全文检索框架---Lucene
一、什么是全文检索
1、数据分类
我们生活中的数据总体分为两种:结构化数据和非结构化数据。
结构化数据:指具有固定格式或有限长度的数据,如数据库,元数据等。
非结构化数据:指不定长或无固定格式的数据,如邮件,word文档等磁盘上的文件
2、结构化数据搜索
常见的结构化数据也就是数据库中的数据。在数据库中搜索很容易实现,通常都是使用sql语句进行查询,而且能很快的得到查询结果。
为什么数据库搜索很容易?
因为数据库中的数据存储是有规律的,有行有列而且数据格式、数据长度都是固定的。
3、非结构化数据查询方法
(1)顺序扫描法(Serial Scanning)
所谓顺序扫描,比如要找内容包含某一个字符串的文件,就是一个文档一个文档的看,对于每一个文档,从头看到尾,如果此文档包含此字符串,则此文档为我们要找的文件,接着看下一个文件,直到扫描完所有的文件。如利用windows的搜索也可以搜索文件内容,只是相当的慢。
(2)全文检索(Full-text Search)
将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的。这部分从非结构化数据中提取出的然后重新组织的信息,我们称之索引。
例如:字典。字典的拼音表和部首检字表就相当于字典的索引,对每一个字的解释是非结构化的,如果字典没有音节表和部首检字表,在茫茫辞海中找一个字只能顺序扫描。然而字的某些信息可以提取出来进行结构化处理,比如读音,就比较结构化,分声母和韵母,分别只有几种可以一一列举,于是将读音拿出来按一定的顺序排列,每一项读音都指向此字的详细解释的页数。我们搜索时按结构化的拼音搜到读音,然后按其指向的页数,便可找到我们的非结构化数据——也即对字的解释。
这种先建立索引,再对索引进行搜索的过程就叫全文检索(Full-text Search)。
虽然创建索引的过程也是非常耗时的,但是索引一旦创建就可以多次使用,全文检索主要处理的是查询,所以耗时间创建索引是值得的。
4、如何实现全文检索
可以使用Lucene实现全文检索。Lucene是apache下的一个开放源代码的全文检索引擎工具包。提供了完整的查询引擎和索引引擎,部分文本分析引擎。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能。
5、全文检索的应用场景
对于数据量大、数据结构不固定的数据可采用全文检索方式搜索,比如百度、Google等搜索引擎、论坛站内搜索、电商网站站内搜索等。
二、Lucene实现全文检索的流程
Lucene是apache Lucene基于Java开发开源全文检索项目工具包,,除Lucene外,Solr,ES等都是基于Lucene的全文检索框架
1、索引和搜索流程图
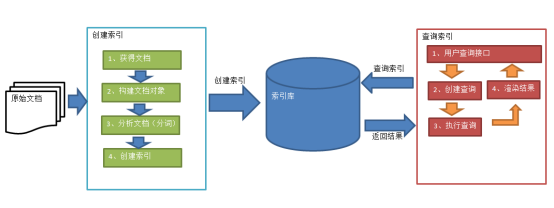
绿色表示索引过程,对要搜索的原始内容进行索引构建一个索引库,索引过程包括:
确定原始内容即要搜索的内容à采集文档à创建文档à分析文档à索引文档
红色表示搜索过程,从索引库中搜索内容,搜索过程包括:
用户通过搜索界面à创建查询à执行搜索,从索引库搜索à渲染搜索结果
2、创建索引
对文档索引的过程,将用户要搜索的文档内容进行索引,索引存储在索引库(index)中。
这里我们要搜索的文档是磁盘上的文本文件,根据案例描述:凡是文件名或文件内容包括关键字的文件都要找出来,这里要对文件名和文件内容创建索引。
2.1 获得原始文档
原始文档是指要索引和搜索的内容。原始内容包括互联网上的网页、数据库中的数据、磁盘上的文件等。
从互联网上、数据库、文件系统中等获取需要搜索的原始信息,这个过程就是信息采集,信息采集的目的是为了对原始内容进行索引。
在Internet上采集信息的软件通常称为爬虫或蜘蛛,也称为网络机器人,爬虫访问互联网上的每一个网页,将获取到的网页内容存储起来。
2.2 创建文档对象
获取原始内容的目的是为了索引,在索引前需要将原始内容创建成文档(Document),文档中包括一个一个的域(Field),域中存储内容。
这里我们可以将磁盘上的一个文件当成一个document,Document中包括一些Field(file_name文件名称、file_path文件路径、file_size文件大小、file_content文件内容)

注意:每个Document可以有多个Field,不同的Document可以有不同的Field,同一个Document可以有相同的Field(域名和域值都相同)
每个文档都有一个唯一的编号,就是文档id。
2.3 分析文档
将原始内容创建为包含域(Field)的文档(document),需要再对域中的内容进行分析,分析的过程是经过对原始文档提取单词、将字母转为小写、去除标点符号、去除停用词等过程生成最终的语汇单元,可以将语汇单元理解为一个一个的单词。
比如下边的文档经过分析如下:
原文档内容:
Lucene is a Java full-text search engine. Lucene is not a complete
application, but rather a code library and API that can easily be used
to add search capabilities to applications.
