导。
第2行的bij是一个临时变量,它的值会在迭代过程中更新,当整个算法运行完毕后,它的值将被保存到cij。在训练开始时,bij的值被初始化为零。
第3行表明第4-7行的步骤会被重复r次(路由迭代次数)。
第4行计算向量ci的值,也就是低层胶囊i的所有权重。这一计算将应用到所有低层胶囊上。为什么要用softmax呢?Softmax将确保所有权重cij均为非负数,且其总和等于一。本质上,softmax强制实施了我在上文描述的系数cij的概率性质。
由于所有bij的值初始化为零(第2行),第一次迭代后,所有系数cij的值会相等。例如,如果我们有3个低层胶囊和2个高层胶囊,那么所有cij将等于0.5。算法初始化时期,所有cij均相等,这意味着不确定性达到最大值:低层胶囊不知道它们的输出最适合哪个高层胶囊。当然,随着这一进程的重复,这些均匀分布将发生改变。
计算了所有低层胶囊的所有的权重cij之后,我们来看第5行,那里将涉及高层胶囊。这一步我们将计算经前一步确定的路由系数cij加权后的输入向量的线性组合。从直觉上说,这意味着缩小输入向量并将它们相加,得到输出向量sj。这一步骤将应用到所有高层胶囊上。
接着,在第6行中,来自前一步的向量将穿过squash非线性函数,这确保了向量的方向被保留下来,而长度被限制在1以下。该步骤生成传给所有高层胶囊的输出向量vj。
CapsNet的另一大创新是新颖的非线性激活函数,这个函数接受一个向量,然后在不改变方向的前提下,压缩它的长度到1以下:

压缩输入向量的标量而不改变其方向
公式右边的蓝色矩形缩放输入向量至单位长度,左边的红色矩形进行一些额外的缩放,输出向量的长度代表胶囊检测的给定特征的概率。
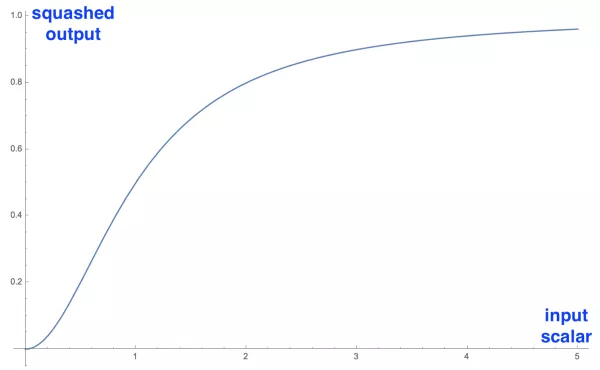
上图是应用于一维向量(标量)的压缩函数,用来演示函数有趣的非线性形态,只有可视化一维情况比较可行,实际应用中,这个函数会接受一个向量并输出一个向量,很难可视化。
以上步骤可视化为下图:
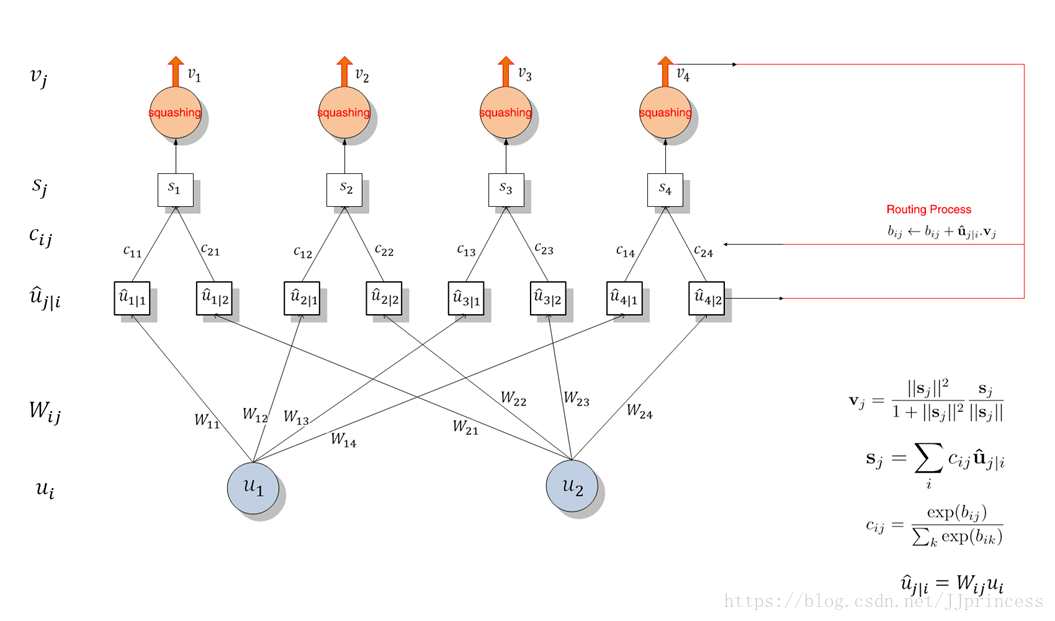
