最大似然估计、n阶矩、协方差(矩阵)、(多元)高斯分布 学习摘要
最大似然估计
似然与概率
在统计学中,似然函数(likelihood function,通常简写为likelihood,似然)和概率(Probability)是两个不同的概念。概率是在特定环境下某件事情发生的可能性,也就是结果没有产生之前依据环境所对应的参数来预测某件事情发生的可能性,比如抛硬币,抛之前我们不知道最后是哪一面朝上,但是根据硬币的性质我们可以推测任何一面朝上的可能性均为50%,这个概率只有在抛硬币之前才是有意义的,抛完硬币后的结果便是确定的;而似然刚好相反,是在确定的结果下去推测产生这个结果的可能环境(参数),还是抛硬币的例子,假设我们随机抛掷一枚硬币1,000次,结果500次人头朝上,500次数字朝上(实际情况一般不会这么理想,这里只是举个例子),我们很容易判断这是一枚标准的硬币,两面朝上的概率均为50%,这个过程就是我们根据结果来判断这个事情本身的性质(参数),也就是似然。
结果和参数相互对应的时候,似然和概率在数值上是相等的,如果用 θ 表示环境对应的参数,x 表示结果,那么概率可以表示为:
P(x | θ)
是条件概率的表示方法,θ是前置条件,理解为在θ 的前提下,事件 x 发生的概率,相对应的似然可以表示为:
L(θ | x)
理解为已知结果为 x ,参数为θ (似然函数里θ 是变量,这里说的参数是相对与概率而言的)对应的概率。
最大似然估计
似然函数的最大值意味着什么?让我们回到概率和似然的定义,概率描述的是在一定条件下某个事件发生的可能性,概率越大说明这件事情越可能会发生;而似然描述的是结果已知的情况下,该事件在不同条件下发生的可能性,似然函数的值越大说明该事件在对应的条件下发生的可能性越大。
最大值似然估计量和极大值似然估计量的区别
最大似然估计量是样本的函数,若把样本的观测值 x1,..., xn 带入到统计量的表达式中,得出的就是最大似然估计值。 前者是个随机变量,后者是一个确定的值,没有随机性。
n阶中心矩
设X是随机变量,则称
为X的k阶中心距。
当中心距中的E(X)为0时,此时为k阶原点矩,即原点矩是中心距的特殊情况。
一阶原点矩就是数学期望,二阶中心距就是方差,在实际中常用低阶矩,高于四阶矩极少使用。
协方差(矩阵)
协方差用于描述两个变量的相关性
Cov(X, Y) = E[ [X−E(X)][Y−E(Y)] ]
相关系数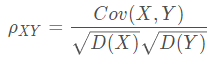 其中,D(X)为方差,E(X)为期望。
其中,D(X)为方差,E(X)为期望。
ρXY=0, 两个变量不相关
协方差矩阵
先从二维随机变量讲起,二维随机变量(X1,X2)有四个二阶中心矩(设它们都存在),分别记为:
c11 = E{ [X1 - E(X1)]2 }
c12 = E{ [X1 - E(X1)][X2 - E(X2)] }
c21 = E{ [X2 - E(X2)][X1 - E(X1)] }
c22 = E{ [X2 - E(X2)]2 }
将它们排列成矩阵的形式
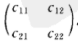
扩展到多维:
设n维随机变量(X1, X2, ..., Xn)的二阶混合中心矩 cij = E{ [Xi - E(Xi)][Xj - E(Xj)] },i,j=1,2,...,n 都存在,则称矩阵
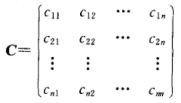
