《操作系统真象还原》ELF文件
下面是第五章部分内容的收获。
用C语言编写内核
一直以来我们都是用汇编语言编写程序的,但接下来我们或许很少用汇编语言编写代码了,大多数都是使用C语言。为什么要这样呢?书上的解释我看的不是很懂,只能结合书上谈谈我的见解,个人觉得有两个原因:
汇编语言编写代码较高级语言来说还是麻烦很多的,毕竟大家试试就知道了,一句C语言代码,可能要几句汇编语言代码才能与之对应。那有人说CPU能执行C语言代码吗,当然不,CPU最终执行的是机器指令,也就是由0和1组成的机器指令。所以肯定需要一个东西将C语言转换为机器指令,这个东西就是编译器,我们平常用的GCC编译器就是用做这个用途。所以有了编译器,我们编写代码就方便了很多,简简单单几句C语言代码就能完成N句机器指令完成的工作,因此为何不用C语言呢。
除了编写难度的问题,另一个点就是像执行lgdt,sgdt等一些特权指令,或者对eflag或者crX控制寄存器等具体某个寄存器进行读写,一般只能通过汇编语言才能做到,因为C语言并不会直接提供对偏底层数据(寄存器)的操作。而接下来的大多功能都不需要使用上面提到的功能,所以单靠C语言和编译器就能达到我们的需求了。
编写简单的内核
下面编写一个简单的内核代码main.c:
int main() {
while();
return ;
}
没错,就是这么简单,这个程序可以帮我们理解如何加载一段可执行程序到内存里面的。
编译一下吧,输入以下指令:
gcc -c -o main.o main.c
参数-c代表汇编程序到目标文件,不进行链接操作。
参数-o代表将输出文件以指定的文件名输出。
这个时候输出的目标文件并不可以直接加载到内存里执行,因为它还是个“半成品”,它还没有被编排号地址,这需要通过链接器进一步将这个目标文件链接成可执行文件。
nm命令是一个查看文件各个符号地址的工具,我们试一下:
nm main.o
然后我们就可以看到下面的输出:

这代表符号main地址还是在0x0下,这显然是没有编址好的符号。
ld命令是个链接器程序,我们使用ld命令去将main.o文件链接成可执行文件:
ld main.o -Ttext 0xc0001500 -e main -o kernel.bin
解释一下参数,-Ttext代表加载节.text到0xc0001500地址,.text包含程序执行的代码,-Ttext就指定了.text的起始地址,至于这个地址,后面会提到。-e指定入口符号或入口地址,代表程序从哪个符号或地址开始执行。为什么需要指定main为入口符号呢,这是因为一般来说程序的默认入口符号都是_start,我们这里需要将main符号作为入口符号,所以需要显式地指定。-o代表以什么文件名生成最终的可执行文件。
ELF文件格式
回忆一下,在此之前,我们是怎么调用程序的,BIOS初始化之后,将第0扇区的MBR加载到0x7c00并且跳到那里执行,mbr再去调用loader,loader的地址是0x900。可以看到这些程序的地址都是固定的,并且调用方和被调用方需要约定好地址,存储在哪。这种方式是很不灵活的,我们可以提供一种较为灵活地方式来加载各种可执行程序吗?有,这种方式就是文件头+文件体。
文件头和文件体的运用还是不少的,比如我们学习计算机网络时,从应用层到链路层每一层都会添加一个头部用来描述这一层用的是什么协议,大小是多少等等。头部像是书上的目录,而文件体就像书的每一章内容,通过书上目录显示的每一章的页码,我们就能找到对应章的位置。