分析后得到的语汇单元:
lucene、java、full、search、engine。。。。
每个单词叫做一个Term,不同的域中拆分出来的相同的单词是不同的term。term中包含两部分一部分是文档的域名,另一部分是单词的内容。
例如:文件名中包含apache和文件内容中包含的apache是不同的term。
2.4 创建索引
对所有文档分析得出的语汇单元进行索引,索引的目的是为了搜索,最终要实现只搜索被索引的语汇单元从而找到Document(文档)。
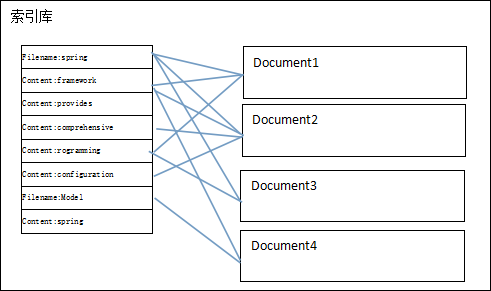
注意:创建索引是对语汇单元索引,通过词语找文档,这种索引的结构叫倒排索引结构。
传统方法是根据文件找到该文件的内容,在文件内容中匹配搜索关键字,这种方法是顺序扫描方法,数据量大、搜索慢。
倒排索引结构是根据内容(词语)找文档,如下图:
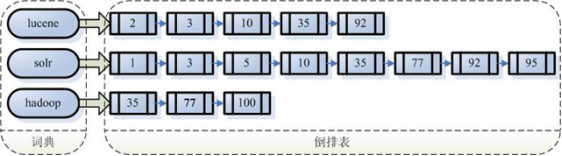
倒排索引结构也叫反向索引结构,包括索引和文档两部分,索引即词汇表,它的规模较小,而文档集合较大。
3、查询索引
查询索引也是搜索的过程。搜索就是用户输入关键字,从索引(index)中进行搜索的过程。根据关键字搜索索引,根据索引找到对应的文档,从而找到要搜索的内容(这里指磁盘上的文件)。
3.1 用户查询接口
全文检索系统提供用户搜索的界面供用户提交搜索的关键字,搜索完成展示搜索结果。
Lucene不提供制作用户搜索界面的功能,需要根据自己的需求开发搜索界面。
3.2 创建查询
用户输入查询关键字执行搜索之前需要先构建一个查询对象,查询对象中可以指定查询要搜索的Field文档域、查询关键字等,查询对象会生成具体的查询语法,
例如:
语法 “fileName:lucene”表示要搜索Field域的内容为“lucene”的文档
3.3 执行查询
搜索索引过程:
根据查询语法在倒排索引词典表中分别找出对应搜索词的索引,从而找到索引所链接的文档链表。
比如搜索语法为“fileName:lucene”表示搜索出fileName域中包含Lucene的文档。
搜索过程就是在索引上查找域为fileName,并且关键字为Lucene的term,并根据term找到文档id列表。
3.4 渲染结果
以一个友好的界面将查询结果展示给用户,用户根据搜索结果找自己想要的信息,为了帮助用户很快找到自己的结果,提供了很多展示的效果,比如搜索结果中将关键字高亮显示,百度提供的快照等。
三、配置开发环境
1、Lucene下载
Lucene是开发全文检索功能的工具包,从官方网站下载lucene-7.4.0,并解压。
官方网站:http://lucene.apache.org/
版本:lucene-7.4.0
JDK要求:JDK1.8以上

四、Lucene入门程序
1、目录展示
2、导入依赖
<!-- https://mvnrepository.com/artifact/org.apache.lucene/lucene-core -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>7.4.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.lucene/lucene-analyzers-common -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>7.4.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/commons-io/commons-io -->
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.4</version>
</dependency>