总结一下到目前为止算法做了什么:步骤4-6是在计算高层胶囊的输出。第7行更新了权重,也是路由算法的本质所在。在这一步中,我们查看了每个高层胶囊j,然后检查每个输入并根据公式更新相应的权重bij。公式表明,胶囊j的当前输出和从低层胶囊i处接收的输入的点积,加上旧权重,等于新权重。点积检测胶囊的输入和输出之间的相似性。另外,如前文所述,低层胶囊将其输出发送给具有类似输出的高层胶囊。点积刻画了这一相似性。这一步骤之后,算法跳转到第3步重新开始这一流程,并重复r次。
重复r次后,我们计算出了所有高层胶囊的输出,并确立路由权重。之后正向传导就可以推进到更高层的网络。
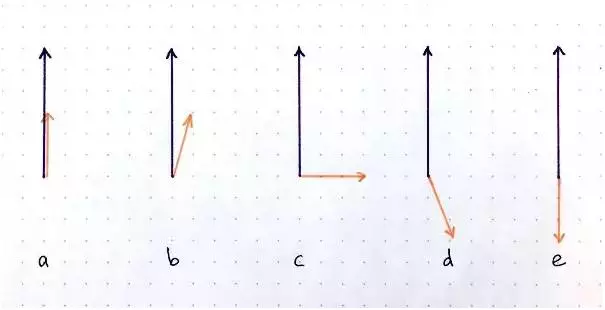
点积运算接收两个向量,并输出一个标量。对于给定长度但方向不同的两个向量而言,点积有几种情况:a最大正值; b 正值;c 零;d 负值;e 绝对值最大的负值。
权重更新的直观例子:

更形象一点地叙述如下:

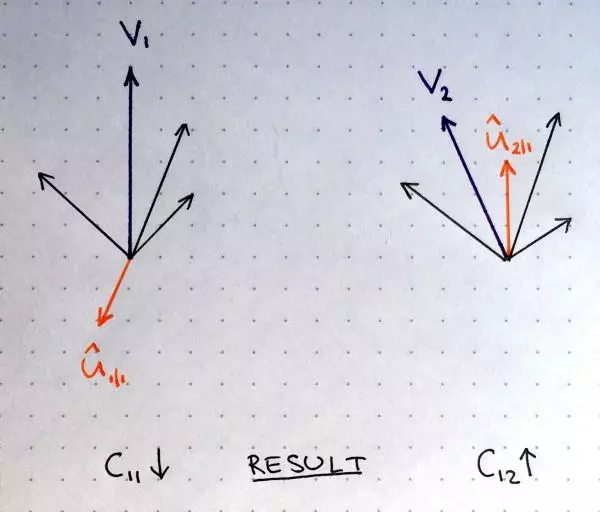
低层胶囊将其输出发送给对此表示“同意”的高层胶囊。这是动态路由算法的精髓
上图中,一个低层胶囊需要“决定”将它的输出发送给哪个高层胶囊。它将通过调整权重C做出决定,胶囊在发送输出前,先将输出乘以这个权重。胶囊将决定是把输出发给左边的胶囊J,还是发给右边的胶囊K。
目前为止,高层胶囊已经接收到来自其他低层胶囊的许多向量。所有这些输入以红点和蓝点表示。这些点聚集的地方,意味着低层胶囊的预测互相接近。比如,胶囊J和K中都有一组聚集的红点,因为那些胶囊的预测很接近。
所以,低层胶囊该把它的输出发给胶囊J还是胶囊K呢?这个问题的答案正是动态路由算法的精髓。低层胶囊的输出乘以相应的矩阵W后,远离胶囊J中“正确”预测的红色聚集,另一方面,在胶囊K中,它将落在非常接近于“真”预测的红色群组中。低层胶囊具备测量哪个高层胶囊更能接受其输出的机制,并据此自动调整权重,使对应胶囊K的权重C变高,对应胶囊J的权重C变低。
采用多少次路由迭代?论文在MNIST和CIFAR数据集上检测了一定范围内的数值,得到以下结论:
- 更多的迭代往往会导致过拟合
