吴裕雄 python 机器学习——集成学习随机森林RandomForestClassifier分类模型
import numpy as np
import matplotlib.pyplot as plt from sklearn import datasets,ensemble
from sklearn.model_selection import train_test_split def load_data_classification():
'''
加载用于分类问题的数据集
'''
# 使用 scikit-learn 自带的 digits 数据集
digits=datasets.load_digits()
# 分层采样拆分成训练集和测试集,测试集大小为原始数据集大小的 1/4
return train_test_split(digits.data,digits.target,test_size=0.25,random_state=0,stratify=digits.target) #集成学习随机森林RandomForestClassifier分类模型
def test_RandomForestClassifier(*data):
X_train,X_test,y_train,y_test=data
clf=ensemble.RandomForestClassifier()
clf.fit(X_train,y_train)
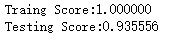
print("Traing Score:%f"%clf.score(X_train,y_train))
print("Testing Score:%f"%clf.score(X_test,y_test)) # 获取分类数据
X_train,X_test,y_train,y_test=load_data_classification()
# 调用 test_RandomForestClassifier
test_RandomForestClassifier(X_train,X_test,y_train,y_test)
def test_RandomForestClassifier_num(*data):
'''
测试 RandomForestClassifier 的预测性能随 n_estimators 参数的影响
'''
X_train,X_test,y_train,y_test=data
nums=np.arange(1,100,step=2)
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
testing_scores=[]
training_scores=[]
for num in nums:
clf=ensemble.RandomForestClassifier(n_estimators=num)
clf.fit(X_train,y_train)
training_scores.append(clf.score(X_train,y_train))
testing_scores.append(clf.score(X_test,y_test))
ax.plot(nums,training_scores,label="Training Score")
ax.plot(nums,testing_scores,label="Testing Score")
ax.set_xlabel("estimator num")
ax.set_ylabel("score")
ax.legend(loc="lower right")
ax.set_ylim(0,1.05)
plt.suptitle("RandomForestClassifier")
plt.show() # 调用 test_RandomForestClassifier_num
test_RandomForestClassifier_num(X_train,X_test,y_train,y_test)

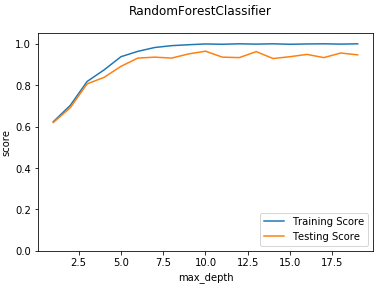
def test_RandomForestClassifier_max_depth(*data):
'''
测试 RandomForestClassifier 的预测性能随 max_depth 参数的影响
'''
X_train,X_test,y_train,y_test=data
maxdepths=range(1,20)
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
testing_scores=[]
training_scores=[]
for max_depth in maxdepths:
clf=ensemble.RandomForestClassifier(max_depth=max_depth)
clf.fit(X_train,y_train)
training_scores.append(clf.score(X_train,y_train))
testing_scores.append(clf.score(X_test,y_test))
ax.plot(maxdepths,training_scores,label="Training Score")
ax.plot(maxdepths,testing_scores,label="Testing Score")
ax.set_xlabel("max_depth")
ax.set_ylabel("score")
ax.legend(loc="lower right")
ax.set_ylim(0,1.05)
plt.suptitle("RandomForestClassifier")
plt.show() # 调用 test_RandomForestClassifier_max_depth
test_RandomForestClassifier_max_depth(X_train,X_test,y_train,y_test)
def test_RandomForestClassifier_max_features(*data):
'''
测试 RandomForestClassifier 的预测性能随 max_features 参数的影响
'''
X_train,X_test,y_train,y_test=data
max_features=np.linspace(0.01,1.0)
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
testing_scores=[]
training_scores=[]
for max_feature in max_features:
clf=ensemble.RandomForestClassifier(max_features=max_feature)
clf.fit(X_train,y_train)
training_scores.append(clf.score(X_train,y_train))
testing_scores.append(clf.score(X_test,y_test))
ax.plot(max_features,training_scores,label="Training Score")
ax.plot(max_features,testing_scores,label="Testing Score")
ax.set_xlabel("max_feature")
ax.set_ylabel("score")
ax.legend(loc="lower right")
ax.set_ylim(0,1.05)
plt.suptitle("RandomForestClassifier")
plt.show() # 调用 test_RandomForestClassifier_max_features
test_RandomForestClassifier_max_features(X_train,X_test,y_train,y_test)

吴裕雄 python 机器学习——集成学习随机森林RandomForestClassifier分类模型的更多相关文章
- 吴裕雄 python 机器学习——集成学习随机森林RandomForestRegressor回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习梯度提升决策树GradientBoostingRegressor回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习AdaBoost算法回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习AdaBoost算法分类模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 机器学习:集成学习:随机森林.GBDT
集成学习(Ensemble Learning) 集成学习的思想是将若干个学习器(分类器&回归器)组合之后产生一个新学习器.弱分类器(weak learner)指那些分类准确率只稍微好于随机猜测 ...