个人理解,文件头+文件体的方式并不是说不需要指定入口地址,它只不过是将入口地址等信息放到一个统一的模块去存储,从某种意义上说,其实和加载MBR和Loader没啥区别,都是需要得到入口地址,而这个入口地址无非是一个放在了一个常数变量里(宏定义),一个放在了一个类似表的东西(文件头),只不过我们约定好了一种文件格式,我们都总能根据格式规范找到入口地址,不再需要自己去额外定义常数,这会更加统一和灵活一些,就像C语言定义了一个结构体,结构体里定义好了有哪些成员,我们预先知道了这个结构体有什么成员,在哪个位置,到这个位置取出变量即可,文件头就和结构体类似,假设文件头告诉你它包含文件体大小和入口地址两个成员,而入口地址在文件体的第二个成员的位置,你去那里找就好了,这样的话任何可执行文件都可以按这种方式找到这个入口地址,不再需要定义变量这种不灵活的方式了。另外值得注意的一点是,程序头部是编译器生成的,那么入口地址自然也是编译器去赋值的 ,当然赋值多少要看编译器怎么实现,我们可以让编译器生成目标文件时指定入口地址,也可以让编译器自己去决定入口地址。
那么对于程序来说,程序头和程序体需要包含什么呢?程序头最基本需要包含程序体的大小和程序的入口地址,程序体大小限制了程序体的边界,程序入口地址方便让我们跳到指定的地址执行代码;程序体自然包括程序代码和其他程序数据了。如下图:
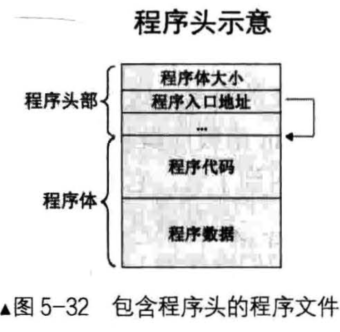
基本的思想就是这样,但具体到实际的话,会有很多细节上的东西,比如如何识别这是个可执行文件,一个程序包含许多节(链接后会划分成段),如何在头部指定这些节或段的具体位置等等。
那么操作系统显然是预先知道这个约定的,但具体怎么规划或实现在各个操作系统都不太一样,我们可以说每个操作系统都有自己的文件格式,即自己文件头和文件体的规划。如Window下可执行文件格式为PE,Linux下采用的可执行文件格式是ELF,Mac系统下的可执行文件格式为Mach-O。说个题外话,一开始我还想再Mac系统下做接下来的实验的,不过一路坐下来发现mac系统和linux系统下文件格式有很大的不同,学习成本有点高,不过有兴趣的同学可以试试,接下来说的还是以Linux的文件格式来加载我们的程序。
Linux下的可执行文件格式为ELF,即Executable and Linkable Format,可执行链接格式。与ELF相关的文件类型有三种,是我们需要区分一下的,如下图:

我们将待重定位文件即没有编址好的文件称为目标文件,将动态链接库称为共享目标文件,将编译链接后的文件称为可执行文件。但以ELF规范的命名方式,这三种文件都称之为ELF目标文件。为了避免混淆,之后我们说目标文件是这三种类型的文件,不单单指待重定位的文件。
段和节
之前我们有涉及过段和节的概念,节,之前有说过,就是人为将代码划分成几个模块,便于程序员理解模块的功能,节的声明并不会影响地址的编排。段不是内存的段,而是文件概念上的段,内存里真正运行的是段而不是节,所以ELF有个专门的字段叫程序头表,它描述段的存储信息,以“程序”头表称呼代表段才是程序真正执行的部分。节和段又是什么关系呢,在链接器将重定位文件合并为可执行文件时,多个节最终会合并成段,虽然节的声明并不会改变地址编排,但节到段的过程可能会改变节中指令的地址,毕竟节不是程序真正执行的部分,下面会结合例子讲讲这个过程。
本书对目标文件的节和段的描述不算太具体,以下结合《深入理解计算机系统》的链接章节进行补充。
可重定位目标文件
在可重定位目标文件中只有节,没有段,一个典型的ELF可重定位目标文件的结构如下图:
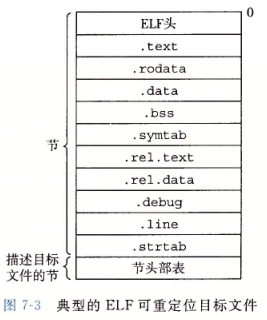
把《深入理解计算机系统》对每个节的描述复制过来 ,让大家看看:
- .text:已编译程序的机器代码。
- .rodata:只读数据,比如printf语句中的格式串和开关(switch)语句的跳转表。
- .data:已初始化的全局C变量。局部C变量在运行时被保存在栈中,既不出现在.data中,也不出现在.bss节中。