为n维随机变量(X1, X2, ..., Xn)的协方差矩阵。由于cij = cji(i≠j;ii,j=1,2,...,n),因而上述矩阵是一个对称矩阵。
(多元)高斯分布
正态分布(normal distribution)又名高斯分布(Gaussian distribution),是一个非常常见的连续概率分布。正态分布在统计学上十分重要,经常用在自然和社会科学来代表一个不明的随机变量。

则其概率密度函数的一般形式为
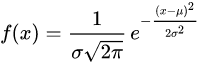
正态分布的数学期望值或期望值


正态分布的概率密度函数曲线呈钟形,因此人们又经常称之为钟形曲线(类似于寺庙里的大钟,因此得名)。我们通常所说的标准正态分布N(0, 1)是位置参数

标准正态分布标准化到一般情形,x 轴方向做 σ 倍延拓的同时, y 轴应该压缩 σ 倍(乘以 1/σ)。
概率密度函数
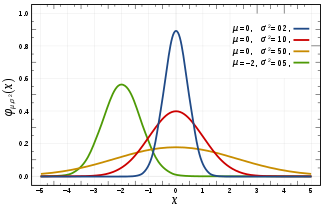

高斯分布一些重要的量:
1. 密度函数关于平均值对称;
2. 平均值与它的众数(statistical mode)以及中位数(median)相等;
3. 函数曲线下68.268949%的面积在平均值左右的一个标准差范围内;
4. 95.449974%的面积在平均值左右两个标准差2σ的范围内;
5. 99.730020%的面积在平均值左右三个标准差3σ的范围。
其中第3-5条称为“68-95-99.7法则” 或 “经验法则”。
概率分布函数
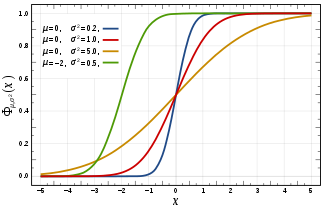
正态分布的分布函数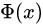 没有解析表达式,它的值可以通过数值积分、泰勒级数或者渐进序列近似得到。
没有解析表达式,它的值可以通过数值积分、泰勒级数或者渐进序列近似得到。
中心极限定理
正态分布有一个很重要的性质:在特定条件下,大量统计独立的随机变量的和的分布趋于正态分布,这就是中心极限定理。中心极限定理的重要意义在于,依据这一定理的结论,其它概率分布能够用正态分布作为近似。
高斯分布线性组合的重要性质
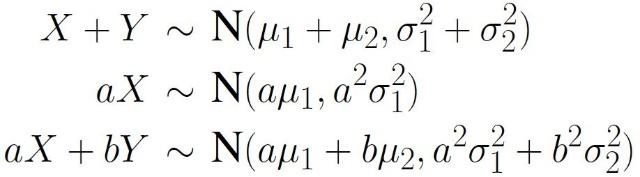
为什么数据科学家都喜欢高斯分布
自然科学和社会科学中有极其大量的过程天然遵循高斯分布。即使当它们并不遵循高斯分布的时候,高斯分布也往往提供最佳的逼近。数学上的原因便是中心极限定理。中心极限定理表明,满足一定条件时,大量相互独立的随机变量经适当标准化后,收敛于高斯分布。这一定理意味着专门为高斯模型开发的大量科学方法和统计学方法同样适用于可能牵涉其他类型分布的广阔领域内的问题。
另外,高斯分布在一些转换后仍然是高斯分布:
高斯函数经傅里叶变换后,所得仍为高斯函数。
两个高斯函数的积仍然是高斯函数。
两个高斯函数的卷积仍然是高斯函数。
两个符合高斯分布的独立随机变量之和仍然符合高斯分布。
对每个高斯模型逼近而言,可能存在一个提供更好的逼近的复杂多参数分布。然而,我们仍然选择高斯模型,因为它大大简化了数学!
如何检查你的数据是不是高斯分布
· 看直方图! 是不是看起来像钟形?
· 计算描述性汇总度量 - 平均值,中位数和模式是否相似?(此处不大明白)
· 2/3的观察是否位于平均值的±1*标准差内? 95%的观察值是否在平均值的±2*标准差范围内?
特征选择
因为我们建立模型的基础是假设特诊满足高斯分布,那么要是特征不符合高斯分布呢?答案当然是整成高斯分布啊!
