什么是LakeHouse?
1. 引入
在Databricks的过去几年中,我们看到了一种新的数据管理范式,该范式出现在许多客户和案例中:LakeHouse。在这篇文章中,我们将描述这种新范式及其相对于先前方案的优势。
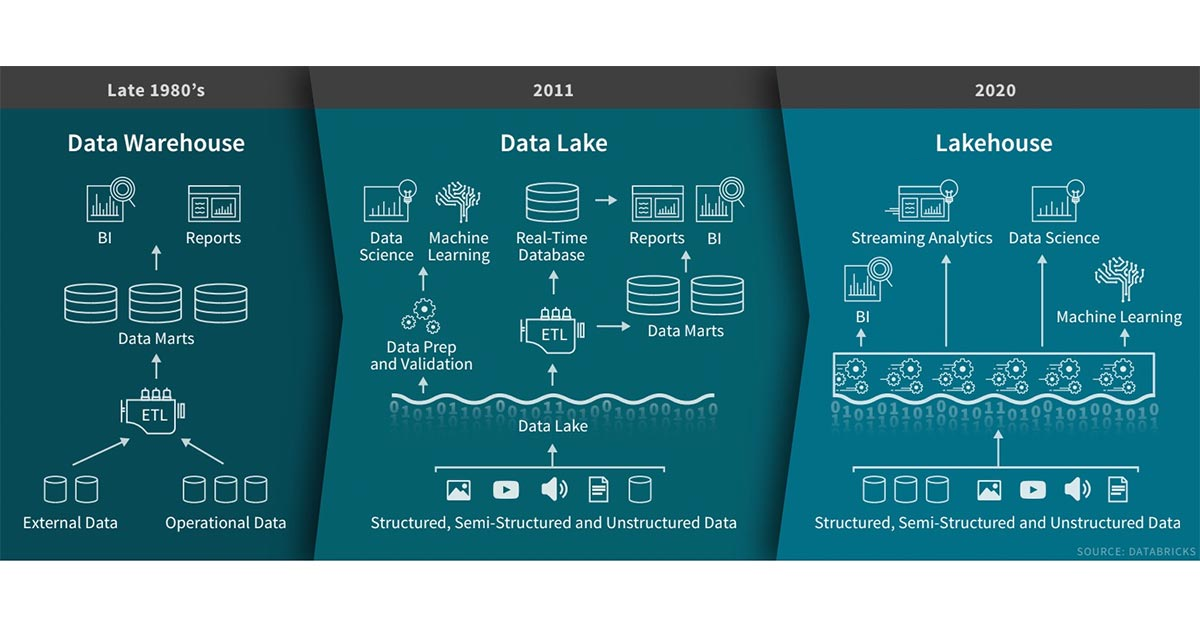
数据仓库技术自1980诞生以来一直在发展,其在决策支持和商业智能应用方面拥有悠久的历史,而MPP体系结构使得系统能够处理更大数据量。但是,虽然数据仓库非常适合结构化数据,但许多现代企业必须处理非结构化数据、半结构化数据以及具有高多样性,高速度和高容量的数据。数据仓库不适用于许多此类场景,并且也不是最具成本效益的。
随着公司开始从许多不同源收集大量数据,架构师开始构想一个单一的系统来容纳不同分析产品和工作负载的数据。大约十年前,公司开始构建数据湖:各种格式原始数据的存储库。数据湖虽然适合存储数据,但缺少一些关键功能:不支持事务、无法提高数据质量、缺乏一致性/隔离性,导致几乎不可能混合处理追加(append)和读取,批处理和流处理作业。由于这些原因,数据湖之前的许多承诺尚未实现,在许多情况下还会失去数据仓库的许多好处。
公司对灵活、高性能系统的需求并未减少,如需要各类数据应用程序包括SQL分析、实时监控、数据科学和机器学习的系统。人工智能的大部分最新进展是有可用于更好处理非结构化数据(文本,图像,视频,音频)的模型,这些恰恰是数据仓库未针对优化的数据类型。一种常见的解决方案是使用多个系统,即一个数据湖、几个数据仓库以及其他专用系统(如流、时间序列、图形和图像数据库系统)。维护大量系统会引入额外的复杂性,更重要的是会带来延迟,因为数据专业人员需要在不同系统间移动或复制数据。
2. 什么是LakeHouse?