- 实践中建议使用3次迭代
CapsNet
CapsNet由两部分组成:编码器和解码器。前3层是编码器,后3层是解码器:
第一层:卷积层
第二层:PrimaryCaps(主胶囊)层
第三层:DigitCaps(数字胶囊)层
第四层:第一全连接层
第五层:第二全连接层
第六层:第三全连接层
第一部分 编码器
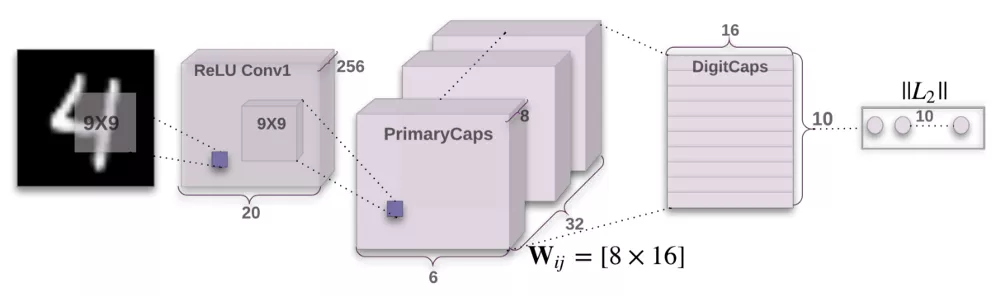
上图中,网络的编码器部分接受一张28x28的MNIST数字图像作为输入,学习将它编码为由实例参数构成的16维向量(本系列前面几篇文章解释了这一过程),这也是胶囊进行工作的所在。预测输出是由DigitCaps输出的长度构成的10维向量。
第一层 卷积层
输入:28x28图像(单色)
输出:20x20x256张量
参数:20992
卷积核:256个步长为1的9×9×19×9×1的核
激活函数:ReLU
卷积层检测2D图像的基本特征。在CapsNet中,卷积层有256个步长为1的9x9x1核,使用ReLU激活。如果你不明白这句话是什么意思,这里有一些很棒的资源让你快速掌握卷积背后的关键概念。计算参数时,别忘了卷积层中的每个核有1个偏置项。因此这一层共有(9x9+1)x256 = 20992个可训练参数。
第二层 PrimaryCaps层(32个胶囊)
输入:20x20x256张量
输出:6x6x8x32张量
参数:5308672
卷积核:8个步长为1的9×9×2569×9×256的核/胶囊
这一层包含32个主胶囊,接受卷积层检测到的基本特征,生成特征的组合。这一层的32个主胶囊本质上和卷积层很相似。每个胶囊将8个9x9x256卷积核应用到20x20x256输入张量,因而生成6x6x8输出张量。由于总共有32个胶囊,输出为6x6x8x32张量。这一层共有5308672个可训练参数(计算过程与上一层类似)。
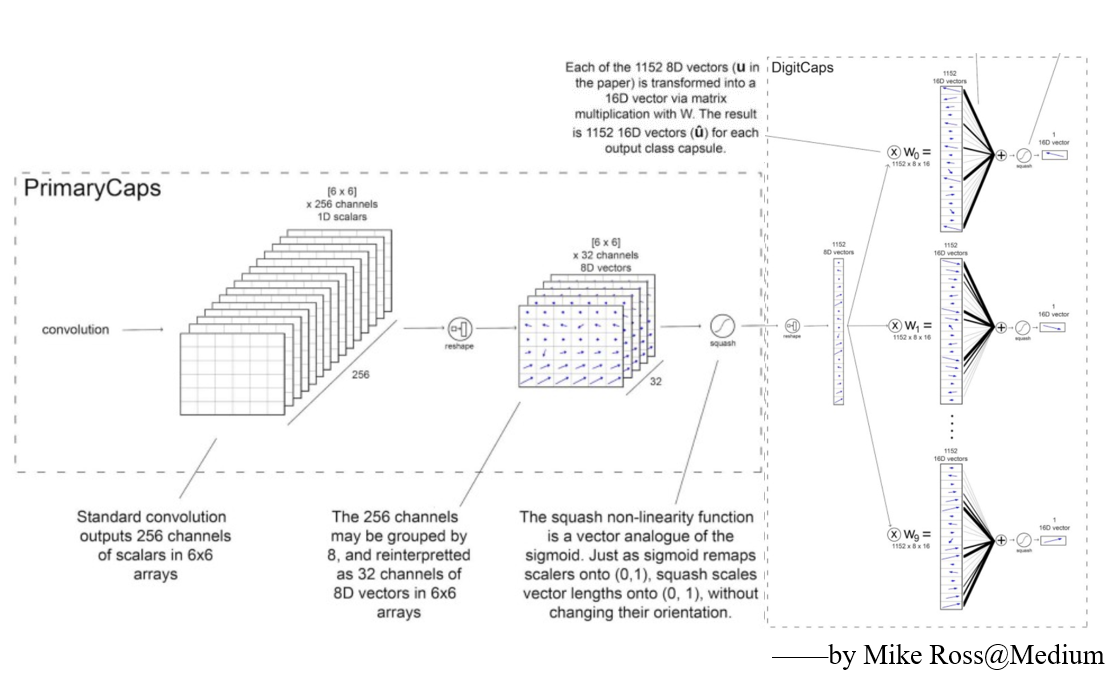
第三层 DigitCaps层(10个胶囊)
输入:6x6x8x32张量
输出:16x10矩阵
参数:1497600
