cache和内存屏障
1 cache简介
1.1 cache缓存映射规则
tag查看cache是否匹配,set index
|tag |set index |block offset |
|20-bit |7-bit |5bit |
1.2 cache 组织方式
Cache 全关联
cache 组关联
cache 4路组关联
四路组关联:
cache包括128个cache set(不为0表示组关联,为0表示全关联fully Associative cache)
每个cache set包含四个cache line(四路,同一数据可能在四个cache位置中的一个缓存)
每个cache line是32字节大小
PIPT 物理地址索引物理地址标签
VIPT 虚拟地址索引物理地址标签
VIVT 虚拟地址索引虚拟地址标签
2 Cache-coherency MESI协议
以cache line为最小单元进行一致性内存管理
2.1 MESI协议状态
modified独占&修改过:其他CPU的该cache是无效的、换出该cache需要写回memory
exclusive独占:其他CPU的该cache是无效的、
share共享: 其他CPU的该cache可以是共享的共同读取该cache
Invalid无效: 表示该cache是无效的,需要读入才能生效
2.2 MESI协议消息
read:表示要读取特定cache
read response:其他chache或memory响应read指令。
invalidate:通知其他cpu将cache的数据设置为无效,后续接收所有CPU的invalidate Acknowledge。
invalidate Acknowledge:所有其他cache收到invalidate移除数据后发送的响应指令。
read invalidate:read+invalidate,期望收到read response和所有CPU的invalidate Acknowledge。
writeback:modified状态下的cacheline写回时候发出。
2.3 MESI状态迁移
|
状态转换|目标状态 原状态 |
Modified | Exclusive | Share | Invalid |
| Modified |
M->E 执行writeback操作 将cacheline的数据写回到memory |
M->S 收到read请求 发送read response |
M->I 收到read invalidate请求 发送read response传递最新数据 清除数据 发送invalidate acknowledge |
|
| Exclusive |
E->M cpu将数据写入cacheline |
E->S 收到read请求 发送read response |
E->I 收到read invalidate 发送read response传递最新数据 清除数据 发送invalidate acknowledge |
|
| Share |
S->M 执行一个原子的read-modify-write操作 发送invalidate 接收invalidate acknowledge |
S->E 发送invalidate 接收invalidate acknowledge |
S->I 收到invalidate 清除数据 发送invalidate acknowledge |
|
| Invalid |
I->M 执行一个原子的read-modify-write操作 发送read invalidate 接收read response传递的最新数据 接收invalidate acknowledge |
I->E 发送read invalidate 接收read response传递的最新数据 接收invalidate acknowledge |
I->S 发送read 接收read response传递的最新数据 |
3. MESI协议优化引起的问题
3.1 store buffer的引入
写入内存时如果没有cache,则会先写入到store buffer中
这样可能会引起其他CPU看到的写入顺序与实际的写入顺序不相同的问题。
3.2 invalidate queue的引入
CPU收到invalidate命令后将invalidate存入invalidate queue中直接返回invalidate acknowledge。
会引起read操作读取到的数据已经失效,但是失效命令在invalidate queue中排队。
4 memory barrier
4.1 memory barrier如何解决上一节描述的问题
write memory barrier:标记当前store buffer中的所有项,如果store buffer中有标记项则后续store都会保存在store中,而不会直接写入cache。
执行现象就是CPU一定是先完成wmb之前的store,然后再完成wmb之后的store。
read memory barrier:将Invalidate Queue中的message处理完成。
执行现象就是CPU一定是先完成rmb之前的load,然后再完成rmb之后的load。
4.2 linux 定义的memory barrier
linux定义的互斥原语(spinlocks、reader-writer locks semaphores、RCU。。。)都隐含需要的memory barrier原语。
4.2.1 编译器优化屏障barrier()
主要解决编译器优化重拍的问题
4.2.2 内存优化屏障
内存优化屏障宏内部包含编译器优化屏障,防止编译器对指令进行重排
write memory barrier(smp_wmb())、read memory barrier(smp_rmb())、memory barrier(smp_mb()):
主要用于CPU间的交互顺序保证
smp_read_barrier_depends():表示依赖关系(例如前一个的操作是取后一个要操作memory的地址),只在Alpha上实现不为空。
mmiowb() :保护spin lock保护的MMIO write操作顺序。有些CPU architecture平台中,spinlock中的memory barrier操作已经保证了MMI的写入顺序,那么这个宏是空的。TODO:不理解mmio具体
up版本memory barrier:wmb()、rmb()、mb()、read_barrier_depends()。
主要用于CPU和外设交互时的顺序保证
5 处理器相关
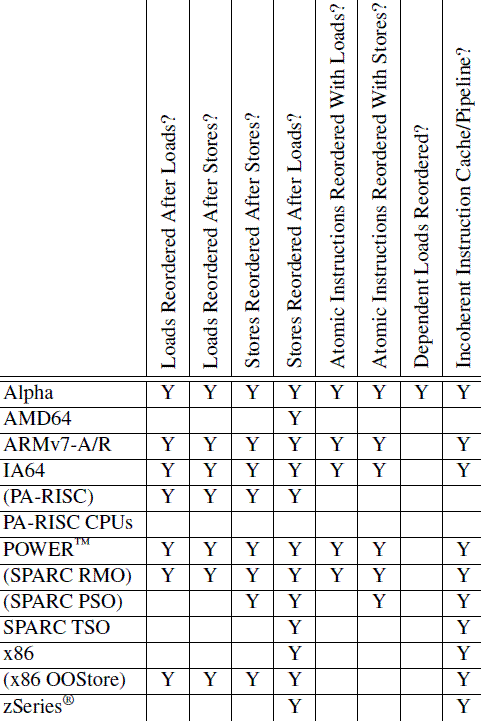
5.1 ARM
DMB(data memory barrier):可以指定内存操作类型(store或store+load)和作用域 (单处理器、一组处理器inner、全局outer),约束观察到的顺序。
DSB(data synchronization barrier):真正对指令执行的约束。
ISB(instruction synchronization barrier):刷新指令缓存,保证之前对指令部分的修改在之后的执行中可见。
参考文献:
http://www.wowotech.net/kernel_synchronization/Why-Memory-Barriers.html
http://www.wowotech.net/kernel_synchronization/why-memory-barrier-2.html
cache和内存屏障的更多相关文章
- JVM内存模型、指令重排、内存屏障概念解析
在高并发模型中,无是面对物理机SMP系统模型,还是面对像JVM的虚拟机多线程并发内存模型,指令重排(编译器.运行时)和内存屏障都是非常重要的概念,因此,搞清楚这些概念和原理很重要.否则,你很难搞清楚哪 ...