- .bss:未初始化的全局C变量。在目标文件中这个节不占据实际的空间,它仅仅是一个占位符。目标文件格式区分初始化和未初始化变量是为了空间效率在:在目标文件中,未初始化变量不需要占据任何实际的磁盘空间。
- .symtab:一个符号表(symbol table),它存放在程序中被定义和引用的函数和全局变量的信息。一些程序员错误地认为必须通过-g选项来编译一个程序,得到符号表信息。实际上,每个可重定位目标文件在.symtab中都有一张符号表。然而,和编译器中的符号表不同,.symtab符号表不包含局部变量的表目。
- .rel.text:当链接噐把这个目标文件和其他文件结合时,.text节中的许多位置都需要修改。一般而言,任何调用外部函数或者引用全局变量的指令都需要修改。另一方面调用本地函数的指令则不需要修改。注意,可执行目标文件中并不需要重定位信息,因此通常省略,除非使用者显式地指示链接器包含这些信息。
- .rel.data:被模块定义或引用的任何全局变量的信息。一般而言,任何已初始化全局变量的初始值是全局变量或者外部定义函数的地址都需要被修改。
- .debug:一个调试符号表,其有些表目是程序中定义的局部变量和类型定义,有些表目是程序中定义和引用的全局变量,有些是原始的C源文件。只有以-g选项调用编译驱动程序时,才会得到这张表。
- .line:原始C源程序中的行号和.text节中机器指令之间的映射。只有以-g选项调用编译驱动程序时,才会得到这张表。
- .strtab:一个字符串表,其内容包括.symtab和.debug节中的符号表,以及节头部中的节名字。字符串表就是以null结尾的字符串序列。
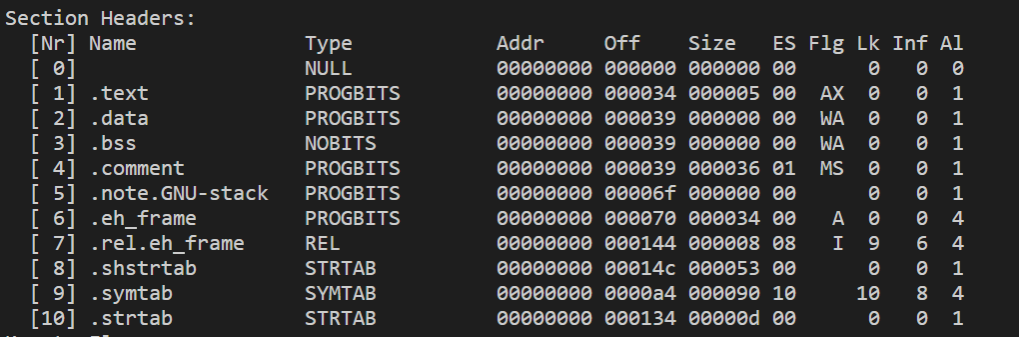
上面我们不是生成了main.o待重定位目标文件吗,通过readelf工具看看里面有什么节:
readelf -S main.o
输出结果如下:
可执行目标文件
一个典型的ELF可执行文件结构如下图:
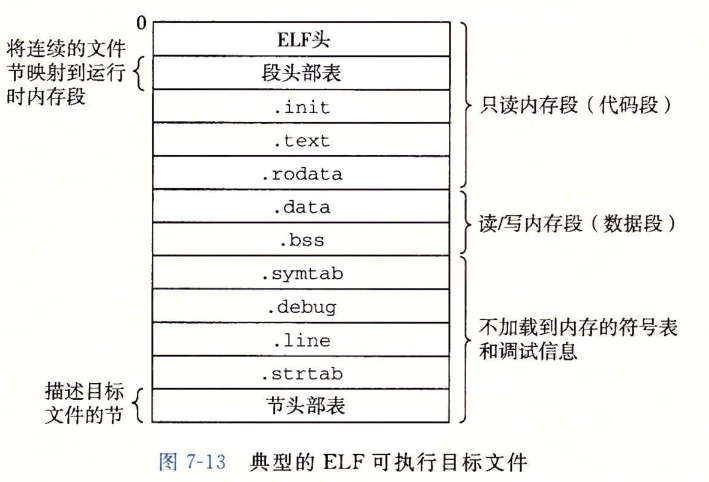
此时的可执行文件已经将各个节合并成段了,我们也用readelf工具查看一下kernel.bin段和节的情况。
readelf -a kernel.bin
通过上面的命令得到ELF目标文件的全部信息。
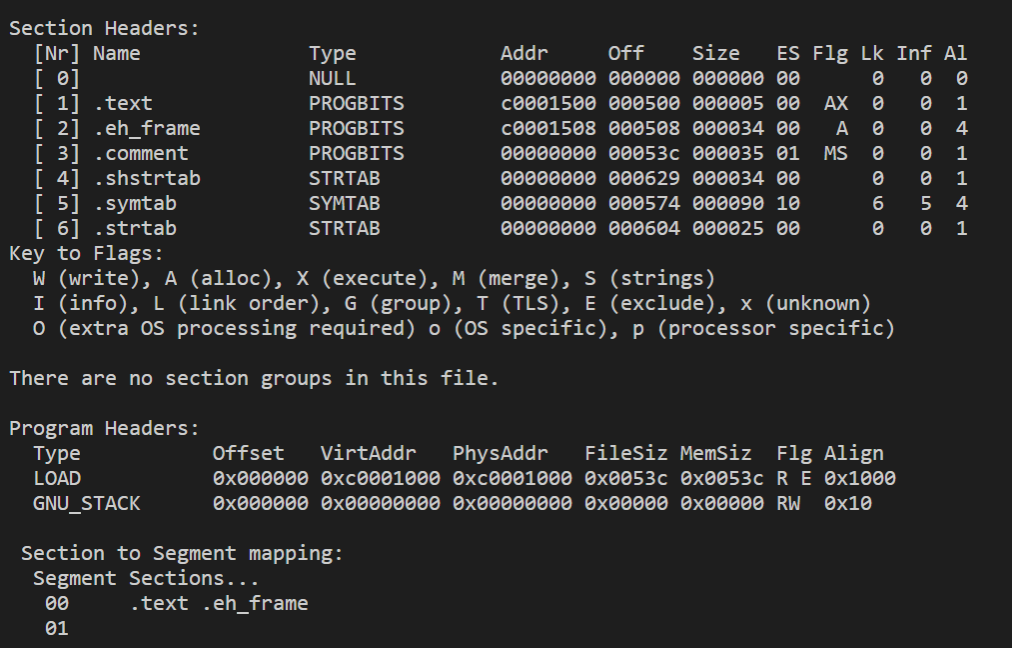
通过上图,我们可以发现可执行目标文件只剩下几个section,重定位目标文件里的一些section不见了,分别是.data,.rel.eh_frame,.note.GNU-stack,.bss节。.rel.eh_frame好理解,毕竟只用作重定位,帮助被引用的符号找到正确的地址,而.data,.bss,.note.GNU-stack,个人觉得是因为它们的大小为0,到可执行文件就没必要存在了。
最终可执行文件将节合并为两个段,将.text,.eh_frame合并为一个段LOAD,可以称之为代码段,因为包含.text可执行的代码,还有一个段GNU_STACK不知道是什么用途,而且它大小为0就不管了。还有一些节并没有合并成段,原因是它们并不是程序执行的部分,没必要加载到内存里面,所以看不到有段包含它们。
我们再把注意力放到节和段的编址上,着重看.text和.eh_frame,因为它们最终组成了代码段,我们发现.text和.eh_frame的地址变了,它们的相对距离也变了;在可重定位文件中,.text和.eh_frame是分开的,而在可执行文件中,.text和.eh_frame是紧挨着的,所以合并成段后,段所包含的节地址是连续的。
相同名称的节也会合并在一起
具有相同名字的节最终会合并在一起。
为了帮助理解节最终合并成段的过程,我下面编写一段小代码test.S:
section .data