这一层包含10个数字胶囊,每个胶囊对应一个数字。每个胶囊接受一个6x6x8x32张量作为输入。你可以把它看成6x6x32的8维向量,也就是1152输入向量。在胶囊内部,每个输入向量通过8x16权重矩阵将8维输入空间映射到16维胶囊输出空间。因此,每个胶囊有1152矩阵,以及用于动态路由的1152 c系数和1152 b系数。乘一下:1152 x 8 x 16 + 1152 + 1152,每个胶囊有149760可训练参数,乘以10得到这一层最终的参数数目。
损失函数



第二部分 解码器
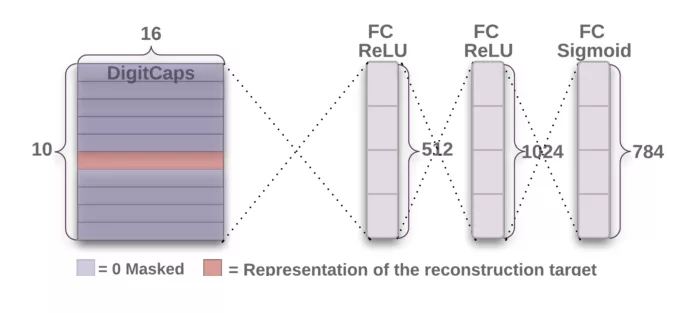
解码器从正确的DigitCap中接受一个16维向量,并学习将其解码为数字图像(请注意,它在训练时仅使用正确的DigitCap向量,忽略不正确的DigitCap)。解码器被用来作为正则子,它接受正确的DigitCap的输出作为输入,并学习重建一张28×28像素的图像,损失函数为重建图像与输入图像之间的欧氏距离。解码器强制胶囊学习对重建原始图像有用的特征。重建图像越接近输入图像越好。下图展示了一些重建图像的例子。

上为原始图像,下为重建图像。
第四层 第一全连接层
输入:16x10
输出:512
参数:82432
低层的每个输出加权后传导至全连接层的每个神经元作为输入。每个神经元同时具备一个偏置项。16x10输入全部传导至这一层的512个神经元中的每个神经元。因此,共有(16x10 + 1)x512可训练参数。
以下两层的计算与此类似:参数数量 = (输入数 + 偏置) x 层中的神经元数。
第五层 第二全连接层
输入:512
输出:1024
参数:525312
第六层 第三全连接层
输入:1024
输出:784(重整后重建28x28解码图像)
参数:803600
网络中的参数总数:8238608
Reconstruct
Hinton一直坚持的一个理念就是,一个好的鲁棒的模型,一定能够借由重构能力,通过提取出的特征表示还原出原始图像,如此才能够说这个模型能够很好地表示特征。
重构的意思就是用预测的类别重新构建出该类别代表的实际图像。前面,我们说到Capsule的向量可以表征一个实例,那么将最后的那个正确预测类别的向量投入到后面的重构网络中,应该可以构建一个完整的图像