解决数据湖限制的新系统开始出现,LakeHouse是一种结合了数据湖和数据仓库优势的新范式。LakeHouse使用新的系统设计:直接在用于数据湖的低成本存储上实现与数据仓库中类似的数据结构和数据管理功能。如果你现在需要重新设计数据仓库,鉴于现在存储(以对象存储的形式)廉价且高可靠,不妨可以使用LakeHouse。
LakeHouse有如下关键特性:
- 事务支持:企业内部许多数据管道通常会并发读写数据。对ACID事务支持确保了多方可使用SQL并发读写数据。
- 模式执行和治理(Schema enforcement and governance):LakeHouse应该有一种可以支持模式执行和演进、支持DW模式的范式(如star/snowflake-schemas)。该系统应该能够推理数据完整性,并具有健壮的治理和审计机制。
- BI支持:LakeHouse可以直接在源数据上使用BI工具。这样可以提高数据新鲜度,减少等待时间,降低必须同时在数据湖和数据仓库中操作两个数据副本的成本。
- 存储与计算分离:这意味着存储和计算使用单独的集群,因此这些系统能够支持更多用户并发和更大数据量。一些现代数据仓库也具有此属性。
- 开放性:使用的存储格式(如Parquet)是开放式和标准化的,并提供API以便各类工具和引擎(包括机器学习和Python / R库)可以直接有效地访问数据。
- 支持从非结构化数据到结构化数据的多种数据类型:LakeHouse可用于存储、优化、分析和访问许多数据应用所需的包括图像、视频、音频、半结构化数据和文本等数据类型。
- 支持各种工作负载:包括数据科学、机器学习以及SQL和分析。可能需要多种工具来支持这些工作负载,但它们底层都依赖同一数据存储库。
- 端到端流:实时报表是许多企业中的标准应用。对流的支持消除了需要构建单独系统来专门用于服务实时数据应用的需求。
以上是LakeHouse的关键特性,企业级系统可能还需要其他功能特性,如安全和访问控制工具是基本要求,尤其是根据最近的隐私法规,包括审核、保留和沿袭(lineage)在内的数据治理功能变得至关重要。可能还需要使用数据发现( data discovery )工具,例如数据目录(catalog)和数据使用指标。使用LakeHouse,那么就只需为单个系统实施、测试和管理此类企业功能。
3. 早期示例
Databricks平台具有LakeHouse的特性。微软的Azure Synapse Analytics服务与Azure Databricks集成,可实现类似LakeHouse模式,其他托管服务(例如BigQuery和Redshift Spectrum)具有上面列出的一些LakeHouse功能特性,但它们是主要针对BI和其他SQL应用。企业若想构建系统,可参考适合于构建LakeHouse的开源文件格式(Delta Lake,Apache Iceberg,Apache Hudi)。
将数据湖和数据仓库合并至一个系统意味着数据团队可以更快地移动,因为他们无需访问多个系统便可使用数据。 在早期的LakeHouse中,SQL与BI工具的集成通常足以满足大多数企业数据仓库的需求。虽然可以使用物化视图和存储过程,但用户可能需要采用其他机制,这些机制与传统数据仓库中的机制不同。后者对于“lift and shift scenarios”尤为重要,“lift and shift scenarios”要求系统所具有的语义与旧的商业数据仓库的语义几乎相同。
LakeHouse对其他类型数据应用的支持又如何呢? LakeHouse的用户可以使用各种标准工具(Spark,Python,R,机器学习库)来处理如数据科学和机器学习等非BI工作负载。数据探索和加工是许多分析和数据科学应用程序的标准。Delta Lake可以让用户逐步改进LakeHouse的数据质量,直到可以使用为止。
尽管分布式文件系统可以用于存储层,但对象存储在LakeHouse中更为常见。对象存储提供低成本、高可用的存储,在大规模并发读取方面表现出色,这是现代数据仓库的基本要求。
4. 从BI到AI
LakeHouse是一种新的数据管理范式,从根本上简化了企业数据基础架构,并且有望在机器学习已渗透到每个行业的时代加速创新。过去公司产品或决策中涉及的大多数数据都是来自操作系统的结构化数据,而如今,许多产品都以计算机视觉和语音模型、文本挖掘等形式集成了AI。而为什么要使用LakeHouse而不是数据湖来进行AI?是因为LakeHouse可以提供数据版本控制、治理、安全性和ACID属性,即使对于非结构化数据也是如此。
当前LakeHouse降低了成本,但它们的性能仍然落后于专门的系统(如数据仓库),但这些系统需要数年的投入和实际部署。同时用户可能会偏爱某些工具(BI工具,IDE,笔记本电脑),因此LakeHouse也需要改善其UX以及与流行工具的连接器,以便更具吸引力。随着技术的不断成熟和发展,这些问题将得到解决。随着时间推移,LakeHouse将缩小这些差距,同时保留服务各种数据应用的更简单、更具成本效益和更强大的能力的核心属性。

什么是LakeHouse?的更多相关文章
- Databricks说的Lakehouse是什么?
在过去的几年里,Lakehouse作为一种新的数据管理范式,已独立出现在Databricks的许多用户和应用案例中.在这篇文章中,我们将阐述这种新范式以及它相对于之前方案的优势. 数据仓库在决策支持和 ...
- Lakehouse: 统一数据仓库和高级分析的新一代开放平台
1. 摘要 数仓架构在未来一段时间内会逐渐消亡,会被一种新的Lakehouse架构取代,该架构主要有如下特性 基于开放的数据格式,如Parquet: 机器学习和数据科学将被作为头等公民支持: 提供卓越 ...