db 0x1,0x2
section .text
add esp,
section .data
db 0x3,0x4
section .text
add esp,
编译该文件:
nasm test.S
再反汇编生成的文件:
ndisasm test
输出如下:

由于是直接利用nasm工具将汇编代码转化成可执行代码的,我们并不知道哪些节合并成什么段,但我们可以通过地址去猜测哪些节合并在一起了。
根据上面的输出,所有.data的节合并在一起了,所有.text的节合并在一起了,而且地址是连续的。还有就是.text和.data同时存在时,会把.text优先放到前面,因为按约定俗成的叫法,.text是可执行的部分,汇编器nasm优先把.text放在前面。如果把.text和.data改成.text1和.data1,这样就是用户自己定义的节,结果是.data1会放在前面,所以如果不存在.text和.data这类约定的节,相同名称的节合并成段时会按照这些节之中第一个的位置来编排地址。
至此我们对段和节,以及它们直接的关系都有比较直观的理解了。
ELF布局
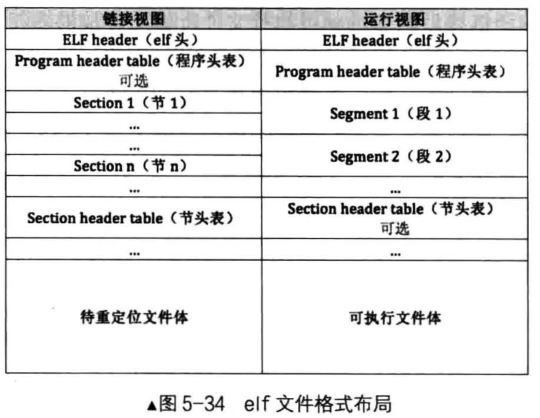
理解完节和段之后,我们再从ELF整个布局理解一下,操作系统是怎么将ELF文件加载到内存里面的。
ELF的布局如上图所示,ELF的布局在链接阶段和运行阶段并不太一样,主要是因为节最终会合并成段,不过我们发现ELF头是共同存在的。
ELF头
ELF头部结构如下图,可以去linux系统下/usr/include/elf.h找到这个定义:
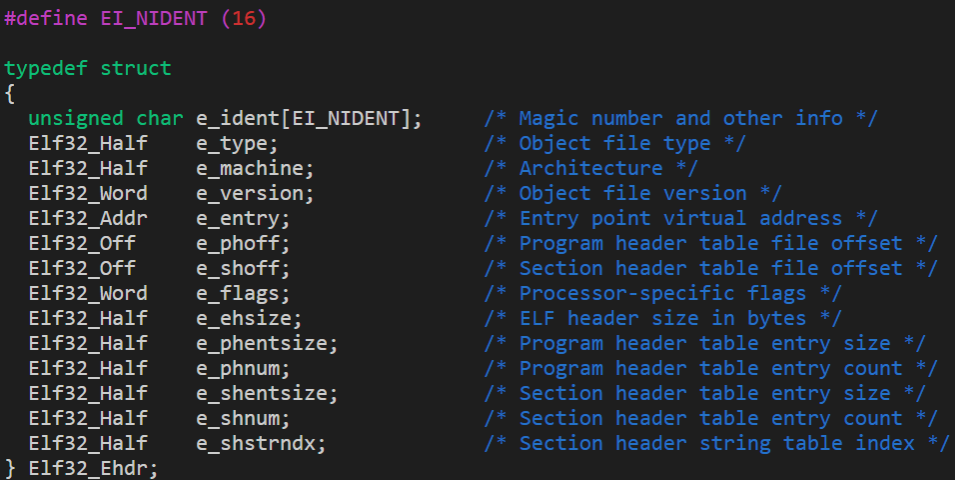
ELF头的每个成员含义可以在注释里面看到,由于我们需要获取程序段的代码,我们需要把注意力放在和Program header相关的成员上,在后面代码编写上我们主要用到e_phentsize、e_phoff、e_phnum,分别代表程序头表的大小、距离文件开头的偏移、个数。

每个成员的字节大小可以根据上图得到,这有什么作用呢?由于我们获取文件段还是要用汇编代码编写的,所以我们需要知道这些成员距离文件开头的偏移位置,e_phentsize、e_phoff、e_phnum距离文件开头的位置分别为42,28,44。
程序头表
虽然说了节和段是什么东西,但还没讲程序头表是什么,程序头表是程序头的数组,程序头表的程序头地址是连续的,不是离散的。程序头是什么,程序头是描述段的数据结构。
下面看一下程序头的结构是怎样的。

每个成员的含义可以在注释看到,后面我们主要用到p_type、p_filesz、p_offset、p_vaddr,分别代表段的类型、文件内的大小、距离文件开头的偏移、在内存中的地址。
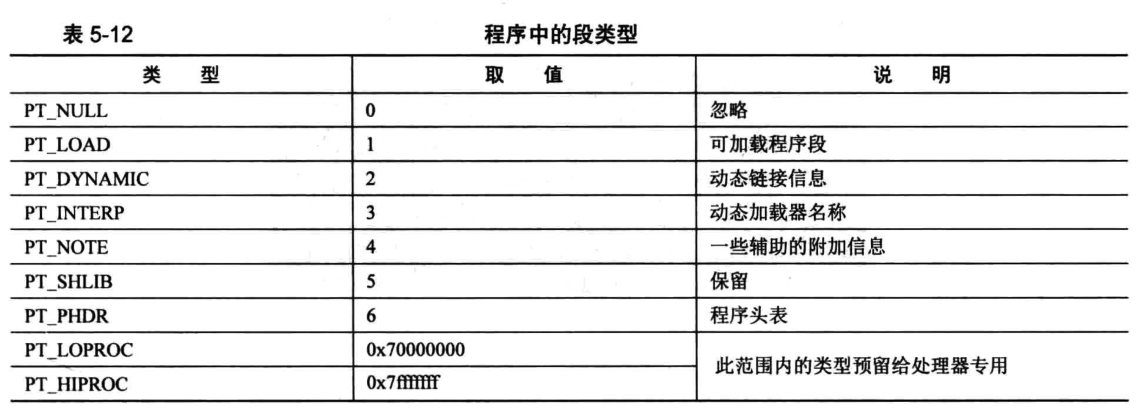
p_type取值与含义如下:
加载段到内存
综合上面一节,我们可以得出加载段到内存的流程:
①得到程序头的大小
②得到第一个程序头的偏移量
③得到程序头的个数
开始复制段:
④判断段类型是否是忽略,是的话不复制,跳到⑦,否则继续
⑤得到段在文件的偏移量、段的大小、在内存的地址
⑥将段复制到内存里
⑦判断是否全部段都复制好了,不是的话,跳到下一个程序头,跳到④,否则复制完成
下面开始编写代码,首先将kernel.bin写入硬盘:
dd if=kernel.bin of=hd60M.img bs= count= seek= conv=notrunc
为什么count=200,因为内核之后会越来越大,我们将count写大点以免写入硬盘写少了,虽然写那么大,但是dd命令会自己判断写入的数据量,不用担心。
seek=9,这个没有什么强制要求,不过离之前写入硬盘的扇区远一点,可能会灵活一些?