我们一开始拿到的特征的分布可能是这样的:
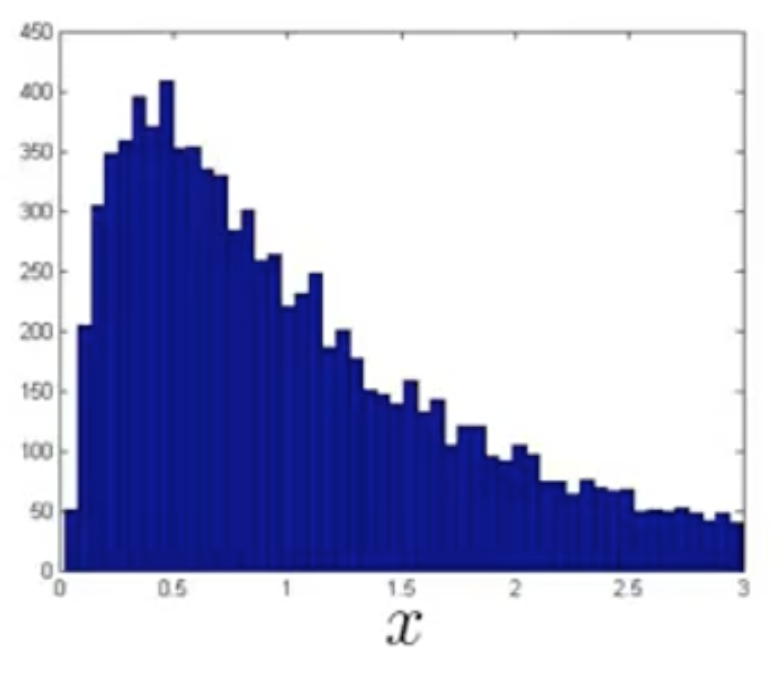
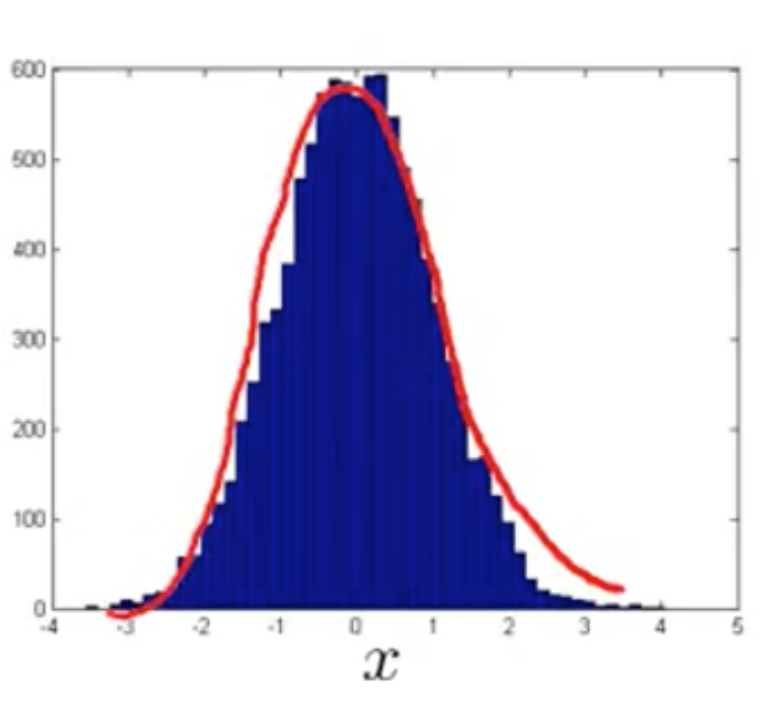
我们可以通过对数操作或者其他操作将他转化为高斯分布,例如,上面的特征经对数操作后形成的分布就非常接近于高斯分布:
多元高斯分布
独立多元正态分布
先假设n个变量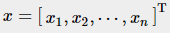 互不相关,且服从正态分布(维度不相关多元正态分布),各个维度的均值
互不相关,且服从正态分布(维度不相关多元正态分布),各个维度的均值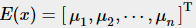 , 方差
, 方差 
根据联合概率密度公式:
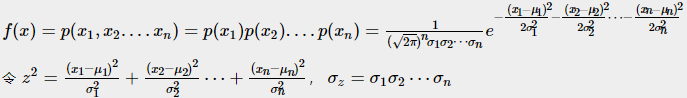
这样多元正态分布又可以写成一元那种漂亮的形式了(注意一元与多元的差别):
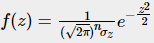
引入协方差矩阵表示σz代入标准化公式
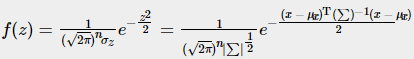
详细解释说明见:The Multivariate normal distribution,下同(相关多元高斯分布)
相关多元高斯分布
我们讨论多元正态分布的前提是多元变量之间是相互独立的,实际上,有很多应用场合,变量与变量之间是有关联的。以二元正态分布为例:
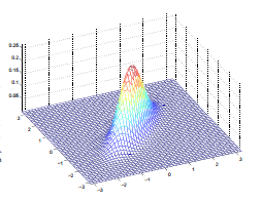
向输入平面作投影后的平面图:

以现在的坐标系来看,X1,X2是相关的,但是如果我们换一个角度,它们就是互不相关的了:

上述过程被称为去相关性,更专业一点叫做归化。经过一系列规归化,我们把新的期望、协方差、协方差的逆带入标准化公式:
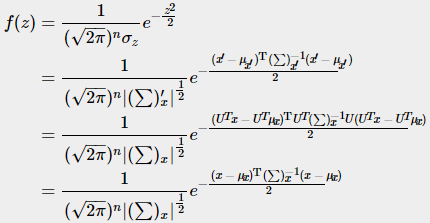
总结一下我们做了什么:
Ⅰ, 我们先定义了新的坐标系,通过矩阵 UT 将元素映射到新的坐标系,目的是去相关性
Ⅱ, 在新的坐标下,我们定义了新的期望、协方差、协方差的逆,他们都可以通过 U 与 UT计算出来,当然我们不用计算
Ⅲ, 套用标准公式,将新的期望、协方差的逆、协方差的行列式代入,发现最后的结果与U、UT无关
示例0 异常检测算法采用独立多元高斯分布无法解决的问题由相关多元高斯分布进行解决,介绍热力图对投影后的图像进行不同方向的拉伸。