故Hinton等人使用额外的重构损失来促进DigitCaps层对输入数字图片进行编码。重构网络架构如下:
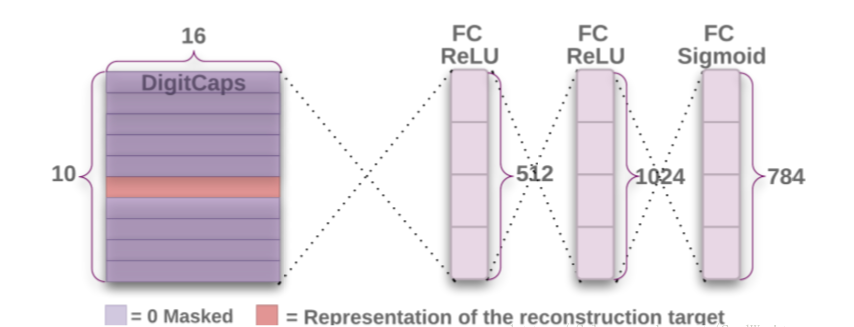
上图表明,正确预测类别的向量,即模值最大的向量送入包含三个全连接层的网络解码。这一过程的损失函数通过计算FC Sigmoid层的输出像素点与原始图像像素点的欧氏距离而构建。
下图是拿MNIST做实验得到的结果:

l代表标签,p代表预测值,r重构出的图片。左边三列是正确的结果。大家可以看到重构出来的图像形状和位置和输入极其类似,这是说明胶囊网络起了作用,即一个Capsule的确包含了物体的多个信息:特征、位置、大小等等。而后面两列是预测失败的,通过重构出来的图我们可以得到原因:3和5太像了,我感觉Hinton的意思就是,这种图人也会犯错,不怪Capsule。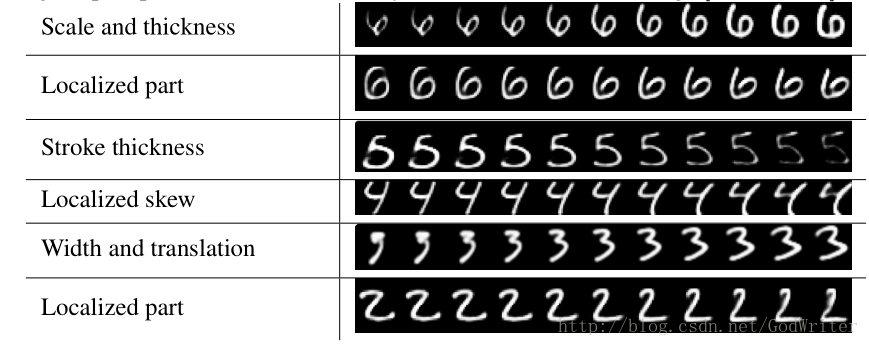
泛化能力对模型无比重要,故Hinton对原来的MNIST数据集做了改变(大小、粗细、位置,如上图)并传入一个训练过的,测试准确率为99.23%的Capsule模型做测试,得到准确率为79%。而一个训练过的准确度为99.22%的传统CNN模型只能达到66%的准确率。不得不说,Capsule模型的泛化能力的确惊人。
总之,Capsule 输出向量的重构与表征除了能提升模型的准确度以外,还能提升模型的可解释性,因为我们能修正需要重构向量中的某个或某些分量而观察重构后的图像变化情况,这有助于我们理解 Capsule 层的输出结果。
总结
优点
- 由于胶囊网络集合了位姿信息,因此其可以通过一小部分数据即学习出很好的表示效果,所以这一点也是相对于CNN的一大提升。举个例子,为了识别手写体数字,人脑需要几十个最多几百个例子,但是CNN却需要几万规模的数据集才能训练出好结果,这显然还是太暴力了!
- 更加贴近人脑的思维方式,更好地建模神经网络中内部知识表示的分层关系,胶囊背后的直觉非常简单优雅。
缺点