下面把loader.S修改的代码以红色字体呈现,代码来自书的资料:
%include "boot.inc"
section loader vstart=LOADER_BASE_ADDR
;构建gdt及其内部的描述符
GDT_BASE: dd 0x00000000
dd 0x00000000 CODE_DESC: dd 0x0000FFFF
dd DESC_CODE_HIGH4 DATA_STACK_DESC: dd 0x0000FFFF
dd DESC_DATA_HIGH4 VIDEO_DESC: dd 0x80000007 ; limit=(0xbffff-0xb8000)/4k=0x7
dd DESC_VIDEO_HIGH4 ; 此时dpl为0 GDT_SIZE equ $ - GDT_BASE
GDT_LIMIT equ GDT_SIZE -
times dq ; 此处预留60个描述符的空位(slot)
SELECTOR_CODE equ (0x0001<<) + TI_GDT + RPL0 ; 相当于(CODE_DESC - GDT_BASE)/8 + TI_GDT + RPL0
SELECTOR_DATA equ (0x0002<<) + TI_GDT + RPL0 ; 同上
SELECTOR_VIDEO equ (0x0003<<) + TI_GDT + RPL0 ; 同上 ; total_mem_bytes用于保存内存容量,以字节为单位,此位置比较好记。
; 当前偏移loader.bin文件头0x200字节,loader.bin的加载地址是0x900,
; 故total_mem_bytes内存中的地址是0xb00.将来在内核中咱们会引用此地址
total_mem_bytes dd
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; ;以下是定义gdt的指针,前2字节是gdt界限,后4字节是gdt起始地址
gdt_ptr dw GDT_LIMIT
dd GDT_BASE ;人工对齐:total_mem_bytes4字节+gdt_ptr6字节+ards_buf244字节+ards_nr2,共256字节
ards_buf times db
ards_nr dw ;用于记录ards结构体数量 loader_start: ;------- int 15h eax = 0000E820h ,edx = 534D4150h ('SMAP') 获取内存布局 ------- xor ebx, ebx ;第一次调用时,ebx值要为0
mov edx, 0x534d4150 ;edx只赋值一次,循环体中不会改变
mov di, ards_buf ;ards结构缓冲区
.e820_mem_get_loop: ;循环获取每个ARDS内存范围描述结构
mov eax, 0x0000e820 ;执行int 0x15后,eax值变为0x534d4150,所以每次执行int前都要更新为子功能号。
mov ecx, ;ARDS地址范围描述符结构大小是20字节
int 0x15
jc .e820_failed_so_try_e801 ;若cf位为1则有错误发生,尝试0xe801子功能
add di, cx ;使di增加20字节指向缓冲区中新的ARDS结构位置
inc word [ards_nr] ;记录ARDS数量
cmp ebx, ;若ebx为0且cf不为1,这说明ards全部返回,当前已是最后一个
jnz .e820_mem_get_loop ;在所有ards结构中,找出(base_add_low + length_low)的最大值,即内存的容量。
mov cx, [ards_nr] ;遍历每一个ARDS结构体,循环次数是ARDS的数量
mov ebx, ards_buf
xor edx, edx ;edx为最大的内存容量,在此先清0
.find_max_mem_area: ;无须判断type是否为1,最大的内存块一定是可被使用
mov eax, [ebx] ;base_add_low
add eax, [ebx+] ;length_low
add ebx, ;指向缓冲区中下一个ARDS结构
cmp edx, eax ;冒泡排序,找出最大,edx寄存器始终是最大的内存容量
jge .next_ards
mov edx, eax ;edx为总内存大小
.next_ards:
loop .find_max_mem_area
jmp .mem_get_ok ;------ int 15h ax = E801h 获取内存大小,最大支持4G ------
; 返回后, ax cx 值一样,以KB为单位,bx dx值一样,以64KB为单位
; 在ax和cx寄存器中为低16M,在bx和dx寄存器中为16MB到4G。
.e820_failed_so_try_e801:
mov ax,0xe801
int 0x15
jc .e801_failed_so_try88 ;若当前e801方法失败,就尝试0x88方法 ;1 先算出低15M的内存,ax和cx中是以KB为单位的内存数量,将其转换为以byte为单位
mov cx,0x400 ;cx和ax值一样,cx用做乘数
mul cx
shl edx,
and eax,0x0000FFFF
or edx,eax
add edx, 0x100000 ;ax只是15MB,故要加1MB
mov esi,edx ;先把低15MB的内存容量存入esi寄存器备份 ;2 再将16MB以上的内存转换为byte为单位,寄存器bx和dx中是以64KB为单位的内存数量
xor eax,eax
mov ax,bx
mov ecx, 0x10000 ;0x10000十进制为64KB
mul ecx ;32位乘法,默认的被乘数是eax,积为64位,高32位存入edx,低32位存入eax.