3、创建索引 CreatLucene
package com.zn; import org.apache.commons.io.FileUtils;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory; import java.io.File;
import java.io.IOException; /**
* 创建索引
*/
public class CreatLucene {
public static void main(String[] args) throws IOException {
//步骤一:创建Directory对象,用于指定索引库的位置
Directory directory= FSDirectory.open(new File("E:\\accp\\Y2\\进阶内容\\Lucene\\Lucene\\Index").toPath());
//步骤二:创建一个IndexWriter对象
IndexWriter indexWriter=new IndexWriter(directory,new IndexWriterConfig());
//步骤三:读取磁盘中文件,对应每一个文件创建一个文档对象
File file=new File("E:\\accp\\Y2\\进阶内容\\Lucene\\资料\\searchsource");
//步骤四:获取文件列表
File[] files=file.listFiles();
for (File item :files) {
//步骤五:获取文件数据,封装域 参数三:是否存储
Field fieldName=new TextField("fieldName",item.getName(), Field.Store.YES);
Field fieldPath=new TextField("fieldPath",item.getName(), Field.Store.YES);
Field fieldSize=new TextField("fieldSize", FileUtils.sizeOf(item)+"", Field.Store.YES);
Field fieldContent=new TextField("fieldContent",FileUtils.readFileToString(item,"UTF-8"), Field.Store.YES);
//步骤六:创建文档对象,向文档对象中添加域
Document document=new Document();
document.add(fieldName);
document.add(fieldPath);
document.add(fieldSize);
document.add(fieldContent); //步骤七:创建索引,将文档对象写入到索引库
indexWriter.addDocument(document);
}
System.out.println("文档对象写入索引库成功啦!!");
//步骤八:关闭资源
indexWriter.close();
}
}
4、查看索引
5、使用Luke工具查看索引库内容
5.1 双击bat脚本启动
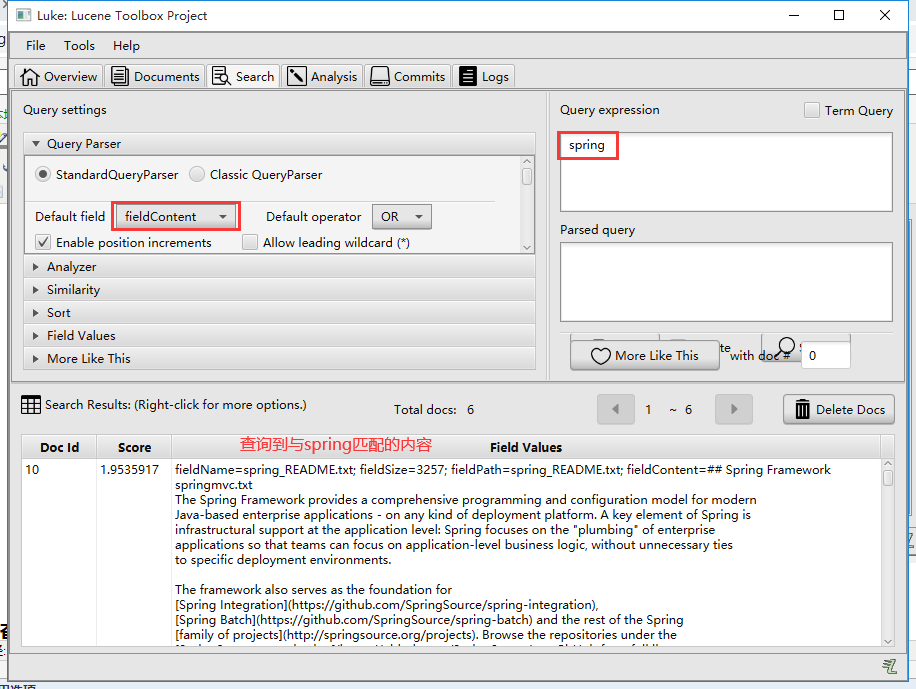
5.2 选择index文件夹路径

5.3 查询与spring匹配
6、查看索引 ReadLucene
package com.zn; import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.*;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory; import java.io.File;
import java.io.IOException; /**