- 胶囊网络的当前实现比其他现代深度学习模型慢很多(我觉得是更新耦合系数以及卷积层叠加影响的),提高训练效率是一大挑战。
参考:
https://www.cnblogs.com/CZiFan/p/9803067.html
https://www.dazhuanlan.com/2019/10/16/5da675cd92427/
https://mp.weixin.qq.com/s/6CRSen8P6zKaMGtX8IRfqw
https://blog.csdn.net/sunlianglong/article/details/80412304
https://www.dazhuanlan.com/2019/10/17/5da7e88d0edb8/
https://blog.csdn.net/GodWriter/article/details/79216404
https://www.cnblogs.com/ratels/p/11690989.html
https://blog.csdn.net/u013010889/article/details/78722140
动手实现CapsNet系列——1 概述的更多相关文章
- 动手实现CapsNet系列——2 实现(未完待续)
执行后返回如下信息: Loading complete. Training started! [epoch 0][iter 0] loss: 0.8082, acc: 14.0000% (14/100 ...
- 快速入门系列--MVC--01概述
虽然使用MVC已经不少年,相关技术的学习进行了多次,但是很多技术思路的理解其实都不够深入.其实就在MVC框架中有很多设计模式和设计思路的体现,例如DependencyResolver类就包含我们常见的 ...
- [2017-08-07]ABP系列——QuickStartA:概述、思想、入门和HelloWorld
唔,说好的文章,欠了好久,先水一篇. 本系列目录:Abp介绍和经验分享-目录 概述 先表个态:对绝大多数人来说,ABP是成熟的,足以用到生产环境的. 最适合的:业务非常复杂且不追求极致性能的(这里并不 ...