add esi,eax ;由于此方法只能测出4G以内的内存,故32位eax足够了,edx肯定为0,只加eax便可
mov edx,esi ;edx为总内存大小
jmp .mem_get_ok ;----------------- int 15h ah = 0x88 获取内存大小,只能获取64M之内 ----------
.e801_failed_so_try88:
;int 15后,ax存入的是以kb为单位的内存容量
mov ah, 0x88
int 0x15
jc .error_hlt
and eax,0x0000FFFF ;16位乘法,被乘数是ax,积为32位.积的高16位在dx中,积的低16位在ax中
mov cx, 0x400 ;0x400等于1024,将ax中的内存容量换为以byte为单位
mul cx
shl edx, ;把dx移到高16位
or edx, eax ;把积的低16位组合到edx,为32位的积
add edx,0x100000 ;0x88子功能只会返回1MB以上的内存,故实际内存大小要加上1MB .mem_get_ok:
mov [total_mem_bytes], edx ;将内存换为byte单位后存入total_mem_bytes处。 ;----------------- 准备进入保护模式 -------------------
;1 打开A20
;2 加载gdt
;3 将cr0的pe位置1 ;----------------- 打开A20 ----------------
in al,0x92
or al,0000_0010B
out 0x92,al ;----------------- 加载GDT ----------------
lgdt [gdt_ptr] ;----------------- cr0第0位置1 ----------------
mov eax, cr0
or eax, 0x00000001
mov cr0, eax jmp dword SELECTOR_CODE:p_mode_start ; 刷新流水线,避免分支预测的影响,这种cpu优化策略,最怕jmp跳转,
; 这将导致之前做的预测失效,从而起到了刷新的作用。
.error_hlt: ;出错则挂起
hlt [bits ]
p_mode_start:
mov ax, SELECTOR_DATA
mov ds, ax
mov es, ax
mov ss, ax
mov esp,LOADER_STACK_TOP
mov ax, SELECTOR_VIDEO
mov gs, ax ; ------------------------- 加载kernel ----------------------
mov eax, KERNEL_START_SECTOR ; kernel.bin所在的扇区号
mov ebx, KERNEL_BIN_BASE_ADDR ; 从磁盘读出后,写入到ebx指定的地址
mov ecx, 200 ; 读入的扇区数 call rd_disk_m_32 ; 创建页目录及页表并初始化页内存位图
call setup_page ;要将描述符表地址及偏移量写入内存gdt_ptr,一会用新地址重新加载
sgdt [gdt_ptr] ; 存储到原来gdt所有的位置 ;将gdt描述符中视频段描述符中的段基址+0xc0000000
mov ebx, [gdt_ptr + ]
or dword [ebx + 0x18 + ], 0xc0000000 ;视频段是第3个段描述符,每个描述符是8字节,故0x18。
;段描述符的高4字节的最高位是段基址的31~24位 ;将gdt的基址加上0xc0000000使其成为内核所在的高地址
add dword [gdt_ptr + ], 0xc0000000 add esp, 0xc0000000 ; 将栈指针同样映射到内核地址 ; 把页目录地址赋给cr3
mov eax, PAGE_DIR_TABLE_POS
mov cr3, eax ; 打开cr0的pg位(第31位)
mov eax, cr0
or eax, 0x80000000
mov cr0, eax ;在开启分页后,用gdt新的地址重新加载
lgdt [gdt_ptr] ; 重新加载 ;;;;;;;;;;;;;;;;;;;;;;;;;;;; 此时不刷新流水线也没问题 ;;;;;;;;;;;;;;;;;;;;;;;;
;由于一直处在32位下,原则上不需要强制刷新,经过实际测试没有以下这两句也没问题.
;但以防万一,还是加上啦,免得将来出来莫句奇妙的问题.
jmp SELECTOR_CODE:enter_kernel ;强制刷新流水线,更新gdt
enter_kernel:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
call kernel_init
mov esp, 0xc009f000
jmp KERNEL_ENTRY_POINT ; 用地址0x1500访问测试,结果ok ;----------------- 将kernel.bin中的segment拷贝到编译的地址 -----------
kernel_init:
xor eax, eax
xor ebx, ebx ;ebx记录程序头表地址
xor ecx, ecx ;cx记录程序头表中的program header数量
xor edx, edx ;dx 记录program header尺寸,即e_phentsize mov dx, [KERNEL_BIN_BASE_ADDR + 42] ; 偏移文件42字节处的属性是e_phentsize,表示program header大小
mov ebx, [KERNEL_BIN_BASE_ADDR + 28] ; 偏移文件开始部分28字节的地方是e_phoff,表示第1 个program header在文件中的偏移量
; 其实该值是0x34,不过还是谨慎一点,这里来读取实际值
add ebx, KERNEL_BIN_BASE_ADDR
mov cx, [KERNEL_BIN_BASE_ADDR + 44] ; 偏移文件开始部分44字节的地方是e_phnum,表示有几个program header
.each_segment:
cmp byte [ebx + 0], PT_NULL ; 若p_type等于 PT_NULL,说明此program header未使用。
je .PTNULL ;为函数memcpy压入参数,参数是从右往左依然压入.函数原型类似于 memcpy(dst,src,size)
push dword [ebx + 16] ; program header中偏移16字节的地方是p_filesz,压入函数memcpy的第三个参数:size
mov eax, [ebx + 4] ; 距程序头偏移量为4字节的位置是p_offset
add eax, KERNEL_BIN_BASE_ADDR ; 加上kernel.bin被加载到的物理地址,eax为该段的物理地址
push eax ; 压入函数memcpy的第二个参数:源地址
push dword [ebx + 8] ; 压入函数memcpy的第一个参数:目的地址,偏移程序头8字节的位置是p_vaddr,这就是目的地址
call mem_cpy ; 调用mem_cpy完成段复制
add esp,12 ; 清理栈中压入的三个参数
.PTNULL:
add ebx, edx ; edx为program header大小,即e_phentsize,在此ebx指向下一个program header
loop .each_segment
ret ;---------- 逐字节拷贝 mem_cpy(dst,src,size) ------------
;输入:栈中三个参数(dst,src,size)
;输出:无
;---------------------------------------------------------
mem_cpy:
cld
push ebp
mov ebp, esp
push ecx ; rep指令用到了ecx,但ecx对于外层段的循环还有用,故先入栈备份
mov edi, [ebp + 8] ; dst
mov esi, [ebp + 12] ; src
mov ecx, [ebp + 16] ; size
rep movsb ; 逐字节拷贝 ;恢复环境
pop ecx
pop ebp
ret ;------------- 创建页目录及页表 ---------------
setup_page:
;先把页目录占用的空间逐字节清0
mov ecx,
mov esi,
.clear_page_dir:
mov byte [PAGE_DIR_TABLE_POS + esi],
inc esi
loop .clear_page_dir ;开始创建页目录项(PDE)
.create_pde: ; 创建Page Directory Entry
mov eax, PAGE_DIR_TABLE_POS
add eax, 0x1000 ; 此时eax为第一个页表的位置及属性
mov ebx, eax ; 此处为ebx赋值,是为.create_pte做准备,ebx为基址。 ; 下面将页目录项0和0xc00都存为第一个页表的地址,
; 一个页表可表示4MB内存,这样0xc03fffff以下的地址和0x003fffff以下的地址都指向相同的页表,
; 这是为将地址映射为内核地址做准备
or eax, PG_US_U | PG_RW_W | PG_P ; 页目录项的属性RW和P位为1,US为1,表示用户属性,所有特权级别都可以访问.