* 查看索引
*/
public class ReadLucene {
public static void main(String[] args) throws IOException {
//1、创建Directory对象,指定索引库位置
Directory directory=FSDirectory.open(new File("E:\\accp\\Y2\\进阶内容\\Lucene\\Lucene\\Index").toPath());
//2、创建IndexReader对象,读取索引库内容
IndexReader indexReader = DirectoryReader.open(directory);
//3、创建IndexSearcher对象
IndexSearcher indexSearcher=new IndexSearcher(indexReader);
//4、创建Query查询对象
Query query=new TermQuery(new Term("fieldContent","spring"));
//5、执行查询,获取到文档对象
TopDocs topDocs = indexSearcher.search(query, 10);
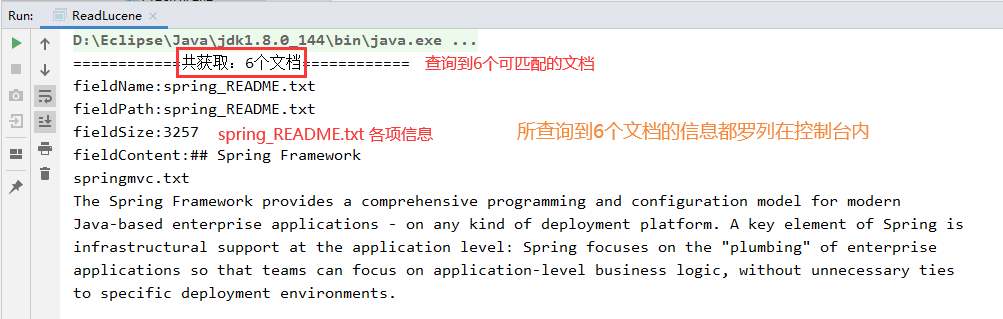
System.out.println("============共获取:"+topDocs.totalHits+"个文档============");
//6、获取文档列表
ScoreDoc [] scoreDocs=topDocs.scoreDocs;
for (ScoreDoc item:scoreDocs){
//获取文档ID
int docId=item.doc;
//取出文档
Document doc = indexSearcher.doc(docId);
//获取到文档域中的数据
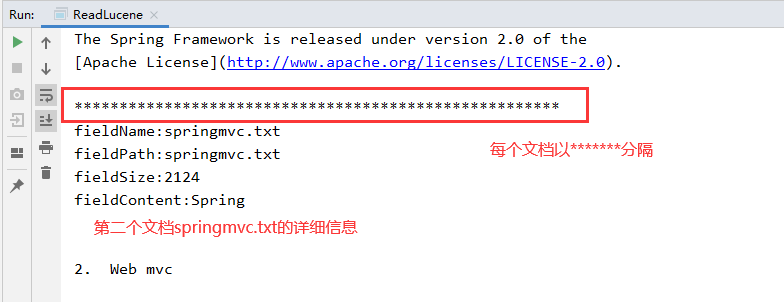
System.out.println("fieldName:"+doc.get("fieldName"));
System.out.println("fieldPath:"+doc.get("fieldPath"));
System.out.println("fieldSize:"+doc.get("fieldSize"));
System.out.println("fieldContent:"+doc.get("fieldContent"));
System.out.println("******************************************************");
}
//7、关闭资源
indexReader.close(); }
}
7、控制台效果
全文检索框架---Lucene的更多相关文章
- Solr全文检索框架
概述: 什么是Solr? Solr是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务.Solr可以独立运行在Jetty.tomcat.webLogic.webSh ...
- JAVAEE——Lucene基础:什么是全文检索、Lucene实现全文检索的流程、配置开发环境、索引库创建与管理
1. 学习计划 第一天:Lucene的基础知识 1.案例分析:什么是全文检索,如何实现全文检索 2.Lucene实现全文检索的流程 a) 创建索引 b) 查询索引 3.配置开发环境 4.创建索引库 5 ...
- 全文检索(Lucene&Solr)
全文检索(Lucene&Solr) 1)什么是全文检索?为什么需要全文检索? 结构化数据(mysql等)方便查询,而非结构化数据(如多篇文章)是难以查询到自己需要的,所以要使用全文检索. 全文 ...