- Orleans 框架3.0 官方文档中文版系列一 —— 概述
关于这个翻译文档的一些说明: 之前逛博客园的时候,看见有个园友在自己的博客上介绍Orleans. 觉得Orleans 是个好东西. 当时心想:如果后面有业务需要的时候可以用用Orleans框架. 当真 ...
- C 标准库系列之概述
基本上很多编程语言都会提供针对语言本身的一系列的标准库或者包,当然C语言同样也有提供标准库,C语言的标准库是一系列的头文件的集合:如assert.h.ctype.h.errno.h.float.h.l ...
- zk系列-zookeeper概述
接触zk是2年前了,最近工作又比较依赖于zk,所以准备起个系列文章,系统的总结下. zookeeper是一个分布式的用于协调的服务,起源于Hadoop中的一个组件.分布式系统可以用zookeeper实 ...
- Dubbo系列_概述
一.本文目的 学习使用Dubbo也有一段时间了,准备写一个系列文章介绍Dubbo的相关知识和使用,供自己以后回顾和他人学习.有兴趣的同学可以加入群:74085440一起探讨 二.书写计 ...
- WCF基于Cookie回传的系列(概述)
1 WCF的基本知识(不作细述,园子里有很多的经典的文章系列) 2 WCF的执行过程 3 让服务通信像浏览器发送请求应答一样回传Cookie,并实现Cookie在不同的服务间共享 4 基于共享后的 ...
- nginx系列 2 概述
一. nginx功能概述 nginx 提供的基本功能服务归纳为:基本HTTP服务.高级HTTTP服务.邮件代理服务.TCP/UDP 代理服务等四大类. (1) Nginx提供基本HTTP服务,可以作为 ...
随机推荐
- 第一篇 网站基础知识 第7章 Tomcat分析
7.1 Tomcat的顶层结构及启动过程 7.1.1 Tomcat的顶层结构 Tomcat中最顶层的容器叫Server,代表整个服务器,Server中包含至少一个Service,用于具体提供服务.Se ...
- TF file
To software:Design rules for placement and routing interconnect resistance /capacitance data for gen ...
- Java 13 新特性
一.core-libs/java.nio 添加 FileSystems.newFileSystem(Path, Map<String, ?>) 方法 java.nio.file.FileS ...
- phpstorm实用技巧
1.切换php代码版本提示 1.1找到External Libraries右键点击(configure PHP Include Paths) 1.2切换提示版本(在这里切换版本)确定即可 2.生成ge ...
- TI DaVinci(达芬奇)入门
(转载来自 德州仪器半导体技术(上海)有限公司 通用DSP 技术应用工程师 崔晶 德州仪器(TI)的第一颗达芬奇(DaVinci)芯片(处理器)DM6446已经问世快三年了.继DM644x之后,TI又 ...
- Codeforces Round #603 (Div. 2) A.Sweet Problem
#include <cstdio> #include <algorithm> using namespace std; int main() { int t; scanf(&q ...
- 原来window 也可以使用pthreads
https://blog.csdn.net/clever101/article/details/101029850
- SpringMVC框架应用
SSMSpringMVC框架 1. MVC设计模式:模型.视图.控制器: 视图:负责格式化数据并把他们呈现给用户,包括数据展示.用户交互.数据验证.界面设计等功能.对应组件:JSP或者HTML ...
- 关于memset....我太难了
众所周知memset是个清空数组的好东西 然而...它慢的要死 直接让我从30ms炸到1045ms 于是快乐tle .... 是我的错 所以以后还是手动清空 (我真快乐)
- quartus 9.0 对话框显示不完整
今天在quartus9.0新建SOPC build时,发现在添加PLL时对话框太大,笔记本分辨率差,导致结束和next不能选择: 解决: 如果电脑分辨率可以调整为合适的,就去调整: 现在介绍分辨率不合 ...