mov [PAGE_DIR_TABLE_POS + 0x0], eax ; 第1个目录项,在页目录表中的第1个目录项写入第一个页表的位置(0x101000)及属性(3)
mov [PAGE_DIR_TABLE_POS + 0xc00], eax ; 一个页表项占用4字节,0xc00表示第768个页表占用的目录项,0xc00以上的目录项用于内核空间,
; 也就是页表的0xc0000000~0xffffffff共计1G属于内核,0x0~0xbfffffff共计3G属于用户进程.
sub eax, 0x1000
mov [PAGE_DIR_TABLE_POS + ], eax ; 使最后一个目录项指向页目录表自己的地址 ;下面创建页表项(PTE)
mov ecx, ; 1M低端内存 / 每页大小4k = 256
mov esi,
mov edx, PG_US_U | PG_RW_W | PG_P ; 属性为7,US=1,RW=1,P=1
.create_pte: ; 创建Page Table Entry
mov [ebx+esi*],edx ; 此时的ebx已经在上面通过eax赋值为0x101000,也就是第一个页表的地址
add edx,
inc esi
loop .create_pte ;创建内核其它页表的PDE
mov eax, PAGE_DIR_TABLE_POS
add eax, 0x2000 ; 此时eax为第二个页表的位置
or eax, PG_US_U | PG_RW_W | PG_P ; 页目录项的属性RW和P位为1,US为0
mov ebx, PAGE_DIR_TABLE_POS
mov ecx, ; 范围为第769~1022的所有目录项数量
mov esi,
.create_kernel_pde:
mov [ebx+esi*], eax
inc esi
add eax, 0x1000
loop .create_kernel_pde
ret ;-------------------------------------------------------------------------------
;功能:读取硬盘n个扇区
rd_disk_m_32:
;-------------------------------------------------------------------------------
; eax=LBA扇区号
; ebx=将数据写入的内存地址
; ecx=读入的扇区数
mov esi,eax ; 备份eax
mov di,cx ; 备份扇区数到di
;读写硬盘:
;第1步:设置要读取的扇区数
mov dx,0x1f2
mov al,cl
out dx,al ;读取的扇区数 mov eax,esi ;恢复ax ;第2步:将LBA地址存入0x1f3 ~ 0x1f6 ;LBA地址7~0位写入端口0x1f3
mov dx,0x1f3
out dx,al ;LBA地址15~8位写入端口0x1f4
mov cl,
shr eax,cl
mov dx,0x1f4
out dx,al ;LBA地址23~16位写入端口0x1f5
shr eax,cl
mov dx,0x1f5
out dx,al shr eax,cl
and al,0x0f ;lba第24~27位
or al,0xe0 ; 设置7~4位为1110,表示lba模式
mov dx,0x1f6
out dx,al ;第3步:向0x1f7端口写入读命令,0x20
mov dx,0x1f7
mov al,0x20
out dx,al ;;;;;;; 至此,硬盘控制器便从指定的lba地址(eax)处,读出连续的cx个扇区,下面检查硬盘状态,不忙就能把这cx个扇区的数据读出来 ;第4步:检测硬盘状态
.not_ready: ;测试0x1f7端口(status寄存器)的的BSY位
;同一端口,写时表示写入命令字,读时表示读入硬盘状态
nop
in al,dx
and al,0x88 ;第4位为1表示硬盘控制器已准备好数据传输,第7位为1表示硬盘忙
cmp al,0x08
jnz .not_ready ;若未准备好,继续等。 ;第5步:从0x1f0端口读数据
mov ax, di ;以下从硬盘端口读数据用insw指令更快捷,不过尽可能多的演示命令使用,
;在此先用这种方法,在后面内容会用到insw和outsw等 mov dx, ;di为要读取的扇区数,一个扇区有512字节,每次读入一个字,共需di*512/2次,所以di*256
mul dx
mov cx, ax
mov dx, 0x1f0
.go_on_read:
in ax,dx
mov [ebx], ax
add ebx,
; 由于在实模式下偏移地址为16位,所以用bx只会访问到0~FFFFh的偏移。
; loader的栈指针为0x900,bx为指向的数据输出缓冲区,且为16位,
; 超过0xffff后,bx部分会从0开始,所以当要读取的扇区数过大,待写入的地址超过bx的范围时,
; 从硬盘上读出的数据会把0x0000~0xffff的覆盖,
; 造成栈被破坏,所以ret返回时,返回地址被破坏了,已经不是之前正确的地址,
; 故程序出会错,不知道会跑到哪里去。
; 所以改为ebx代替bx指向缓冲区,这样生成的机器码前面会有0x66和0x67来反转。
; 0X66用于反转默认的操作数大小! 0X67用于反转默认的寻址方式.
; cpu处于16位模式时,会理所当然的认为操作数和寻址都是16位,处于32位模式时,
; 也会认为要执行的指令是32位.
; 当我们在其中任意模式下用了另外模式的寻址方式或操作数大小(姑且认为16位模式用16位字节操作数,
; 32位模式下用32字节的操作数)时,编译器会在指令前帮我们加上0x66或0x67,
; 临时改变当前cpu模式到另外的模式下.
; 假设当前运行在16位模式,遇到0X66时,操作数大小变为32位.
; 假设当前运行在32位模式,遇到0X66时,操作数大小变为16位.