- 吴裕雄 python 机器学习——伯努利贝叶斯BernoulliNB模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,naive_bayes from skl ...
- 吴裕雄 python 机器学习——数据预处理过滤式特征选取SelectPercentile模型
from sklearn.feature_selection import SelectPercentile,f_classif #数据预处理过滤式特征选取SelectPercentile模型 def ...
- 吴裕雄 python 机器学习——数据预处理过滤式特征选取VarianceThreshold模型
from sklearn.feature_selection import VarianceThreshold #数据预处理过滤式特征选取VarianceThreshold模型 def test_Va ...
- 吴裕雄 python 机器学习——数据预处理字典学习模型
from sklearn.decomposition import DictionaryLearning #数据预处理字典学习DictionaryLearning模型 def test_Diction ...
随机推荐
- linux - mysql - 新建用户
新建用户 使用如下命令创建一个用户名和密码分别为"myuser"和"mypassword"的用户,localhost在User表里是Host字段(主机). my ...
- Django文件夹
Django文件 App文件夹 migrations文件 生成models创建表的翻译语句 telemplatetags文件夹 telemplatetags文件夹下的文件专门用来创建自定义标签.自定义 ...
- Java实现图形界面的三部曲及IDE中的窗口设计
设计和实现图形用户界面的工作主要有以下几点: • (1)创建组件(Component) • 创建组成界面的各种元素,如按钮.文本框等.• (2)指定布局(Layout) • 根据具体需要排列它们的位置 ...
- Python入门4 —— 输入与输出
一:输入(Input) 1.python3中的input(输入) inp_username=input("请输入您的密码:") # "18" print(inp ...
- win10中批量新建文件夹
1.新建一个bat文件,如[批量新建.bat].或者新建txt文件,输入完内容后重命名为bat文件 2.建议用notepad软件打开文件,首先确定编码格式为ANSI编码 (否则最后出现的效果是乱码,不 ...
- 后台异常 - Unrecognized Windows Sockets error: 0: JVM_Bind
问题描述 LifecycleException: Protocol handler initialization failed: java.net.SocketException: Unrecogn ...
- (转)java垃圾回收一
转自:http://jianfulove.iteye.com/blog/1833768 一切都进入了自动化了,但是对于各种内存溢出,内存泄漏问题的出现,我们还是很有必要学习GC的.地球人都知道,Jav ...
- SpringMVC请求乱码问题
今天做一个项目实现插入数据的功能,最开始没有添加FilterEncoding处理字符集乱码了,那是正常的,后来我添加过之后依然还是乱码,让我 百思不得其解,代码配置如下: EncodingFilter ...
- sql查询 —— 模糊查询
--模糊查询 --like --%至少替换一个 -- _只替换一个 -- 查姓李的人 select *from student name like "李%"; -- 查名为杰伦的人 ...
- Android基础知识 -- Fragment
Fragment是android3.0后提供的API(所以android:minSdkVersion="11"以上版本),主要针对平板UI.有自己的生命周期,但是必须依附在Acti ...