- [百度空间] [转]内存屏障 - MemoryBarrier
处理器的乱序和并发执行 目前的高级处理器,为了提高内部逻辑元件的利用率以提高运行速度,通常会采用多指令发射.乱序执行等各种措施.现在普遍使用的一些超标量处理器通常能够在一个指令周期内并发执行多条指令. ...
- [面试]volatile类型修饰符/内存屏障/处理器缓存
volatile类型修饰符 本篇文章的目的是为了自己梳理面试知识点, 在这里做一下笔记. 绝大部分内容是基于这些文章的内容进行了copy+整理: 1. http://www.infoq.com/cn/ ...
- Linux并发与同步专题 (1)原子操作和内存屏障
关键词:. <Linux并发与同步专题 (1)原子操作和内存屏障> <Linux并发与同步专题 (2)spinlock> <Linux并发与同步专题 (3) 信号量> ...
- JVM内存模型、指令重排、内存屏障概念解析(转载)
在高并发模型中,无是面对物理机SMP系统模型,还是面对像JVM的虚拟机多线程并发内存模型,指令重排(编译器.运行时)和内存屏障都是非常重要的概念,因此,搞清楚这些概念和原理很重要.否则,你很难搞清楚哪 ...
- C和C++中的volatile、内存屏障和CPU缓存一致性协议MESI
目录 1. 前言2 2. 结论2 3. volatile应用场景3 4. 内存屏障(Memory Barrier)4 5. setjmp和longjmp4 1) 结果1(非优化编译:g++ -g -o ...
- LINUX内核内存屏障
================= LINUX内核内存屏障 ================= By ...
- CPU缓存和内存屏障
CPU性能优化手段 - 缓存 为了提高程序的运行性能, 现代CPU在很多方面对程序进行了优化例如: CPU高速缓存, 尽可能的避免处理器访问主内存的时间开销, 处理器大多会利用缓存以提高性能 多级缓存 ...
- volatile 和 内存屏障
接下来看看volatile是如何解决上面两个问题的: 被volatile修饰的变量在编译成字节码文件时会多个lock指令,该指令在执行过程中会生成相应的内存屏障,以此来解决可见性跟重排序的问题. 内存 ...
随机推荐
- 假期续命充电——简单上手tesorflow2 框架
谈到深度学习,就不得不谈到tensorflow 在tensorflow之后出了2.0版本,相比之前有了很大的改变,趁着假期赶紧冲冲冲! 稍微学习了一些基础,做一个自我总结,作为一些基础的知识不再过多重 ...
- 防止过拟合的方法 预测鸾凤花(sklearn)
1. 防止过拟合的方法有哪些? 过拟合(overfitting)是指在模型参数拟合过程中的问题,由于训练数据包含抽样误差,训练时,复杂的模型将抽样误差也考虑在内,将抽样误差也进行了很好的拟合. 产生过 ...
- Qt Installer Framework翻译(0)
本人主攻C++和Qt. 以前一直看人家的博客,找资料学习.今天我也终于开博客啦. 最近在研究Qt install framework(IFW)应用程序安装框架. google也没发现有正儿八经的官方文 ...
- Java入门 - 语言基础 - 06.变量类型
原文地址:http://www.work100.net/training/java-variable-type.html 更多教程:光束云 - 免费课程 变量类型 序号 文内章节 视频 1 概述 2 ...
- (转) exp1-3://一次有趣的XSS漏洞挖掘分析(3)最终篇
这真是最后一次了.真的再不逗这个程序员了.和预期一样,勤奋的程序员今天又更新程序了.因为前面写的payload都有一个致命的弱点,就是document.write()会完全破坏DOM结构.而且再“ ...
- 提高Dom 访问效率
在浏览器中对于Dom的操作和普通的脚本的操作处于两个不同的dll中,两个dll的交互是比较耗时的,优化对Dom的操作可以提高脚本的执行速度. JS访问DOM是很慢的,尽量不要用JS来设置页面 布局 有 ...
- JavaScript 注意
字符串常用方法: 除.length外 都要加括号 trimLeft trimRight L和R要大写. .charAt 类似索引,超出范围为空 ,注意 (At)大小写. 注意 1.st ...
- C# LINQ查询表达式用法对应Lambda表达式
C#编程语言非常优美,我个人还是非常赞同的.特别是在学习一段时间C#后发现确实在它的语法和美观度来说确实要比其它编程语言强一些(也可能是由于VS编译器的加持)用起来非常舒服,而且对于C#我觉得他最优美 ...
- spring @Scheduled注解 定时任务 详解
scheduled的使用注解的方式进行调度 先要配置spring.xml xmlns:task="http://www.springframework.org/schema/task&quo ...
- <背包>solution-POJ1742_Coins
POJ1742 - Coins People in Silverland use coins.They have coins of value A1,A2,A3...An Silverland dol ...