- Haystack全文检索框架
一.什么是Haystack Haystack是django的开源全文搜索框架(全文检索不同于特定字段的模糊查询,使用全文检索的效率更高 ),该框架支持Solr,Elasticsearch,Whoosh ...
- Lucene全文检索框架
1.什么时Lucene? 是一个全文搜索框架,而不是应用产品,他只是一种工具让你能实现某些产品,并不像www.baidu.com拿来就能用 是apache组织的一个用java实现的全文搜索引擎的开源项 ...
- java框架---->lucene的使用(一)
Lucene是一个全文检索的框架,apache组织提供了一个用Java实现的全文搜索引擎的开源项目.这里我们对apache的lucene的框架做一个简单的介绍.心甘情愿这四个字,透着一股卑微,但也有藏 ...
- Haystack Python全文检索框架
Haystack 1.什么是Haystack Haystack是django的开源全文搜索框架(全文检索不同于特定字段的模糊查询,使用全文检索的效率更高 ),该框架支持Solr,Elasticsear ...
- 【手把手教你全文检索】Lucene索引的【增、删、改、查】
前言 搞检索的,应该多少都会了解Lucene一些,它开源而且简单上手,官方API足够编写些小DEMO.并且根据倒排索引,实现快速检索.本文就简单的实现增量添加索引,删除索引,通过关键字查询,以及更新索 ...
- OSCHina技术导向:Java全文搜索框架Lucene
Lucene 是apache软件基金会一个开放源代码的全文检索引擎工具包,是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎.Lucene的目的是为软件开发人员提供一个简单易用 ...
随机推荐
- 【Magicodes.IE 2.0.0-beta1版本发布】已支持数据表格、列筛选器和Sheet拆分
为了更好的完善Magicodes.IE,春节期间我们会进行一次大的重构.由于精力有限,急缺文档和翻译(将文档翻译为英文文档)支持,诚邀各位加入.同时在功能方便也做了相关规划,有兴趣的朋友可以参与提交P ...
- App的基本结构
今天主要学习安装了Android Studio,并且成功地在虚拟机上运行了HelloWord工程.下面针对HelloWord工程对app的基本框架结构进行一个总结.掌握app的基本结构对初学软件开发的 ...
- Elasticsearch系列---结构化搜索
概要 结构化搜索针对日期.时间.数字等结构化数据的搜索,它们有自己的格式,我们可以对它们进行范围,比较大小等逻辑操作,这些逻辑操作得到的结果非黑即白,要么符合条件在结果集里,要么不符合条件在结果集之外 ...
- 为BlueLake主题增加图片放大效果
fancyBox 是一个流行的媒体展示增强组件,可以方便为网站添加图片放大.相册浏览.视频弹出层播放等效果.优点有使用简单,支持高度自定义,兼顾触屏.响应式移动端特性,总之使用体验相当好. 现在,我们 ...
- Element中(Notification)通知组件字体修改(Vue项目中Element的Notification修改字体)
这个问题纠结很久,一样的写的为啥有的页面就可以,有的就不行: 后来才发现: 先说一下怎么设置: 先定义customClass一个属性,用来写class属性值: 之后还需要修改一下组件里style标签的 ...
- tensorflow框架
一.tensorflow的工作流程,实际上它体现出来的是一个”懒性“方法论 (1)构建一个计算图. (2)初始化变量 (3)创建一个会话 (4)在会话中运行图的计算 (5)关闭会话 二.神经网络搭建八 ...
- 夜深了 关于 异步Action的定义的截图
- Client API Object Model - Form Context
FormContext 提供界面或者界面上控件的的引用. 比如说 quick view control, row in an editable grid 等等. Xrm.Page 和 getFormC ...
- Azure 认知服务概述
背景知识 近些年随着机器学习.深度学习等技术的不断发展,人工智能在越来越多的场景得到了应用,如人脸识别.图像识别.语音识别.语音生成.自然语言处理.决策分析等等,让机器拥有了听.说.看和思考的能力,很 ...
- Vertx使用EventBus发送接受自定义对象
先看官方文档步骤: 需要一个编解码器,看源码: 可见内置了需要数据类型的实现,所以发送其他消息可以发送,但是如果发送自定义对象就需要自己实现编解码逻辑了 一 自定义编解码器 /** * 自定义对象编解 ...