; 假设当前运行在16位模式,遇到0X67时,寻址方式变为32位寻址
; 假设当前运行在32位模式,遇到0X67时,寻址方式变为16位寻址. loop .go_on_read
ret
头文件boot.inc增加如下:
;------------- loader和kernel ---------- LOADER_BASE_ADDR equ 0x900
LOADER_STACK_TOP equ LOADER_BASE_ADDR
LOADER_START_SECTOR equ 0x2 KERNEL_BIN_BASE_ADDR equ 0x70000
KERNEL_START_SECTOR equ 0x9
KERNEL_ENTRY_POINT equ 0xc0001500
以下是对mem_cpy函数,书上的解释,内容有点多,直接复制下来:

《操作系统真象还原》ELF文件的更多相关文章
- 《操作系统真象还原》bochs安装
在安装bochs之前,我们先需要安装虚拟机和linux发行版,也可以安装双系统,总之有个linux操作系统就好. 我是在ubuntu14.04系统下安装bochs的. 安装Bochs 以下为安装步骤 ...
- 《操作系统真象还原》MBR
以下是读本书第三章的收获. 如何知道一个源程序的各符号(指令和变量)地址?简单来说,地址就是该符号偏移文件开头的距离,符号的地址是按顺序编排的,所以两个相邻的符号,其地址也是相邻的.对于指令来说,指令 ...
- 《操作系统真象还原》BIOS
以下是读本书第二章的收获. 记得我大学学习操作系统的时候会遇到一些奇奇怪怪的问题,因为觉得问题太奇怪了,所以羞于问老师.诸如ROM到底是个什么东西:如果用内存映射的方式访问外部设备,是不是内存条里专门 ...
- ELF文件
ELF文件格式是一个开发标准,各种UNIX系统的可执行文件都采用ELF格式,它有三种不同的类型: 可重定位的目标文件 可执行文件 共享库 现在分析一下上一篇文章中经过汇编之后生成的目标文件max.o和 ...
- ELF文件的加载过程(load_elf_binary函数详解)--Linux进程的管理与调度(十三)
加载和动态链接 从编译/链接和运行的角度看,应用程序和库程序的连接有两种方式. 一种是固定的.静态的连接,就是把需要用到的库函数的目标代码(二进制)代码从程序库中抽取出来,链接进应用软件的目标映像中: ...
- GCC编译器原理(二)------编译原理一:ELF文件(2)
四. ELF 文件格式分析 ELF文件(目标文件)格式主要四种: 可重定向文件: 文件保存着代码和适当的数据,用来和其他的目标文件一起来创建一个可执行文件或者是一个共享目标文件.(目标文件或者静态库文 ...
- GCC编译器原理(二)------编译原理一:ELF文件(1)
二.ELF 文件介绍 2.1 可执行文件格式综述 相对于其它文件类型,可执行文件可能是一个操作系统中最重要的文件类型,因为它们是完成操作的真正执行者.可执行文件的大小.运行速度.资源占用情况以及可扩展 ...
- ARM 之一 ELF文件、镜像(Image)文件、可执行文件、对象文件 详解
[转]https://blog.csdn.net/ZCShouCSDN/article/details/100048461 ELF 文件规范 ELF(Executable and Linking ...
- 【DSP开发】DSP COFF 与 ELF文件
本文介绍了C6000最新的v7.2或者之后的编译器如何支持ELF(EABI)和COFF-ABI格式,首先由ARM引入嵌入式(Embedded) EABI的介绍,之后比较了COFF-ABI和EABI的区 ...
随机推荐
- 网络安全初级实战笔记(一):owasp zap 暴力破解
网络安全里装着好多人的侠客梦.但是不能触碰铁律,所以,只小小的自娱自乐. 自己练习,大都会用到DVWA,一个很好的安全测试平台,自己搭建(很简单,傻瓜式搭建),自己设置安全级别,自己验证各种漏洞攻击方 ...
- 深入了解MySQL,一篇简短的总结
MySQL的基本语法 这里作为MySQL部分模块的深入了解,大部分都是理论方面的笔记,不会写具体用法. 具体用法会记录在下面这个随笔分类下,不过暂时还没更新完,等过段时间会更新下事务.存储过程.索引等 ...
- VFP CursorAdapter 起步二(作者:Doug Hennig 译者:fbilo)
用 CursorAdapter 来取得和更新数据 在 VFP8 中新增的 CursorAdapter 基类提供一个统一.易用的数据接口.Doug Hennig 在这个月的文章中演示了怎样使用 Curs ...
- 浅析Internet上使用的安全协议
Internet上使用的安全协议 网络安全是分层实现的,从应用层安全到数据链路层安全. 一.运输层安全协议:安全套接字SSL 1.1.简介 SSL 是安全套接层 (Secure Socket Laye ...
- 【5min+】 设计模式的迷惑?Provider vs Factory
系列介绍 [五分钟的dotnet]是一个利用您的碎片化时间来学习和丰富.net知识的博文系列.它所包含了.net体系中可能会涉及到的方方面面,比如C#的小细节,AspnetCore,微服务中的.net ...
- C#设计模式学习笔记:(14)命令模式
本笔记摘抄自:https://www.cnblogs.com/PatrickLiu/p/7873322.html,记录一下学习过程以备后续查用. 一.引言 今天我们要讲行为型设计模式的第二个模式--命 ...
- 聊聊spring之bean对象的实例化过程
在spring实例化 之前bean对象封装成 beanDefinition 对象 想了解详情的请参考上一篇文章 好了 我们聊聊 Bean 的实例化过程的几个重要角色 BeanDefinitionReg ...
- Android Binder实现浅析-Binder驱动
简介 Android是如何实现跨进程通信的,大家熟悉的Binder是什么,怎么设计的,进程间的数据如何发送接收的.本文将以及解析,并对Binder驱动实现.Native层实现.Java层实现三块做一个 ...
- java循环语句 总结笔记
1.for 循环语句 语法:for(initialization;condition;iteration) public class A { public static void main(Strin ...
- js删除对象数组
若用remove删除某个对象数组,使用for循环遍历数组中的每个对象进行删除,则必须从数组的最后一个元素倒序删除,否则每次删除都只能删除数组的一半元素,因为把索引为0的子节点删除后那么很自然的原来索引 ...