独立多元高斯分布模型只是相关多元高斯分布模型的一个约束,它将相关多元高斯分布的等高线约束到了同轴分布(概率密度的等高线是沿着轴向的)!
https://blog.csdn.net/u014182497/article/details/82252456
https://zhidao.baidu.com/question/717195483776826085.html
https://blog.csdn.net/lql0716/article/details/68267829
https://blog.csdn.net/qq_23869697/article/details/80610361
https://blog.csdn.net/Flyingzhan/article/details/82502713
https://blog.csdn.net/hhaowang/article/details/83898881#commentBox
https://baijiahao.baidu.com/s?id=1621087027738177317&wfr=spider&for=pc
http://www.360doc.com/content/18/0608/06/31429017_760580081.shtml
最大似然估计、n阶矩、协方差(矩阵)、(多元)高斯分布 学习摘要的更多相关文章
- 又看了一次EM 算法,还有高斯混合模型,最大似然估计
先列明材料: 高斯混合模型的推导计算(英文版): http://www.seanborman.com/publications/EM_algorithm.pdf 这位翻译写成中文版: http://w ...
- 参数估计:最大似然估计MLE
http://blog.csdn.net/pipisorry/article/details/51461997 最大似然估计MLE 顾名思义,当然是要找到一个参数,使得L最大,为什么要使得它最大呢,因 ...
- 【MLE】最大似然估计Maximum Likelihood Estimation
模型已定,参数未知 已知某个随机样本满足某种概率分布,但是其中具体的参数不清楚,参数估计就是通过若干次试验,观察其结果,利用结果推出参数的大概值.最大似然估计是建立在这样的思想上:已知某个参数能使这个 ...
- 【ML数学知识】极大似然估计
它是建立在极大似然原理的基础上的一个统计方法,极大似然原理的直观想法是,一个随机试验如有若干个可能的结果A,B,C,... ,若在一次试验中,结果A出现了,那么可以认为实验条件对A的出现有利,也即出现 ...