- 使用Apache Pulsar + Hudi构建Lakehouse方案了解下?
1. 动机 Lakehouse最早由Databricks公司提出,其可作为低成本.直接访问云存储并提供传统DBMS管系统性能和ACID事务.版本.审计.索引.缓存.查询优化的数据管理系统,Lakeho ...
- 一文带你了解Lakehouse的并发控制:我们是否过于乐观
1. 概述 如今数据湖上的事务被认为是 Lakehouse 的一个关键特征. 但到目前为止,实际完成了什么? 目前有哪些方法? 它们在现实世界中的表现如何? 这些问题是本博客的重点. 有幸从事过各种数 ...
- Halodoc使用 Apache Hudi 构建 Lakehouse的关键经验
Halodoc 数据工程已经从传统的数据平台 1.0 发展到使用 LakeHouse 架构的现代数据平台 2.0 的改造.在我们之前的博客中,我们提到了我们如何在 Halodoc 实施 Lakehou ...
- 基于 Apache Hudi 和DBT 构建开放的Lakehouse
本博客的重点展示如何利用增量数据处理和执行字段级更新来构建一个开放式 Lakehouse. 我们很高兴地宣布,用户现在可以使用 Apache Hudi + dbt 来构建开放Lakehouse. 在深 ...
- 基于 Apache Hudi + Presto + AWS S3 构建开放Lakehouse
认识Lakehouse 数据仓库被认为是对结构化数据执行分析的标准,但它不能处理非结构化数据. 包括诸如文本.图像.音频.视频和其他格式的信息. 此外机器学习和人工智能在业务的各个方面变得越来越普遍, ...
- 印尼医疗龙头企业Halodoc的数据平台转型之Lakehouse架构
1. 摘要 在 Halodoc,我们始终致力于为最终用户简化医疗保健服务,随着公司的发展,我们不断构建和提供新功能. 我们两年前建立的可能无法支持我们今天管理的数据量,以解决我们决定改进数据平台架构的 ...
- Apache Hudi vs Delta Lake:透明TPC-DS Lakehouse性能基准
1. 介绍 最近几周,人们对比较 Hudi.Delta 和 Iceberg 的表现越来越感兴趣. 我们认为社区应该得到更透明和可重复的分析. 我们想就如何执行和呈现这些基准.它们带来什么价值以及我们应 ...
随机推荐
- C++虚继承初识
struct Employee { ... }; struct Manager : Employee { ... }; struct Worker : Employee { ... }; struct ...
- slim的中间件
slim中间件的作用简单来说就是过滤数据,request过来的数据要经过中间件才能到达内部,然后内部数据要到达外部的时候,也要经过中间件,正常通过才能到达外部
- hibernate映射-继承映射
对于面向对象的程序设计语言而言,继承和多态是两个最基本的概念.Hibernate的继承映射可以理解成持久化类之间的继承关系.例如:人和学生之间的关系.学生继承人,可以认为学生是一个特殊的人,如果对人进 ...
- 看demo1
http://pytorch-cn.readthedocs.io/zh/latest/package_references/torch/ pytorch文档 1.json JSON(JavaScrip ...
- 【python测试开发栈】—帮你总结Python os模块高频使用的方法
Python中的os模块是主要和系统操作相关的模块,在平时的工作中会经常用到,花时间整理了os模块的高频使用方法,同时整理出使用时需要注意的点.归纳来讲,os模块的方法可以分为:目录操作.文件操作.路 ...
- 0006 列表(ul、ol、dl)
1. 列表标签(重点) 学习目标 理解 无序列表的应用场景 自定义列表的应用场景 应用 无序列表语法 自定义列表语法 问? 前面我们知道表格一般用于数据展示的,但是网页中还是有很多跟表格类似的布局,如 ...
- 记录nfs的防火墙以及权限问题
在前面的一篇文章(https://www.cnblogs.com/zyxnhr/p/10660431.html)中,已经介绍了nfs的安装挂载使用,但是存在两个问题 一. 防火墙 在nfs和nfs的守 ...
- 洛谷$P$2286 宠物收养场 $[HNOI2004]$ $splay$
正解:$splay$ 解题报告: 传送门! $splay$板子,,,? 先考虑这题要实现些什么东西嘛$QwQ$ 其实只要实现一个东西?就查询数列中与给定数字相差最小的数,显然用$splay$查询前驱后 ...
- $Poj1037\ A\ Decorative\ Fence$ 计数类$DP$
Poj AcWing Description Sol 这题很数位$DP$啊, 预处理$+$试填法 $F[i][j][k]$表示用$i$块长度不同的木板,当前木板(第$i$块)在这$i$块木板中从小到 ...
- 洛谷P1036 选数 题解 简单搜索/简单状态压缩枚举
题目链接:https://www.luogu.com.cn/problem/P1036 题目描述 已知 \(n\) 个整数 \(x_1,x_2,-,x_n\) ,以及 \(1\) 个整数 \(k(k& ...