- ML 徒手系列 最大似然估计
1.最大似然估计数学定义: 假设总体分布为f(x,θ),X1,X2...Xn为总体采样得到的样本.其中X1,X2...Xn独立同分布,可求得样本的联合概率密度函数为: 其中θ是需要求得的未知量,xi是 ...
- B-概率论-极大似然估计
[TOC] 更新.更全的<机器学习>的更新网站,更有python.go.数据结构与算法.爬虫.人工智能教学等着你:https://www.cnblogs.com/nickchen121/ ...
- LR为什么用极大似然估计,损失函数为什么是log损失函数(交叉熵)
首先,逻辑回归是一个概率模型,不管x取什么值,最后模型的输出也是固定在(0,1)之间,这样就可以代表x取某个值时y是1的概率 这里边的参数就是θ,我们估计参数的时候常用的就是极大似然估计,为什么呢?可 ...
- Maximum Likelihood 最大似然估计
Maximum Likelihood 最大似然估计 这个算法解决的问题是,当我们知道一组变量的密度分布函数与从总体采样的个体的时候,需要估计函数中的某些变量. 假设概率密度函数如下: 一般来说,为了计 ...
- 似然估计中为什么要取对数以GMM为例
1.往往假设特征之间独立同分布,那么似然函数往往是连城形式,直接求骗到不好搞,根据log可以把连乘变为连加. 2.另外概率值是小数,多个小数相乘容易赵成浮点数下溢,去log变为连加可以避免这个问题. ...
随机推荐
- 金蝶handler中 collection 代码片段理解
1,AtsOverTimeBillBatchEditHandler中collection的理解 SelectorItemCollection selectors = new SelectorItemC ...
- JAVA异常类Throwable解析
在 Java 中,所有的异常都有一个共同的祖先java.lang包中的 Throwable类. Throwable: 有两个重要的子类:Exception(异常) 和 Error(错误) :二者都是 ...
- 1026 程序运行时间 (15 分)C语言
题目描述 要获得一个C语言程序的运行时间,常用的方法是调用头文件time.h,其中提供了clock()函数,可以捕捉从程序开始运行到clock()被调用时所耗费的时间.这个时间单位是clock tic ...
- [Windows10]记一次修复注册表相关血案:该文件没有与之关联的应用来执行该操作。请安装应用,若已经安装应用,请在“默认应用设置”页面中创建关联。
今天闲得蛋疼清理了一下右键菜单,于是在之后某时刻使用Everything的“双击路径列打开目录”功能时发现异常: [Window Title] Everything.exe [Content] 该文件 ...
- Match3 Module For Game(THDN)
介绍 THDN的核心机制为Match3的利用,本文对Match3 Gameplay进行记录,并对其进行改良.THDN作为RogueLIke性质的游戏,玩家在随机生成的dungeon里进行探索并获 ...
- vue 项目使用JSbrideg.js与app通信
一.建立JSbrideg.js文件 var jsBridge = { isAndroid: null, isIOS: null, callHandlerFunc: functi ...
- 从零开始入门 K8s | GPU 管理和 Device Plugin 工作机制
作者 | 车漾 阿里巴巴高级技术专家 本文整理自<CNCF x Alibaba 云原生技术公开课>第 20 讲. 关注"阿里巴巴云原生"公众号,回复关键词" ...
- 详解定时任务中的 cron 表达式
1.前言 我们经常使用 cron 表达式来定义定时任务的执行策略,今天我们就总结一下 cron 表达式的一些相关知识. 2. cron 表达式的定义 cron 表达式是一个字符串,该字符串由 6 个空 ...
- TensorFlow——训练模型的保存和载入的方法介绍
我们在训练好模型的时候,通常是要将模型进行保存的,以便于下次能够直接的将训练好的模型进行载入. 1.保存模型 首先需要建立一个saver,然后在session中通过saver的save即可将模型保存起 ...
- cogs 1176. [郑州101中学] 月考 Set 做法
1176. [郑州101中学] 月考 ★★☆ 输入文件:mtest.in 输出文件:mtest.out 简单对比时间限制:1 s 内存限制:128 MB [题目描述] 在上次的月考中B ...